Download as pdf or txt
You might also like
- Wjec A2 Chemistry Study and Revision Guide PDFDocument125 pagesWjec A2 Chemistry Study and Revision Guide PDFPakorn WinayanuwattikunNo ratings yet
- Drugs and Substance Abuse PDFDocument8 pagesDrugs and Substance Abuse PDFMaria Aminta CacerecesNo ratings yet
- Lecture 5 (Bivariate ND & Error Ellipses)Document5 pagesLecture 5 (Bivariate ND & Error Ellipses)Kismet100% (4)
- Front View: Wire Rope DrumDocument2 pagesFront View: Wire Rope DrumDave Vendivil SambranoNo ratings yet
- The Cygnus MysteryDocument25 pagesThe Cygnus MysteryGraham Harris100% (3)
- DC1 Workbook LDocument59 pagesDC1 Workbook LNIRANJAN KUMARNo ratings yet
- Statics of Masonry Solids and StructuresDocument21 pagesStatics of Masonry Solids and StructuresMarioNo ratings yet
- Calculus Properties and IdentitiesDocument5 pagesCalculus Properties and IdentitiesbelleblackNo ratings yet
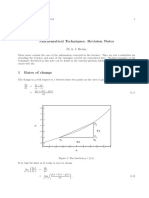
- Mathematical Techniques: Revision Notes: DR A. J. BevanDocument11 pagesMathematical Techniques: Revision Notes: DR A. J. BevanRoy VeseyNo ratings yet
- Fs Xii CNDDocument2 pagesFs Xii CNDsahilsr845401No ratings yet
- 1 FonksiyonlarDocument15 pages1 FonksiyonlarfiratvurunbigiNo ratings yet
- 高等数学常用微积分公式Document7 pages高等数学常用微积分公式竭彬臣No ratings yet
- Math 1102, Solved Problems On Multiple IntegralsDocument12 pagesMath 1102, Solved Problems On Multiple IntegralsFaizNo ratings yet
- Derivatives RulesDocument1 pageDerivatives Ruleslost.devil.0909No ratings yet
- Shear and Moment Diagrams Shear and Moment DiagramsDocument9 pagesShear and Moment Diagrams Shear and Moment DiagramsRajkamal AroraNo ratings yet
- การวิเคราะห์ความเค้นและความเครียดDocument56 pagesการวิเคราะห์ความเค้นและความเครียดMhee UtdNo ratings yet
- @ Compensation ComponentsDocument4 pages@ Compensation Componentsgholamalipour9768No ratings yet
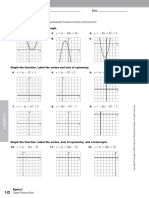
- Graphing Rational Functions Notes KeyDocument8 pagesGraphing Rational Functions Notes Keysasw111 sasw111No ratings yet
- EEE 201 Engineering Mathematics Prof. Dr. Saffet AYASUN Inst.: Dr. Bülent DağDocument36 pagesEEE 201 Engineering Mathematics Prof. Dr. Saffet AYASUN Inst.: Dr. Bülent DağBarış DuranNo ratings yet
- Cambridge Particle Physics CoursesDocument22 pagesCambridge Particle Physics CoursesThiziri AMEZZANo ratings yet
- Fundamentals of Elasticity Theory: Professor M. H. SaddDocument29 pagesFundamentals of Elasticity Theory: Professor M. H. SaddArriane Faith A. EstoniloNo ratings yet
- Fundamentals of Elasticity Theory: Professor M. H. SaddDocument29 pagesFundamentals of Elasticity Theory: Professor M. H. SaddMilad RadNo ratings yet
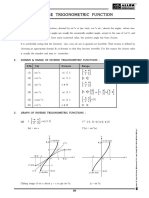
- Inverse Trigonometric FucntionDocument19 pagesInverse Trigonometric Fucntionmalik faizanlangNo ratings yet
- Graphs of Rational FunctionsDocument4 pagesGraphs of Rational FunctionsRomel DingilNo ratings yet
- SPM Linear LawDocument5 pagesSPM Linear LawNg YieviaNo ratings yet
- 2023 자이스토리 고2 수2-1Document224 pages2023 자이스토리 고2 수2-1tgim796No ratings yet
- Volumes by SlicingDocument7 pagesVolumes by SlicingJessica BillNo ratings yet
- Structural Mechanics: OutlineDocument37 pagesStructural Mechanics: OutlineZain ul HassanNo ratings yet
- 11 Solusi Deret Untuk Pers DifferensialDocument30 pages11 Solusi Deret Untuk Pers DifferensialReza HermawanNo ratings yet
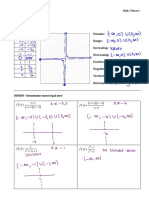
- Mathematical Review: 1. (Functions)Document11 pagesMathematical Review: 1. (Functions)leoNo ratings yet
