
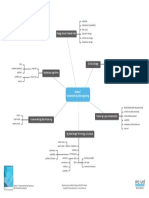
Big Data Dataset Categories Pattern Identification
Big Data Dataset Categories Pattern Identification
You might also like
- Oracle WMS 02Document53 pagesOracle WMS 02indra tamaNo ratings yet
- Two-Stack PDA: CS6800 Advance Theory of ComputationDocument51 pagesTwo-Stack PDA: CS6800 Advance Theory of ComputationShivendra AgarwalNo ratings yet
- CS1103 HW2Document2 pagesCS1103 HW2XinyiNo ratings yet
- Basic Calculus Classroom Instruction Delivery Alignment PlanDocument7 pagesBasic Calculus Classroom Instruction Delivery Alignment PlanIsrael Morta Garzon75% (4)
- MATH 341 - Operations Research I - Kamran RashidDocument5 pagesMATH 341 - Operations Research I - Kamran RashidIMSAAADNo ratings yet
- Crash Course in Analytics For Non Analytics ManagersDocument74 pagesCrash Course in Analytics For Non Analytics ManagersUzair FaruqiNo ratings yet
- Machine LearningDocument1 pageMachine LearningFareedNo ratings yet
- System Design: References / ResourcesDocument1 pageSystem Design: References / ResourcesabdallahNo ratings yet
- Computer ScienceDocument1 pageComputer SciencejayNo ratings yet
- ML-DL Training CurriculumDocument2 pagesML-DL Training CurriculumShubhendra vatsaNo ratings yet
- Computer NetworkDocument7 pagesComputer Networkgritchard4No ratings yet
- Reservoir Engineers Competency Matrix - Society of Petroleum EngineersDocument5 pagesReservoir Engineers Competency Matrix - Society of Petroleum Engineersbillal_m_aslamNo ratings yet
- BroomDocument172 pagesBroomNcube BonganiNo ratings yet
- Advanced Statistics (Week 3)Document14 pagesAdvanced Statistics (Week 3)Dileep Kumar MotukuriNo ratings yet
- SImA 1.3 Customer Facing (HCS) DraftDocument17 pagesSImA 1.3 Customer Facing (HCS) DraftcloudsforestNo ratings yet
- Statistics Mathematics: Fundamental Big Data Analysis & ScienceDocument1 pageStatistics Mathematics: Fundamental Big Data Analysis & SciencepietropesNo ratings yet
- Lecture 5 - Introduction To System Dynamics, Causal Loop Diagrams PDFDocument97 pagesLecture 5 - Introduction To System Dynamics, Causal Loop Diagrams PDFAlee TeenaNo ratings yet
- AI EthicsDocument23 pagesAI EthicspawanNo ratings yet
- AI EthicsDocument23 pagesAI EthicsJakub P. IlnickiNo ratings yet
- Special Section: Seismic Inversion: Cyril D. Boateng, Li-Yun Fu, Wu Yu, and Guan XizhuDocument10 pagesSpecial Section: Seismic Inversion: Cyril D. Boateng, Li-Yun Fu, Wu Yu, and Guan Xizhusaurabh sharmaNo ratings yet
- Extended Polynomial Dimensional Decomposition For Arbitrary Probability DistributionsDocument13 pagesExtended Polynomial Dimensional Decomposition For Arbitrary Probability DistributionsEric CNo ratings yet
- Math 241 Section 2.2 (8-2-2021)Document25 pagesMath 241 Section 2.2 (8-2-2021)H ANo ratings yet
- W1 - Introduction To Computational Fluid DynamicsDocument8 pagesW1 - Introduction To Computational Fluid DynamicsAnson CheongNo ratings yet
- Chp-10 (Topic Not in Book) Types of Data in Cluster Analysis.Document13 pagesChp-10 (Topic Not in Book) Types of Data in Cluster Analysis.deepanshub.cs.21No ratings yet
- Science Abb2823Document21 pagesScience Abb2823Gosia FrączekNo ratings yet
- © by SIAM. Unauthorized Reproduction of This Article Is ProhibitedDocument22 pages© by SIAM. Unauthorized Reproduction of This Article Is ProhibitedTu FindingNo ratings yet
