Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5820)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- GEOBIA in ArcGIS Jacek UrbanskiDocument43 pagesGEOBIA in ArcGIS Jacek UrbanskisergonzalezNo ratings yet
- CTP Tools DescriptionDocument26 pagesCTP Tools Descriptionsanchezm881100% (1)
- Ara Axapta500.edbDocument3,858 pagesAra Axapta500.edbAhmed Badawy0% (1)
- Assignment 04aDocument4 pagesAssignment 04akushalNo ratings yet
- Project Organizational Chart of Wilmont PDFDocument1 pageProject Organizational Chart of Wilmont PDFMohamed MidouneNo ratings yet
- FrancisAsuncion CostOfQualityDocument2 pagesFrancisAsuncion CostOfQualityMohamed MidouneNo ratings yet
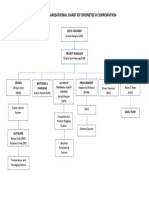
- Project Organizational Chart of Dronetech Corporation PDFDocument1 pageProject Organizational Chart of Dronetech Corporation PDFMohamed MidouneNo ratings yet
- Cost of Quality Assessment: Project Name Revision Number Revision DateDocument2 pagesCost of Quality Assessment: Project Name Revision Number Revision DateMohamed MidouneNo ratings yet
- Project Charter PDFDocument2 pagesProject Charter PDFMohamed MidouneNo ratings yet
- CAPE Applied Mathematics Past Papers 2005P1C PDFDocument8 pagesCAPE Applied Mathematics Past Papers 2005P1C PDFEquitable BrownNo ratings yet
- Design Rules For Vacuum ChambersDocument12 pagesDesign Rules For Vacuum ChambersDavid Jimenez GonzalezNo ratings yet
- Chapter 3Document9 pagesChapter 3Hamza HussineNo ratings yet
- Algebra 2Document8 pagesAlgebra 2Ejed Daganga Bsee-iiNo ratings yet
- Jawaharlal Nehru University MA Economics Past Year Papers: Source Updated: August 20, 2021Document178 pagesJawaharlal Nehru University MA Economics Past Year Papers: Source Updated: August 20, 2021Shourya MarwahaNo ratings yet
- Cheat Sheet: Geometric Confirmation Geometry Creation Geometric OperationsDocument2 pagesCheat Sheet: Geometric Confirmation Geometry Creation Geometric OperationshatNo ratings yet
- Iso 1328-Agma - Parte 1Document35 pagesIso 1328-Agma - Parte 1bernaldoarnaoNo ratings yet
- Asset and Equity VolatilitiesDocument40 pagesAsset and Equity Volatilitiescorporateboy36596No ratings yet
- Group Technology and Cellular Manufacturing-IDocument20 pagesGroup Technology and Cellular Manufacturing-IAnonymous NGBgXVq1xNo ratings yet
- ODE Formula SheetDocument4 pagesODE Formula SheetJohnNo ratings yet
- Soalan LKM5 Topik3 SM015 20222023Document2 pagesSoalan LKM5 Topik3 SM015 20222023Syafiyah MursyidahNo ratings yet
- Journal of Architectural Environment & Structural Engineering Research - Vol.5, Iss.4 October 2022Document38 pagesJournal of Architectural Environment & Structural Engineering Research - Vol.5, Iss.4 October 2022Bilingual PublishingNo ratings yet
- Class 12th Maths Chapter 1 (Relations and Functions) Unsolved PDFDocument7 pagesClass 12th Maths Chapter 1 (Relations and Functions) Unsolved PDFEr. Narender SinghNo ratings yet
- Femh 104Document17 pagesFemh 104Dunil WadaskarNo ratings yet
- Module5 QB 1Document21 pagesModule5 QB 1Vaishnavi G . RaoNo ratings yet
- SilverThin Slewing Rings and Pinions CatalogDocument16 pagesSilverThin Slewing Rings and Pinions CatalogGanesh LohakareNo ratings yet
- Design of Stiffeners For Industrial Piping Under External Pressure Using FemDocument6 pagesDesign of Stiffeners For Industrial Piping Under External Pressure Using FemJosip KacmarcikNo ratings yet
- RheologyDocument54 pagesRheologyShivraj JadhavNo ratings yet
- 3 & 4 Sem ECE UpdatedDocument78 pages3 & 4 Sem ECE UpdatedBhargav ShatrughnaNo ratings yet
- Grade 5 Long Division Worksheets FreeDocument3 pagesGrade 5 Long Division Worksheets FreeBillyNo ratings yet
- Cs 402 AnalysisDocument4 pagesCs 402 AnalysisSandeep Kumar mehtaNo ratings yet
- ForestDocument670 pagesForestKarina LanzarinNo ratings yet
- Mba Ist Year Assignment Question PapersDocument13 pagesMba Ist Year Assignment Question PapersAbdul Muneer50% (2)
- TRIAL MATH M 950-2 2015 Jong SrawakDocument9 pagesTRIAL MATH M 950-2 2015 Jong SrawakmasyatiNo ratings yet
- Cot Act. 6Document7 pagesCot Act. 6FRECY MARZANNo ratings yet
- LS Dyna TutorialDocument16 pagesLS Dyna TutorialSumit SehgalNo ratings yet