Download as pdf or txt
You might also like
- A Pin-Light, BentDocument6 pagesA Pin-Light, BentSaaj Alfred Jarry100% (5)
- A Pin-Light, BentDocument6 pagesA Pin-Light, BentSaaj Alfred Jarry100% (5)
- Convergence Introduction: ©2021 Delta Green PartnershipDocument19 pagesConvergence Introduction: ©2021 Delta Green PartnershipNat Linken100% (1)
- Ultrasonic Directive SpeakerDocument42 pagesUltrasonic Directive SpeakerNakul NemaNo ratings yet
- Staff Emotional Intelligence ReportDocument4 pagesStaff Emotional Intelligence Reporttanveer ahmedNo ratings yet
- Rethinking The Box: Approaches To The Reality of Electronic Music PerformanceDocument12 pagesRethinking The Box: Approaches To The Reality of Electronic Music PerformanceMatthias StrassmüllerNo ratings yet
- Tools - For - Studying - Spectral - Temporal - Effects - of - Noise - 2010 INTERNOISE - 511Document10 pagesTools - For - Studying - Spectral - Temporal - Effects - of - Noise - 2010 INTERNOISE - 511Rami MalekNo ratings yet
- Haptics in Computer Music: A Paradigm ShiftDocument4 pagesHaptics in Computer Music: A Paradigm ShiftipiresNo ratings yet
- From Sound Modeling To Analysis-Synthesis of Sounds: 1 Scope of The ArticleDocument9 pagesFrom Sound Modeling To Analysis-Synthesis of Sounds: 1 Scope of The ArticleSlavyana DraganovaNo ratings yet
- A Corpus-Based Method For Controlling Guitar Feedback: Sam Ferguson, Andrew Johnston Aengus MartinDocument6 pagesA Corpus-Based Method For Controlling Guitar Feedback: Sam Ferguson, Andrew Johnston Aengus Martinjpmac5No ratings yet
- Study of Preference For Surround Microphone Techniques Used in The Recording of Choir and Instrumental EnsembleDocument14 pagesStudy of Preference For Surround Microphone Techniques Used in The Recording of Choir and Instrumental EnsembleHuỳnh Lê Hoài BảoNo ratings yet
- Urban Sound ClassificationDocument6 pagesUrban Sound Classificationamit kNo ratings yet
- Designing Environmental SoundsDocument5 pagesDesigning Environmental SoundsJunona TutuneaNo ratings yet
- Acoustical ParametersDocument26 pagesAcoustical ParametersFederico Nahuel CacavelosNo ratings yet
- Realtime and Accurate Musical Control ofDocument9 pagesRealtime and Accurate Musical Control ofgerardo7martinez-13No ratings yet
- Acoustic Environment ClassificationDocument10 pagesAcoustic Environment ClassificationSyukriNizamNo ratings yet
- PDFDocument30 pagesPDFcosasdeangelNo ratings yet
- Sergio Bleda José J. López Basilio PueoDocument6 pagesSergio Bleda José J. López Basilio PueoVenkatesan Thanigai ArasuNo ratings yet
- Fundamental Concepts of AcousticsDocument8 pagesFundamental Concepts of AcousticsAADIL AHMED A50% (2)
- Multitone Testing of Sound System Components - Some Results and Conclusions, Part 1: History and TheoryDocument40 pagesMultitone Testing of Sound System Components - Some Results and Conclusions, Part 1: History and Theoryjose kornelukNo ratings yet
- Aucoutics ProjectDocument45 pagesAucoutics ProjectDhiraj KolheNo ratings yet
- AuralizationDocument10 pagesAuralizationguzskaNo ratings yet
- Chameli Devi Institute of Technology & Management, IndoreDocument15 pagesChameli Devi Institute of Technology & Management, IndoreNazsh AslamNo ratings yet
- A History of Audio EffectsDocument27 pagesA History of Audio EffectsVini MachajewskiNo ratings yet
