
Bivariate Association of Data
Bivariate Association of Data
You might also like
- Air Brake Work BookDocument47 pagesAir Brake Work BookRudolf Oppermann50% (2)
- Logistic Regression Project With PythonDocument14 pagesLogistic Regression Project With PythonMeryem HarimNo ratings yet
- Qgis Map Design SampleDocument20 pagesQgis Map Design SampleKalamaro71% (7)
- Homework2 PDFDocument3 pagesHomework2 PDFTeoTheSpazNo ratings yet
- 2 - Quiz 3 Instructions - Set O Group of 4hDocument3 pages2 - Quiz 3 Instructions - Set O Group of 4hKimberly IgnacioNo ratings yet
- Supplementary Learning Materials For Senior High School: Tagum City College of Science and Technology Foundation IncDocument18 pagesSupplementary Learning Materials For Senior High School: Tagum City College of Science and Technology Foundation Incjaylyn carasNo ratings yet
- Stata SwiidDocument6 pagesStata Swiid24a4010600No ratings yet
- Using Ggplot2 For Plots in RDocument8 pagesUsing Ggplot2 For Plots in RDhruv BhallaNo ratings yet
- BIA 658 Social Network Analysis - Midterm Exam Fall 2020Document3 pagesBIA 658 Social Network Analysis - Midterm Exam Fall 2020Asif Ahmed NeloyNo ratings yet
- PS 2 TextDocument4 pagesPS 2 TextrickyfavarettoNo ratings yet
- Data Visualization in Python: Worksheet 2.6Document1 pageData Visualization in Python: Worksheet 2.6Emely GonzagaNo ratings yet
- Home Assignment 2 PDFDocument3 pagesHome Assignment 2 PDFГеоргий РакNo ratings yet
- IE QuestionsDocument6 pagesIE QuestionsPreethi VNo ratings yet
- Topic 1Document6 pagesTopic 1arp140102No ratings yet
- Modelling COVID-19 Outbreak: Segmented Regression To Assess Lockdown EffectivenessDocument5 pagesModelling COVID-19 Outbreak: Segmented Regression To Assess Lockdown EffectivenessDebabrata SahaNo ratings yet
- Basic Stata Graphics For Economics StudentsDocument31 pagesBasic Stata Graphics For Economics StudentsLIUL LB TamiratNo ratings yet
- Introduction To The TIDYVERSEDocument4 pagesIntroduction To The TIDYVERSEFor ThingsNo ratings yet
- Econometric Analysis of Panel DataDocument14 pagesEconometric Analysis of Panel Data1111111111111-859751No ratings yet
- Is There A Correlation Between Average Gross Domestic Product Per Capita (GDP) and Countries' Averag 2Document16 pagesIs There A Correlation Between Average Gross Domestic Product Per Capita (GDP) and Countries' Averag 2Hania ElgawsakyNo ratings yet
- Engle Ledoit Wolf (2019)Document14 pagesEngle Ledoit Wolf (2019)KadirNo ratings yet
- CU-2020 B.A. B.Sc. (Honours) Economics Semester-V Paper-DSE-A-1P Practical QPDocument2 pagesCU-2020 B.A. B.Sc. (Honours) Economics Semester-V Paper-DSE-A-1P Practical QPRiju PrasadNo ratings yet
- Arellano Bond GMM EstimatorsDocument10 pagesArellano Bond GMM Estimatorsamnoman17100% (1)
- Economics II881 0Ph5UNVbG9Document2 pagesEconomics II881 0Ph5UNVbG9Nell CrastoNo ratings yet
- Exercise 1Document5 pagesExercise 1Yassine AzzimaniNo ratings yet
- Diago, Primel MS 102 Prelim M1 L2Document12 pagesDiago, Primel MS 102 Prelim M1 L2Primel DiagoNo ratings yet
