
Introduction To Statistical Learning
Introduction To Statistical Learning
You might also like
- D182 Task 1 Developing Reflective PracticeDocument13 pagesD182 Task 1 Developing Reflective Practicedenook100% (1)
- Data Interpretation Guide For All Competitive and Admission ExamsFrom EverandData Interpretation Guide For All Competitive and Admission ExamsRating: 2.5 out of 5 stars2.5/5 (6)
- Number Recognition 1 10 2Document14 pagesNumber Recognition 1 10 2api-450467649No ratings yet
- Three-Year Science Laboratory Development Plan (S.Y 2015-2018)Document4 pagesThree-Year Science Laboratory Development Plan (S.Y 2015-2018)aljayne De Castro100% (1)
- Art Unit Plan Term 1 Artist Study Nicky ForemanDocument2 pagesArt Unit Plan Term 1 Artist Study Nicky Foremanapi-2462183730% (1)
- Islp 4Document5 pagesIslp 4amithx100No ratings yet
- Discrete and Continuous Dynamical Systems Series S: Doi:10.3934/dcdss.2022054Document25 pagesDiscrete and Continuous Dynamical Systems Series S: Doi:10.3934/dcdss.2022054LeksaNo ratings yet
- 5 Noman Naseer Linear RegressionDocument15 pages5 Noman Naseer Linear Regression057GV Văn HiếuNo ratings yet
- Business Mathematics: Quarter 2, Week 8-Module 18 Drawing A Graph or Table To Present Data ABM - BM11PAD-Ili-9Document18 pagesBusiness Mathematics: Quarter 2, Week 8-Module 18 Drawing A Graph or Table To Present Data ABM - BM11PAD-Ili-9kurlstine joanne aceronNo ratings yet
- Linear Regression 1Document10 pagesLinear Regression 1CharanKanwal VirkNo ratings yet
- StatLearning2r PDFDocument267 pagesStatLearning2r PDFBruno CasellaNo ratings yet
- Arithmetic Mean PDFDocument29 pagesArithmetic Mean PDFDivya Gothi100% (1)
- 3 Linear Regression-Handout PDFDocument48 pages3 Linear Regression-Handout PDFTaylor TamNo ratings yet
- Week2 StatisticalLearningDocument46 pagesWeek2 StatisticalLearningMuntaz MuntazNo ratings yet
- Monash University: Semester One Mid Semester Test 2018 Faculty of Information TechnologyDocument12 pagesMonash University: Semester One Mid Semester Test 2018 Faculty of Information TechnologyAlireza KafaeiNo ratings yet
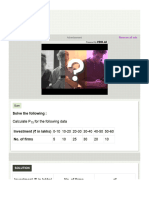
- Calculate P15 For The Following Data Investment ( in LakhDocument6 pagesCalculate P15 For The Following Data Investment ( in LakhDavid Oba OlayiwolaNo ratings yet
- Ashish Maths 10 B StatisticsDocument14 pagesAshish Maths 10 B StatisticsAkash KumarNo ratings yet
- ST 6 Diagrammatic Presentation of DataDocument10 pagesST 6 Diagrammatic Presentation of Dataranim29814No ratings yet
- Adobe Scan 14 Jan 2024Document14 pagesAdobe Scan 14 Jan 2024suchismitasarkar2003No ratings yet
- Bsfilipino1-1 Arangoso JRDocument6 pagesBsfilipino1-1 Arangoso JRJulius Renz ArangosoNo ratings yet
- Lec 03 - Regresi Linier (Optimized)Document30 pagesLec 03 - Regresi Linier (Optimized)Asal ReviewNo ratings yet
- Midterm F07 SolutionsDocument4 pagesMidterm F07 SolutionsKamal JackNo ratings yet
- Ch3 Linear RegressionDocument64 pagesCh3 Linear RegressionDivyansh BhadauriaNo ratings yet
- 02-BCA-Statistical Methods and Their ApplicationsDocument1 page02-BCA-Statistical Methods and Their ApplicationsKrishna Chaitanya BramheswaramNo ratings yet
