
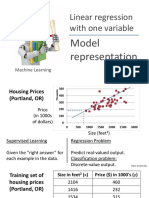
LinearRegression Annotated
LinearRegression Annotated
You might also like
- Dict Ict ExamDocument4 pagesDict Ict Examgirlthing60% (5)
- Lecture 6,7-Linear RegressionDocument47 pagesLecture 6,7-Linear RegressionWaseem ShahzadNo ratings yet
- 5 LinearRegression With One-VariableDocument21 pages5 LinearRegression With One-Variableauro auroNo ratings yet
- Week 04Document101 pagesWeek 04Osii CNo ratings yet
- Gradient Descent - Linear RegressionDocument47 pagesGradient Descent - Linear RegressionRaushan Kashyap100% (1)
- Lecture 3 AiDocument48 pagesLecture 3 AiEnes sağnakNo ratings yet
- Linear RegressionDocument51 pagesLinear RegressionKunal Langer100% (1)
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- Linear Regression: Study On The Coursera All Right Reserved: Andrew NGDocument29 pagesLinear Regression: Study On The Coursera All Right Reserved: Andrew NGRabbia KhalidNo ratings yet
- Statistics Chapter3Document60 pagesStatistics Chapter3Zhiye Tang100% (1)
- Linear Regerssion With 1var Lecture2Document49 pagesLinear Regerssion With 1var Lecture26441 Abdul RehmanNo ratings yet
- Lecture LinearRegressionDocument42 pagesLecture LinearRegressionRaunak AsnaniNo ratings yet
- Linear RegressionDocument75 pagesLinear RegressionAaqib InamNo ratings yet
- Lecture 2Document71 pagesLecture 2Bandar AlmaslukhNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model Representationesteban1815No ratings yet
- Linear Regression With One VariableDocument49 pagesLinear Regression With One Variableabdala sabryNo ratings yet
- Applied Machine Learning: One Variable (Simple) Linear RegressionDocument38 pagesApplied Machine Learning: One Variable (Simple) Linear RegressionWanida KrataeNo ratings yet
- L3 Linear Regression and Gradient DescentDocument46 pagesL3 Linear Regression and Gradient Descentjoseph karimNo ratings yet
- Lecture 2Document62 pagesLecture 2Usama MustafaNo ratings yet
- Math Library FunctionsDocument23 pagesMath Library FunctionsSuresh Reddy PolinatiNo ratings yet
- ML02Document25 pagesML02Muneeb ButtNo ratings yet
- Linear Regression With One VariableDocument49 pagesLinear Regression With One Variablemabs72258No ratings yet
- Linear Regression: Jia-Bin Huang Virginia TechDocument59 pagesLinear Regression: Jia-Bin Huang Virginia TechMr. Raghunath ReddyNo ratings yet
- Chapter 1Document27 pagesChapter 1Bereket Desalegn0% (1)
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- CS229 Lecture Notes: Supervised LearningDocument28 pagesCS229 Lecture Notes: Supervised LearningEdiz MannlichNo ratings yet
- Introduction To OptimizationDocument13 pagesIntroduction To OptimizationSushil ThakkarNo ratings yet
- Large Scale Deep LearningDocument170 pagesLarge Scale Deep Learningpavancreative81No ratings yet
- Series 1Document2 pagesSeries 1Sangwoo KimNo ratings yet
- ML03Document14 pagesML03Muneeb ButtNo ratings yet
- M02 Linear Regression MethodsDocument40 pagesM02 Linear Regression Methodsanjibalaji52No ratings yet
- Introduction To Matlab: Doikon@Document26 pagesIntroduction To Matlab: Doikon@Milind RavindranathNo ratings yet
- Functions: Aryaf AladwanDocument70 pagesFunctions: Aryaf Aladwansaeed wedyanNo ratings yet
- HW1Document4 pagesHW1sun_917443954No ratings yet
- 5-SpatialFiltering 2Document74 pages5-SpatialFiltering 2pham tamNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Sc0x w1l2 CleanDocument35 pagesSc0x w1l2 CleanHaseeb RehmanNo ratings yet
- Humathematical EconomicsDocument44 pagesHumathematical EconomicsyacobNo ratings yet
- Linear RegressionDocument14 pagesLinear RegressionSyed Tariq NaqshbandiNo ratings yet
- Calculus: - The Two Basic Forms of Calculus AreDocument19 pagesCalculus: - The Two Basic Forms of Calculus Aregostavis chilamoNo ratings yet
