Download as pdf or txt
You might also like
- Finessing Fixed DividendsDocument2 pagesFinessing Fixed DividendsVeeken Chaglassian100% (2)
- Iso 21501-4 2007Document24 pagesIso 21501-4 2007monttoyayoNo ratings yet
- Teaching Note 98-02: Approximation of American Option Values: Barone-Adesi-WhaleyDocument4 pagesTeaching Note 98-02: Approximation of American Option Values: Barone-Adesi-WhaleyVeeken ChaglassianNo ratings yet
- The Vol Smile Problem - FX FocusDocument5 pagesThe Vol Smile Problem - FX FocusVeeken ChaglassianNo ratings yet
- Smile Dynamics II: Option PricingDocument7 pagesSmile Dynamics II: Option PricingVeeken ChaglassianNo ratings yet
- Module 5 - Stat. - Prob.Document4 pagesModule 5 - Stat. - Prob.Nicole MendozaNo ratings yet
- 1-Chap II Econometrics ABC DR MitikuDocument80 pages1-Chap II Econometrics ABC DR MitikuMewded DelelegnNo ratings yet
- Lecture 2. Simple Linear RegressionDocument49 pagesLecture 2. Simple Linear RegressionAnwar TemamNo ratings yet
- Handout 1Document16 pagesHandout 1pobisas812No ratings yet
- Structural Macroeconometrics: David N. Dejong Chetan DaveDocument31 pagesStructural Macroeconometrics: David N. Dejong Chetan Davejai_haas06No ratings yet
- Ch3 Slides Ed4 2024Document72 pagesCh3 Slides Ed4 2024ann1172002No ratings yet
- SSP Notes PDFDocument125 pagesSSP Notes PDFsandeepdevasriiNo ratings yet
- Elg 3126Document6 pagesElg 3126Serigne Saliou Mbacke SourangNo ratings yet
- Fokker-Planck - and Langevin EquatDocument16 pagesFokker-Planck - and Langevin Equatmarkus.aureliusNo ratings yet
- Statistical MethodDocument227 pagesStatistical Methodmaria sanjaiNo ratings yet
- Statistics For ManagememtDocument152 pagesStatistics For Managememttowfik sefaNo ratings yet
- 04 BasisDocument8 pages04 BasishariNo ratings yet
- Mathematical Association of AmericaDocument4 pagesMathematical Association of AmericaMonal BhoyarNo ratings yet
- Ch3 Slides Ed4 March2021Document75 pagesCh3 Slides Ed4 March2021Phuc Hong PhamNo ratings yet
- Fuzzy Rules and ReasoningDocument18 pagesFuzzy Rules and ReasoningKavitha PNo ratings yet
- Probability & Stats NotesDocument17 pagesProbability & Stats Notesjerry veraNo ratings yet
- Chapter 3Document35 pagesChapter 3Betty TesfayeNo ratings yet
- Roots of EquationsDocument31 pagesRoots of EquationsGzim RamadaniNo ratings yet
- Contraction PDFDocument27 pagesContraction PDFMauriNo ratings yet
- Lab 5: Nonlinear Systems: GoalsDocument5 pagesLab 5: Nonlinear Systems: GoalsVinodhini RavikumarNo ratings yet
- Slides Session 4Document135 pagesSlides Session 4Adarsh AgrawalNo ratings yet
- Semi-Detailed Lesson Plan in Statistics and Probability I. ObjectivesDocument5 pagesSemi-Detailed Lesson Plan in Statistics and Probability I. ObjectivesJeson N. Rondina100% (2)
- Sri Vidya College of Engineering and Technology, Virudhunagar Course Material (Question Bank)Document4 pagesSri Vidya College of Engineering and Technology, Virudhunagar Course Material (Question Bank)David MillerNo ratings yet
- Roots of Equations: Bracketing MethodsDocument30 pagesRoots of Equations: Bracketing MethodsHassaan ShahNo ratings yet
- MulticollinearityDocument36 pagesMulticollinearitymath.atha.officialNo ratings yet
- Point Estimation: Statistics (MAST20005) & Elements of Statistics (MAST90058) Semester 2, 2018Document12 pagesPoint Estimation: Statistics (MAST20005) & Elements of Statistics (MAST90058) Semester 2, 2018Anonymous na314kKjOANo ratings yet
- Chapter 9Document5 pagesChapter 9Dhynelle MuycoNo ratings yet
- Chapter 1Document27 pagesChapter 1Bereket Desalegn0% (1)
- Skiwness and KurosisDocument28 pagesSkiwness and Kurosishulyoortiz26No ratings yet
- Modelos Discretos en Matemáticas AplicadasDocument22 pagesModelos Discretos en Matemáticas AplicadasEddy LizarazuNo ratings yet
- Newtons Method CyclesDocument25 pagesNewtons Method CyclesSamNo ratings yet