- G9 Notes Graphs 1Document5 pagesG9 Notes Graphs 1Larry MofaNo ratings yet
- Regression 2021 Partie2 Anglais Annote PDFDocument18 pagesRegression 2021 Partie2 Anglais Annote PDFAZONTO conradNo ratings yet
- Sig 01Document59 pagesSig 01kalaNo ratings yet
- Practice Papers - Marking Schemes - Set1,2,3Document25 pagesPractice Papers - Marking Schemes - Set1,2,3Avijit RoyNo ratings yet
- National Institute of Business ManagementDocument10 pagesNational Institute of Business ManagementSonali RajapakseNo ratings yet
- ST 7 Frequency Distribution Histogram, Polygon & OgiveDocument8 pagesST 7 Frequency Distribution Histogram, Polygon & Ogivesykobeats7No ratings yet
- Exam-Style Question:: Measures of SpreadDocument8 pagesExam-Style Question:: Measures of SpreadFadi AyyoubNo ratings yet
- Six SigmaDocument38 pagesSix SigmaSAMHO DigitalNo ratings yet
- (F-F) M X + I (F - F) + (F - F)Document12 pages(F-F) M X + I (F - F) + (F - F)Софи БреславецNo ratings yet
- AnalytixLabs - Linear Regression - 1623137749089Document41 pagesAnalytixLabs - Linear Regression - 1623137749089Sarthak SharmaNo ratings yet
- Lec 12 - Regresi Multi-LinierDocument22 pagesLec 12 - Regresi Multi-LinierAsal ReviewNo ratings yet
- Ncert Solutions For Class 11 Maths May22 Chapter 15 StatisticsDocument52 pagesNcert Solutions For Class 11 Maths May22 Chapter 15 StatisticsPriyanshuNo ratings yet
- Week 5 Empirical - Methods 2Document20 pagesWeek 5 Empirical - Methods 2muller1234No ratings yet
- Lecture PDFDocument115 pagesLecture PDFAnwar HussainNo ratings yet
- Relationship B/W Dependent and Independent Variables: 1) Functional RelationDocument9 pagesRelationship B/W Dependent and Independent Variables: 1) Functional RelationMuhammad BilalNo ratings yet
- Tutorial 5 Worksheet 7 Question 3 Answers Julian MoolenburghDocument3 pagesTutorial 5 Worksheet 7 Question 3 Answers Julian MoolenburghGing ChingNo ratings yet
- CBSE Class 11 Economics Sample Paper Set A PDFDocument7 pagesCBSE Class 11 Economics Sample Paper Set A PDFumangNo ratings yet
- Slides03 PDFDocument25 pagesSlides03 PDFHani RNo ratings yet
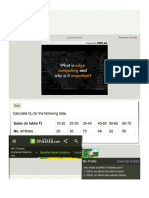
- Calculate Q3 For The Following Data. Sales (In Lakhs ) 10-20 20-30 30-40 40-50Document6 pagesCalculate Q3 For The Following Data. Sales (In Lakhs ) 10-20 20-30 30-40 40-50David Oba OlayiwolaNo ratings yet
- ADMS 2200-Marketing Plan-BudgetDocument8 pagesADMS 2200-Marketing Plan-BudgetBeatak1No ratings yet
- Correlation and Regression 32Document10 pagesCorrelation and Regression 32Cry BeroNo ratings yet
- 11 Economics SP 02Document15 pages11 Economics SP 02MOHAMMAD SYED AEJAZNo ratings yet
- Usps April27meetingDocument18 pagesUsps April27meetingtmurseNo ratings yet
- 101sln PDFDocument12 pages101sln PDFPres Asociatie3kNo ratings yet
- Holistic Progress Card (2023-24) : Ar Ayan Wajid KallurukalluruDocument4 pagesHolistic Progress Card (2023-24) : Ar Ayan Wajid KallurukalluruMasthan Vali KNo ratings yet
- Chapter 12Document19 pagesChapter 12Hossam AboomarNo ratings yet
- CBSE X Maths Case Study Practice Tests (3 Topics)Document7 pagesCBSE X Maths Case Study Practice Tests (3 Topics)Vishal MNo ratings yet