- Ergodic Rate Analysis of Reconfigurable Intelligent Surface-Aided Massive MIMO Systems With ZF DetectorsDocument5 pagesErgodic Rate Analysis of Reconfigurable Intelligent Surface-Aided Massive MIMO Systems With ZF DetectorspratirajNo ratings yet
- Appendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science WorkflowsDocument5 pagesAppendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science Workflowsgfdsal878No ratings yet
- Appendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science WorkflowsDocument5 pagesAppendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science Workflowsgfdsal878No ratings yet
- 1 s2.0 S1877050922010122 MainDocument15 pages1 s2.0 S1877050922010122 Mainjuan pNo ratings yet
- Zavoli Federici 2021 Reinforcement Learning For Robust Trajectory Design of Interplanetary MissionsDocument14 pagesZavoli Federici 2021 Reinforcement Learning For Robust Trajectory Design of Interplanetary Missionsrezaferidooni00No ratings yet
- Fluid Mechanics Lectures NotesDocument16 pagesFluid Mechanics Lectures NotesFady KamilNo ratings yet
- Query OptimizationDocument27 pagesQuery OptimizationNiraj KoiralaNo ratings yet
- RM - Statistics - 2024-03-03 - 05-33-09Document1 pageRM - Statistics - 2024-03-03 - 05-33-09nitinNo ratings yet
- W3 - Mass and Momentum ConservationDocument16 pagesW3 - Mass and Momentum ConservationAnson CheongNo ratings yet
- Pesticide Detection NNDocument8 pagesPesticide Detection NNjabinaya62No ratings yet
- FlowDocument1 pageFlowRochmat HerdiansyahNo ratings yet
- Statistics 19.06 v.2Document18 pagesStatistics 19.06 v.2Jacqueline FeniarNo ratings yet
- Introduction To ANSYS Introduction To ANSYS Meshing: LT 5 Mesh Quality Check yDocument21 pagesIntroduction To ANSYS Introduction To ANSYS Meshing: LT 5 Mesh Quality Check yHeba AlaaNo ratings yet
- Kinds of Mathematical ModelsDocument1 pageKinds of Mathematical ModelsMho'd Abdul GaffarNo ratings yet
- Data Mini NGDocument1 pageData Mini NGapi-26993994No ratings yet
- An Optimal 9-Point, Finite-Difference, Frequency-Space, 2-D Scalar Wave ExtrapolatorDocument9 pagesAn Optimal 9-Point, Finite-Difference, Frequency-Space, 2-D Scalar Wave ExtrapolatorAndrés Felipe CastroNo ratings yet
- Datastructures and AlgorithmsDocument1 pageDatastructures and Algorithmsjoshimeet479No ratings yet
- Introduction To Financial EconometricsDocument191 pagesIntroduction To Financial EconometricsArvinder KaurNo ratings yet
- Eichelberger 2015Document16 pagesEichelberger 2015OmatoukNo ratings yet
- Test PDFDocument31 pagesTest PDFkimado9049No ratings yet
- Method FrameworkDocument1 pageMethod FrameworkJANN ROVIC CUETONo ratings yet
- Jones1964 - A Generalization of The Direct-Stiffness Method of Structural AnalysisDocument6 pagesJones1964 - A Generalization of The Direct-Stiffness Method of Structural AnalysisMatheus Garcia GoncalvesNo ratings yet
- Signal Pattern Recognition Based On Fractal FeaturDocument15 pagesSignal Pattern Recognition Based On Fractal FeaturPancho BvNo ratings yet
- Wa0000.Document8 pagesWa0000.dholi.urmila11No ratings yet
- Layer-Parallel Training of Deep Residual Neural NetworksDocument23 pagesLayer-Parallel Training of Deep Residual Neural NetworksDavid Garrido GonzalezNo ratings yet