- Complement Os 008Document17 pagesComplement Os 008juanxmanuelNo ratings yet
- An Introduction To Fuzzy ControlDocument27 pagesAn Introduction To Fuzzy Controldali ramsNo ratings yet
- Spring 2012 Statistics 153 Lecture FiveDocument6 pagesSpring 2012 Statistics 153 Lecture FiveShubham GanvirNo ratings yet
- Stochastic Methods in Finance: Lecture Notes For STAT3006 / STATG017Document26 pagesStochastic Methods in Finance: Lecture Notes For STAT3006 / STATG017doomriderNo ratings yet
- HW 1Document5 pagesHW 1tt_aljobory3911No ratings yet
- AA SL - Unit 4a - Limits and Differential CalculusDocument65 pagesAA SL - Unit 4a - Limits and Differential CalculusSamiha DuzaNo ratings yet
- TEXTDocument9 pagesTEXTsharma.patanjaliNo ratings yet
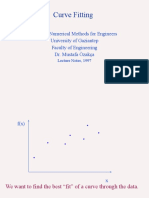
- Curve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaDocument171 pagesCurve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaAbdullah Emirhan AydınNo ratings yet
- Matrix Algebra For Beginners, Part III The Matrix ExponentialDocument9 pagesMatrix Algebra For Beginners, Part III The Matrix ExponentialPhine-hasNo ratings yet
- Chapter 5Document45 pagesChapter 5FitsumNo ratings yet
- A Random Variable Is A Variable Whose Possible Values Are Numerical Outcomes of A Random Phenomenon/experimentDocument21 pagesA Random Variable Is A Variable Whose Possible Values Are Numerical Outcomes of A Random Phenomenon/experimentfathimathNo ratings yet
- 7CCMMS61 Statistics For Data Analysis: Francisco Javier Rubio Department of MathematicsDocument13 pages7CCMMS61 Statistics For Data Analysis: Francisco Javier Rubio Department of MathematicsViorel AdirvaNo ratings yet
- PHN 311 Lectures On InterpolationDocument42 pagesPHN 311 Lectures On InterpolationJay RashamiyaNo ratings yet
- CS221 - Artificial Intelligence - Machine Learning - 6 Non-Linear FeaturesDocument22 pagesCS221 - Artificial Intelligence - Machine Learning - 6 Non-Linear FeaturesArdiansyah Mochamad NugrahaNo ratings yet
- Chapter 3 - Discrete Radom Variables and Probability DistributionDocument70 pagesChapter 3 - Discrete Radom Variables and Probability DistributionTran Minh Nhut (K17 HCM)No ratings yet
- Regression Analysis: Advanced Research MethadologyDocument44 pagesRegression Analysis: Advanced Research MethadologysohailNo ratings yet
- Visco-Bresse 27 July 19Document21 pagesVisco-Bresse 27 July 19Wael YoussefNo ratings yet
- Chapter04 ConvolutionDocument13 pagesChapter04 ConvolutionMimansa SipolyaNo ratings yet
- EN530.678 Nonlinear Control and Planning in Robotics Lecture 3: Stability February 3, 2020Document12 pagesEN530.678 Nonlinear Control and Planning in Robotics Lecture 3: Stability February 3, 2020SAYED JAVED ALI SHAHNo ratings yet
- Apsp1 PDFDocument22 pagesApsp1 PDFJingwei ChenNo ratings yet
- 1 Probability DistributionDocument24 pages1 Probability DistributionDominic AguirreNo ratings yet
- Transelliptical Component Analysis: Johns Hopkins University Princeton UniversityDocument26 pagesTranselliptical Component Analysis: Johns Hopkins University Princeton UniversitybobmezzNo ratings yet
- Lecture-13 - ESO208 - Aug 31 - 2022Document28 pagesLecture-13 - ESO208 - Aug 31 - 2022Imad ShaikhNo ratings yet
- One Dimensional FlowsDocument19 pagesOne Dimensional FlowsBhawan NarineNo ratings yet
- Chapter 3Document39 pagesChapter 3api-3729261No ratings yet
- Unit 5 Random Variables: StructureDocument20 pagesUnit 5 Random Variables: StructureNikita SabaleNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- Binomial BSconvergenceDocument10 pagesBinomial BSconvergenceVeeken ChaglassianNo ratings yet
- Murakami QuotesDocument2 pagesMurakami QuotesVeeken ChaglassianNo ratings yet
- Teaching Note 98-01: Closed-Form American Call Option Pricing: Roll-Geske-WhaleyDocument8 pagesTeaching Note 98-01: Closed-Form American Call Option Pricing: Roll-Geske-WhaleyVeeken ChaglassianNo ratings yet