- ch02 AnsDocument11 pagesch02 AnsAmarjargal NorovNo ratings yet
- 27-Principlesgis UnlockedDocument74 pages27-Principlesgis UnlockedCHRISTIAN LANDAVAZONo ratings yet
- DS100-3 WS 2.6 Gonzaga EhDocument6 pagesDS100-3 WS 2.6 Gonzaga EhEmely GonzagaNo ratings yet
- A Neuro Fuzzy System Based Inflation Prediction of Agricultural CommoditiesDocument6 pagesA Neuro Fuzzy System Based Inflation Prediction of Agricultural CommoditiesAbhishek DuttaNo ratings yet
- MATH AI SL IA kcs199 AnnotatedDocument19 pagesMATH AI SL IA kcs199 AnnotatedReena NarangNo ratings yet
- Example Metrics - Final Assignment - WS1920 - SHDocument9 pagesExample Metrics - Final Assignment - WS1920 - SHNinò GogsaNo ratings yet
- AnswersDocument19 pagesAnswersjayaniNo ratings yet
- Mathematics in The Modern World: 2015 Census of PopulationDocument4 pagesMathematics in The Modern World: 2015 Census of PopulationJhuliane Ralph50% (2)
- GretlDocument83 pagesGretlKanat ÇırpNo ratings yet
- Growth and Redistribution Co Onents of Changes in Poverty MeasuresDocument21 pagesGrowth and Redistribution Co Onents of Changes in Poverty MeasuresBelinda RoemerNo ratings yet
- Joshi Final ProjectDocument9 pagesJoshi Final Projectrahulsg0358No ratings yet
- Exercise 1: Regression With Time Series Data Using MicrofitDocument5 pagesExercise 1: Regression With Time Series Data Using Microfitabsam82No ratings yet
- Measuring The Output Gap Using Large Datasets: Matteo Barigozzi Matteo LucianiDocument44 pagesMeasuring The Output Gap Using Large Datasets: Matteo Barigozzi Matteo Luciani6doitNo ratings yet
- 04.2 DigitalSoilMappinginEarthEngine RandomForestRegressionDocument21 pages04.2 DigitalSoilMappinginEarthEngine RandomForestRegressionjoaonitNo ratings yet
- 03 9708 22 2RP Afp M24 23022024050650Document4 pages03 9708 22 2RP Afp M24 23022024050650Frost IecwolfNo ratings yet
- How To Use Dummy X VariablesDocument7 pagesHow To Use Dummy X VariablesPrasad HegdeNo ratings yet
- Modeling Utah Population Data: Estimates of Utah Resident Population, in 100,000's Year XDocument8 pagesModeling Utah Population Data: Estimates of Utah Resident Population, in 100,000's Year Xapi-284563579No ratings yet
- Eviews Class ProblemsDocument3 pagesEviews Class ProblemsLakshmiNo ratings yet
- Deep DFMDocument40 pagesDeep DFMde deNo ratings yet
- FRA Milestone 1Document33 pagesFRA Milestone 1Nitya BalakrishnanNo ratings yet
- Genmath 11 - Q3 - Las 4 RTPDocument4 pagesGenmath 11 - Q3 - Las 4 RTPcass dumpNo ratings yet
- Skyline Plots PDFDocument35 pagesSkyline Plots PDFMarijaTodorovicNo ratings yet
- Assignment of Introduction To StatisticsDocument3 pagesAssignment of Introduction To StatisticsbashatigabuNo ratings yet
- EC 208 - HW2 - Spring 22 v1.2Document2 pagesEC 208 - HW2 - Spring 22 v1.2Umut Mert EğerciNo ratings yet
- Sissoko 2007Document77 pagesSissoko 2007Joel ChineduNo ratings yet
- A New Look at CryptocurrenciesDocument4 pagesA New Look at CryptocurrenciesFar hatNo ratings yet
- Distributed Csps by Graph Partitioning: Miguel A. Salido, Federico BarberDocument8 pagesDistributed Csps by Graph Partitioning: Miguel A. Salido, Federico Barberkhaoula BOUAZZINo ratings yet