- Math 241 Section 1.2 (3-2-2021)Document32 pagesMath 241 Section 1.2 (3-2-2021)H ANo ratings yet
- JavaScript Developer Roadmap - Step by Step Guide To Learn JavaScriptDocument1 pageJavaScript Developer Roadmap - Step by Step Guide To Learn JavaScriptgoxedNo ratings yet
- Chapter11 - Database ManagementDocument39 pagesChapter11 - Database ManagementXaronAngelNo ratings yet
- New Two-Equation Eddy Viscosity Transport Model For Turbulent Flow ComputationDocument10 pagesNew Two-Equation Eddy Viscosity Transport Model For Turbulent Flow Computationsaleamlak muluNo ratings yet
- Jany B Dy YrrDocument2 pagesJany B Dy Yrrhamzadaud032No ratings yet
- Unsupervised Learning Algorithm 1Document3 pagesUnsupervised Learning Algorithm 1vamsi krishnaNo ratings yet
- Module 4 Algorithms For Data ScienceDocument66 pagesModule 4 Algorithms For Data ScienceRaghu CNo ratings yet
- Pink Neutral Mindmap Diagram Brainstorm TemplateDocument1 pagePink Neutral Mindmap Diagram Brainstorm Templatearunprasath1755No ratings yet
- Updated CPC ScheduleDocument1 pageUpdated CPC ScheduleAzim CoolNo ratings yet
- Learning Data-Driven DiscretizationsDocument6 pagesLearning Data-Driven Discretizationssridevi10masNo ratings yet
- FDS FlowchartDocument1 pageFDS Flowchartf20201741No ratings yet
- Storage Device Characteristics: Fundamental Big Data EngineeringDocument1 pageStorage Device Characteristics: Fundamental Big Data EngineeringpietropesNo ratings yet
- BDSCP Module 09 MindmapDocument1 pageBDSCP Module 09 MindmappietropesNo ratings yet
- BDSCP Module 08 MindmapDocument1 pageBDSCP Module 08 MindmappietropesNo ratings yet
- Statistics Mathematics: Fundamental Big Data Analysis & ScienceDocument1 pageStatistics Mathematics: Fundamental Big Data Analysis & SciencepietropesNo ratings yet
- Jason Brownlee Thesis PDFDocument390 pagesJason Brownlee Thesis PDFpietropesNo ratings yet
- How To Win Every Argument PDFDocument196 pagesHow To Win Every Argument PDFRice RS100% (7)
- Household Projections For Korea (2020 2050)Document8 pagesHousehold Projections For Korea (2020 2050)Daria SkepkoNo ratings yet
- 5 6073134106445611130 PDFDocument15 pages5 6073134106445611130 PDFSiston MakafuNo ratings yet
- Lecture3 2018Document16 pagesLecture3 2018Stefan-Aurelian ApostolNo ratings yet
- Time Value of Money Unit 2Document4 pagesTime Value of Money Unit 2ManishJaiswalNo ratings yet
- Lecture 2.1.10 Characteristics of Neural Networks TerminologyDocument2 pagesLecture 2.1.10 Characteristics of Neural Networks TerminologyMuskan GahlawatNo ratings yet
- Numerical IntegrationDocument24 pagesNumerical Integrationالأردني JordanianNo ratings yet
- Unit 13 - Week 12: Assignment 12Document4 pagesUnit 13 - Week 12: Assignment 12DrJagannath SamantaNo ratings yet
- 3182 FormulasDocument9 pages3182 FormulasAnnie HsuNo ratings yet
- Struct Int Struct Struct Struct Void Int Struct Struct Sizeof Struct Struct StructDocument23 pagesStruct Int Struct Struct Struct Void Int Struct Struct Sizeof Struct Struct StructMarshallNo ratings yet
- Digital Signal Processing Lab: Dr. Nanda Kumar MDocument38 pagesDigital Signal Processing Lab: Dr. Nanda Kumar MKasi BandlaNo ratings yet
- Data Structure MCQDocument16 pagesData Structure MCQMaaz AdhoniNo ratings yet