- Teaching Note 97-08: Pricing and Valuation of Commodity SwapsDocument13 pagesTeaching Note 97-08: Pricing and Valuation of Commodity SwapsVeeken ChaglassianNo ratings yet
- Teaching Note 96-01: Default Risk As An Option: Version Date: November 3, 2003 C:/Classbackup/Teaching Notes/Tn96-01.WpdDocument5 pagesTeaching Note 96-01: Default Risk As An Option: Version Date: November 3, 2003 C:/Classbackup/Teaching Notes/Tn96-01.WpdVeeken ChaglassianNo ratings yet
- Teaching Note 00-04: Girsanov'S Theorem in Derivative PricingDocument16 pagesTeaching Note 00-04: Girsanov'S Theorem in Derivative PricingVeeken ChaglassianNo ratings yet
- Teaching Note 96-02: Risk Neutral Pricing in Discrete TimeDocument4 pagesTeaching Note 96-02: Risk Neutral Pricing in Discrete TimeVeeken ChaglassianNo ratings yet
- Teaching Note 00-01: Linear Homogeneity, Euler'S Rule, The Black-Scholes Model, and An Application To Forward Start OptionsDocument6 pagesTeaching Note 00-01: Linear Homogeneity, Euler'S Rule, The Black-Scholes Model, and An Application To Forward Start OptionsVeeken ChaglassianNo ratings yet
- Tn99-01: Solving Linear Equations in Excel: Version Date: February 3, 1999 C:/Class/TN99-01.wpdDocument4 pagesTn99-01: Solving Linear Equations in Excel: Version Date: February 3, 1999 C:/Class/TN99-01.wpdVeeken ChaglassianNo ratings yet
- Data Mining in Finance: B20.3355 / B90.3355: Intensive Methods For Financial Modeling and Data AnalysisDocument14 pagesData Mining in Finance: B20.3355 / B90.3355: Intensive Methods For Financial Modeling and Data AnalysisVeeken ChaglassianNo ratings yet
- Overviewof Option Strategies 1Document6 pagesOverviewof Option Strategies 1Veeken ChaglassianNo ratings yet
- Stats 242: Algorithmic Trading and Quantitative Strategies Summer 2011Document9 pagesStats 242: Algorithmic Trading and Quantitative Strategies Summer 2011Veeken ChaglassianNo ratings yet
- Topics: Convexity Immunization by Matching Convexity in Addition To DurationDocument8 pagesTopics: Convexity Immunization by Matching Convexity in Addition To DurationVeeken ChaglassianNo ratings yet
- A Discrete Question (Divs)Document2 pagesA Discrete Question (Divs)Veeken ChaglassianNo ratings yet
- Dumas - Fleming - Whaley - 95 - Loval Vol TestsDocument31 pagesDumas - Fleming - Whaley - 95 - Loval Vol TestsVeeken ChaglassianNo ratings yet
- New Products, New Risks: Equity DerivativesDocument4 pagesNew Products, New Risks: Equity DerivativesVeeken ChaglassianNo ratings yet
- Implied Binomial Trees From The Historical DistributionDocument29 pagesImplied Binomial Trees From The Historical DistributionVeeken ChaglassianNo ratings yet
- Default Rate by Underwriter: Cibc Performs BestDocument22 pagesDefault Rate by Underwriter: Cibc Performs BestVeeken ChaglassianNo ratings yet
- Economics of Finance (U6022) Homework Assignment #2 Tracking A Hedged Options Portfolio Over Time Due: October 23, 2002Document3 pagesEconomics of Finance (U6022) Homework Assignment #2 Tracking A Hedged Options Portfolio Over Time Due: October 23, 2002Veeken ChaglassianNo ratings yet
- Catch-Up Could Make Spread More Palatable: The Weekly Publication of High Yield Strategy February 27, 2004 Vol. 2, No. 9Document19 pagesCatch-Up Could Make Spread More Palatable: The Weekly Publication of High Yield Strategy February 27, 2004 Vol. 2, No. 9Veeken ChaglassianNo ratings yet
- Market Mechanics PDFDocument14 pagesMarket Mechanics PDFVeeken ChaglassianNo ratings yet
- Asymptotics and Calibration of Local Volatility Models PDFDocument9 pagesAsymptotics and Calibration of Local Volatility Models PDFVeeken ChaglassianNo ratings yet
- Keep Your Eyes On The Size: The Weekly Publication of High Yield Strategy February 13, 2004 Vol. 2, No. 7Document21 pagesKeep Your Eyes On The Size: The Weekly Publication of High Yield Strategy February 13, 2004 Vol. 2, No. 7Veeken ChaglassianNo ratings yet