- A Kind of Integrated Serial Algorithms For Noise Reduction and Characteristics Expanding in Respiratory SoundDocument12 pagesA Kind of Integrated Serial Algorithms For Noise Reduction and Characteristics Expanding in Respiratory SoundDmytro AshkinaziNo ratings yet
- A Paradigm For Physical Interaction With Sound in 3-D Audio SpaceDocument9 pagesA Paradigm For Physical Interaction With Sound in 3-D Audio SpaceRicardo Cubillos PeñaNo ratings yet
- Structured Additive Synthesis: Towards A Model of Sound Timbre and Electroacoustic Music FormsDocument4 pagesStructured Additive Synthesis: Towards A Model of Sound Timbre and Electroacoustic Music FormsJuan Ignacio Isgro100% (1)
- 21 Howard1997Document13 pages21 Howard1997jesús buendia puyo100% (1)
- Villanueva-Rivera Et Al 2011Document14 pagesVillanueva-Rivera Et Al 2011Jaime Caro VeraNo ratings yet
- Exploring Phase Information in Sound Source SeparaDocument9 pagesExploring Phase Information in Sound Source SeparaPaulo FeijãoNo ratings yet
- Keller Et Al2010 ICMCDocument8 pagesKeller Et Al2010 ICMCmusicoyargentinoNo ratings yet
- Full TextDocument6 pagesFull TextLaura SalasNo ratings yet
- Modal Synthesis of Weapon Sounds PDFDocument7 pagesModal Synthesis of Weapon Sounds PDFDmitry NemtsoffNo ratings yet
- Virtual Acoustics at The Service of Music Performance and RecordingDocument5 pagesVirtual Acoustics at The Service of Music Performance and RecordingJair AlvesNo ratings yet
- FFT Analysis As A Creative Tool in Live PDFDocument4 pagesFFT Analysis As A Creative Tool in Live PDFjluispostigaNo ratings yet
- A Design For Active Noise Cancellation in The 2Cc CouplerDocument4 pagesA Design For Active Noise Cancellation in The 2Cc CouplerAnuroop G RaoNo ratings yet
- Acmus: Design and Simulation of Music Listening Environments Fernando Iazzetta, Fabio Kon, Flavio S. C. Da SilvaDocument7 pagesAcmus: Design and Simulation of Music Listening Environments Fernando Iazzetta, Fabio Kon, Flavio S. C. Da SilvaGilson BarbozaNo ratings yet
- Gsound: Interactive Sound Propagation For GamesDocument6 pagesGsound: Interactive Sound Propagation For GamesMAURICIO LANDEROSNo ratings yet
- Soundscape Design Through Evolutionary Engines: José Fornari, Adolfo Maia JR., Jônatas ManzolliDocument11 pagesSoundscape Design Through Evolutionary Engines: José Fornari, Adolfo Maia JR., Jônatas ManzollitutifornariNo ratings yet
- Synthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezDocument5 pagesSynthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezZellagui EnergyNo ratings yet
- Morphing Techniques For Enhanced Scat SingingDocument4 pagesMorphing Techniques For Enhanced Scat SingingMilton Villarroel G.No ratings yet
- Interactive Environmental Sound Installation For Music Therapy PurposeDocument4 pagesInteractive Environmental Sound Installation For Music Therapy PurposeNicki Yuta PNo ratings yet
- Active Noise Control, IEEE Signal Process. Mag., OctoberDocument25 pagesActive Noise Control, IEEE Signal Process. Mag., OctoberNeamu ValentinNo ratings yet
- Digital Sound Synthesis by Physical ModellingDocument12 pagesDigital Sound Synthesis by Physical ModellingBrandy ThomasNo ratings yet
- Audio Segment HeuristicDocument10 pagesAudio Segment HeuristicSuresh KumarNo ratings yet
- Carpentier 2016 OLOFONIA EN Holophonic Sound in Ircam's Concert HallDocument21 pagesCarpentier 2016 OLOFONIA EN Holophonic Sound in Ircam's Concert HallsammarcoNo ratings yet
