Download as pdf or txt
You might also like
- MPD - ATR 42-500 Rev 24Document843 pagesMPD - ATR 42-500 Rev 24Arif Rahman100% (2)
- LINUX Containers-For-Everyone-Ebook PDFDocument100 pagesLINUX Containers-For-Everyone-Ebook PDFDebra HargersilverNo ratings yet
- Interface Requirements SpecificationDocument27 pagesInterface Requirements Specificationdhanoj6522No ratings yet
- HTTP WWW - AkadiaDocument17 pagesHTTP WWW - Akadiaapi-3823655100% (1)
- Analytic Functions in OracleDocument35 pagesAnalytic Functions in OraclebalajismithNo ratings yet
- Analytic Functions by Example Oracle FAQDocument16 pagesAnalytic Functions by Example Oracle FAQsanthu50875No ratings yet
- CubeRollup Slides PDFDocument27 pagesCubeRollup Slides PDFSumit KNo ratings yet
- Department of Computer Science: Lab 06: Aggregating Data Using Group FunctionsDocument9 pagesDepartment of Computer Science: Lab 06: Aggregating Data Using Group FunctionsMydah NasirNo ratings yet
- Analytical FunctionsDocument9 pagesAnalytical FunctionsSai KiranNo ratings yet
- Function (Arg1,..., Argn) OVER ( (PARTITION BY ) (ORDER BY ) )Document11 pagesFunction (Arg1,..., Argn) OVER ( (PARTITION BY ) (ORDER BY ) )Santhosh KumarNo ratings yet
- Lecture 6 - Aggregating Data Using Group FunctionsDocument44 pagesLecture 6 - Aggregating Data Using Group Functionslil kidNo ratings yet
- Lab 10Document12 pagesLab 10Usman AshrafNo ratings yet
- SQL Statements 4Document26 pagesSQL Statements 4Muhammad FaisalNo ratings yet
- N SQL Olap F E: EW Unctions For VeryoneDocument18 pagesN SQL Olap F E: EW Unctions For VeryoneGirishNo ratings yet
- Oracle Lab 7Document20 pagesOracle Lab 7kanoujiya28501No ratings yet
- 5 Aggregating DataDocument21 pages5 Aggregating DataPaulNo ratings yet
- Teradata Advanced SQL Part1 PDFDocument38 pagesTeradata Advanced SQL Part1 PDFBiswadip Seth100% (2)
- Database Programming: Using Rollup and Cube Operations, and Grouping SetsDocument34 pagesDatabase Programming: Using Rollup and Cube Operations, and Grouping SetsKevin Van MalderenNo ratings yet
- Practice Assignment of Data BaseDocument5 pagesPractice Assignment of Data Basemehreenshahid789No ratings yet
- ORacle SQL AnalyticsDocument32 pagesORacle SQL AnalyticsLewis CunninghamNo ratings yet
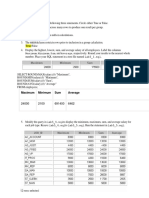
- Practice 5: Maximum Minimum Sum AverageDocument10 pagesPractice 5: Maximum Minimum Sum AverageJunary Daniela MUNOZ JIMENEZNo ratings yet
- Oracle and PLDocument7 pagesOracle and PLAbhinav GonuguntlaNo ratings yet
- RDBMS Unit5Document14 pagesRDBMS Unit5Jeaneffil VimalrajNo ratings yet
- Lab 3Document26 pagesLab 3aa3537913No ratings yet
- Schedule: Timing Topic: 35 Minutes 40 Minutes Practice 75 Minutes TotalDocument31 pagesSchedule: Timing Topic: 35 Minutes 40 Minutes Practice 75 Minutes TotalDaniiel ObandoNo ratings yet
- Query TipsDocument47 pagesQuery TipssonyNo ratings yet
- Cursors, TriggersDocument30 pagesCursors, TriggersTarun Kumar ChauhanNo ratings yet
- Aggregate Function in OracleDocument12 pagesAggregate Function in OracleAnonymous rt8iK9pbNo ratings yet