- The Role of Short Sellers in The Marketplace: Executive SummaryDocument8 pagesThe Role of Short Sellers in The Marketplace: Executive SummaryVeeken ChaglassianNo ratings yet
- Time Series LectureDocument14 pagesTime Series LectureVeeken ChaglassianNo ratings yet
- JPM CDS vs. Bonds-1999-12-2Document4 pagesJPM CDS vs. Bonds-1999-12-2Veeken ChaglassianNo ratings yet
- Design and Analysis of Experiments: Tropical Animal Feeding: A Manual For Research WorkersDocument26 pagesDesign and Analysis of Experiments: Tropical Animal Feeding: A Manual For Research WorkerspepeNo ratings yet
- 40 Multiple Choice Questions in Basic StatisticsDocument38 pages40 Multiple Choice Questions in Basic StatisticsLokmaniNo ratings yet
- A. Chapter 11 (SD) - UDocument112 pagesA. Chapter 11 (SD) - UErasmo IñiguezNo ratings yet
- Practical Bayesian InferenceDocument322 pagesPractical Bayesian InferenceSinisa Hristov100% (1)
- MLE and MAP ClassifierDocument55 pagesMLE and MAP ClassifierSupriyo ChakmaNo ratings yet
- Two-Sample Hypothesis TestsDocument56 pagesTwo-Sample Hypothesis TestsNgan Duong Nguyen ThanhNo ratings yet
- Serviceability Floor Loads: Division of Structural Engineering, Lund University, Box 118, SE-221 00 Lund, SwedenDocument20 pagesServiceability Floor Loads: Division of Structural Engineering, Lund University, Box 118, SE-221 00 Lund, SwedenEr. Hisham Ajmal PCNo ratings yet
- Mock Exam 4Document62 pagesMock Exam 4pagis31861No ratings yet
- Binomial DistributionDocument2 pagesBinomial DistributionChow PohlingNo ratings yet
- Metastock Formulas PDFDocument9 pagesMetastock Formulas PDFZvi OrenNo ratings yet
- Module #4 Hand in Assignment: Grade Probability 80 .15 70 .25 60 .25 50 .20 40 .15Document1 pageModule #4 Hand in Assignment: Grade Probability 80 .15 70 .25 60 .25 50 .20 40 .15CarlosNo ratings yet
- Gender DifferencesDocument10 pagesGender DifferencesShaeeb Mohd KhandayNo ratings yet
- WAIS-R Subtest Scatter: Base-Rate Data From A Healthy UK SampleDocument13 pagesWAIS-R Subtest Scatter: Base-Rate Data From A Healthy UK SampleNikola PekićNo ratings yet
- CHAPTER 2: Data Collection and Basic Concepts in Sampling DesignDocument14 pagesCHAPTER 2: Data Collection and Basic Concepts in Sampling DesignDominique Anne BenozaNo ratings yet
- S. Sampling DistributionDocument28 pagesS. Sampling DistributionBrian GarciaNo ratings yet
- 9709 s12 QP 61 PDFDocument4 pages9709 s12 QP 61 PDFVeronica MardonesNo ratings yet
- Statistik IifDocument9 pagesStatistik IifMauidzotussyarifahNo ratings yet
- Sampling Distribution (Assignment 2)Document2 pagesSampling Distribution (Assignment 2)Feroz khan0% (1)
- Quantitative Methods: Section-BDocument52 pagesQuantitative Methods: Section-BKamesh VijayabaskaranNo ratings yet
- Mean, Variance and SDDocument2 pagesMean, Variance and SDGelyn Forteza CataloniaNo ratings yet
- ADDB Week 5Document66 pagesADDB Week 5Khayandra SalsabilaNo ratings yet
- 4.2 Confidence Intervals For The MeanDocument9 pages4.2 Confidence Intervals For The MeanTheory SummersNo ratings yet
- Measures of Variability - V &SD (Grouped)Document3 pagesMeasures of Variability - V &SD (Grouped)Clara ColocadoNo ratings yet
- HW 02 220Document3 pagesHW 02 220zhang JayantNo ratings yet
- Stat 97Document10 pagesStat 97Ahmed Kadem ArabNo ratings yet
- Cooperative Learning Based Learning Plan in Grade 7 MathematicsDocument12 pagesCooperative Learning Based Learning Plan in Grade 7 MathematicsLemerie GepitulanNo ratings yet
- Chapter 9 - QuestionsDocument5 pagesChapter 9 - QuestionshrfjbjrfrfNo ratings yet
- Statistical Computing Seminars Introduction To Stata ProgrammingDocument26 pagesStatistical Computing Seminars Introduction To Stata ProgrammingAkolgo PaulinaNo ratings yet
- Traditional Hypothesis Testing Using ZDocument7 pagesTraditional Hypothesis Testing Using ZMarvin Yebes ArceNo ratings yet