
ML 93 1 Chap7 Clustering&EM
ML 93 1 Chap7 Clustering&EM
You might also like
- ML - 97 - 1 - Chp04 - Parametric Methods - 2Document36 pagesML - 97 - 1 - Chp04 - Parametric Methods - 2erfan roshandelNo ratings yet
- Quantization of Classical FieldsDocument31 pagesQuantization of Classical FieldsSorushaminfarNo ratings yet
- Gauge Theory and The Standard ModelDocument20 pagesGauge Theory and The Standard ModelRodja MoqtadaeeNo ratings yet
- Shivehname Ahmadi Roshan 14 01 1Document24 pagesShivehname Ahmadi Roshan 14 01 1Ali KhubbakhtNo ratings yet
- Signals SystemsDocument119 pagesSignals SystemsshahabcontrolNo ratings yet
- File 5794Document12 pagesFile 5794asNo ratings yet
- مبانی هوش محاسباتیDocument3 pagesمبانی هوش محاسباتیrahmanianNo ratings yet
- 0 Labs For System Identification CourseDocument13 pages0 Labs For System Identification CoursealexmontogoNo ratings yet
- File 7174Document23 pagesFile 7174asNo ratings yet
- CHAPTER05 Quadratic ProgDocument8 pagesCHAPTER05 Quadratic ProgMeysam GheysariNo ratings yet
- File 5243Document11 pagesFile 5243asNo ratings yet
- عدد شرطیDocument10 pagesعدد شرطیmaryam afzaliNo ratings yet
- محاسبه عدد شرطیDocument10 pagesمحاسبه عدد شرطیmaryam afzaliNo ratings yet
- ماتریس ها (پارسه)Document48 pagesماتریس ها (پارسه)mr.khoshpanahNo ratings yet
- Electric Circuit Chapter 1Document20 pagesElectric Circuit Chapter 1مهدی ارغوانیNo ratings yet
- Signals and SystemsDocument119 pagesSignals and SystemsAdel HabibiNo ratings yet
- 86 KharejDocument19 pages86 KharejTaghi KhajeNo ratings yet
- 4 5938527026775328085Document44 pages4 5938527026775328085Ashebir TaresaNo ratings yet
- Cluster Analysis00 1Document44 pagesCluster Analysis00 1alihamidi0097No ratings yet
- Solved MCQs 20Document1 pageSolved MCQs 20snackvideo2299No ratings yet
- S02 - Numbers SystemDocument12 pagesS02 - Numbers SystemArya VafaeeshoarNo ratings yet
- RIFAH Math 9th ClassDocument17 pagesRIFAH Math 9th ClassMuhammad NadeemNo ratings yet
- جزوه های کمک آموزشی - ریاضی 1 - فصل 4 - درس 3 (متن) - 103612Document8 pagesجزوه های کمک آموزشی - ریاضی 1 - فصل 4 - درس 3 (متن) - 103612Hossein kianiNo ratings yet
- Nemoone SoalDocument2 pagesNemoone SoalshahabcontrolNo ratings yet
- Mathematics 10TH 2ND HalfDocument3 pagesMathematics 10TH 2ND Halfashfaq4985No ratings yet
- نمونه سوال حسابان87Document5 pagesنمونه سوال حسابان87siamakbeikzadeh5No ratings yet
- حسابانDocument9 pagesحسابانSoheil GholamiNo ratings yet
- دفترچه سوال و پاسخ تشریحی آزمون ها (PDF) - دفترچه سوال و پاسخ تشریحی آزمون آزمایشی مرحله 6 (متن) - 117167Document16 pagesدفترچه سوال و پاسخ تشریحی آزمون ها (PDF) - دفترچه سوال و پاسخ تشریحی آزمون آزمایشی مرحله 6 (متن) - 117167Sepanta AbdolahpourNo ratings yet
- 03dcfb38-8a85-4960-ac5a-dd77ff97d2e5Document10 pages03dcfb38-8a85-4960-ac5a-dd77ff97d2e5Mehdi AbdollahiNo ratings yet
- Azmoon 1Document2 pagesAzmoon 1i9jjvuietnNo ratings yet
- MATLAB Learning (In Persian) PDFDocument47 pagesMATLAB Learning (In Persian) PDFHamrah korNo ratings yet
- P 89 Ai 5394Document18 pagesP 89 Ai 5394Amir DashtiNo ratings yet
- Computer GraphicsDocument38 pagesComputer GraphicsmajidNo ratings yet
- Computer Science 10TH 2ND HalfDocument2 pagesComputer Science 10TH 2ND Halfashfaq4985No ratings yet
- Azeerteashat PDFDocument61 pagesAzeerteashat PDFReza BakhtiariNo ratings yet
- Nokteph 1Document4 pagesNokteph 1vczq6v5v6sNo ratings yet
- Powsys 3Document28 pagesPowsys 3ehsan.abdollahi.62No ratings yet