- 3 - Linear Regression Multiple VariablesDocument44 pages3 - Linear Regression Multiple Variableshung13579No ratings yet
- Linear RegressionDocument63 pagesLinear Regressionakrab.tech7No ratings yet
- Machine Learning CourseraDocument55 pagesMachine Learning CourseraLê Văn Tú100% (1)
- 3.3 Bias VarianceDocument14 pages3.3 Bias VarianceDavi Sousa e SilvaNo ratings yet
- L2 Graphs Piecewise, Absolute, and Greatest IntegerDocument21 pagesL2 Graphs Piecewise, Absolute, and Greatest IntegerJhettNo ratings yet
- Lecture-13 - ESO208 - Aug 31 - 2022Document28 pagesLecture-13 - ESO208 - Aug 31 - 2022Imad ShaikhNo ratings yet
- Lecture03 FT 2DDocument68 pagesLecture03 FT 2DMd Nur-A-Adam DonyNo ratings yet
- Cs229 Notes Deep LearningDocument21 pagesCs229 Notes Deep LearningChirag PramodNo ratings yet
- Ass 1Document3 pagesAss 1Vibhanshu LodhiNo ratings yet
- Fisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsDocument22 pagesFisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsGeorge HamiltonNo ratings yet
- Intoduction To MATLABDocument32 pagesIntoduction To MATLABDania KhattakNo ratings yet
- Lecture #4 Komnum - OptimizationDocument49 pagesLecture #4 Komnum - OptimizationNata SunardiNo ratings yet
- Lecture 3-Linear-Regression-Part2Document45 pagesLecture 3-Linear-Regression-Part2Nada ShaabanNo ratings yet
- Gradient Descent and SGDDocument8 pagesGradient Descent and SGDROHIT ARORANo ratings yet
- Chapter 3 Modeling of Physical SystemsDocument29 pagesChapter 3 Modeling of Physical Systemssaleh1978No ratings yet
- 3289 BeamerHestonRegimeDocument50 pages3289 BeamerHestonRegimenexxus hcNo ratings yet
- Lab 1 Introduction To MATLABDocument35 pagesLab 1 Introduction To MATLABAbdul RehmanNo ratings yet
- 5 Backward PropagationDocument81 pages5 Backward Propagationbiware8359No ratings yet
- NEET Chemistry Chapter Wise Mock Test - Chemical Thermodynamics - CBSE TutsDocument36 pagesNEET Chemistry Chapter Wise Mock Test - Chemical Thermodynamics - CBSE Tutssreenandhan 2017No ratings yet
- 100 Bài tập đọc hiểu Tiếng Anh theo chủ đề có đáp ánDocument337 pages100 Bài tập đọc hiểu Tiếng Anh theo chủ đề có đáp ánThang ThangNo ratings yet
- Benefits and Risks of The InternetDocument7 pagesBenefits and Risks of The InternetErick MiulerNo ratings yet
- El Asombroso Razonamiento de Los Niños, Jorge Salgado S.Document13 pagesEl Asombroso Razonamiento de Los Niños, Jorge Salgado S.Paula CamposNo ratings yet
- Admission of Selected Students - 2017-2018 - FINALDocument65 pagesAdmission of Selected Students - 2017-2018 - FINALDennisEudes100% (1)
- CHAPTER Electrons in AtomsDocument38 pagesCHAPTER Electrons in AtomsAref DahabrahNo ratings yet
- Managerial SkillsDocument30 pagesManagerial SkillsShefali Damon SalvatoreNo ratings yet
- Comparing Training MethodsDocument62 pagesComparing Training MethodsAdriana VozziNo ratings yet
- Annual Report 2010: IEEE Kerala SectionDocument27 pagesAnnual Report 2010: IEEE Kerala SectionjijoviNo ratings yet
- Head Teachers Role in School ImprovementDocument14 pagesHead Teachers Role in School Improvementpkjatt145No ratings yet
- Arts 2457Document8 pagesArts 2457findheroNo ratings yet
- Soal Bahasa Inggris Kelas 3Document4 pagesSoal Bahasa Inggris Kelas 3Ricavera TariganNo ratings yet
- Hirata Et Al, FinalDocument15 pagesHirata Et Al, FinalNaji Z. ArandiNo ratings yet
- ENGLISH G10 Written Test 3rd Quarter W12Document4 pagesENGLISH G10 Written Test 3rd Quarter W12Cynthia LuayNo ratings yet
- December 2011 Soul TruthDocument8 pagesDecember 2011 Soul Truthayayog3679No ratings yet
- Ι. Κτιστάκις, ο νέος Έλληνας δικαστής στο ΕΔΔΑDocument21 pagesΙ. Κτιστάκις, ο νέος Έλληνας δικαστής στο ΕΔΔΑARISTEIDIS VIKETOSNo ratings yet