- Cursors and TriggersDocument5 pagesCursors and TriggersJyoti VermaNo ratings yet
- Les05 SELECT GrupareDocument21 pagesLes05 SELECT GrupareAnisoara BursucNo ratings yet
- Mysql Aggregate FunctionsDocument10 pagesMysql Aggregate FunctionsbayushNo ratings yet
- Query TipsDocument48 pagesQuery TipsAditya Narayahn BiswalNo ratings yet
- Day-2 Aggregate FunctionsDocument25 pagesDay-2 Aggregate FunctionsAshok DuraiNo ratings yet
- Lab 1Document9 pagesLab 1syedayanali28No ratings yet
- SQL Unit 2Document30 pagesSQL Unit 2NikileshNo ratings yet
- Database Essentials For Data Science LabDocument19 pagesDatabase Essentials For Data Science LabpatricknamdevNo ratings yet
- OracleDocument16 pagesOraclegumbadeaniket1234No ratings yet
- Create Sample SQL Server Database and Data: GROUING SETS. These Options Are Similar, But Produce Different ResultsDocument9 pagesCreate Sample SQL Server Database and Data: GROUING SETS. These Options Are Similar, But Produce Different ResultsServicios Gerenciales Integrales C.A.No ratings yet
- Class 10Document6 pagesClass 10eswar090911No ratings yet
- Pipelined FunctionsDocument21 pagesPipelined FunctionsAtif KhanNo ratings yet
- Aggregate Functions in DBMDocument13 pagesAggregate Functions in DBMMuhammad ShaffanNo ratings yet
- AIM: Implement Views: Views: Exp No: 7 DateDocument7 pagesAIM: Implement Views: Views: Exp No: 7 DateRamesh VarathanNo ratings yet
- ITE407 - Advanced Databases Group Fns LectureNotes 02212017Document4 pagesITE407 - Advanced Databases Group Fns LectureNotes 02212017Dalia AstiNo ratings yet
- Laporan 2 PLSQL Develop Program Unit Basis Data Lanjut - 2103171008 - Rintan Aprilia PratiwiDocument12 pagesLaporan 2 PLSQL Develop Program Unit Basis Data Lanjut - 2103171008 - Rintan Aprilia PratiwiRintan Yuri AprilliaNo ratings yet
- Return To Table of ContentsDocument8 pagesReturn To Table of ContentskarzthikNo ratings yet
- Understanding Oracle Explain PlanDocument30 pagesUnderstanding Oracle Explain Planjenasatyabrata825999No ratings yet
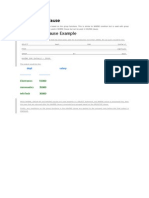
- SQL HAVING Clause ExampleDocument1 pageSQL HAVING Clause ExamplevenniiiiNo ratings yet
- PLSQLDocument34 pagesPLSQLPooja GoyalNo ratings yet
- SQR Performance & EfficiencyDocument10 pagesSQR Performance & EfficiencyKalicharan ReddyNo ratings yet
- Database Security and Audting: Application Data AuditingDocument9 pagesDatabase Security and Audting: Application Data AuditingYasir ShakilNo ratings yet
- Introduction To Oracle Functions and Group by ClauseDocument62 pagesIntroduction To Oracle Functions and Group by Clauseeumine100% (2)
- Analytical QuestionsDocument25 pagesAnalytical QuestionsdeepunymNo ratings yet
- Analytic Functions in OracleDocument14 pagesAnalytic Functions in OracleVasant HelloNo ratings yet
- DBMS Lab 07 04112020 012905pmDocument6 pagesDBMS Lab 07 04112020 012905pmJaveria AbbasiNo ratings yet
- New Features of Oracle Database 11gDocument5 pagesNew Features of Oracle Database 11gsatyapadhyNo ratings yet