- ECMT2130: Semester 2, 2020 Assignment: Geoff Shuetrim Geoffrey - Shuetrim@sydney - Edu.au University of SydneyDocument7 pagesECMT2130: Semester 2, 2020 Assignment: Geoff Shuetrim Geoffrey - Shuetrim@sydney - Edu.au University of SydneyDaniyal AsifNo ratings yet
- Kuliah10 Analisa Time Series Dan TrendDocument9 pagesKuliah10 Analisa Time Series Dan TrendDita EnsNo ratings yet
- 3 Regresi LinierDocument30 pages3 Regresi LinierRozy SulthanaNo ratings yet
- What Is VLSI and Why You Should CareDocument21 pagesWhat Is VLSI and Why You Should CareRameshNo ratings yet
- Elective Computational MathematicsDocument36 pagesElective Computational Mathematicspradhumnyadav756No ratings yet
- CITATION HTT /L 1033Document55 pagesCITATION HTT /L 1033Miskatul ArafatNo ratings yet
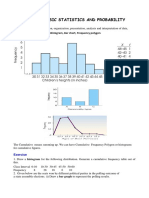
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocument6 pagesUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNo ratings yet
- Dynamics, Adaptive Control and Extended Synchronization of Hyperchaotic System and Its Application To Secure CommunicationDocument17 pagesDynamics, Adaptive Control and Extended Synchronization of Hyperchaotic System and Its Application To Secure CommunicationijccmsNo ratings yet
- Strategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDocument23 pagesStrategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDeepak ChaudharyNo ratings yet
- Strategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDocument24 pagesStrategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDeepak ChaudharyNo ratings yet
- 4.49tybsc ItDocument12 pages4.49tybsc ItAbhay Prajapati0% (2)
- Applied Financial Econometrics Using Stata 3. Linear Factor ModelsDocument42 pagesApplied Financial Econometrics Using Stata 3. Linear Factor ModelsNeemaNo ratings yet
- Assignment 1Document2 pagesAssignment 1Dong NguyenNo ratings yet
- HRM Assignment PDFDocument5 pagesHRM Assignment PDFnamami saxenaNo ratings yet
- Module Scheme of WorkDocument5 pagesModule Scheme of WorkJan FishNo ratings yet
- Project Work: - DR Parag AjagaonkarDocument13 pagesProject Work: - DR Parag AjagaonkarHussainAttarwalaNo ratings yet
- Y7 ICT-Ms PatriciaDocument4 pagesY7 ICT-Ms PatriciaemonimtiazNo ratings yet
- BijanresumeDocument1 pageBijanresumeapi-317032154No ratings yet
- Detailed Lesson Plan (DLP) in Earth & Life Science: S11/12ES-Ia-e-4Document5 pagesDetailed Lesson Plan (DLP) in Earth & Life Science: S11/12ES-Ia-e-4Bowina KhoNo ratings yet
- Ed10 BISLIG Globalization and Multicultural LiteracyDocument5 pagesEd10 BISLIG Globalization and Multicultural LiteracyCrysvenne Perez BisligNo ratings yet
- LBS Research Proposal Format-FinalDocument3 pagesLBS Research Proposal Format-FinalAhsanFarooqNo ratings yet
- Cover Letter For Special Needs Teaching AssistantDocument7 pagesCover Letter For Special Needs Teaching Assistantvyp0wosyb1m3100% (2)
- Automatic Speech RecognitionDocument9 pagesAutomatic Speech RecognitionRahul RajNo ratings yet
- Grade5 Health Catch Up FridayDocument2 pagesGrade5 Health Catch Up Fridaymariaestrellita.bolasa94% (16)
- Learning SMDocument107 pagesLearning SMSudip AcharyaNo ratings yet
