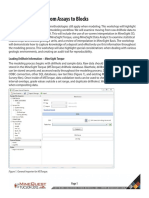
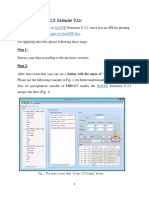
Download as pdf or txt
You might also like
- Lab 03 - Data Formats - Contrast Stretching - Density SlicingDocument11 pagesLab 03 - Data Formats - Contrast Stretching - Density SlicingANN SHALITANo ratings yet
- Data Spikes HiddenDocument13 pagesData Spikes HiddenhanakistNo ratings yet
- Epa Probit Analysis ProgramDocument5 pagesEpa Probit Analysis ProgramLuthfy Wulandari100% (1)
- Econometrics Pset #1Document5 pagesEconometrics Pset #1tarun singhNo ratings yet
- High-Low Method FormulasDocument3 pagesHigh-Low Method FormulasSabu VincentNo ratings yet
- Modeling A Multi-Seam Coal Reserve Using RockworksDocument10 pagesModeling A Multi-Seam Coal Reserve Using RockworksWahyudi KurniaNo ratings yet
- GEOPAK Terrain and Subsurface Modeling v8 1Document358 pagesGEOPAK Terrain and Subsurface Modeling v8 1Howard GibbonsNo ratings yet
- River2D Examples PDFDocument23 pagesRiver2D Examples PDFfrankie986No ratings yet
- AIM2000-a Program To Analyze and VisualizeDocument15 pagesAIM2000-a Program To Analyze and VisualizeNorberto MonteiroNo ratings yet
- Rock Topple User Manual 081127Document11 pagesRock Topple User Manual 081127Stephen HolleyNo ratings yet
- MIT 302 - Statistical Computing II - Tutorial 04Document7 pagesMIT 302 - Statistical Computing II - Tutorial 04evansojoshuzNo ratings yet
- Modeling Workflow PDFDocument25 pagesModeling Workflow PDFNurlanOruzievNo ratings yet
- Simren Dubey 2019450014Document7 pagesSimren Dubey 2019450014simran dubeyNo ratings yet
- An Example of Application of The Geostatistics Approach Using The GS+ SoftwareDocument17 pagesAn Example of Application of The Geostatistics Approach Using The GS+ SoftwareRossana CairaNo ratings yet
- Tsinghua Introduction To Big Data Systems hw8 QuestionDocument5 pagesTsinghua Introduction To Big Data Systems hw8 QuestionjovanhuangNo ratings yet
- Depth Map ManualDocument4 pagesDepth Map ManualJoost de BontNo ratings yet
- Chapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableDocument8 pagesChapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableAsiongMartinez12No ratings yet
- DEV Lecture Notes Unit IIDocument57 pagesDEV Lecture Notes Unit IIprins lNo ratings yet
- CE 701: Remote Sensing Technology Lab Exercise 2 Georeferencing, Georectification and MosaickingDocument6 pagesCE 701: Remote Sensing Technology Lab Exercise 2 Georeferencing, Georectification and MosaickingraaaaajjjjjNo ratings yet
- Ternarias Triangulo J.GDocument76 pagesTernarias Triangulo J.GAicrag JehisbellNo ratings yet
- Lab ManualDocument161 pagesLab ManualIam engineerNo ratings yet
- R Module 4Document42 pagesR Module 4NIDHISH SNo ratings yet
- Esse 3600Document15 pagesEsse 3600api-324911878100% (1)
- 22MSM40206 Data VisualisationDocument13 pages22MSM40206 Data Visualisationhejoj76652No ratings yet
- A Method For Slicing CAD Models in Binary STL Format IATS-libreDocument5 pagesA Method For Slicing CAD Models in Binary STL Format IATS-libreAnonymous AjEedIk81No ratings yet
- Messegeeproject 3 RDocument13 pagesMessegeeproject 3 Rapi-259928430No ratings yet
- A Visual Basic Program To Generate Sediment Grain-Size Statistics and To Extrapolate Particle DistributionsDocument5 pagesA Visual Basic Program To Generate Sediment Grain-Size Statistics and To Extrapolate Particle DistributionscokkyNo ratings yet
- Tutorial For Risa Educational: C.M. Uang and K.M. LeetDocument18 pagesTutorial For Risa Educational: C.M. Uang and K.M. LeetfabianoramiroNo ratings yet
- Composite Indicator Analysis and Optimization (CIAO) Tool: Codebook For PractitionersDocument11 pagesComposite Indicator Analysis and Optimization (CIAO) Tool: Codebook For PractitionersLuana LavagnoliNo ratings yet
