Download as pdf or txt
You might also like
- (Courant Lecture Notes) S. R. S. Varadhan - Probability Theory-Amer Mathematical Society (2001) PDFDocument178 pages(Courant Lecture Notes) S. R. S. Varadhan - Probability Theory-Amer Mathematical Society (2001) PDFAmanda EdwardsNo ratings yet
- (Springer Finance) Monique Jeanblanc, Marc Yor, Marc Chesney (Auth.) - Mathematical Methods For Financial Markets (2009, Springer-Verlag London) PDFDocument752 pages(Springer Finance) Monique Jeanblanc, Marc Yor, Marc Chesney (Auth.) - Mathematical Methods For Financial Markets (2009, Springer-Verlag London) PDFАрсен Тирчик100% (1)
- Final Schedule RORES 1 7Document1 pageFinal Schedule RORES 1 7AMITPALNo ratings yet
- Final Schedule RORES 1 7Document1 pageFinal Schedule RORES 1 7AMITPALNo ratings yet
- Kalyana C. Veluvolu: Associate ProfessorDocument18 pagesKalyana C. Veluvolu: Associate ProfessorSports CornerNo ratings yet
- Introduction HP - HandoutsDocument37 pagesIntroduction HP - HandoutsPuviyarasan MNo ratings yet
- A Course On Statistics For Finance: Journal of Applied Statistics April 2014Document4 pagesA Course On Statistics For Finance: Journal of Applied Statistics April 2014Ankush Kumar YedeNo ratings yet
- Suprava ProfileDocument9 pagesSuprava ProfileChetna ShahNo ratings yet
- Addressing The Forgotten Art of Fundoscopy ': Evaluation of A Novel Teaching OphthalmoscopeDocument10 pagesAddressing The Forgotten Art of Fundoscopy ': Evaluation of A Novel Teaching OphthalmoscopeWalisson 5No ratings yet
- Jurnal Inter ErlinDocument20 pagesJurnal Inter ErlinErlina AzmiNo ratings yet
- Image ProcessingDocument70 pagesImage ProcessingHanish LakshanNo ratings yet
- Robotic Process Automation - V1Document2 pagesRobotic Process Automation - V1Manoj ReddyNo ratings yet
- Statistical Physics Approach To Dendritic Computation: The Excitable-Wave Mean-Field ApproximationDocument25 pagesStatistical Physics Approach To Dendritic Computation: The Excitable-Wave Mean-Field ApproximationKrishna DasNo ratings yet
- DetailedSchedule ICONCT09Document13 pagesDetailedSchedule ICONCT09surendiranNo ratings yet
- Hoog 2020Document4 pagesHoog 2020juliopanzNo ratings yet
- Suyogduttjain CVDocument3 pagesSuyogduttjain CVsuyogdjainNo ratings yet
- Fuhl Geisler Santini CBF Circular Binary Features For Robust Real-Time Pupil Center Detection ACM 2018Document6 pagesFuhl Geisler Santini CBF Circular Binary Features For Robust Real-Time Pupil Center Detection ACM 2018tamas.ingridNo ratings yet
- Pratira2024 - Brochure & InvitationDocument3 pagesPratira2024 - Brochure & InvitationM SureshNo ratings yet
- Pallav Ranka - CV PDFDocument2 pagesPallav Ranka - CV PDFAnonymous UxL8HXQ0HNo ratings yet
- DR Poornaiah BillaDocument3 pagesDR Poornaiah BillaSai kumarNo ratings yet
- Fuhl Santini PupilNet Convolutional Neural NetworksDocument10 pagesFuhl Santini PupilNet Convolutional Neural Networksingrid.joraNo ratings yet
- The Role of Visual Representation in Physics Learning: Dynamic Versus Static VisualizationDocument8 pagesThe Role of Visual Representation in Physics Learning: Dynamic Versus Static VisualizationErgi BufasiNo ratings yet
- Smartphone Ophthalmoscope As A Tool in Teaching Direct Ophthalmoscopy: A Crossover Randomized Controlled TrialDocument9 pagesSmartphone Ophthalmoscope As A Tool in Teaching Direct Ophthalmoscopy: A Crossover Randomized Controlled TrialWalisson BarbosaNo ratings yet