- What Is Sql ?: Fundamentals of Sql,T-Sql,Pl/Sql and Datawarehousing.From EverandWhat Is Sql ?: Fundamentals of Sql,T-Sql,Pl/Sql and Datawarehousing.No ratings yet
- Pivot Tables for everyone. From simple tables to Power-Pivot: Useful guide for creating Pivot Tables in ExcelFrom EverandPivot Tables for everyone. From simple tables to Power-Pivot: Useful guide for creating Pivot Tables in ExcelNo ratings yet
- Advanced SAS Interview Questions You'll Most Likely Be AskedFrom EverandAdvanced SAS Interview Questions You'll Most Likely Be AskedNo ratings yet
- Oracle SQL Revealed: Executing Business Logic in the Database EngineFrom EverandOracle SQL Revealed: Executing Business Logic in the Database EngineNo ratings yet
- Excel In 7 Days : Master Excel Features & Formulas. Become A Pro From Scratch In Just 7 Days With Step-By-Step Instructions, Clear Illustrations, And Practical ExamplesFrom EverandExcel In 7 Days : Master Excel Features & Formulas. Become A Pro From Scratch In Just 7 Days With Step-By-Step Instructions, Clear Illustrations, And Practical ExamplesNo ratings yet
- FSGDocument8 pagesFSGRedrouthu JayaprakashNo ratings yet
- New 3Document98 pagesNew 3Redrouthu JayaprakashNo ratings yet
- Difference Between 11i and R12Document3 pagesDifference Between 11i and R12Redrouthu JayaprakashNo ratings yet
- GL PPMDocument6 pagesGL PPMRedrouthu JayaprakashNo ratings yet
- Built-In Functions in PL/SQLDocument2 pagesBuilt-In Functions in PL/SQLRedrouthu JayaprakashNo ratings yet
- What Is Object Type in PLDocument13 pagesWhat Is Object Type in PLRedrouthu JayaprakashNo ratings yet
- Inventory: Physical or LogicalDocument5 pagesInventory: Physical or LogicalRedrouthu JayaprakashNo ratings yet
- Sourcing - RFQ (Detailed Flow) : Demo Script (Internal)Document38 pagesSourcing - RFQ (Detailed Flow) : Demo Script (Internal)Redrouthu JayaprakashNo ratings yet
- Workday 101 For HR and ManagersDocument28 pagesWorkday 101 For HR and ManagersRedrouthu Jayaprakash100% (2)
- Wokday Business ProcessDocument2 pagesWokday Business ProcessRedrouthu JayaprakashNo ratings yet
- Quick Reference Guide: Maintain Supervisory Organization Structure (Includes CreateDocument6 pagesQuick Reference Guide: Maintain Supervisory Organization Structure (Includes CreateRedrouthu JayaprakashNo ratings yet
- Organization Management in Workday: As Dynamic As Your BusinessDocument4 pagesOrganization Management in Workday: As Dynamic As Your BusinessRedrouthu JayaprakashNo ratings yet
- Ready, Set, Restructure!: A Guide For Workday ReorganizationsDocument10 pagesReady, Set, Restructure!: A Guide For Workday ReorganizationsRedrouthu JayaprakashNo ratings yet
- Flex FieldsDocument21 pagesFlex FieldsRedrouthu JayaprakashNo ratings yet
- Lesson - 1: What Is My Mother Tongue?Document3 pagesLesson - 1: What Is My Mother Tongue?Redrouthu JayaprakashNo ratings yet
- Birt Versions For Our Clients: Modo BIRT Verion: 4.3.1 DI BIRT Version: 2.6.1 BIRT Bundle TypesDocument5 pagesBirt Versions For Our Clients: Modo BIRT Verion: 4.3.1 DI BIRT Version: 2.6.1 BIRT Bundle TypesRedrouthu JayaprakashNo ratings yet
