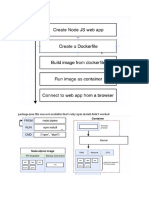
Download as pdf or txt
You might also like
- GitHub Actions in Action (MEAP V03) (Michael Kaufmann, Rob Bos, Marcel de Vries) (Z-Library)Document207 pagesGitHub Actions in Action (MEAP V03) (Michael Kaufmann, Rob Bos, Marcel de Vries) (Z-Library)Victor M. Varela RodriguezNo ratings yet
- Web Publishing and Browsing (WDP)Document13 pagesWeb Publishing and Browsing (WDP)nandanNo ratings yet
- MySQL Cheatsheet - CodeWithHarryDocument13 pagesMySQL Cheatsheet - CodeWithHarrybishal sarma100% (1)
- Web Programming: Unit 1: Introduction To Dynamic WebsitesDocument15 pagesWeb Programming: Unit 1: Introduction To Dynamic WebsitesIwan SaputraNo ratings yet
- Exam AZ-104: Microsoft Azure Administrator - Skills MeasuredDocument12 pagesExam AZ-104: Microsoft Azure Administrator - Skills MeasuredAl QanasNo ratings yet
- Docker DocumentationV1Document16 pagesDocker DocumentationV1thej100% (1)
- Python Advanced - Threads and ThreadingDocument9 pagesPython Advanced - Threads and ThreadingPedro Elias Romero NietoNo ratings yet
- A Complete Guide To Web Development in PythonDocument3 pagesA Complete Guide To Web Development in PythonIsaac GNo ratings yet
- 7 Fundamental Steps To Complete A Data Analytics ProjectDocument6 pages7 Fundamental Steps To Complete A Data Analytics ProjectAdnan HashmiNo ratings yet
- W3Schools: Angularjs Ajax - $HTTPDocument12 pagesW3Schools: Angularjs Ajax - $HTTPccalin10No ratings yet
- What Is Devops?Document23 pagesWhat Is Devops?DDNo ratings yet
- Web Crawling: Christopher Olston and Marc NajorkDocument49 pagesWeb Crawling: Christopher Olston and Marc Najorkshriram1082883No ratings yet
- Choosing Compute OptionsDocument45 pagesChoosing Compute OptionsTeddi ZulkarnaenNo ratings yet
- Docker The Ultimate Beginner's GuideDocument18 pagesDocker The Ultimate Beginner's GuideDarius1501No ratings yet
- HTML Tutorials - I-Tech Software EducationDocument50 pagesHTML Tutorials - I-Tech Software Educationvadevel100% (1)
- Cloud Computing ConceptsDocument17 pagesCloud Computing ConceptsKuljit Kaur100% (1)
- rc207 010d Cloud Foundry PDFDocument10 pagesrc207 010d Cloud Foundry PDFA.K. MarsNo ratings yet
- Microsoft SQL Server Database CommandDocument5 pagesMicrosoft SQL Server Database CommandzulhasnorNo ratings yet
- PHP Hyper Text PreprocessorDocument35 pagesPHP Hyper Text PreprocessorHimanshu Sharma100% (2)
- Aws Intro v2Document35 pagesAws Intro v2Pavan NavNo ratings yet
- Cs Cheat SheetDocument14 pagesCs Cheat Sheetthanhsonhugoa4No ratings yet
- GithubDocument17 pagesGithubmr_angelCNo ratings yet
- Programming Concepts Cheat SheetDocument5 pagesProgramming Concepts Cheat SheetRhibhav PalNo ratings yet
- Computer Science Project ListDocument8 pagesComputer Science Project ListALi FarHanNo ratings yet
- Docker Cheat SheetDocument50 pagesDocker Cheat SheetabhinavsrivastavNo ratings yet
- UIJAVAKITDocument33 pagesUIJAVAKITsunny ralph100% (1)
- DDL CommandsDocument65 pagesDDL CommandsVanu ShaNo ratings yet
- Hive Installation On WindowsDocument21 pagesHive Installation On WindowsSrinath YasamNo ratings yet
- Practical - Develop in LaravelDocument3 pagesPractical - Develop in LaravelJayesh PopatNo ratings yet
- Cheat Sheet AngularJSDocument5 pagesCheat Sheet AngularJSKeerthi MaddiralaNo ratings yet
- 0 2 Contiki TutorialDocument33 pages0 2 Contiki TutorialMoazh TawabNo ratings yet
- Odoo in High Availability and Ready For Mass Scalability With Zevenet - ZEVENETDocument10 pagesOdoo in High Availability and Ready For Mass Scalability With Zevenet - ZEVENETIdris IdrisNo ratings yet
- SQL Server DBA ResponsibilitiesDocument2 pagesSQL Server DBA ResponsibilitiestejareddyNo ratings yet
- Python Interview QuestionsDocument24 pagesPython Interview QuestionsAarav HarithasNo ratings yet
- Testing Tools MaterialDocument30 pagesTesting Tools Materialsuman80% (5)
- Javascript M TRLDocument186 pagesJavascript M TRLPuspala ManojkumarNo ratings yet
- Git Basic Usage InstallationDocument3 pagesGit Basic Usage Installationel craft ariasNo ratings yet