- 21st Century Literature LESSON LOGDocument2 pages21st Century Literature LESSON LOGEvaNo ratings yet
- Hook Bridge Thesis ExamplesDocument5 pagesHook Bridge Thesis Examplesamandagraytulsa100% (2)
- Cinyanja Grade 8 Term 1 Schemes of WorkDocument4 pagesCinyanja Grade 8 Term 1 Schemes of WorkDøps Maløne80% (5)
- Homework Support For Kids: Part 1: Staff GuideDocument77 pagesHomework Support For Kids: Part 1: Staff GuideDilara ÇivicioğluNo ratings yet
- MS Parent Bulletin (Week of April 24 To 28)Document10 pagesMS Parent Bulletin (Week of April 24 To 28)International School ManilaNo ratings yet
- NAMS 2019 105 FRANCISCO BULNES MexicoDocument4 pagesNAMS 2019 105 FRANCISCO BULNES MexicoShaNo ratings yet
- Lab Report: By: Atharva SatputeDocument3 pagesLab Report: By: Atharva SatputeAtharva SatputeNo ratings yet
- Code Switching As A Key For Students To Participate More in Classroom DiscussionsDocument5 pagesCode Switching As A Key For Students To Participate More in Classroom DiscussionsJhessa May CanuelNo ratings yet
- Participant'S Handbook: Indian Institute of Management KashipurDocument58 pagesParticipant'S Handbook: Indian Institute of Management KashipurAmit KumarNo ratings yet
- XUMag June-Sept2014 4webDocument23 pagesXUMag June-Sept2014 4webWendel AbejoNo ratings yet
- The Power of TeachingDocument16 pagesThe Power of TeachingArminda CostunaNo ratings yet
- Great Books, Honors Programs, and Hidden Origins - The Virginia Plan and The University of Virginia in The Liberal Arts Movement (History of Education)Document266 pagesGreat Books, Honors Programs, and Hidden Origins - The Virginia Plan and The University of Virginia in The Liberal Arts Movement (History of Education)Subtain 7247No ratings yet
- BAF 500 Thesis Syllabus PDFDocument5 pagesBAF 500 Thesis Syllabus PDFFatbardha MorinaNo ratings yet























































































Download as pdf or txt
You might also like
- Dict Ict ExamDocument4 pagesDict Ict Examgirlthing60% (5)
- Lecture 6,7-Linear RegressionDocument47 pagesLecture 6,7-Linear RegressionWaseem ShahzadNo ratings yet
- 5 LinearRegression With One-VariableDocument21 pages5 LinearRegression With One-Variableauro auroNo ratings yet
- Week 04Document101 pagesWeek 04Osii CNo ratings yet
- Gradient Descent - Linear RegressionDocument47 pagesGradient Descent - Linear RegressionRaushan Kashyap100% (1)
- Lecture 3 AiDocument48 pagesLecture 3 AiEnes sağnakNo ratings yet
- Linear RegressionDocument51 pagesLinear RegressionKunal Langer100% (1)
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- Linear Regression: Study On The Coursera All Right Reserved: Andrew NGDocument29 pagesLinear Regression: Study On The Coursera All Right Reserved: Andrew NGRabbia KhalidNo ratings yet
- Statistics Chapter3Document60 pagesStatistics Chapter3Zhiye Tang100% (1)
- Linear Regerssion With 1var Lecture2Document49 pagesLinear Regerssion With 1var Lecture26441 Abdul RehmanNo ratings yet
- Lecture LinearRegressionDocument42 pagesLecture LinearRegressionRaunak AsnaniNo ratings yet
- Linear RegressionDocument75 pagesLinear RegressionAaqib InamNo ratings yet
- Lecture 2Document71 pagesLecture 2Bandar AlmaslukhNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model Representationesteban1815No ratings yet
- Linear Regression With One VariableDocument49 pagesLinear Regression With One Variableabdala sabryNo ratings yet
- Applied Machine Learning: One Variable (Simple) Linear RegressionDocument38 pagesApplied Machine Learning: One Variable (Simple) Linear RegressionWanida KrataeNo ratings yet
- L3 Linear Regression and Gradient DescentDocument46 pagesL3 Linear Regression and Gradient Descentjoseph karimNo ratings yet