- Tichu BayesDocument5 pagesTichu BayesizuvielNo ratings yet
- Singh RB - Thermal and Statistical Physics - 2edDocument20 pagesSingh RB - Thermal and Statistical Physics - 2edeasy BooksNo ratings yet
- Monica Nusskern Week 1 AssignmentDocument9 pagesMonica Nusskern Week 1 AssignmentganamuNo ratings yet
- QuizDocument143 pagesQuizRajeev PathakNo ratings yet
- Jose Geraldo Pereira, Ruben Aldrovandi - An Introduction To Geometrical Physics-World Scientific (2017)Document812 pagesJose Geraldo Pereira, Ruben Aldrovandi - An Introduction To Geometrical Physics-World Scientific (2017)Zaratustra Nietzche100% (1)
- LQR Tuning of Power System Stabilizer For Damping OscillationsDocument18 pagesLQR Tuning of Power System Stabilizer For Damping Oscillations●●●●●●●1100% (1)
- Decision TheoryDocument36 pagesDecision Theorythea gabriellaNo ratings yet
- Image Processing-Ch4 - Part 1Document63 pagesImage Processing-Ch4 - Part 1saifNo ratings yet
- Lect3 2Document43 pagesLect3 2matin ashrafiNo ratings yet
- Brains As Models of IntelligenceDocument2 pagesBrains As Models of IntelligenceAggelos ChiotisNo ratings yet
- Cheatsheet PDFDocument2 pagesCheatsheet PDFShadhil MajeedNo ratings yet
- OptimDocument70 pagesOptimNitin KumarNo ratings yet
- Flat It Gate 2Document33 pagesFlat It Gate 2Mohan BabuNo ratings yet
- University of Ottawa MAT 2377 Midterm ExamDocument4 pagesUniversity of Ottawa MAT 2377 Midterm ExamJamED ALRubioNo ratings yet
- CSI 06 AlgorithmsDocument30 pagesCSI 06 Algorithmsnguyên trần minhNo ratings yet
- Stiffness & FlexibilityDocument41 pagesStiffness & Flexibilityujjwalsingh8509No ratings yet






























































































Download as pdf or txt
You might also like
- Oracle WMS 02Document53 pagesOracle WMS 02indra tamaNo ratings yet
- Two-Stack PDA: CS6800 Advance Theory of ComputationDocument51 pagesTwo-Stack PDA: CS6800 Advance Theory of ComputationShivendra AgarwalNo ratings yet
- CS1103 HW2Document2 pagesCS1103 HW2XinyiNo ratings yet
- Basic Calculus Classroom Instruction Delivery Alignment PlanDocument7 pagesBasic Calculus Classroom Instruction Delivery Alignment PlanIsrael Morta Garzon75% (4)
- MATH 341 - Operations Research I - Kamran RashidDocument5 pagesMATH 341 - Operations Research I - Kamran RashidIMSAAADNo ratings yet
- Crash Course in Analytics For Non Analytics ManagersDocument74 pagesCrash Course in Analytics For Non Analytics ManagersUzair FaruqiNo ratings yet
- Machine LearningDocument1 pageMachine LearningFareedNo ratings yet
- System Design: References / ResourcesDocument1 pageSystem Design: References / ResourcesabdallahNo ratings yet
- Computer ScienceDocument1 pageComputer SciencejayNo ratings yet
- ML-DL Training CurriculumDocument2 pagesML-DL Training CurriculumShubhendra vatsaNo ratings yet
- Computer NetworkDocument7 pagesComputer Networkgritchard4No ratings yet
- Reservoir Engineers Competency Matrix - Society of Petroleum EngineersDocument5 pagesReservoir Engineers Competency Matrix - Society of Petroleum Engineersbillal_m_aslamNo ratings yet
- BroomDocument172 pagesBroomNcube BonganiNo ratings yet
- Advanced Statistics (Week 3)Document14 pagesAdvanced Statistics (Week 3)Dileep Kumar MotukuriNo ratings yet