- G.Projector User's Guide: Input Map ImagesDocument4 pagesG.Projector User's Guide: Input Map ImagesAnonymous C5CB5VRhNo ratings yet
- Só Linha de AmarrDocument72 pagesSó Linha de AmarrPaula NardiNo ratings yet
- R Graphics Chapter1Document22 pagesR Graphics Chapter1Juan David MartinNo ratings yet
- Chapter 3-Plotting With PyPlotDocument76 pagesChapter 3-Plotting With PyPlotAnjanaNo ratings yet
- Visibility TechniquesDocument5 pagesVisibility TechniquesArun GsNo ratings yet
- 1992 - A Method For Registration of 3-D Shapes - ICP - OKDocument18 pages1992 - A Method For Registration of 3-D Shapes - ICP - OKluongxuandanNo ratings yet
- Tutorial OpenPIVDocument7 pagesTutorial OpenPIVlgustavolucaNo ratings yet
- Saveetha Institute of Medical and Technical Sciences: Unit V Plotting and Regression Analysis in RDocument63 pagesSaveetha Institute of Medical and Technical Sciences: Unit V Plotting and Regression Analysis in RMuzakir Laikh KhanNo ratings yet
- SREPT: Software Reliability Estimation and Prediction Tool: User ManualDocument17 pagesSREPT: Software Reliability Estimation and Prediction Tool: User ManualLethal11No ratings yet
- Tri Plot - v1 4 2Document82 pagesTri Plot - v1 4 2Elvis Jesús Espíritu Espíritu100% (1)
- Computers & Geosciences Volume 29 Issue 5 2003 (Doi 10.1016/s0098-3004 (03) 00047-5) J.P. Conroy S.J. Radzevicius - Compact MATLAB Code For Displaying 3D GPR Data With TranslucenceDocument3 pagesComputers & Geosciences Volume 29 Issue 5 2003 (Doi 10.1016/s0098-3004 (03) 00047-5) J.P. Conroy S.J. Radzevicius - Compact MATLAB Code For Displaying 3D GPR Data With TranslucenceAbraham Raymundo Rebollo TapiaNo ratings yet
- MS ModeloDocument23 pagesMS ModeloAmy OlsonNo ratings yet
- Solución To Slice A STL FileDocument4 pagesSolución To Slice A STL FileelectroternalNo ratings yet
- Ejercicion Interpolacion ArcmapDocument13 pagesEjercicion Interpolacion Arcmaplebiatan89No ratings yet
- Camera CalibrationDocument5 pagesCamera CalibrationgeodesiikaNo ratings yet
- User Guide Gpec 2012 1Document27 pagesUser Guide Gpec 2012 1João GuilhermeNo ratings yet
- Dmiot School of Computing Software Engineering Academic ProgramDocument13 pagesDmiot School of Computing Software Engineering Academic ProgrammazengiyaNo ratings yet
- Introduction To Tecplot 10-1Document19 pagesIntroduction To Tecplot 10-1snehil2789No ratings yet
- Lecture 3Document19 pagesLecture 3Sahil AgarwalNo ratings yet
- Data Visualization Using MatplotlibDocument30 pagesData Visualization Using MatplotlibSureshNo ratings yet
- Depthmap: A Program To Perform Visibility Graph AnalysisDocument9 pagesDepthmap: A Program To Perform Visibility Graph AnalysisHelen Chavarria JaraNo ratings yet
- Descriptive StatisticsDocument27 pagesDescriptive StatisticsSaravjeet SinghNo ratings yet
- Ex 32012Document42 pagesEx 32012Meharu MulatuNo ratings yet
- Spatial Analysis ExerciseDocument46 pagesSpatial Analysis ExerciseMagda LenaNo ratings yet
- Image Processing by GRASS GISDocument65 pagesImage Processing by GRASS GISVan Anh TranNo ratings yet
- Contour and Heat Map Graphs by NetCDF Files PDFDocument7 pagesContour and Heat Map Graphs by NetCDF Files PDFAgriMetSoftNo ratings yet
- Gap FillDocument12 pagesGap FillAntonio J. Esteban CampuzanoNo ratings yet
- MSDA VariogramsDocument6 pagesMSDA VariogramsDavid Huamani Urpe100% (1)
- Mathematical Transformation of Data, Fit, and Graphic Representation of Regression Curves Through Computer ProgrammingDocument9 pagesMathematical Transformation of Data, Fit, and Graphic Representation of Regression Curves Through Computer ProgrammingJefferson NascimentoNo ratings yet