- Assignment of Introduction To Statistics - UpdatedDocument3 pagesAssignment of Introduction To Statistics - UpdatedbashatigabuNo ratings yet
- 2021 en Tutorial 7Document5 pages2021 en Tutorial 7Hari-haran KUMARNo ratings yet
- Basic Econometrics 5th Edition Gujarati Solutions ManualDocument12 pagesBasic Econometrics 5th Edition Gujarati Solutions ManualAmyWaltersxknsf100% (15)
- MC Math 13 Module 3Document16 pagesMC Math 13 Module 3Raffy BarotillaNo ratings yet
- Document 4Document16 pagesDocument 4Su BoccardNo ratings yet
- Lista 2 Macro IIIDocument10 pagesLista 2 Macro IIIraphael guimaraesNo ratings yet
- Ggplot2 ExerciseDocument6 pagesGgplot2 Exerciseretokoller44No ratings yet
- Mapping the Spatial Distribution of Poverty Using Satellite Imagery in ThailandFrom EverandMapping the Spatial Distribution of Poverty Using Satellite Imagery in ThailandNo ratings yet
- Mapping the Spatial Distribution of Poverty Using Satellite Imagery in the PhilippinesFrom EverandMapping the Spatial Distribution of Poverty Using Satellite Imagery in the PhilippinesNo ratings yet
- UNIT-2: Flywheels and Turning Moment DiagramsDocument54 pagesUNIT-2: Flywheels and Turning Moment DiagramsPraveen KumarNo ratings yet
- 1PH7228-7HF00-0AB8 2D Dimension ENDocument1 page1PH7228-7HF00-0AB8 2D Dimension ENZulfikar FahmiNo ratings yet
- Tekla Software Training in Bangalore - Google SearchDocument1 pageTekla Software Training in Bangalore - Google SearchMohammedNo ratings yet
- MUY IMPORTANTEEEEEE ENH1350EXT Data Sheet - 180621 - SG - 0Document8 pagesMUY IMPORTANTEEEEEE ENH1350EXT Data Sheet - 180621 - SG - 0Omar PerezNo ratings yet
- CrowdGAN - Identity-Free Interactive Crowd Video Generation and BeyondDocument16 pagesCrowdGAN - Identity-Free Interactive Crowd Video Generation and BeyondmmmmNo ratings yet
- 1702-EN-ST-000-SD-181 Sht-03 OF 04 Rev-0 PDFDocument1 page1702-EN-ST-000-SD-181 Sht-03 OF 04 Rev-0 PDFbharani dharanNo ratings yet
- Sriharshini InternshipDocument12 pagesSriharshini InternshipSriharshini 158No ratings yet
- 459251104-DCS-UH-1H-Flight-Manual-EN-pdf 3Document1 page459251104-DCS-UH-1H-Flight-Manual-EN-pdf 3mav87th-1No ratings yet
- Effetto Pietra: Stone LookDocument23 pagesEffetto Pietra: Stone LookClaudio AllegriNo ratings yet
- Pssewindandsolarmodels CasestudiesDocument69 pagesPssewindandsolarmodels Casestudiespra0% (1)
- Dokumen Data Inventaris Di PT SRDocument22 pagesDokumen Data Inventaris Di PT SRPriambodo AriewibowoNo ratings yet
- "Design & Development Analysis of Quadcopter": Parag Parihar, Priyanshu Bhawsar, Piyush HargodDocument6 pages"Design & Development Analysis of Quadcopter": Parag Parihar, Priyanshu Bhawsar, Piyush HargodAnonymous e7Rajar9SwNo ratings yet
- A.Nisansala Weeraperuma ResumeDocument1 pageA.Nisansala Weeraperuma Resumenisansaladilshani8No ratings yet
- Sony dvp-fx720 Ver1.4Document69 pagesSony dvp-fx720 Ver1.4david godinezNo ratings yet