- Econometrics CheatsheetDocument3 pagesEconometrics Cheatsheetf/z BENRABOUHNo ratings yet
- Differentiation of Exponential and Logarithmic FunctionsDocument28 pagesDifferentiation of Exponential and Logarithmic FunctionsAudie T. MataNo ratings yet
- Basic Calculus Activity Sheets Week 5Document10 pagesBasic Calculus Activity Sheets Week 5Ely BNo ratings yet
- AQA FP2 Revision SheetsDocument10 pagesAQA FP2 Revision SheetsQuangMinh ScottNo ratings yet
- Chap 4Document41 pagesChap 4임종윤No ratings yet
- ME-6201 AEP Stress Function PDFDocument19 pagesME-6201 AEP Stress Function PDFPrabhataNo ratings yet
- 02 June - Quiz - Linear InequalitiesDocument7 pages02 June - Quiz - Linear InequalitiesimanNo ratings yet
- Differentiation of AlgebraicDocument15 pagesDifferentiation of Algebraictuan arfah tuan matNo ratings yet
- Inverse Trigonometric Functions: Memory TipsDocument5 pagesInverse Trigonometric Functions: Memory TipsMORTAL X67No ratings yet
- Inverse Trigonometric Functions: Memory TipsDocument5 pagesInverse Trigonometric Functions: Memory TipsMohd UvaisNo ratings yet
- Episode11 PDFDocument5 pagesEpisode11 PDFBiju Kumar B SNo ratings yet
- Inverse Trigonometric Functions: Memory TipsDocument5 pagesInverse Trigonometric Functions: Memory TipsMORTAL X67No ratings yet
- 2431 Dozvoljene Formule - Mat2 Za UsmeniDocument1 page2431 Dozvoljene Formule - Mat2 Za UsmeniMislav FranicNo ratings yet
- Common Functions Reference Chpter 1Document4 pagesCommon Functions Reference Chpter 1ski3013No ratings yet
- A Study of Weibull Mixture ROC Curve With Constant Shape Parameter PDFDocument10 pagesA Study of Weibull Mixture ROC Curve With Constant Shape Parameter PDFAzhar UddinNo ratings yet
- StatsticsDocument20 pagesStatsticshussenNo ratings yet
- Linear Regression PDFDocument45 pagesLinear Regression PDFprashant200690No ratings yet
- Correlation Regression TheoryDocument8 pagesCorrelation Regression TheorySushree srabani SwainNo ratings yet
- Control of Mobile Robots: Linear SystemsDocument65 pagesControl of Mobile Robots: Linear Systemssonti11No ratings yet
- Basics of Deep Learning: Pierre-Marc Jodoin and Christian DesrosiersDocument183 pagesBasics of Deep Learning: Pierre-Marc Jodoin and Christian DesrosiersalyasocialwayNo ratings yet
- Macromechanics of A LaminateDocument45 pagesMacromechanics of A LaminateAvinash ShindeNo ratings yet
- Binomial TheoremDocument12 pagesBinomial TheoremRajesh KumarNo ratings yet
- Algorithmic Identification of Chart PatternsDocument35 pagesAlgorithmic Identification of Chart Patternsvenkata sivaram posaNo ratings yet
- 1-2 Practice - ADocument4 pages1-2 Practice - AStanleyNo ratings yet
- Systematially Designed Book For Differential Calculus UPSC CSE IFoS Mathematics Optional Mindset Makers Upendra Singh SirDocument275 pagesSystematially Designed Book For Differential Calculus UPSC CSE IFoS Mathematics Optional Mindset Makers Upendra Singh SirRATNADEEP DASNo ratings yet
- Practice Exam 1Document1 pagePractice Exam 1Ricardo Bernardo RickyNo ratings yet
- Chapter 8: Correlaiton and Simple Linear Regression AnalysisDocument7 pagesChapter 8: Correlaiton and Simple Linear Regression AnalysisRUHDRANo ratings yet
- Inverse Jeemain - GuruDocument32 pagesInverse Jeemain - GuruNeetu GuptaNo ratings yet
- Linear InequalitiesDocument1 pageLinear InequalitiesTu Nguyen MinhNo ratings yet
- MCS - Volume 3 - Issue 3 - Pages 40-46Document7 pagesMCS - Volume 3 - Issue 3 - Pages 40-46Jacie RonquilloNo ratings yet