- AI Workshop - BrochureDocument2 pagesAI Workshop - Brochurevasavi kNo ratings yet
- Full Chapter Practice of Bayesian Probability Theory in Geotechnical Engineering Wan Huan Zhou PDFDocument53 pagesFull Chapter Practice of Bayesian Probability Theory in Geotechnical Engineering Wan Huan Zhou PDFdavid.swanson240100% (6)
- FDP-JNTUA - Online ScheduleDocument2 pagesFDP-JNTUA - Online ScheduleDamodara ReddyNo ratings yet
- Kalees Resume 07.09.2017Document6 pagesKalees Resume 07.09.2017Kaleeswaran DevarajNo ratings yet
- CV ShobanaDocument4 pagesCV ShobanashobanaNo ratings yet
- Workshop Antennas ECEDocument2 pagesWorkshop Antennas ECESCHOLARSHIP BIEWNo ratings yet
- Sa Ii - FDP - BrochureDocument2 pagesSa Ii - FDP - BrochureVaishaliNo ratings yet
- Bio Sketch ofDocument2 pagesBio Sketch ofMikhailNo ratings yet
- Curriculum Vitae: Professor and HeadDocument13 pagesCurriculum Vitae: Professor and Headhusain rizviNo ratings yet
- Fnhum 09 00716Document6 pagesFnhum 09 00716Monica Arellano LlacsaNo ratings yet
- Decision Tree Based Depression Classicationfrom Audio Videoand Language InformationDocument9 pagesDecision Tree Based Depression Classicationfrom Audio Videoand Language Informationalvee rohanNo ratings yet
- Resume: Tamilnadu Government Best Employee of The State Gold Medalist - 2015Document130 pagesResume: Tamilnadu Government Best Employee of The State Gold Medalist - 2015Hodcse FxecNo ratings yet
- Seminar ReportDocument18 pagesSeminar ReporttechieagarwalNo ratings yet
- Foodarom Cover LetterDocument4 pagesFoodarom Cover LetterVictor AceroNo ratings yet
- Proceedings of Spie: Simulation and Visualization of Fundamental Optics Phenomenon by LabviewDocument7 pagesProceedings of Spie: Simulation and Visualization of Fundamental Optics Phenomenon by LabviewDavid Hinostroza VargasNo ratings yet
- FDP On Artificial Intelligence and Machine Learning 8.1.2024 To 13.1.2024Document3 pagesFDP On Artificial Intelligence and Machine Learning 8.1.2024 To 13.1.2024janakNo ratings yet
- Baylor College of Medicine Cover LetterDocument4 pagesBaylor College of Medicine Cover LetterVictor AceroNo ratings yet
- Uploads Big 20170812091155 CvravishankarDocument4 pagesUploads Big 20170812091155 Cvravishankargautamkr15No ratings yet
- Design and Implementation of A Movie Reservation SystemDocument7 pagesDesign and Implementation of A Movie Reservation SystemObi KingsleyNo ratings yet
- Chao TianDocument17 pagesChao TianAllez InwunderNo ratings yet
- Erfan 2020 J. Phys. Conf. Ser. 1471 012061Document7 pagesErfan 2020 J. Phys. Conf. Ser. 1471 012061tuti suoriyantiNo ratings yet
- Faculty Development Programme: Rcret20Document2 pagesFaculty Development Programme: Rcret20SINGARAVELAN ANo ratings yet
- 01 Days ST Training Program 16112021 Insu Audit of Power Plant & Process IndDocument4 pages01 Days ST Training Program 16112021 Insu Audit of Power Plant & Process IndInvincible 2.0No ratings yet
- A Coupled-Lines System To Determine The Anteroposterior Position of Maxillary Central Incisors For Smiling Profile EstheticsDocument11 pagesA Coupled-Lines System To Determine The Anteroposterior Position of Maxillary Central Incisors For Smiling Profile EstheticsRoberto OlaveNo ratings yet
- Research Project AbstractsDocument20 pagesResearch Project AbstractsGnanavel GNo ratings yet