- M 2 +9n 4m 5 mn+5nDocument11 pagesM 2 +9n 4m 5 mn+5nAlvand HormoziNo ratings yet
- فصل 4- انتگرالDocument33 pagesفصل 4- انتگرالabdimh728No ratings yet
- LADocument5 pagesLAjavad konjiNo ratings yet
- Solved MCQsDocument2 pagesSolved MCQsAmmar HussainNo ratings yet
- شمصجصوثدصلDocument7 pagesشمصجصوثدصلhshavababajajshNo ratings yet
- Am HW1Document4 pagesAm HW1ehsan ardeshiriNo ratings yet
- مجموعه فارم های سال 1403Document13 pagesمجموعه فارم های سال 1403saifysharif80No ratings yet
- Lecture 21Document4 pagesLecture 21bahram bahramiNo ratings yet
- Week2a Chap4 MarixDocument42 pagesWeek2a Chap4 MarixAliNo ratings yet
- PF 27578924Document6 pagesPF 27578924kamyar safariNo ratings yet
- La HW4Document11 pagesLa HW4ebi1234No ratings yet
- RIFAH Class 9th Physics Half Chapter Wise TestDocument18 pagesRIFAH Class 9th Physics Half Chapter Wise TestMuhammad NadeemNo ratings yet
- T3 Chapter 3 9Document1 pageT3 Chapter 3 9Danixh WritesNo ratings yet
- LA-02-Algebra of Matrices - Part 2Document39 pagesLA-02-Algebra of Matrices - Part 2erfNo ratings yet
- کوانتومDocument31 pagesکوانتومnegin.sherzavani18No ratings yet
- 4 5845963437800163371 PDFDocument50 pages4 5845963437800163371 PDFNazir AhmadNo ratings yet
- طراحی دال دوطرفه1Document29 pagesطراحی دال دوطرفه1Arash LashkariNo ratings yet
- مقاومت مصالح 3-1 PDFDocument73 pagesمقاومت مصالح 3-1 PDFmahdiNo ratings yet
- F 3-RevisedDocument44 pagesF 3-RevisedmaryamNo ratings yet
- hw01 PDFDocument2 pageshw01 PDFParsa AseminiaNo ratings yet
- سلسلة تمارين محلولة رقم 2 الاتصال و النهياتDocument16 pagesسلسلة تمارين محلولة رقم 2 الاتصال و النهياتIbrahím LaâmëchNo ratings yet


























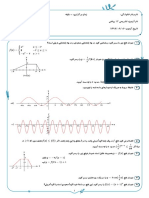














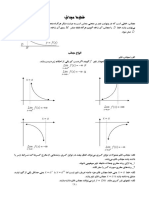
















Download as pdf or txt
You might also like
- ML - 97 - 1 - Chp04 - Parametric Methods - 2Document36 pagesML - 97 - 1 - Chp04 - Parametric Methods - 2erfan roshandelNo ratings yet
- Quantization of Classical FieldsDocument31 pagesQuantization of Classical FieldsSorushaminfarNo ratings yet
- Gauge Theory and The Standard ModelDocument20 pagesGauge Theory and The Standard ModelRodja MoqtadaeeNo ratings yet
- Shivehname Ahmadi Roshan 14 01 1Document24 pagesShivehname Ahmadi Roshan 14 01 1Ali KhubbakhtNo ratings yet
- Signals SystemsDocument119 pagesSignals SystemsshahabcontrolNo ratings yet
- File 5794Document12 pagesFile 5794asNo ratings yet
- مبانی هوش محاسباتیDocument3 pagesمبانی هوش محاسباتیrahmanianNo ratings yet
- 0 Labs For System Identification CourseDocument13 pages0 Labs For System Identification CoursealexmontogoNo ratings yet
- File 7174Document23 pagesFile 7174asNo ratings yet
- CHAPTER05 Quadratic ProgDocument8 pagesCHAPTER05 Quadratic ProgMeysam GheysariNo ratings yet
- File 5243Document11 pagesFile 5243asNo ratings yet
- عدد شرطیDocument10 pagesعدد شرطیmaryam afzaliNo ratings yet
- محاسبه عدد شرطیDocument10 pagesمحاسبه عدد شرطیmaryam afzaliNo ratings yet
- ماتریس ها (پارسه)Document48 pagesماتریس ها (پارسه)mr.khoshpanahNo ratings yet
- Electric Circuit Chapter 1Document20 pagesElectric Circuit Chapter 1مهدی ارغوانیNo ratings yet
- Signals and SystemsDocument119 pagesSignals and SystemsAdel HabibiNo ratings yet
- 86 KharejDocument19 pages86 KharejTaghi KhajeNo ratings yet
- 4 5938527026775328085Document44 pages4 5938527026775328085Ashebir TaresaNo ratings yet