- Pitching Research: Bond University (Professorial Fellow) University of Queensland (Emeritus Professor)Document37 pagesPitching Research: Bond University (Professorial Fellow) University of Queensland (Emeritus Professor)Anisa LalaNo ratings yet
- Project ReportDocument22 pagesProject ReportHarsh NegiNo ratings yet
- Rec ColumnDocument2 pagesRec Columnnirmal sutharNo ratings yet
- CISSP Exam SimulationDocument145 pagesCISSP Exam SimulationMac Joy100% (2)
- Lesson Plan Week 3 NSDocument4 pagesLesson Plan Week 3 NSLewaa HaidarNo ratings yet
- May 2021 Examination Diet School of Mathematics & Statistics MT4614Document6 pagesMay 2021 Examination Diet School of Mathematics & Statistics MT4614Tev WallaceNo ratings yet
- 3.1 Expression StatementsDocument3 pages3.1 Expression Statementsbambi2002No ratings yet
- Unit V Map Design & LayoutDocument32 pagesUnit V Map Design & LayoutRashkv428 kvNo ratings yet
- Ex No: 1 Date: Program On Saas To Create Word DocumentDocument18 pagesEx No: 1 Date: Program On Saas To Create Word Documentmathi yazhaganNo ratings yet
- VHF 1000 P DSCDocument42 pagesVHF 1000 P DSCOleksandr IvashchenkoNo ratings yet
- Cocina 6 Hornillas de TopeDocument2 pagesCocina 6 Hornillas de Topejrangel.cenvihNo ratings yet
- AD5933 CDocument7 pagesAD5933 CkakiksNo ratings yet
- Blu 4 Eng 2019Document14 pagesBlu 4 Eng 2019BAHZAD SEDEEQNo ratings yet
- CDX MP40Document54 pagesCDX MP40scribduser1979No ratings yet
- Vinyl Tubing (MS-01-108) R2Document1 pageVinyl Tubing (MS-01-108) R2herysyam1980No ratings yet



























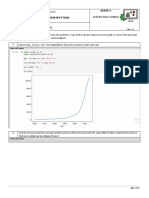





























































Download as pdf or txt
You might also like
- Air Brake Work BookDocument47 pagesAir Brake Work BookRudolf Oppermann50% (2)
- Logistic Regression Project With PythonDocument14 pagesLogistic Regression Project With PythonMeryem HarimNo ratings yet
- Qgis Map Design SampleDocument20 pagesQgis Map Design SampleKalamaro71% (7)
- Homework2 PDFDocument3 pagesHomework2 PDFTeoTheSpazNo ratings yet
- 2 - Quiz 3 Instructions - Set O Group of 4hDocument3 pages2 - Quiz 3 Instructions - Set O Group of 4hKimberly IgnacioNo ratings yet
- Supplementary Learning Materials For Senior High School: Tagum City College of Science and Technology Foundation IncDocument18 pagesSupplementary Learning Materials For Senior High School: Tagum City College of Science and Technology Foundation Incjaylyn carasNo ratings yet
- Stata SwiidDocument6 pagesStata Swiid24a4010600No ratings yet
- Using Ggplot2 For Plots in RDocument8 pagesUsing Ggplot2 For Plots in RDhruv BhallaNo ratings yet
- BIA 658 Social Network Analysis - Midterm Exam Fall 2020Document3 pagesBIA 658 Social Network Analysis - Midterm Exam Fall 2020Asif Ahmed NeloyNo ratings yet
- PS 2 TextDocument4 pagesPS 2 TextrickyfavarettoNo ratings yet
- Data Visualization in Python: Worksheet 2.6Document1 pageData Visualization in Python: Worksheet 2.6Emely GonzagaNo ratings yet
- Home Assignment 2 PDFDocument3 pagesHome Assignment 2 PDFГеоргий РакNo ratings yet
- IE QuestionsDocument6 pagesIE QuestionsPreethi VNo ratings yet