- Imaging TechniquesDocument136 pagesImaging TechniquessastfNo ratings yet
- FDP AI InvitationDocument1 pageFDP AI InvitationniranjanNo ratings yet
- Sagar Simha K T - EceDocument2 pagesSagar Simha K T - Ecesagar simhaNo ratings yet
- ConferenceDocument3 pagesConferencekarthikkumarenNo ratings yet
- Theme Du PFEDocument2 pagesTheme Du PFEtinanourNo ratings yet
- Resume Ms K.deebaDocument5 pagesResume Ms K.deebaanandNo ratings yet
- A Combined Brain-Computer Interface Based On P300 Potentials and Motion-Onset Visual Evoked PotentialsDocument12 pagesA Combined Brain-Computer Interface Based On P300 Potentials and Motion-Onset Visual Evoked PotentialsCristina RacoareNo ratings yet
- STTP - Slot 2 - SchduleDocument1 pageSTTP - Slot 2 - Schdulepriya dharshiniNo ratings yet
- Face Mask Detection Using Deep CNNS: Prof. Ashwini KulkarniDocument67 pagesFace Mask Detection Using Deep CNNS: Prof. Ashwini KulkarniShruti DeshmukhNo ratings yet
- MATH 353 - StatisticsDocument212 pagesMATH 353 - Statisticsprincesskaydee555No ratings yet
- JPM 12 00387Document14 pagesJPM 12 00387sghNo ratings yet
- 3OBuried Energy For Conservation and Energy Management SEPTDocument7 pages3OBuried Energy For Conservation and Energy Management SEPTmmmNo ratings yet
- Mid-Term Project ReportDocument40 pagesMid-Term Project ReportKasturi SonawaneNo ratings yet
- Improving Accessible Digital Practices in Higher Education: Challenges and New Practices for InclusionFrom EverandImproving Accessible Digital Practices in Higher Education: Challenges and New Practices for InclusionNo ratings yet
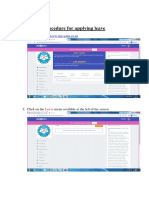
- Procedure For Applying Leave, ONDuty and Medical LeaveDocument6 pagesProcedure For Applying Leave, ONDuty and Medical LeavejollyggNo ratings yet
- ICASET2022 BroucherDocument16 pagesICASET2022 BroucherjollyggNo ratings yet
- Uncertainty and Bayesian Networks: Chapter 13, 14.1-2Document35 pagesUncertainty and Bayesian Networks: Chapter 13, 14.1-2jollyggNo ratings yet
- Malla Reddy College of Engineering & Technology B. Tech-Iii - Year - I - Sem - It L T/P/D C 3 - /-/ - 3 (R20Axxxx) Artificial IntelligenceDocument2 pagesMalla Reddy College of Engineering & Technology B. Tech-Iii - Year - I - Sem - It L T/P/D C 3 - /-/ - 3 (R20Axxxx) Artificial IntelligencejollyggNo ratings yet
- Full Version Is HEREDocument4 pagesFull Version Is HEREjollyggNo ratings yet
- Fundamentals of Artificial Intelligence: Intelligent AgentsDocument19 pagesFundamentals of Artificial Intelligence: Intelligent AgentsjollyggNo ratings yet
- Artificial Intelligence: Constraint Satisfaction ProblemsDocument34 pagesArtificial Intelligence: Constraint Satisfaction ProblemsjollyggNo ratings yet
- Uncertainty (Chapter 13, Russell & Norvig)Document41 pagesUncertainty (Chapter 13, Russell & Norvig)jollyggNo ratings yet
- Uncertainty: Chapter 13, Sections 1-6Document31 pagesUncertainty: Chapter 13, Sections 1-6jollyggNo ratings yet
- 2179-Article Text-2758-1-10-20090202 PDFDocument10 pages2179-Article Text-2758-1-10-20090202 PDFjollyggNo ratings yet
- Cabalar KRDocument218 pagesCabalar KRjollyggNo ratings yet
- Malla Reddy College of Engineering & Technology Autonomous Institution - UGC, Govt of IndiaDocument1 pageMalla Reddy College of Engineering & Technology Autonomous Institution - UGC, Govt of IndiajollyggNo ratings yet
- Iv-I Cse Question Bank - R15Document53 pagesIv-I Cse Question Bank - R15jollyggNo ratings yet