- Form 137 Format ElementaryDocument7 pagesForm 137 Format ElementaryNoemi Credito MataNo ratings yet
- 1371594350-ELT 303 Teaching Speaking and Listening Comp. Skills 2013-2014 Syllabus PDFDocument8 pages1371594350-ELT 303 Teaching Speaking and Listening Comp. Skills 2013-2014 Syllabus PDFGenesis Abesia LaborNo ratings yet
- ERPH 2022 EnglishDocument14 pagesERPH 2022 EnglishSarveena MurugiahNo ratings yet
- Classroom AccommodationsDocument13 pagesClassroom AccommodationsTiffany InocenteNo ratings yet
- 131 FullDocument11 pages131 Fullcrys_by666No ratings yet
- Abra State Insitute of Sciences and TechnologyDocument11 pagesAbra State Insitute of Sciences and TechnologyRebelita BejarinNo ratings yet
- Designing Websites in Dreamweaver CS5Document284 pagesDesigning Websites in Dreamweaver CS5heomasyNo ratings yet
- 5 - Exit Survey FormDocument5 pages5 - Exit Survey FormRaja SekarNo ratings yet
- SCSA3015 Deep Learning Quiz For IV Year (Batch 2019 - 2023)Document15 pagesSCSA3015 Deep Learning Quiz For IV Year (Batch 2019 - 2023)Pavan VangapallyNo ratings yet
- Arabic English CV 001Document1 pageArabic English CV 001Ayman GhaziNo ratings yet
- SBM Form 1 School Based Management SBM Validation Tool SY 18-19-19 20Document17 pagesSBM Form 1 School Based Management SBM Validation Tool SY 18-19-19 20Erick SibugNo ratings yet
- KRAI PracticalDocument14 pagesKRAI PracticalContact VishalNo ratings yet
- Report Assesment FormDocument2 pagesReport Assesment FormMuhammad FirdausNo ratings yet
- Problems Facing Teaching and Learning ofDocument27 pagesProblems Facing Teaching and Learning ofoluwafemi MatthewNo ratings yet




















































































Download as pdf or txt
You might also like
- D182 Task 1 Developing Reflective PracticeDocument13 pagesD182 Task 1 Developing Reflective Practicedenook100% (1)
- Data Interpretation Guide For All Competitive and Admission ExamsFrom EverandData Interpretation Guide For All Competitive and Admission ExamsRating: 2.5 out of 5 stars2.5/5 (6)
- Number Recognition 1 10 2Document14 pagesNumber Recognition 1 10 2api-450467649No ratings yet
- Three-Year Science Laboratory Development Plan (S.Y 2015-2018)Document4 pagesThree-Year Science Laboratory Development Plan (S.Y 2015-2018)aljayne De Castro100% (1)
- Art Unit Plan Term 1 Artist Study Nicky ForemanDocument2 pagesArt Unit Plan Term 1 Artist Study Nicky Foremanapi-2462183730% (1)
- Islp 4Document5 pagesIslp 4amithx100No ratings yet
- Discrete and Continuous Dynamical Systems Series S: Doi:10.3934/dcdss.2022054Document25 pagesDiscrete and Continuous Dynamical Systems Series S: Doi:10.3934/dcdss.2022054LeksaNo ratings yet
- 5 Noman Naseer Linear RegressionDocument15 pages5 Noman Naseer Linear Regression057GV Văn HiếuNo ratings yet
- Business Mathematics: Quarter 2, Week 8-Module 18 Drawing A Graph or Table To Present Data ABM - BM11PAD-Ili-9Document18 pagesBusiness Mathematics: Quarter 2, Week 8-Module 18 Drawing A Graph or Table To Present Data ABM - BM11PAD-Ili-9kurlstine joanne aceronNo ratings yet
- Linear Regression 1Document10 pagesLinear Regression 1CharanKanwal VirkNo ratings yet