- Html5 NotesDocument40 pagesHtml5 NotesTejas159No ratings yet
- Mairon Salazar: Programming Lenguages PresentDocument7 pagesMairon Salazar: Programming Lenguages PresentdantenocturnoNo ratings yet
- Linux and H/W Optimizations For MySQLDocument160 pagesLinux and H/W Optimizations For MySQLOleksiy Kovyrin100% (2)
- How Does Git Work - Git Tutorial For BeginnersDocument10 pagesHow Does Git Work - Git Tutorial For BeginnersJaime SotoNo ratings yet
- Docker SwarmDocument85 pagesDocker SwarmSreenivas KalahastiNo ratings yet
- PHP NotesDocument70 pagesPHP NotesPablo AhmedNo ratings yet
- Bootstrap (Front-End Framework)Document4 pagesBootstrap (Front-End Framework)Asad AliNo ratings yet
- Git Tag: JMS Tech HomeDocument5 pagesGit Tag: JMS Tech HomeMy Linux100% (1)
- The Outbox Pattern: One of My Previous ArticlesDocument11 pagesThe Outbox Pattern: One of My Previous ArticlesAdolfNo ratings yet
- Trucchi Htaccess Per HackerDocument26 pagesTrucchi Htaccess Per HackerRunelore Rune CelticheNo ratings yet
- Oracle To Azure PostgreSQL Migration CookbookDocument13 pagesOracle To Azure PostgreSQL Migration CookbookErik CastroNo ratings yet
- Docker For Local Web Development, Part 5 - HTTPS All The ThingsDocument31 pagesDocker For Local Web Development, Part 5 - HTTPS All The ThingsShirouitNo ratings yet
- Devops NotesDocument15 pagesDevops NotesSHEIKH KAMRAN MUNEERNo ratings yet
- Nagios Is One of The Most Popular Open Source Monitoring SystemsDocument36 pagesNagios Is One of The Most Popular Open Source Monitoring SystemsbadhonctgNo ratings yet
- Chapter 1 IntroductionDocument25 pagesChapter 1 IntroductionStefan JackNo ratings yet
- Laravel FrameworkDocument4 pagesLaravel FrameworkkrutiNo ratings yet
- STATELESS COMPONENT Declared As A Function That Has No State and Returns The Same Markup Given The Same PropsDocument7 pagesSTATELESS COMPONENT Declared As A Function That Has No State and Returns The Same Markup Given The Same Propsproxten dsilvaNo ratings yet
- Query OptimizationDocument138 pagesQuery OptimizationRadu Borza100% (1)
- realpython.com-Python Booleans Optimize Your Code With Truth ValuesDocument27 pagesrealpython.com-Python Booleans Optimize Your Code With Truth ValuesAman AliNo ratings yet
- Basic Web Development ChecklistDocument1 pageBasic Web Development ChecklistAman AliNo ratings yet
- Scraping Media From The Web With PythonDocument9 pagesScraping Media From The Web With PythonAman AliNo ratings yet
- Banday 2019Document30 pagesBanday 2019Aman AliNo ratings yet
- A Survey On Biometrics and Cancelable Biometrics SystemsDocument27 pagesA Survey On Biometrics and Cancelable Biometrics SystemsAman AliNo ratings yet
- Rank Correlation Measure - A Representational Transformation For Biometric Template ProtectionDocument6 pagesRank Correlation Measure - A Representational Transformation For Biometric Template ProtectionAman AliNo ratings yet
- Cancelable Biometrics - A Comprehensive SurveyDocument44 pagesCancelable Biometrics - A Comprehensive SurveyAman AliNo ratings yet
- Binomial Coefficient Analysis With RDocument5 pagesBinomial Coefficient Analysis With RAman AliNo ratings yet
- Advanced Web Scraping TacticsDocument16 pagesAdvanced Web Scraping TacticsAman AliNo ratings yet
- Beta and Gamma Function Implementation in RDocument15 pagesBeta and Gamma Function Implementation in RAman AliNo ratings yet
- Biometric Template ProtectionDocument6 pagesBiometric Template ProtectionAman AliNo ratings yet
- 13 - Performance Best PracticesDocument5 pages13 - Performance Best PracticesAman AliNo ratings yet
- Using Business Rules in MySQLDocument7 pagesUsing Business Rules in MySQLAman AliNo ratings yet
- Jahiliya PDFDocument37 pagesJahiliya PDFAman AliNo ratings yet
- Khadeejah RADocument4 pagesKhadeejah RAAman AliNo ratings yet
- The One After That". Meaning The Sahaba, The Tabi'een and Tabi Tabi'eenDocument37 pagesThe One After That". Meaning The Sahaba, The Tabi'een and Tabi Tabi'eenAman AliNo ratings yet