- DV Lab Manual 2022-23Document10 pagesDV Lab Manual 2022-23FS20IF015No ratings yet
- Drawing Graphs With Metapost: John D. HobbyDocument17 pagesDrawing Graphs With Metapost: John D. HobbymihaimiitNo ratings yet
- Computer Vision Graph Cuts: Exploring Graph Cuts in Computer VisionFrom EverandComputer Vision Graph Cuts: Exploring Graph Cuts in Computer VisionNo ratings yet
- Geometric Primitive: Exploring Foundations and Applications in Computer VisionFrom EverandGeometric Primitive: Exploring Foundations and Applications in Computer VisionNo ratings yet
- Scanline Rendering: Exploring Visual Realism Through Scanline Rendering TechniquesFrom EverandScanline Rendering: Exploring Visual Realism Through Scanline Rendering TechniquesNo ratings yet
- Reliability: Case Processing SummaryDocument7 pagesReliability: Case Processing SummaryEka TamaNo ratings yet
- Jurnal Desy Sofita EDITDocument8 pagesJurnal Desy Sofita EDITade syuraNo ratings yet
- Multiple RegressionDocument57 pagesMultiple RegressionChristian Alfred VillenaNo ratings yet
- SarimaDocument7 pagesSarimaNiiken UlhaqNo ratings yet
- What Is LASSO Regression Definition, Examples and TechniquesDocument15 pagesWhat Is LASSO Regression Definition, Examples and TechniquesSudip SinghNo ratings yet
- Solved Practice Questions Lecture 32-34Document8 pagesSolved Practice Questions Lecture 32-34Fun NNo ratings yet
- TitanicDocument13 pagesTitanicapi-579641772100% (2)
- University of Mumbai: Examinations Summer 2022 Quantitative AnalysisDocument3 pagesUniversity of Mumbai: Examinations Summer 2022 Quantitative AnalysisSURABHI NAIK192074No ratings yet
- Weak IVDocument7 pagesWeak IVKennNo ratings yet
- Aparna Rathi SC E: Electronics & Radar Development Establishment (LRDE)Document91 pagesAparna Rathi SC E: Electronics & Radar Development Establishment (LRDE)muvin236No ratings yet
- Module 6 - ExcelDocument9 pagesModule 6 - ExcelNiharika MathurNo ratings yet
- Linear Regression and Neural Networks: COMP3314 - Week 5Document34 pagesLinear Regression and Neural Networks: COMP3314 - Week 5marcelNo ratings yet
- X y S R: Name: - Period: - Row: - Date: - Homework 9Document3 pagesX y S R: Name: - Period: - Row: - Date: - Homework 9Emily DicksonNo ratings yet
- Topic 6 HeteroscedasticityDocument15 pagesTopic 6 HeteroscedasticityRaghunandana RajaNo ratings yet
- Regression and CorrelationDocument12 pagesRegression and CorrelationAbdul RehmanNo ratings yet
- Textbook Mathematical Theory of Bayesian Statistics First Edition Watanabe Ebook All Chapter PDFDocument53 pagesTextbook Mathematical Theory of Bayesian Statistics First Edition Watanabe Ebook All Chapter PDFjames.landford380100% (12)
- Statistical Analysis With Software Application Assessment No. 6Document1 pageStatistical Analysis With Software Application Assessment No. 6Maria Kathreena Andrea AdevaNo ratings yet
- Partial Least Squares Path ModelingDocument2 pagesPartial Least Squares Path ModelingGatuzNo ratings yet
- Chapter 5 - Cost EstimationDocument45 pagesChapter 5 - Cost EstimationWalid Marhaba100% (1)
- Generalized Linear ModelsDocument12 pagesGeneralized Linear ModelsAndika AfriansyahNo ratings yet
- Nonlinear Relationships: Y X X X X EYXDocument23 pagesNonlinear Relationships: Y X X X X EYXEmmanuella EmefeNo ratings yet
- Chapter 6Document33 pagesChapter 6jun del rosarioNo ratings yet
- Influence Maximization Via MartingalesDocument21 pagesInfluence Maximization Via Martingales蔡于飛No ratings yet
- 261 PDFDocument2 pages261 PDFRere UtamiNo ratings yet
- Asymptotic VarianceDocument6 pagesAsymptotic VarianceSiyaBNo ratings yet
- ARIMA Models in Python Chapter2Document43 pagesARIMA Models in Python Chapter2FgpeqwNo ratings yet