- StatLearning2r PDFDocument267 pagesStatLearning2r PDFBruno CasellaNo ratings yet
- Arithmetic Mean PDFDocument29 pagesArithmetic Mean PDFDivya Gothi100% (1)
- 3 Linear Regression-Handout PDFDocument48 pages3 Linear Regression-Handout PDFTaylor TamNo ratings yet
- Week2 StatisticalLearningDocument46 pagesWeek2 StatisticalLearningMuntaz MuntazNo ratings yet
- Monash University: Semester One Mid Semester Test 2018 Faculty of Information TechnologyDocument12 pagesMonash University: Semester One Mid Semester Test 2018 Faculty of Information TechnologyAlireza KafaeiNo ratings yet
- Calculate P15 For The Following Data Investment ( in LakhDocument6 pagesCalculate P15 For The Following Data Investment ( in LakhDavid Oba OlayiwolaNo ratings yet
- Ashish Maths 10 B StatisticsDocument14 pagesAshish Maths 10 B StatisticsAkash KumarNo ratings yet
- ST 6 Diagrammatic Presentation of DataDocument10 pagesST 6 Diagrammatic Presentation of Dataranim29814No ratings yet
- Adobe Scan 14 Jan 2024Document14 pagesAdobe Scan 14 Jan 2024suchismitasarkar2003No ratings yet
- Bsfilipino1-1 Arangoso JRDocument6 pagesBsfilipino1-1 Arangoso JRJulius Renz ArangosoNo ratings yet
- Lec 03 - Regresi Linier (Optimized)Document30 pagesLec 03 - Regresi Linier (Optimized)Asal ReviewNo ratings yet
- Midterm F07 SolutionsDocument4 pagesMidterm F07 SolutionsKamal JackNo ratings yet
- Ch3 Linear RegressionDocument64 pagesCh3 Linear RegressionDivyansh BhadauriaNo ratings yet
- 02-BCA-Statistical Methods and Their ApplicationsDocument1 page02-BCA-Statistical Methods and Their ApplicationsKrishna Chaitanya BramheswaramNo ratings yet
- G9 Notes Graphs 1Document5 pagesG9 Notes Graphs 1Larry MofaNo ratings yet
- Regression 2021 Partie2 Anglais Annote PDFDocument18 pagesRegression 2021 Partie2 Anglais Annote PDFAZONTO conradNo ratings yet
- Sig 01Document59 pagesSig 01kalaNo ratings yet
- Practice Papers - Marking Schemes - Set1,2,3Document25 pagesPractice Papers - Marking Schemes - Set1,2,3Avijit RoyNo ratings yet
- National Institute of Business ManagementDocument10 pagesNational Institute of Business ManagementSonali RajapakseNo ratings yet
- ST 7 Frequency Distribution Histogram, Polygon & OgiveDocument8 pagesST 7 Frequency Distribution Histogram, Polygon & Ogivesykobeats7No ratings yet
- Exam-Style Question:: Measures of SpreadDocument8 pagesExam-Style Question:: Measures of SpreadFadi AyyoubNo ratings yet
- Six SigmaDocument38 pagesSix SigmaSAMHO DigitalNo ratings yet
- (F-F) M X + I (F - F) + (F - F)Document12 pages(F-F) M X + I (F - F) + (F - F)Софи БреславецNo ratings yet
- AnalytixLabs - Linear Regression - 1623137749089Document41 pagesAnalytixLabs - Linear Regression - 1623137749089Sarthak SharmaNo ratings yet
- Lec 12 - Regresi Multi-LinierDocument22 pagesLec 12 - Regresi Multi-LinierAsal ReviewNo ratings yet
- Ncert Solutions For Class 11 Maths May22 Chapter 15 StatisticsDocument52 pagesNcert Solutions For Class 11 Maths May22 Chapter 15 StatisticsPriyanshuNo ratings yet
- Week 5 Empirical - Methods 2Document20 pagesWeek 5 Empirical - Methods 2muller1234No ratings yet
- Lecture PDFDocument115 pagesLecture PDFAnwar HussainNo ratings yet
