Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5834)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
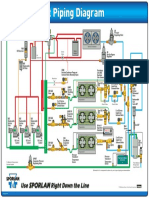
- HVACR Supermarket Piping DiagramDocument1 pageHVACR Supermarket Piping DiagramAngel sandovalNo ratings yet
- SECI Model-CKMDocument8 pagesSECI Model-CKMmanishadaaNo ratings yet
- TemplateReport PMSDocument42 pagesTemplateReport PMSmanishadaaNo ratings yet
- Final Ge Nine Cell MatrixDocument18 pagesFinal Ge Nine Cell Matrixmanishadaa100% (1)
- Intercultural Communication: Manish Hada Managerial Communication Mba-It 3 Batch Assignment-3Document1 pageIntercultural Communication: Manish Hada Managerial Communication Mba-It 3 Batch Assignment-3manishadaaNo ratings yet
- MUM Application Details Notes: Self StudyDocument1 pageMUM Application Details Notes: Self StudymanishadaaNo ratings yet
- Case Analysis (1 30)Document3 pagesCase Analysis (1 30)manishadaaNo ratings yet
- Ex8G Q9Document2 pagesEx8G Q9AlfredNo ratings yet
- Heat Transfer, Incopera 977 988Document12 pagesHeat Transfer, Incopera 977 988Rayhan HakimNo ratings yet
- FlareTot - Total Flare AnalysisDocument8 pagesFlareTot - Total Flare AnalysisArjun KapoorNo ratings yet
- C 143 - C 143M - 03 Slump TestDocument4 pagesC 143 - C 143M - 03 Slump TestHaris Alam100% (1)
- MS XP MythsDocument31 pagesMS XP MythsSandip GumtyaNo ratings yet
- Python Introduction: 1 Overview About Compiler, Practical PartDocument3 pagesPython Introduction: 1 Overview About Compiler, Practical PartRenas DareeshNo ratings yet
- Encrypt Your Data AssetsDocument353 pagesEncrypt Your Data AssetsSHAHID FAROOQNo ratings yet
- Regression Analysis: Model Building: Learning ObjectivesDocument38 pagesRegression Analysis: Model Building: Learning ObjectivesAnh DoNo ratings yet
- CHEG411 Chemical Reaction Engineeirng. F PDFDocument206 pagesCHEG411 Chemical Reaction Engineeirng. F PDFSarang GohNo ratings yet
- Optimization With Scilab: Michaël BAUDIN & Vincent COUVERTDocument52 pagesOptimization With Scilab: Michaël BAUDIN & Vincent COUVERTLazNgcengulaNo ratings yet
- Analog Communications Lab ManualDocument60 pagesAnalog Communications Lab ManualmailmeasddNo ratings yet
- Datastage To Run SAS CodeDocument66 pagesDatastage To Run SAS Codejbk1110% (1)
- Piping Erection (En)Document2 pagesPiping Erection (En)Izzet BozkurtNo ratings yet
- Bluetooth TrainingDocument1 pageBluetooth TrainingsyedtNo ratings yet
- J. R. Simonson (Auth.) - Engineering Heat Transfer-Palgrave Macmillan UK (1988)Document280 pagesJ. R. Simonson (Auth.) - Engineering Heat Transfer-Palgrave Macmillan UK (1988)Glasst Innovacion 2019100% (2)
- Self Checking TestbenchDocument5 pagesSelf Checking TestbenchEswaran SamyNo ratings yet
- Activity 2: Mathematical Modeling of Physical SystemsDocument10 pagesActivity 2: Mathematical Modeling of Physical SystemsNico SilorioNo ratings yet
- Extended Abstract Pankaj AroraLKKHIDocument10 pagesExtended Abstract Pankaj AroraLKKHIAidiaiem KhawaijNo ratings yet
- 3.5 ArchimedesDocument13 pages3.5 ArchimedesNURUL FAEZAH BINTI MUSTAPA MoeNo ratings yet
- Cambridge Ordinary LevelDocument20 pagesCambridge Ordinary Levelqsqt78jq6yNo ratings yet
- MS Paint ComputerDocument11 pagesMS Paint ComputerLiza JeonNo ratings yet
- Section I (Compulsory) Will Contain Short Answer: Class XDocument5 pagesSection I (Compulsory) Will Contain Short Answer: Class XGeorge Stephen TharakanNo ratings yet
- LCM: Lightweight Communications and Marshalling: Albert S. Huang, Edwin Olson, David C. MooreDocument6 pagesLCM: Lightweight Communications and Marshalling: Albert S. Huang, Edwin Olson, David C. Mooreinher1tanceNo ratings yet
- Computer Network - CS610 Power Point Slides Lecture 17Document22 pagesComputer Network - CS610 Power Point Slides Lecture 17Ibrahim ChoudaryNo ratings yet
- SPE-196769-MS - Burdakov, Wolcott - WAG Pilot Design and ResultsDocument15 pagesSPE-196769-MS - Burdakov, Wolcott - WAG Pilot Design and ResultsDonald WolcottNo ratings yet
- Ultra-Wideband Millimeter-Wave Dielectric Characteristics of Freshly Excised Normal and Malignant Human Skin TissuesDocument10 pagesUltra-Wideband Millimeter-Wave Dielectric Characteristics of Freshly Excised Normal and Malignant Human Skin TissuesDenis JaissonNo ratings yet
- Acer Aspire m1900Document6 pagesAcer Aspire m1900Ali MashduqiNo ratings yet
- Farasa: A Fast and Furious Segmenter For Arabic: June 2016Document7 pagesFarasa: A Fast and Furious Segmenter For Arabic: June 2016Fahd AhmedNo ratings yet
- Piezo Concept Strain GaugeDocument22 pagesPiezo Concept Strain GaugeAndika Surya HadiwinataNo ratings yet