- Topic 1Document6 pagesTopic 1arp140102No ratings yet
- Modelling COVID-19 Outbreak: Segmented Regression To Assess Lockdown EffectivenessDocument5 pagesModelling COVID-19 Outbreak: Segmented Regression To Assess Lockdown EffectivenessDebabrata SahaNo ratings yet
- Basic Stata Graphics For Economics StudentsDocument31 pagesBasic Stata Graphics For Economics StudentsLIUL LB TamiratNo ratings yet
- Introduction To The TIDYVERSEDocument4 pagesIntroduction To The TIDYVERSEFor ThingsNo ratings yet
- Econometric Analysis of Panel DataDocument14 pagesEconometric Analysis of Panel Data1111111111111-859751No ratings yet
- Is There A Correlation Between Average Gross Domestic Product Per Capita (GDP) and Countries' Averag 2Document16 pagesIs There A Correlation Between Average Gross Domestic Product Per Capita (GDP) and Countries' Averag 2Hania ElgawsakyNo ratings yet
- Engle Ledoit Wolf (2019)Document14 pagesEngle Ledoit Wolf (2019)KadirNo ratings yet
- CU-2020 B.A. B.Sc. (Honours) Economics Semester-V Paper-DSE-A-1P Practical QPDocument2 pagesCU-2020 B.A. B.Sc. (Honours) Economics Semester-V Paper-DSE-A-1P Practical QPRiju PrasadNo ratings yet
- Arellano Bond GMM EstimatorsDocument10 pagesArellano Bond GMM Estimatorsamnoman17100% (1)
- Economics II881 0Ph5UNVbG9Document2 pagesEconomics II881 0Ph5UNVbG9Nell CrastoNo ratings yet
- Exercise 1Document5 pagesExercise 1Yassine AzzimaniNo ratings yet
- Diago, Primel MS 102 Prelim M1 L2Document12 pagesDiago, Primel MS 102 Prelim M1 L2Primel DiagoNo ratings yet
- ch02 AnsDocument11 pagesch02 AnsAmarjargal NorovNo ratings yet
- 27-Principlesgis UnlockedDocument74 pages27-Principlesgis UnlockedCHRISTIAN LANDAVAZONo ratings yet
- DS100-3 WS 2.6 Gonzaga EhDocument6 pagesDS100-3 WS 2.6 Gonzaga EhEmely GonzagaNo ratings yet
- A Neuro Fuzzy System Based Inflation Prediction of Agricultural CommoditiesDocument6 pagesA Neuro Fuzzy System Based Inflation Prediction of Agricultural CommoditiesAbhishek DuttaNo ratings yet
- MATH AI SL IA kcs199 AnnotatedDocument19 pagesMATH AI SL IA kcs199 AnnotatedReena NarangNo ratings yet
- Example Metrics - Final Assignment - WS1920 - SHDocument9 pagesExample Metrics - Final Assignment - WS1920 - SHNinò GogsaNo ratings yet
- AnswersDocument19 pagesAnswersjayaniNo ratings yet
- Mathematics in The Modern World: 2015 Census of PopulationDocument4 pagesMathematics in The Modern World: 2015 Census of PopulationJhuliane Ralph50% (2)
- GretlDocument83 pagesGretlKanat ÇırpNo ratings yet
- Growth and Redistribution Co Onents of Changes in Poverty MeasuresDocument21 pagesGrowth and Redistribution Co Onents of Changes in Poverty MeasuresBelinda RoemerNo ratings yet
- Joshi Final ProjectDocument9 pagesJoshi Final Projectrahulsg0358No ratings yet
- Exercise 1: Regression With Time Series Data Using MicrofitDocument5 pagesExercise 1: Regression With Time Series Data Using Microfitabsam82No ratings yet
- Measuring The Output Gap Using Large Datasets: Matteo Barigozzi Matteo LucianiDocument44 pagesMeasuring The Output Gap Using Large Datasets: Matteo Barigozzi Matteo Luciani6doitNo ratings yet