- SImA 1.3 Customer Facing (HCS) DraftDocument17 pagesSImA 1.3 Customer Facing (HCS) DraftcloudsforestNo ratings yet
- Statistics Mathematics: Fundamental Big Data Analysis & ScienceDocument1 pageStatistics Mathematics: Fundamental Big Data Analysis & SciencepietropesNo ratings yet
- Lecture 5 - Introduction To System Dynamics, Causal Loop Diagrams PDFDocument97 pagesLecture 5 - Introduction To System Dynamics, Causal Loop Diagrams PDFAlee TeenaNo ratings yet
- AI EthicsDocument23 pagesAI EthicspawanNo ratings yet
- AI EthicsDocument23 pagesAI EthicsJakub P. IlnickiNo ratings yet
- Special Section: Seismic Inversion: Cyril D. Boateng, Li-Yun Fu, Wu Yu, and Guan XizhuDocument10 pagesSpecial Section: Seismic Inversion: Cyril D. Boateng, Li-Yun Fu, Wu Yu, and Guan Xizhusaurabh sharmaNo ratings yet
- Extended Polynomial Dimensional Decomposition For Arbitrary Probability DistributionsDocument13 pagesExtended Polynomial Dimensional Decomposition For Arbitrary Probability DistributionsEric CNo ratings yet
- Math 241 Section 2.2 (8-2-2021)Document25 pagesMath 241 Section 2.2 (8-2-2021)H ANo ratings yet
- W1 - Introduction To Computational Fluid DynamicsDocument8 pagesW1 - Introduction To Computational Fluid DynamicsAnson CheongNo ratings yet
- Chp-10 (Topic Not in Book) Types of Data in Cluster Analysis.Document13 pagesChp-10 (Topic Not in Book) Types of Data in Cluster Analysis.deepanshub.cs.21No ratings yet
- Science Abb2823Document21 pagesScience Abb2823Gosia FrączekNo ratings yet
- © by SIAM. Unauthorized Reproduction of This Article Is ProhibitedDocument22 pages© by SIAM. Unauthorized Reproduction of This Article Is ProhibitedTu FindingNo ratings yet
- Ergodic Rate Analysis of Reconfigurable Intelligent Surface-Aided Massive MIMO Systems With ZF DetectorsDocument5 pagesErgodic Rate Analysis of Reconfigurable Intelligent Surface-Aided Massive MIMO Systems With ZF DetectorspratirajNo ratings yet
- Appendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science WorkflowsDocument5 pagesAppendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science Workflowsgfdsal878No ratings yet
- Appendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science WorkflowsDocument5 pagesAppendix 4: Abdul Wahab Ziaullah, Sanjay Chawla, Fadwa El Mellouhi Automated Materials Science Workflowsgfdsal878No ratings yet
- 1 s2.0 S1877050922010122 MainDocument15 pages1 s2.0 S1877050922010122 Mainjuan pNo ratings yet
- Zavoli Federici 2021 Reinforcement Learning For Robust Trajectory Design of Interplanetary MissionsDocument14 pagesZavoli Federici 2021 Reinforcement Learning For Robust Trajectory Design of Interplanetary Missionsrezaferidooni00No ratings yet
- Fluid Mechanics Lectures NotesDocument16 pagesFluid Mechanics Lectures NotesFady KamilNo ratings yet
- Query OptimizationDocument27 pagesQuery OptimizationNiraj KoiralaNo ratings yet
- RM - Statistics - 2024-03-03 - 05-33-09Document1 pageRM - Statistics - 2024-03-03 - 05-33-09nitinNo ratings yet
- W3 - Mass and Momentum ConservationDocument16 pagesW3 - Mass and Momentum ConservationAnson CheongNo ratings yet
- Pesticide Detection NNDocument8 pagesPesticide Detection NNjabinaya62No ratings yet
- FlowDocument1 pageFlowRochmat HerdiansyahNo ratings yet