- Relationship B/W Dependent and Independent Variables: 1) Functional RelationDocument9 pagesRelationship B/W Dependent and Independent Variables: 1) Functional RelationMuhammad BilalNo ratings yet
- Tutorial 5 Worksheet 7 Question 3 Answers Julian MoolenburghDocument3 pagesTutorial 5 Worksheet 7 Question 3 Answers Julian MoolenburghGing ChingNo ratings yet
- CBSE Class 11 Economics Sample Paper Set A PDFDocument7 pagesCBSE Class 11 Economics Sample Paper Set A PDFumangNo ratings yet
- Slides03 PDFDocument25 pagesSlides03 PDFHani RNo ratings yet
- Calculate Q3 For The Following Data. Sales (In Lakhs ) 10-20 20-30 30-40 40-50Document6 pagesCalculate Q3 For The Following Data. Sales (In Lakhs ) 10-20 20-30 30-40 40-50David Oba OlayiwolaNo ratings yet
- ADMS 2200-Marketing Plan-BudgetDocument8 pagesADMS 2200-Marketing Plan-BudgetBeatak1No ratings yet
- Correlation and Regression 32Document10 pagesCorrelation and Regression 32Cry BeroNo ratings yet
- 11 Economics SP 02Document15 pages11 Economics SP 02MOHAMMAD SYED AEJAZNo ratings yet
- Usps April27meetingDocument18 pagesUsps April27meetingtmurseNo ratings yet
- 101sln PDFDocument12 pages101sln PDFPres Asociatie3kNo ratings yet
- Holistic Progress Card (2023-24) : Ar Ayan Wajid KallurukalluruDocument4 pagesHolistic Progress Card (2023-24) : Ar Ayan Wajid KallurukalluruMasthan Vali KNo ratings yet
- Chapter 12Document19 pagesChapter 12Hossam AboomarNo ratings yet
- CBSE X Maths Case Study Practice Tests (3 Topics)Document7 pagesCBSE X Maths Case Study Practice Tests (3 Topics)Vishal MNo ratings yet
- ECMT2130: Semester 2, 2020 Assignment: Geoff Shuetrim Geoffrey - Shuetrim@sydney - Edu.au University of SydneyDocument7 pagesECMT2130: Semester 2, 2020 Assignment: Geoff Shuetrim Geoffrey - Shuetrim@sydney - Edu.au University of SydneyDaniyal AsifNo ratings yet
- Kuliah10 Analisa Time Series Dan TrendDocument9 pagesKuliah10 Analisa Time Series Dan TrendDita EnsNo ratings yet
- 3 Regresi LinierDocument30 pages3 Regresi LinierRozy SulthanaNo ratings yet
- What Is VLSI and Why You Should CareDocument21 pagesWhat Is VLSI and Why You Should CareRameshNo ratings yet
- Elective Computational MathematicsDocument36 pagesElective Computational Mathematicspradhumnyadav756No ratings yet
- CITATION HTT /L 1033Document55 pagesCITATION HTT /L 1033Miskatul ArafatNo ratings yet
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocument6 pagesUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNo ratings yet
- Dynamics, Adaptive Control and Extended Synchronization of Hyperchaotic System and Its Application To Secure CommunicationDocument17 pagesDynamics, Adaptive Control and Extended Synchronization of Hyperchaotic System and Its Application To Secure CommunicationijccmsNo ratings yet
- Strategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDocument23 pagesStrategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDeepak ChaudharyNo ratings yet
- Strategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDocument24 pagesStrategy: This Document Is Strictly For Personal Use. Do Not Share With OthersDeepak ChaudharyNo ratings yet
- 4.49tybsc ItDocument12 pages4.49tybsc ItAbhay Prajapati0% (2)