- Lecture 2Document62 pagesLecture 2Usama MustafaNo ratings yet
- Math Library FunctionsDocument23 pagesMath Library FunctionsSuresh Reddy PolinatiNo ratings yet
- ML02Document25 pagesML02Muneeb ButtNo ratings yet
- Linear Regression With One VariableDocument49 pagesLinear Regression With One Variablemabs72258No ratings yet
- Linear Regression: Jia-Bin Huang Virginia TechDocument59 pagesLinear Regression: Jia-Bin Huang Virginia TechMr. Raghunath ReddyNo ratings yet
- Chapter 1Document27 pagesChapter 1Bereket Desalegn0% (1)
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- CS229 Lecture Notes: Supervised LearningDocument28 pagesCS229 Lecture Notes: Supervised LearningEdiz MannlichNo ratings yet
- Introduction To OptimizationDocument13 pagesIntroduction To OptimizationSushil ThakkarNo ratings yet
- Large Scale Deep LearningDocument170 pagesLarge Scale Deep Learningpavancreative81No ratings yet
- Series 1Document2 pagesSeries 1Sangwoo KimNo ratings yet
- ML03Document14 pagesML03Muneeb ButtNo ratings yet
- M02 Linear Regression MethodsDocument40 pagesM02 Linear Regression Methodsanjibalaji52No ratings yet
- Introduction To Matlab: Doikon@Document26 pagesIntroduction To Matlab: Doikon@Milind RavindranathNo ratings yet
- Functions: Aryaf AladwanDocument70 pagesFunctions: Aryaf Aladwansaeed wedyanNo ratings yet
- HW1Document4 pagesHW1sun_917443954No ratings yet
- 5-SpatialFiltering 2Document74 pages5-SpatialFiltering 2pham tamNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Sc0x w1l2 CleanDocument35 pagesSc0x w1l2 CleanHaseeb RehmanNo ratings yet
- Humathematical EconomicsDocument44 pagesHumathematical EconomicsyacobNo ratings yet
- Linear RegressionDocument14 pagesLinear RegressionSyed Tariq NaqshbandiNo ratings yet
- Calculus: - The Two Basic Forms of Calculus AreDocument19 pagesCalculus: - The Two Basic Forms of Calculus Aregostavis chilamoNo ratings yet
- 3 - Linear Regression Multiple VariablesDocument44 pages3 - Linear Regression Multiple Variableshung13579No ratings yet
- Linear RegressionDocument63 pagesLinear Regressionakrab.tech7No ratings yet
- Machine Learning CourseraDocument55 pagesMachine Learning CourseraLê Văn Tú100% (1)
- 3.3 Bias VarianceDocument14 pages3.3 Bias VarianceDavi Sousa e SilvaNo ratings yet
- L2 Graphs Piecewise, Absolute, and Greatest IntegerDocument21 pagesL2 Graphs Piecewise, Absolute, and Greatest IntegerJhettNo ratings yet
- Lecture-13 - ESO208 - Aug 31 - 2022Document28 pagesLecture-13 - ESO208 - Aug 31 - 2022Imad ShaikhNo ratings yet
- Lecture03 FT 2DDocument68 pagesLecture03 FT 2DMd Nur-A-Adam DonyNo ratings yet
- Cs229 Notes Deep LearningDocument21 pagesCs229 Notes Deep LearningChirag PramodNo ratings yet
- Ass 1Document3 pagesAss 1Vibhanshu LodhiNo ratings yet
- Fisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsDocument22 pagesFisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsGeorge HamiltonNo ratings yet
- Intoduction To MATLABDocument32 pagesIntoduction To MATLABDania KhattakNo ratings yet
- Lecture #4 Komnum - OptimizationDocument49 pagesLecture #4 Komnum - OptimizationNata SunardiNo ratings yet
- Lecture 3-Linear-Regression-Part2Document45 pagesLecture 3-Linear-Regression-Part2Nada ShaabanNo ratings yet
- Gradient Descent and SGDDocument8 pagesGradient Descent and SGDROHIT ARORANo ratings yet
- Chapter 3 Modeling of Physical SystemsDocument29 pagesChapter 3 Modeling of Physical Systemssaleh1978No ratings yet
- 3289 BeamerHestonRegimeDocument50 pages3289 BeamerHestonRegimenexxus hcNo ratings yet
- Lab 1 Introduction To MATLABDocument35 pagesLab 1 Introduction To MATLABAbdul RehmanNo ratings yet
- 5 Backward PropagationDocument81 pages5 Backward Propagationbiware8359No ratings yet