- SINOHIN JOSHUA PHYSICS02 Midterm HW02Document6 pagesSINOHIN JOSHUA PHYSICS02 Midterm HW02morikun2003No ratings yet
- A Percussive Sound Synthesizer Based On Physical and Perceptual AttributesDocument10 pagesA Percussive Sound Synthesizer Based On Physical and Perceptual AttributesΜέμνων ΜπερδεμένοςNo ratings yet
- Applsci 06 00129 PDFDocument46 pagesApplsci 06 00129 PDFRobPNo ratings yet
- Engineering Acoustics Course NotesDocument84 pagesEngineering Acoustics Course Notes王龙No ratings yet
- Christian Dittmar and Christian UhleDocument8 pagesChristian Dittmar and Christian UhlejaknoppNo ratings yet
- In Tech 0305Document7 pagesIn Tech 0305Rainy Shady MistuNo ratings yet
- A Multi-Channel System For Sound Control in The Open Space: Wojciech CIESIELKADocument19 pagesA Multi-Channel System For Sound Control in The Open Space: Wojciech CIESIELKAdonald141No ratings yet
- Analisis Emocional ErlkoningDocument20 pagesAnalisis Emocional ErlkoningNuria Sánchez PulidoNo ratings yet
- 21 LeGroux-ICMC08Document4 pages21 LeGroux-ICMC08Judap FlocNo ratings yet
- Introduction To Ambisonics - Rev. 2015Document25 pagesIntroduction To Ambisonics - Rev. 2015Francesca OrtolaniNo ratings yet
- Timbral Hauntings: An Interactive System Re-Interpreting The Present in Echoes of The PastDocument8 pagesTimbral Hauntings: An Interactive System Re-Interpreting The Present in Echoes of The PastfedoerigoNo ratings yet
- Overlapped Music Segmentation Using A New Effective Feature and Random ForestsDocument9 pagesOverlapped Music Segmentation Using A New Effective Feature and Random ForestsIAES IJAINo ratings yet
- Lab Report 2Document9 pagesLab Report 2jfkNo ratings yet
- The Columbine Massacre - Barack Obama - Zionist Wolf in Sheep's (PDFDrive)Document18 pagesThe Columbine Massacre - Barack Obama - Zionist Wolf in Sheep's (PDFDrive)Roman TilahunNo ratings yet
- Analysis of Digital Audio Effects Using Simulink and C6713 DSKDocument6 pagesAnalysis of Digital Audio Effects Using Simulink and C6713 DSKLinhDangNo ratings yet
- Designing Quiet Structures: A Sound Power Minimization ApproachFrom EverandDesigning Quiet Structures: A Sound Power Minimization ApproachNo ratings yet
- Score KaijaSaariaho NoaNoaDocument6 pagesScore KaijaSaariaho NoaNoaSaaj Alfred JarryNo ratings yet
- Microsound by Curtis Roads - p19Document1 pageMicrosound by Curtis Roads - p19Saaj Alfred JarryNo ratings yet
- Symbiosis MarshalDocument15 pagesSymbiosis MarshalSaaj Alfred JarryNo ratings yet
- This Content Downloaded From 193.54.174.3 On Mon, 01 Mar 2021 09:45:02 UTCDocument21 pagesThis Content Downloaded From 193.54.174.3 On Mon, 01 Mar 2021 09:45:02 UTCSaaj Alfred JarryNo ratings yet
- Subjectivity and The Construction of Emotion in The Music of BjörkDocument28 pagesSubjectivity and The Construction of Emotion in The Music of BjörkSaaj Alfred JarryNo ratings yet
- The Complexity of Xenakis's Notion of Space: BstractDocument14 pagesThe Complexity of Xenakis's Notion of Space: BstractSaaj Alfred JarryNo ratings yet
- Oresteia Nouvelle EditionDocument152 pagesOresteia Nouvelle EditionSaaj Alfred JarryNo ratings yet
- CH 19 Cash and Liquidity Management Appendix Class WorkDocument4 pagesCH 19 Cash and Liquidity Management Appendix Class WorkMhmd KaramNo ratings yet
- 2-Tourism and CrimeDocument17 pages2-Tourism and CrimeJohn Melvin AbonitallaNo ratings yet