- 16ECE315-Digital Design Through Verilog HDLDocument1 page16ECE315-Digital Design Through Verilog HDLSyed AshmadNo ratings yet
- Explanatory Notes: 2.1 Introduction To Systems Analysis and Design (6 Theory Periods)Document2 pagesExplanatory Notes: 2.1 Introduction To Systems Analysis and Design (6 Theory Periods)Mohd AsrulNo ratings yet
- Chip8: A CHIP-8 / SCHIP Emulator by David Winter (Hpmaniac)Document14 pagesChip8: A CHIP-8 / SCHIP Emulator by David Winter (Hpmaniac)Guy100% (1)
- Distributed Systems Assignment 2Document3 pagesDistributed Systems Assignment 2Jěhøvāh Šhāĺøm100% (1)
- Oracle® Goldengate: Microsoft SQL Server Installation and Setup GuideDocument53 pagesOracle® Goldengate: Microsoft SQL Server Installation and Setup GuideutpalbasakNo ratings yet
- Something About Us - Daft Punk - Gratis Partitura y TablaturaDocument1 pageSomething About Us - Daft Punk - Gratis Partitura y TablaturaMephistoMarcan0% (1)
- 0818 Gearsolutions PDFDocument76 pages0818 Gearsolutions PDFdesetekNo ratings yet
- 5 8 18Document3 pages5 8 18Holy Wayne 'Trinity' ChuaNo ratings yet
- Lab6 Basic RoutingDocument2 pagesLab6 Basic RoutingNadun Sasanga KumarasingheNo ratings yet
- Bridge Design For InfraWorks 360 FAQ'sDocument3 pagesBridge Design For InfraWorks 360 FAQ'syogendra shahNo ratings yet
- Elmaster Project - User ManualDocument97 pagesElmaster Project - User ManualRafael Cardoso Dias CostaNo ratings yet
- BS Lab Manual NewDocument36 pagesBS Lab Manual NewShameer PhyNo ratings yet
- Async and Await PDFDocument5 pagesAsync and Await PDFnikolatesla2009No ratings yet
- Research Paper Smart Ballot SystemDocument4 pagesResearch Paper Smart Ballot SystemGAMENo ratings yet
- Harshit Arora: ComputerengineerDocument2 pagesHarshit Arora: ComputerengineerharshitNo ratings yet
- User Interface Design: Purbanchal University: Bit Iii SemesterDocument90 pagesUser Interface Design: Purbanchal University: Bit Iii Semesterrupak dangiNo ratings yet
- Rapiscan 628DVDocument2 pagesRapiscan 628DVTriam Patience MundaNo ratings yet
- JY-61 MPU6050 Module User Manual by ElecmasterDocument12 pagesJY-61 MPU6050 Module User Manual by ElecmasterElecmaster100% (1)
- CMM5 Quick Start GuideDocument2 pagesCMM5 Quick Start Guidejavierdb2012No ratings yet
- n64 GamesDocument7 pagesn64 GamesBrian CregeenNo ratings yet
- E186549-1694281924323-292886-E186549 WDD Assignment 2023Document74 pagesE186549-1694281924323-292886-E186549 WDD Assignment 2023Darshi KarunarathneNo ratings yet
- Sensor and ActuatorDocument42 pagesSensor and ActuatorArief IskandarNo ratings yet
- Logcat 1648695382959Document208 pagesLogcat 1648695382959arief tNo ratings yet
- Oracle E-Business Suite Exchange Rates LoadDocument4 pagesOracle E-Business Suite Exchange Rates LoadSamHasNo ratings yet
- Innovative Enhancement of The Caesar Cipher AlgoriDocument5 pagesInnovative Enhancement of The Caesar Cipher Algorisid allawadiNo ratings yet
- Mobile Banking in IndiaDocument33 pagesMobile Banking in Indiaanir_1986No ratings yet
- Hydrology 1Document2 pagesHydrology 1Engr AbirNo ratings yet