- NEET Chemistry Chapter Wise Mock Test - Chemical Thermodynamics - CBSE TutsDocument36 pagesNEET Chemistry Chapter Wise Mock Test - Chemical Thermodynamics - CBSE Tutssreenandhan 2017No ratings yet
- 100 Bài tập đọc hiểu Tiếng Anh theo chủ đề có đáp ánDocument337 pages100 Bài tập đọc hiểu Tiếng Anh theo chủ đề có đáp ánThang ThangNo ratings yet
- Benefits and Risks of The InternetDocument7 pagesBenefits and Risks of The InternetErick MiulerNo ratings yet
- El Asombroso Razonamiento de Los Niños, Jorge Salgado S.Document13 pagesEl Asombroso Razonamiento de Los Niños, Jorge Salgado S.Paula CamposNo ratings yet
- Admission of Selected Students - 2017-2018 - FINALDocument65 pagesAdmission of Selected Students - 2017-2018 - FINALDennisEudes100% (1)
- CHAPTER Electrons in AtomsDocument38 pagesCHAPTER Electrons in AtomsAref DahabrahNo ratings yet
- Managerial SkillsDocument30 pagesManagerial SkillsShefali Damon SalvatoreNo ratings yet
- Comparing Training MethodsDocument62 pagesComparing Training MethodsAdriana VozziNo ratings yet
- Annual Report 2010: IEEE Kerala SectionDocument27 pagesAnnual Report 2010: IEEE Kerala SectionjijoviNo ratings yet
- Head Teachers Role in School ImprovementDocument14 pagesHead Teachers Role in School Improvementpkjatt145No ratings yet
- Arts 2457Document8 pagesArts 2457findheroNo ratings yet
- Soal Bahasa Inggris Kelas 3Document4 pagesSoal Bahasa Inggris Kelas 3Ricavera TariganNo ratings yet
- Hirata Et Al, FinalDocument15 pagesHirata Et Al, FinalNaji Z. ArandiNo ratings yet
- ENGLISH G10 Written Test 3rd Quarter W12Document4 pagesENGLISH G10 Written Test 3rd Quarter W12Cynthia LuayNo ratings yet
- December 2011 Soul TruthDocument8 pagesDecember 2011 Soul Truthayayog3679No ratings yet
- Ι. Κτιστάκις, ο νέος Έλληνας δικαστής στο ΕΔΔΑDocument21 pagesΙ. Κτιστάκις, ο νέος Έλληνας δικαστής στο ΕΔΔΑARISTEIDIS VIKETOSNo ratings yet
- 21st Century Literature LESSON LOGDocument2 pages21st Century Literature LESSON LOGEvaNo ratings yet
- Hook Bridge Thesis ExamplesDocument5 pagesHook Bridge Thesis Examplesamandagraytulsa100% (2)
- Cinyanja Grade 8 Term 1 Schemes of WorkDocument4 pagesCinyanja Grade 8 Term 1 Schemes of WorkDøps Maløne80% (5)
- Homework Support For Kids: Part 1: Staff GuideDocument77 pagesHomework Support For Kids: Part 1: Staff GuideDilara ÇivicioğluNo ratings yet
- MS Parent Bulletin (Week of April 24 To 28)Document10 pagesMS Parent Bulletin (Week of April 24 To 28)International School ManilaNo ratings yet
- NAMS 2019 105 FRANCISCO BULNES MexicoDocument4 pagesNAMS 2019 105 FRANCISCO BULNES MexicoShaNo ratings yet
- Lab Report: By: Atharva SatputeDocument3 pagesLab Report: By: Atharva SatputeAtharva SatputeNo ratings yet
- Code Switching As A Key For Students To Participate More in Classroom DiscussionsDocument5 pagesCode Switching As A Key For Students To Participate More in Classroom DiscussionsJhessa May CanuelNo ratings yet
- Participant'S Handbook: Indian Institute of Management KashipurDocument58 pagesParticipant'S Handbook: Indian Institute of Management KashipurAmit KumarNo ratings yet
- XUMag June-Sept2014 4webDocument23 pagesXUMag June-Sept2014 4webWendel AbejoNo ratings yet
- The Power of TeachingDocument16 pagesThe Power of TeachingArminda CostunaNo ratings yet
- Great Books, Honors Programs, and Hidden Origins - The Virginia Plan and The University of Virginia in The Liberal Arts Movement (History of Education)Document266 pagesGreat Books, Honors Programs, and Hidden Origins - The Virginia Plan and The University of Virginia in The Liberal Arts Movement (History of Education)Subtain 7247No ratings yet
- BAF 500 Thesis Syllabus PDFDocument5 pagesBAF 500 Thesis Syllabus PDFFatbardha MorinaNo ratings yet