- Statistics 19.06 v.2Document18 pagesStatistics 19.06 v.2Jacqueline FeniarNo ratings yet
- Introduction To ANSYS Introduction To ANSYS Meshing: LT 5 Mesh Quality Check yDocument21 pagesIntroduction To ANSYS Introduction To ANSYS Meshing: LT 5 Mesh Quality Check yHeba AlaaNo ratings yet
- Kinds of Mathematical ModelsDocument1 pageKinds of Mathematical ModelsMho'd Abdul GaffarNo ratings yet
- Data Mini NGDocument1 pageData Mini NGapi-26993994No ratings yet
- An Optimal 9-Point, Finite-Difference, Frequency-Space, 2-D Scalar Wave ExtrapolatorDocument9 pagesAn Optimal 9-Point, Finite-Difference, Frequency-Space, 2-D Scalar Wave ExtrapolatorAndrés Felipe CastroNo ratings yet
- Datastructures and AlgorithmsDocument1 pageDatastructures and Algorithmsjoshimeet479No ratings yet
- Introduction To Financial EconometricsDocument191 pagesIntroduction To Financial EconometricsArvinder KaurNo ratings yet
- Eichelberger 2015Document16 pagesEichelberger 2015OmatoukNo ratings yet
- Test PDFDocument31 pagesTest PDFkimado9049No ratings yet
- Method FrameworkDocument1 pageMethod FrameworkJANN ROVIC CUETONo ratings yet
- Jones1964 - A Generalization of The Direct-Stiffness Method of Structural AnalysisDocument6 pagesJones1964 - A Generalization of The Direct-Stiffness Method of Structural AnalysisMatheus Garcia GoncalvesNo ratings yet
- Signal Pattern Recognition Based On Fractal FeaturDocument15 pagesSignal Pattern Recognition Based On Fractal FeaturPancho BvNo ratings yet
- Wa0000.Document8 pagesWa0000.dholi.urmila11No ratings yet
- Layer-Parallel Training of Deep Residual Neural NetworksDocument23 pagesLayer-Parallel Training of Deep Residual Neural NetworksDavid Garrido GonzalezNo ratings yet
- Math 241 Section 1.2 (3-2-2021)Document32 pagesMath 241 Section 1.2 (3-2-2021)H ANo ratings yet
- JavaScript Developer Roadmap - Step by Step Guide To Learn JavaScriptDocument1 pageJavaScript Developer Roadmap - Step by Step Guide To Learn JavaScriptgoxedNo ratings yet
- Chapter11 - Database ManagementDocument39 pagesChapter11 - Database ManagementXaronAngelNo ratings yet
- New Two-Equation Eddy Viscosity Transport Model For Turbulent Flow ComputationDocument10 pagesNew Two-Equation Eddy Viscosity Transport Model For Turbulent Flow Computationsaleamlak muluNo ratings yet
- Jany B Dy YrrDocument2 pagesJany B Dy Yrrhamzadaud032No ratings yet
- Unsupervised Learning Algorithm 1Document3 pagesUnsupervised Learning Algorithm 1vamsi krishnaNo ratings yet
- Module 4 Algorithms For Data ScienceDocument66 pagesModule 4 Algorithms For Data ScienceRaghu CNo ratings yet
- Pink Neutral Mindmap Diagram Brainstorm TemplateDocument1 pagePink Neutral Mindmap Diagram Brainstorm Templatearunprasath1755No ratings yet
- Updated CPC ScheduleDocument1 pageUpdated CPC ScheduleAzim CoolNo ratings yet
- Learning Data-Driven DiscretizationsDocument6 pagesLearning Data-Driven Discretizationssridevi10masNo ratings yet
- FDS FlowchartDocument1 pageFDS Flowchartf20201741No ratings yet
- Storage Device Characteristics: Fundamental Big Data EngineeringDocument1 pageStorage Device Characteristics: Fundamental Big Data EngineeringpietropesNo ratings yet
- BDSCP Module 09 MindmapDocument1 pageBDSCP Module 09 MindmappietropesNo ratings yet
- BDSCP Module 08 MindmapDocument1 pageBDSCP Module 08 MindmappietropesNo ratings yet