- Cluster Analysis00 1Document44 pagesCluster Analysis00 1alihamidi0097No ratings yet
- Solved MCQs 20Document1 pageSolved MCQs 20snackvideo2299No ratings yet
- S02 - Numbers SystemDocument12 pagesS02 - Numbers SystemArya VafaeeshoarNo ratings yet
- RIFAH Math 9th ClassDocument17 pagesRIFAH Math 9th ClassMuhammad NadeemNo ratings yet
- جزوه های کمک آموزشی - ریاضی 1 - فصل 4 - درس 3 (متن) - 103612Document8 pagesجزوه های کمک آموزشی - ریاضی 1 - فصل 4 - درس 3 (متن) - 103612Hossein kianiNo ratings yet
- Nemoone SoalDocument2 pagesNemoone SoalshahabcontrolNo ratings yet
- Mathematics 10TH 2ND HalfDocument3 pagesMathematics 10TH 2ND Halfashfaq4985No ratings yet
- نمونه سوال حسابان87Document5 pagesنمونه سوال حسابان87siamakbeikzadeh5No ratings yet
- حسابانDocument9 pagesحسابانSoheil GholamiNo ratings yet
- دفترچه سوال و پاسخ تشریحی آزمون ها (PDF) - دفترچه سوال و پاسخ تشریحی آزمون آزمایشی مرحله 6 (متن) - 117167Document16 pagesدفترچه سوال و پاسخ تشریحی آزمون ها (PDF) - دفترچه سوال و پاسخ تشریحی آزمون آزمایشی مرحله 6 (متن) - 117167Sepanta AbdolahpourNo ratings yet
- 03dcfb38-8a85-4960-ac5a-dd77ff97d2e5Document10 pages03dcfb38-8a85-4960-ac5a-dd77ff97d2e5Mehdi AbdollahiNo ratings yet
- Azmoon 1Document2 pagesAzmoon 1i9jjvuietnNo ratings yet
- MATLAB Learning (In Persian) PDFDocument47 pagesMATLAB Learning (In Persian) PDFHamrah korNo ratings yet
- P 89 Ai 5394Document18 pagesP 89 Ai 5394Amir DashtiNo ratings yet
- Computer GraphicsDocument38 pagesComputer GraphicsmajidNo ratings yet
- Computer Science 10TH 2ND HalfDocument2 pagesComputer Science 10TH 2ND Halfashfaq4985No ratings yet
- Azeerteashat PDFDocument61 pagesAzeerteashat PDFReza BakhtiariNo ratings yet
- Nokteph 1Document4 pagesNokteph 1vczq6v5v6sNo ratings yet
- Powsys 3Document28 pagesPowsys 3ehsan.abdollahi.62No ratings yet
- M 2 +9n 4m 5 mn+5nDocument11 pagesM 2 +9n 4m 5 mn+5nAlvand HormoziNo ratings yet
- فصل 4- انتگرالDocument33 pagesفصل 4- انتگرالabdimh728No ratings yet
- LADocument5 pagesLAjavad konjiNo ratings yet
- Solved MCQsDocument2 pagesSolved MCQsAmmar HussainNo ratings yet
- شمصجصوثدصلDocument7 pagesشمصجصوثدصلhshavababajajshNo ratings yet
- Am HW1Document4 pagesAm HW1ehsan ardeshiriNo ratings yet
- مجموعه فارم های سال 1403Document13 pagesمجموعه فارم های سال 1403saifysharif80No ratings yet
- Lecture 21Document4 pagesLecture 21bahram bahramiNo ratings yet
- Week2a Chap4 MarixDocument42 pagesWeek2a Chap4 MarixAliNo ratings yet
- PF 27578924Document6 pagesPF 27578924kamyar safariNo ratings yet
- La HW4Document11 pagesLa HW4ebi1234No ratings yet
- RIFAH Class 9th Physics Half Chapter Wise TestDocument18 pagesRIFAH Class 9th Physics Half Chapter Wise TestMuhammad NadeemNo ratings yet
- T3 Chapter 3 9Document1 pageT3 Chapter 3 9Danixh WritesNo ratings yet
- LA-02-Algebra of Matrices - Part 2Document39 pagesLA-02-Algebra of Matrices - Part 2erfNo ratings yet
- کوانتومDocument31 pagesکوانتومnegin.sherzavani18No ratings yet
- 4 5845963437800163371 PDFDocument50 pages4 5845963437800163371 PDFNazir AhmadNo ratings yet
- طراحی دال دوطرفه1Document29 pagesطراحی دال دوطرفه1Arash LashkariNo ratings yet
- مقاومت مصالح 3-1 PDFDocument73 pagesمقاومت مصالح 3-1 PDFmahdiNo ratings yet
- F 3-RevisedDocument44 pagesF 3-RevisedmaryamNo ratings yet
- hw01 PDFDocument2 pageshw01 PDFParsa AseminiaNo ratings yet
- سلسلة تمارين محلولة رقم 2 الاتصال و النهياتDocument16 pagesسلسلة تمارين محلولة رقم 2 الاتصال و النهياتIbrahím LaâmëchNo ratings yet