- Abominable Rapes in The Name of Nikah Halala: An Analytical Study of Halala With Special Reference ToDocument4 pagesAbominable Rapes in The Name of Nikah Halala: An Analytical Study of Halala With Special Reference ToAman AliNo ratings yet
- Zul Abu UbaydahDocument10 pagesZul Abu UbaydahAman AliNo ratings yet
- XML Subjective Questions and AnswersDocument6 pagesXML Subjective Questions and AnswersSaravanan SanthoshNo ratings yet
- Reengineering An Industrial HMI: Approach, Objectives, and ChallengesDocument5 pagesReengineering An Industrial HMI: Approach, Objectives, and ChallengesM. Umair WaheedNo ratings yet
- 14 Week 13 System ImplementationDocument26 pages14 Week 13 System ImplementationhdsasdadNo ratings yet
- Practical 9gsgDocument3 pagesPractical 9gsgPriyank KapuriyaNo ratings yet
- 3.EC8791 - ERTS - 2 Mark Q&ADocument39 pages3.EC8791 - ERTS - 2 Mark Q&AVinothkumar Uruman88% (8)
- Profile Summary Core Competencies: Shrikant Sadashiv MahajanDocument2 pagesProfile Summary Core Competencies: Shrikant Sadashiv Mahajanharishram123456No ratings yet
- Past Paper ITE1712-19S1 - Attempt ReviewDocument30 pagesPast Paper ITE1712-19S1 - Attempt Reviewsafran86msnNo ratings yet
- SACHIN PAKHIDDE - STQA JournalDocument15 pagesSACHIN PAKHIDDE - STQA JournalPrashikp PrashikpNo ratings yet
- ECE391: Computer System Engineering Homework 1 1/ C++ Code Variables Check If ErrorDocument5 pagesECE391: Computer System Engineering Homework 1 1/ C++ Code Variables Check If ErrorHuy Khang NguyễnNo ratings yet
- Introduction To Software Testing: A Practical Guide To Testing, Design, Automation, and ExecutionDocument219 pagesIntroduction To Software Testing: A Practical Guide To Testing, Design, Automation, and Executionerenuenal2003No ratings yet
- OpenText Vendor Invoice Management - Training Doc-1Document20 pagesOpenText Vendor Invoice Management - Training Doc-1Anil ReddyNo ratings yet
- Walk Through 1Document15 pagesWalk Through 1Mạnh Xuân LươngNo ratings yet
- Openbravo Eclipse Devel SetupDocument37 pagesOpenbravo Eclipse Devel SetupJack PremuNo ratings yet
- ORA-06553: PLS-306: Wrong Number or Types of Arguments in Call To 'FUNC1'Document2 pagesORA-06553: PLS-306: Wrong Number or Types of Arguments in Call To 'FUNC1'Salai SukumarNo ratings yet
- PentominoDocument4 pagesPentominoMartha RuizNo ratings yet
- Doulos SysVlog Interface Modports PaperDocument8 pagesDoulos SysVlog Interface Modports PaperkrishnaavNo ratings yet
- CPP v1.1Document447 pagesCPP v1.1Minh NguyenNo ratings yet
- Introduction To The QUINCY CDocument14 pagesIntroduction To The QUINCY CPavitra RajavelooNo ratings yet
- OS Lab ManualDocument89 pagesOS Lab ManualLaiba BabarNo ratings yet
- SynKernelDiag2019 05 31 - 18 04 35Document1,645 pagesSynKernelDiag2019 05 31 - 18 04 35Youssef El-BadryNo ratings yet
- Microsoft Testkings ms-700 PDF 2020-May-03 by Keith 41q VceDocument12 pagesMicrosoft Testkings ms-700 PDF 2020-May-03 by Keith 41q Vcejaywhite lightNo ratings yet
- Airline Reservation SystemDocument18 pagesAirline Reservation SystemAsha AshaNo ratings yet
- Distributed Systems Lab ProgramsDocument2 pagesDistributed Systems Lab ProgramsGaurav Jaiswal100% (1)
- JavaScript - Object Oriented Programming Using ES6 - by NC Patro - CodeburstDocument1 pageJavaScript - Object Oriented Programming Using ES6 - by NC Patro - CodeburstBleep NewsNo ratings yet
- Eclipse Dev Programmer's Guide 3.4 GalileoDocument628 pagesEclipse Dev Programmer's Guide 3.4 GalileoRemoteMethod100% (2)
- 2.6 Years of Experience As A Build and Release/ Devops Engineering in Software Configuration andDocument5 pages2.6 Years of Experience As A Build and Release/ Devops Engineering in Software Configuration andFasiNo ratings yet
- Debugging Classification and Anti-Debugging StrategiesDocument6 pagesDebugging Classification and Anti-Debugging Strategiesproxymo1No ratings yet
- 12 IpDocument14 pages12 IpJígñésh Jáy PrákáshNo ratings yet
- Software Engineering Principles & Best PracticesDocument8 pagesSoftware Engineering Principles & Best PracticesJeganNo ratings yet
- Computer Security TechniquesDocument36 pagesComputer Security TechniquesIDRISA NKUNYANo ratings yet