- Statistics Mathematics: Fundamental Big Data Analysis & ScienceDocument1 pageStatistics Mathematics: Fundamental Big Data Analysis & SciencepietropesNo ratings yet
- Jason Brownlee Thesis PDFDocument390 pagesJason Brownlee Thesis PDFpietropesNo ratings yet
- How To Win Every Argument PDFDocument196 pagesHow To Win Every Argument PDFRice RS100% (7)
- Household Projections For Korea (2020 2050)Document8 pagesHousehold Projections For Korea (2020 2050)Daria SkepkoNo ratings yet
- 5 6073134106445611130 PDFDocument15 pages5 6073134106445611130 PDFSiston MakafuNo ratings yet
- Lecture3 2018Document16 pagesLecture3 2018Stefan-Aurelian ApostolNo ratings yet
- Time Value of Money Unit 2Document4 pagesTime Value of Money Unit 2ManishJaiswalNo ratings yet
- Lecture 2.1.10 Characteristics of Neural Networks TerminologyDocument2 pagesLecture 2.1.10 Characteristics of Neural Networks TerminologyMuskan GahlawatNo ratings yet
- Numerical IntegrationDocument24 pagesNumerical Integrationالأردني JordanianNo ratings yet
- Unit 13 - Week 12: Assignment 12Document4 pagesUnit 13 - Week 12: Assignment 12DrJagannath SamantaNo ratings yet
- 3182 FormulasDocument9 pages3182 FormulasAnnie HsuNo ratings yet
- Struct Int Struct Struct Struct Void Int Struct Struct Sizeof Struct Struct StructDocument23 pagesStruct Int Struct Struct Struct Void Int Struct Struct Sizeof Struct Struct StructMarshallNo ratings yet
- Digital Signal Processing Lab: Dr. Nanda Kumar MDocument38 pagesDigital Signal Processing Lab: Dr. Nanda Kumar MKasi BandlaNo ratings yet
- Data Structure MCQDocument16 pagesData Structure MCQMaaz AdhoniNo ratings yet
- Tichu BayesDocument5 pagesTichu BayesizuvielNo ratings yet
- Singh RB - Thermal and Statistical Physics - 2edDocument20 pagesSingh RB - Thermal and Statistical Physics - 2edeasy BooksNo ratings yet
- Monica Nusskern Week 1 AssignmentDocument9 pagesMonica Nusskern Week 1 AssignmentganamuNo ratings yet
- QuizDocument143 pagesQuizRajeev PathakNo ratings yet
- Jose Geraldo Pereira, Ruben Aldrovandi - An Introduction To Geometrical Physics-World Scientific (2017)Document812 pagesJose Geraldo Pereira, Ruben Aldrovandi - An Introduction To Geometrical Physics-World Scientific (2017)Zaratustra Nietzche100% (1)
- LQR Tuning of Power System Stabilizer For Damping OscillationsDocument18 pagesLQR Tuning of Power System Stabilizer For Damping Oscillations●●●●●●●1100% (1)
- Decision TheoryDocument36 pagesDecision Theorythea gabriellaNo ratings yet
- Image Processing-Ch4 - Part 1Document63 pagesImage Processing-Ch4 - Part 1saifNo ratings yet
- Lect3 2Document43 pagesLect3 2matin ashrafiNo ratings yet
- Brains As Models of IntelligenceDocument2 pagesBrains As Models of IntelligenceAggelos ChiotisNo ratings yet
- Cheatsheet PDFDocument2 pagesCheatsheet PDFShadhil MajeedNo ratings yet
- OptimDocument70 pagesOptimNitin KumarNo ratings yet
- Flat It Gate 2Document33 pagesFlat It Gate 2Mohan BabuNo ratings yet
- University of Ottawa MAT 2377 Midterm ExamDocument4 pagesUniversity of Ottawa MAT 2377 Midterm ExamJamED ALRubioNo ratings yet
- CSI 06 AlgorithmsDocument30 pagesCSI 06 Algorithmsnguyên trần minhNo ratings yet
- Stiffness & FlexibilityDocument41 pagesStiffness & Flexibilityujjwalsingh8509No ratings yet