- VochysiaceaeDocument5 pagesVochysiaceaeElyasse B.No ratings yet
- Department of Public Works and Highways: Regional Office Vii Cebu 6Th District Engineering OfficeDocument10 pagesDepartment of Public Works and Highways: Regional Office Vii Cebu 6Th District Engineering OfficeLolNo ratings yet
- Research Paper About Drugs AbuseDocument7 pagesResearch Paper About Drugs Abusefvfj1pqe100% (1)
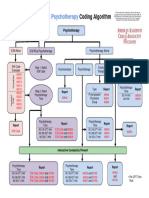
- E and M and Psychotherapy Coding AlgorithmDocument1 pageE and M and Psychotherapy Coding AlgorithmRashiden MadjalesNo ratings yet
- S6L1D-E4 Wdg.311/312 - Technical Data SheetDocument9 pagesS6L1D-E4 Wdg.311/312 - Technical Data SheetAlfonso RivasNo ratings yet
- IMS Transaction ManagerDocument147 pagesIMS Transaction ManagerBalaji Kishore Kumar100% (2)
- Fleetwood Town Centre PlanDocument65 pagesFleetwood Town Centre PlanPaulNo ratings yet
- Book of AbstractsDocument108 pagesBook of Abstractssab parNo ratings yet
- Mortal Kombat X FatalitiesDocument3 pagesMortal Kombat X FatalitiessdfjsadNo ratings yet
- CHAPTER 6 - HOMEWORK - With KeyDocument8 pagesCHAPTER 6 - HOMEWORK - With KeyVõ Ngọc HânNo ratings yet
- Metamorphism: Directions: The Transformation of A Certain Rock-Type Into A Metamorphic Rock TakesDocument4 pagesMetamorphism: Directions: The Transformation of A Certain Rock-Type Into A Metamorphic Rock TakesLizelle Anie ArcilloNo ratings yet
- Fuel Injection Systems: Dedicated To High-PrecisionDocument4 pagesFuel Injection Systems: Dedicated To High-Precisionfrancoisclef5083No ratings yet
- SP Catalogue JAN-DECDocument20 pagesSP Catalogue JAN-DECRiverland Welding and Tool SuppliesNo ratings yet
- 555 Timers With PSpice LabDocument6 pages555 Timers With PSpice LabHatem MOKHTARI0% (1)
- G3 Success With Math TestsDocument58 pagesG3 Success With Math TestsNgoc Mai100% (2)
- J6-S9014 DatasheetDocument2 pagesJ6-S9014 DatasheetOreol100% (1)
- Software Effort Estimation Based On Use Case Reuse (Back Propagation)Document11 pagesSoftware Effort Estimation Based On Use Case Reuse (Back Propagation)IJRASETPublicationsNo ratings yet
- V.I. Karas Et Al - Kinetic Simulation of Fields Excitation and Particle Acceleration by Laser Beat Wave in Non-Homogeneous PlasmasDocument3 pagesV.I. Karas Et Al - Kinetic Simulation of Fields Excitation and Particle Acceleration by Laser Beat Wave in Non-Homogeneous PlasmasVasmazxNo ratings yet
- II-Day 6Document8 pagesII-Day 6Sir AsherNo ratings yet
- 1 Diesel Systems: Injection Pump Specification Customer Part No. Ar50002 EwnonnoDocument3 pages1 Diesel Systems: Injection Pump Specification Customer Part No. Ar50002 EwnonnoRobert Alexander FrankNo ratings yet
- Teaching GrammarDocument22 pagesTeaching GrammarMUHAMMAD RAFFINo ratings yet
- Ficha Técnica de ATF QuaquerDocument4 pagesFicha Técnica de ATF QuaquerRodrigo AguirreNo ratings yet
- The Student Pulse Panel BookDocument12 pagesThe Student Pulse Panel BookTran Minh TungNo ratings yet
- Application For Radio Operator CertificateDocument1 pageApplication For Radio Operator CertificateToshiNo ratings yet
- Digital Educational Technology in Improving Professional Auditory CompetenceDocument3 pagesDigital Educational Technology in Improving Professional Auditory CompetenceOpen Access JournalNo ratings yet
- 1246 SP 4 Emm 24003 B2Document132 pages1246 SP 4 Emm 24003 B2Arash Aghagol100% (1)