- WWW - Isr.umd - Edu Austin Ense621.d Projects04.d Project-Food-OrderingDocument46 pagesWWW - Isr.umd - Edu Austin Ense621.d Projects04.d Project-Food-OrderingjollyggNo ratings yet
- National Talent Search Examination 2015 Stage 2: Answer KeyDocument1 pageNational Talent Search Examination 2015 Stage 2: Answer KeyjollyggNo ratings yet
- 2020 Bbac 312 Bba 241 A2Document5 pages2020 Bbac 312 Bba 241 A2MH MuntuwabantuNo ratings yet
- Chapter5: Joint Probability DistributionsDocument39 pagesChapter5: Joint Probability DistributionsVidya MalavNo ratings yet
- Simulation in FinanceDocument62 pagesSimulation in FinanceraviNo ratings yet
- Topic 1 Notes PDFDocument25 pagesTopic 1 Notes PDFNkhandu S M WilliamsNo ratings yet
- Complete ProbabilityDocument19 pagesComplete ProbabilityAditya KumarNo ratings yet
- Syllabus - Math 101 (12-13)Document1 pageSyllabus - Math 101 (12-13)Honorato G. Perez IIINo ratings yet
- Random Variables: Complete Business Statistics, 8/e Instructor's Solutions Manual, Chapter 3Document33 pagesRandom Variables: Complete Business Statistics, 8/e Instructor's Solutions Manual, Chapter 3DeepanshGoyalNo ratings yet
- ET4060 Fundamentals of Data Communication Networks Lecture 06Document35 pagesET4060 Fundamentals of Data Communication Networks Lecture 06Loc DoNo ratings yet
- 02-Random VariablesDocument38 pages02-Random Variablesmilkiyas mosisaNo ratings yet
- Lampiran 3 SpssDocument25 pagesLampiran 3 SpssyulianaNo ratings yet
- Module 19 - : Distribution of Sample Proportions and MeansDocument6 pagesModule 19 - : Distribution of Sample Proportions and MeansOlaolu JosephNo ratings yet
- PQT-Assignment 2 PDFDocument2 pagesPQT-Assignment 2 PDFacasNo ratings yet
- q3 Stat2100 Bautista-LhurielyDocument11 pagesq3 Stat2100 Bautista-LhurielyMEL KIAN CAESAR DUPOLNo ratings yet
- Tables For Standard Normal CDF and Loss FunctionsDocument3 pagesTables For Standard Normal CDF and Loss FunctionsНастя БорзуноваNo ratings yet
- Practice 1 PDFDocument4 pagesPractice 1 PDFNataliAmiranashviliNo ratings yet
- Final 6711 F10Document4 pagesFinal 6711 F10Songya PanNo ratings yet
- M.Sc. Actuarial Economics: Indira Gandhi National Open University, New DelhiDocument8 pagesM.Sc. Actuarial Economics: Indira Gandhi National Open University, New Delhiallan2inNo ratings yet
- Latent Dirichlet AllocationDocument13 pagesLatent Dirichlet Allocationzarthon100% (2)
- GillDocument474 pagesGillandy_guess_1No ratings yet
- Practice Problems - Set 3Document2 pagesPractice Problems - Set 3ashwinagrawal198231No ratings yet
- AssociationDocument57 pagesAssociationLalu Kumar :motivational speakerNo ratings yet
- Statistic Engineering Topic 1Document9 pagesStatistic Engineering Topic 1harisNo ratings yet
- Generalized Pareto DistributionDocument8 pagesGeneralized Pareto Distributionchuck333No ratings yet
- Peperiksaan Percubaan STPM 2014: Sekolah Menengah Kebangsaan Anderson, Ipoh, PerakDocument9 pagesPeperiksaan Percubaan STPM 2014: Sekolah Menengah Kebangsaan Anderson, Ipoh, PerakPeng Peng KekNo ratings yet
- MultinomialDistribution PDFDocument6 pagesMultinomialDistribution PDF3rlangNo ratings yet
- Cambridge International ExaminationsDocument12 pagesCambridge International ExaminationsNgợm NghịchNo ratings yet
- Maths IV PDE&Prob StatisticsDocument3 pagesMaths IV PDE&Prob StatisticsIshaNo ratings yet