- Differentiation of Trigonometric FunctionsDocument26 pagesDifferentiation of Trigonometric FunctionsAudie T. MataNo ratings yet
- Derivative of Trig FunctionDocument26 pagesDerivative of Trig FunctionMyko Brian SantillanNo ratings yet
- Productivity Now: Social Administration, Training, Economics and Production DivisionFrom EverandProductivity Now: Social Administration, Training, Economics and Production DivisionNo ratings yet
- Verification of Algorithm and Equipment For Electrochemical Impedance MeasurementsDocument11 pagesVerification of Algorithm and Equipment For Electrochemical Impedance MeasurementsMaria Paulina Holguin PatiñoNo ratings yet
- Hydroelectric Power PlantDocument3 pagesHydroelectric Power Plantpalani kumarNo ratings yet
- Asuhan Pasien Dengan Terminall IllnessDocument50 pagesAsuhan Pasien Dengan Terminall IllnessCieciel Silviaa FebrianiiNo ratings yet
- PDF The Boy Who Flew Too High Texto CompletoDocument3 pagesPDF The Boy Who Flew Too High Texto Completokayque Almeida MonteiroNo ratings yet
- ProposalDocument18 pagesProposalakintundeakinboladeNo ratings yet
- Lecture 4 Natural Capital, Ecosystem Services and ValuationDocument28 pagesLecture 4 Natural Capital, Ecosystem Services and ValuationGiang MJNo ratings yet
- Rash Driving Detection SystemDocument5 pagesRash Driving Detection SystemIJSTE100% (1)
- Recipe Book Part 1Document19 pagesRecipe Book Part 1Justine Keira AyoNo ratings yet
- SItx 40516prepare Meat DishesDocument9 pagesSItx 40516prepare Meat DishesTikaram GhimireNo ratings yet
- The Future of Cystic Fibrosis Treatment From DiseDocument14 pagesThe Future of Cystic Fibrosis Treatment From DiseAlexander LozaNo ratings yet
- Stritt & Priebe Inc. Stritt & Priebe Inc. Stritt & Priebe Inc. Stritt & Priebe IncDocument1 pageStritt & Priebe Inc. Stritt & Priebe Inc. Stritt & Priebe Inc. Stritt & Priebe IncPeerunthorn WongcharoenchaichanaNo ratings yet
- The Dangers of CrammingDocument2 pagesThe Dangers of CrammingIntan Shafira RachmadhiniNo ratings yet
- Executive Summary: Project TitleDocument57 pagesExecutive Summary: Project Titlenabajit1989No ratings yet
- Data structures Course استاذ خيرالله الصادق الفرجانيDocument47 pagesData structures Course استاذ خيرالله الصادق الفرجانيAsma S Al ShebaniNo ratings yet
- Text 1 (A & B)Document2 pagesText 1 (A & B)ifx leeNo ratings yet
- Chapter 1 DhatuDocument6 pagesChapter 1 Dhatusbec96860% (1)
- NBRK0200 Installation Configuration ManualDocument32 pagesNBRK0200 Installation Configuration ManualGoran JovanovicNo ratings yet
- 2TG - (Catalog) Towing Tractor EngineDocument4 pages2TG - (Catalog) Towing Tractor EngineAhmad FirdausNo ratings yet
- How To Use ThermafilDocument7 pagesHow To Use ThermafilEvan ChiangNo ratings yet
- Project Proposal TemplateDocument3 pagesProject Proposal TemplateNimrah KhanNo ratings yet
- Hanwa Injection Substation Maintainance Ceck ListDocument18 pagesHanwa Injection Substation Maintainance Ceck ListMubarak Aleem100% (1)
- Grade of Adeptus MajorDocument61 pagesGrade of Adeptus MajorIlluminhateNo ratings yet
- Hotel Minimum ReqDocument28 pagesHotel Minimum ReqAnusha AshokNo ratings yet
- Pretest and PosttestDocument3 pagesPretest and PosttestMarissa FontanilNo ratings yet
- Best Tracksuit: A Quick HistoryDocument3 pagesBest Tracksuit: A Quick HistoryMahreen IshereNo ratings yet
- Ruby Village TemplateDocument2 pagesRuby Village Templatekomal sharmaNo ratings yet