- Applied Financial Econometrics Using Stata 3. Linear Factor ModelsDocument42 pagesApplied Financial Econometrics Using Stata 3. Linear Factor ModelsNeemaNo ratings yet
- Assignment 1Document2 pagesAssignment 1Dong NguyenNo ratings yet
- HRM Assignment PDFDocument5 pagesHRM Assignment PDFnamami saxenaNo ratings yet
- Module Scheme of WorkDocument5 pagesModule Scheme of WorkJan FishNo ratings yet
- Project Work: - DR Parag AjagaonkarDocument13 pagesProject Work: - DR Parag AjagaonkarHussainAttarwalaNo ratings yet
- Y7 ICT-Ms PatriciaDocument4 pagesY7 ICT-Ms PatriciaemonimtiazNo ratings yet
- BijanresumeDocument1 pageBijanresumeapi-317032154No ratings yet
- Detailed Lesson Plan (DLP) in Earth & Life Science: S11/12ES-Ia-e-4Document5 pagesDetailed Lesson Plan (DLP) in Earth & Life Science: S11/12ES-Ia-e-4Bowina KhoNo ratings yet
- Ed10 BISLIG Globalization and Multicultural LiteracyDocument5 pagesEd10 BISLIG Globalization and Multicultural LiteracyCrysvenne Perez BisligNo ratings yet
- LBS Research Proposal Format-FinalDocument3 pagesLBS Research Proposal Format-FinalAhsanFarooqNo ratings yet
- Cover Letter For Special Needs Teaching AssistantDocument7 pagesCover Letter For Special Needs Teaching Assistantvyp0wosyb1m3100% (2)
- Automatic Speech RecognitionDocument9 pagesAutomatic Speech RecognitionRahul RajNo ratings yet
- Grade5 Health Catch Up FridayDocument2 pagesGrade5 Health Catch Up Fridaymariaestrellita.bolasa94% (16)
- Learning SMDocument107 pagesLearning SMSudip AcharyaNo ratings yet
- Form 137 Format ElementaryDocument7 pagesForm 137 Format ElementaryNoemi Credito MataNo ratings yet
- 1371594350-ELT 303 Teaching Speaking and Listening Comp. Skills 2013-2014 Syllabus PDFDocument8 pages1371594350-ELT 303 Teaching Speaking and Listening Comp. Skills 2013-2014 Syllabus PDFGenesis Abesia LaborNo ratings yet
- ERPH 2022 EnglishDocument14 pagesERPH 2022 EnglishSarveena MurugiahNo ratings yet
- Classroom AccommodationsDocument13 pagesClassroom AccommodationsTiffany InocenteNo ratings yet
- 131 FullDocument11 pages131 Fullcrys_by666No ratings yet
- Abra State Insitute of Sciences and TechnologyDocument11 pagesAbra State Insitute of Sciences and TechnologyRebelita BejarinNo ratings yet
- Designing Websites in Dreamweaver CS5Document284 pagesDesigning Websites in Dreamweaver CS5heomasyNo ratings yet
- 5 - Exit Survey FormDocument5 pages5 - Exit Survey FormRaja SekarNo ratings yet
- SCSA3015 Deep Learning Quiz For IV Year (Batch 2019 - 2023)Document15 pagesSCSA3015 Deep Learning Quiz For IV Year (Batch 2019 - 2023)Pavan VangapallyNo ratings yet
- Arabic English CV 001Document1 pageArabic English CV 001Ayman GhaziNo ratings yet
- SBM Form 1 School Based Management SBM Validation Tool SY 18-19-19 20Document17 pagesSBM Form 1 School Based Management SBM Validation Tool SY 18-19-19 20Erick SibugNo ratings yet
- KRAI PracticalDocument14 pagesKRAI PracticalContact VishalNo ratings yet
- Report Assesment FormDocument2 pagesReport Assesment FormMuhammad FirdausNo ratings yet
- Problems Facing Teaching and Learning ofDocument27 pagesProblems Facing Teaching and Learning ofoluwafemi MatthewNo ratings yet