- 04.2 DigitalSoilMappinginEarthEngine RandomForestRegressionDocument21 pages04.2 DigitalSoilMappinginEarthEngine RandomForestRegressionjoaonitNo ratings yet
- 03 9708 22 2RP Afp M24 23022024050650Document4 pages03 9708 22 2RP Afp M24 23022024050650Frost IecwolfNo ratings yet
- How To Use Dummy X VariablesDocument7 pagesHow To Use Dummy X VariablesPrasad HegdeNo ratings yet
- Modeling Utah Population Data: Estimates of Utah Resident Population, in 100,000's Year XDocument8 pagesModeling Utah Population Data: Estimates of Utah Resident Population, in 100,000's Year Xapi-284563579No ratings yet
- Eviews Class ProblemsDocument3 pagesEviews Class ProblemsLakshmiNo ratings yet
- Deep DFMDocument40 pagesDeep DFMde deNo ratings yet
- FRA Milestone 1Document33 pagesFRA Milestone 1Nitya BalakrishnanNo ratings yet
- Genmath 11 - Q3 - Las 4 RTPDocument4 pagesGenmath 11 - Q3 - Las 4 RTPcass dumpNo ratings yet
- Skyline Plots PDFDocument35 pagesSkyline Plots PDFMarijaTodorovicNo ratings yet
- Assignment of Introduction To StatisticsDocument3 pagesAssignment of Introduction To StatisticsbashatigabuNo ratings yet
- EC 208 - HW2 - Spring 22 v1.2Document2 pagesEC 208 - HW2 - Spring 22 v1.2Umut Mert EğerciNo ratings yet
- Sissoko 2007Document77 pagesSissoko 2007Joel ChineduNo ratings yet
- A New Look at CryptocurrenciesDocument4 pagesA New Look at CryptocurrenciesFar hatNo ratings yet
- Distributed Csps by Graph Partitioning: Miguel A. Salido, Federico BarberDocument8 pagesDistributed Csps by Graph Partitioning: Miguel A. Salido, Federico Barberkhaoula BOUAZZINo ratings yet
- Assignment of Introduction To Statistics - UpdatedDocument3 pagesAssignment of Introduction To Statistics - UpdatedbashatigabuNo ratings yet
- 2021 en Tutorial 7Document5 pages2021 en Tutorial 7Hari-haran KUMARNo ratings yet
- Basic Econometrics 5th Edition Gujarati Solutions ManualDocument12 pagesBasic Econometrics 5th Edition Gujarati Solutions ManualAmyWaltersxknsf100% (15)
- MC Math 13 Module 3Document16 pagesMC Math 13 Module 3Raffy BarotillaNo ratings yet
- Document 4Document16 pagesDocument 4Su BoccardNo ratings yet
- Lista 2 Macro IIIDocument10 pagesLista 2 Macro IIIraphael guimaraesNo ratings yet
- Ggplot2 ExerciseDocument6 pagesGgplot2 Exerciseretokoller44No ratings yet
- Mapping the Spatial Distribution of Poverty Using Satellite Imagery in ThailandFrom EverandMapping the Spatial Distribution of Poverty Using Satellite Imagery in ThailandNo ratings yet
- Mapping the Spatial Distribution of Poverty Using Satellite Imagery in the PhilippinesFrom EverandMapping the Spatial Distribution of Poverty Using Satellite Imagery in the PhilippinesNo ratings yet
- UNIT-2: Flywheels and Turning Moment DiagramsDocument54 pagesUNIT-2: Flywheels and Turning Moment DiagramsPraveen KumarNo ratings yet
- 1PH7228-7HF00-0AB8 2D Dimension ENDocument1 page1PH7228-7HF00-0AB8 2D Dimension ENZulfikar FahmiNo ratings yet
- Tekla Software Training in Bangalore - Google SearchDocument1 pageTekla Software Training in Bangalore - Google SearchMohammedNo ratings yet
- MUY IMPORTANTEEEEEE ENH1350EXT Data Sheet - 180621 - SG - 0Document8 pagesMUY IMPORTANTEEEEEE ENH1350EXT Data Sheet - 180621 - SG - 0Omar PerezNo ratings yet
- CrowdGAN - Identity-Free Interactive Crowd Video Generation and BeyondDocument16 pagesCrowdGAN - Identity-Free Interactive Crowd Video Generation and BeyondmmmmNo ratings yet
- 1702-EN-ST-000-SD-181 Sht-03 OF 04 Rev-0 PDFDocument1 page1702-EN-ST-000-SD-181 Sht-03 OF 04 Rev-0 PDFbharani dharanNo ratings yet
- Sriharshini InternshipDocument12 pagesSriharshini InternshipSriharshini 158No ratings yet
- 459251104-DCS-UH-1H-Flight-Manual-EN-pdf 3Document1 page459251104-DCS-UH-1H-Flight-Manual-EN-pdf 3mav87th-1No ratings yet
- Effetto Pietra: Stone LookDocument23 pagesEffetto Pietra: Stone LookClaudio AllegriNo ratings yet
- Pssewindandsolarmodels CasestudiesDocument69 pagesPssewindandsolarmodels Casestudiespra0% (1)
- Dokumen Data Inventaris Di PT SRDocument22 pagesDokumen Data Inventaris Di PT SRPriambodo AriewibowoNo ratings yet
- "Design & Development Analysis of Quadcopter": Parag Parihar, Priyanshu Bhawsar, Piyush HargodDocument6 pages"Design & Development Analysis of Quadcopter": Parag Parihar, Priyanshu Bhawsar, Piyush HargodAnonymous e7Rajar9SwNo ratings yet
- A.Nisansala Weeraperuma ResumeDocument1 pageA.Nisansala Weeraperuma Resumenisansaladilshani8No ratings yet
- Sony dvp-fx720 Ver1.4Document69 pagesSony dvp-fx720 Ver1.4david godinezNo ratings yet
- Pitching Research: Bond University (Professorial Fellow) University of Queensland (Emeritus Professor)Document37 pagesPitching Research: Bond University (Professorial Fellow) University of Queensland (Emeritus Professor)Anisa LalaNo ratings yet
- Project ReportDocument22 pagesProject ReportHarsh NegiNo ratings yet
- Rec ColumnDocument2 pagesRec Columnnirmal sutharNo ratings yet
- CISSP Exam SimulationDocument145 pagesCISSP Exam SimulationMac Joy100% (2)
- Lesson Plan Week 3 NSDocument4 pagesLesson Plan Week 3 NSLewaa HaidarNo ratings yet
- May 2021 Examination Diet School of Mathematics & Statistics MT4614Document6 pagesMay 2021 Examination Diet School of Mathematics & Statistics MT4614Tev WallaceNo ratings yet
- 3.1 Expression StatementsDocument3 pages3.1 Expression Statementsbambi2002No ratings yet
- Unit V Map Design & LayoutDocument32 pagesUnit V Map Design & LayoutRashkv428 kvNo ratings yet
- Ex No: 1 Date: Program On Saas To Create Word DocumentDocument18 pagesEx No: 1 Date: Program On Saas To Create Word Documentmathi yazhaganNo ratings yet
- VHF 1000 P DSCDocument42 pagesVHF 1000 P DSCOleksandr IvashchenkoNo ratings yet
- Cocina 6 Hornillas de TopeDocument2 pagesCocina 6 Hornillas de Topejrangel.cenvihNo ratings yet
- AD5933 CDocument7 pagesAD5933 CkakiksNo ratings yet
- Blu 4 Eng 2019Document14 pagesBlu 4 Eng 2019BAHZAD SEDEEQNo ratings yet
- CDX MP40Document54 pagesCDX MP40scribduser1979No ratings yet
- Vinyl Tubing (MS-01-108) R2Document1 pageVinyl Tubing (MS-01-108) R2herysyam1980No ratings yet