Download as pdf or txt
You might also like
- Chapter 3 Quantitative Research MethodologyDocument54 pagesChapter 3 Quantitative Research MethodologyClarence Dave T. TolentinoNo ratings yet
- Concept of The ScaleDocument2 pagesConcept of The ScaleAliasNo ratings yet
- Chapter 6 Models and Technique of MP Demand and Supply Forecasting by Shahid ElimsDocument18 pagesChapter 6 Models and Technique of MP Demand and Supply Forecasting by Shahid ElimsJoginder GrewalNo ratings yet
- NSTP - Project MatrixDocument1 pageNSTP - Project MatrixJandrei Garcia AdonisNo ratings yet
- Sampling Techniques2Document5 pagesSampling Techniques2MLeidyyy100% (1)
- RIZAL ReflectionDocument2 pagesRIZAL ReflectionEvan BoaloyNo ratings yet
- Personal Commitment StatementDocument1 pagePersonal Commitment StatementMark Hizon BellosilloNo ratings yet
- MGT Man Is Called To Served GODDocument3 pagesMGT Man Is Called To Served GODAllan AgpaloNo ratings yet
- Community-Based ManagementDocument28 pagesCommunity-Based ManagementDIANNE MAE JULAINE MALUBAY PABLEONo ratings yet
- Reflection Paper 8Document3 pagesReflection Paper 8Catunhay, Charelle B.No ratings yet
- Luna Colleges, Inc.: The Impact of Review Centers On The College Examinee'S ConfidenceDocument26 pagesLuna Colleges, Inc.: The Impact of Review Centers On The College Examinee'S ConfidenceApril Abril SalvadorNo ratings yet
- 5 2018 12 10!09 06 45 PMDocument18 pages5 2018 12 10!09 06 45 PMMa Jeneva Macutay SajulgaNo ratings yet
- Financial Literacy of Teachers and School Heads in The Division of Marinduque: Basis For Financial Education Enhancement ProgramDocument12 pagesFinancial Literacy of Teachers and School Heads in The Division of Marinduque: Basis For Financial Education Enhancement ProgramPsychology and Education: A Multidisciplinary JournalNo ratings yet
- Chapter 6 Job Evaluation and Work-Flow AnalysisDocument5 pagesChapter 6 Job Evaluation and Work-Flow AnalysisJenefer Diano100% (2)
- Activities 1-5 - BoncalesDocument12 pagesActivities 1-5 - BoncalesBraille Boncales100% (1)
- RBA Chapter 7 PostingDocument10 pagesRBA Chapter 7 PostingReiner GGayNo ratings yet
- Rizal Activity 1 Compare and ContrastDocument2 pagesRizal Activity 1 Compare and ContrastJenny Rose BautistaNo ratings yet
- Compensation Structure in The PhilippinesDocument12 pagesCompensation Structure in The PhilippinesLeavic MaghanoyNo ratings yet
- Life and Works of Rizal - Chapter 2Document1 pageLife and Works of Rizal - Chapter 2Gwendell June SevilloNo ratings yet
- Banco de Oro Universal Bank: A Brief StudyDocument22 pagesBanco de Oro Universal Bank: A Brief StudyLileth ViduyaNo ratings yet
- Pros and Cons of Market IntegrationDocument1 pagePros and Cons of Market IntegrationBlank UNKOWNNo ratings yet
- Quiz 2-MMWDocument2 pagesQuiz 2-MMWEngel QuimsonNo ratings yet
- Ge 4 - Mathematics in The Modern World (Final Term) : Secillano, Patrick Joseph NDocument63 pagesGe 4 - Mathematics in The Modern World (Final Term) : Secillano, Patrick Joseph NNimfa SantiagoNo ratings yet
- Abegail Chio BSHM 1B NSTP Activity 1 To 4Document11 pagesAbegail Chio BSHM 1B NSTP Activity 1 To 4Edrin Roy Cachero SyNo ratings yet
- RRL ProgressedDocument14 pagesRRL ProgressedMonique100% (1)
- What Is Your Understanding of The Concept of Governance? and What Is Your Own Concept of Governance? ExplainDocument5 pagesWhat Is Your Understanding of The Concept of Governance? and What Is Your Own Concept of Governance? ExplainMarkRubinOpoNo ratings yet
- Math 321E Presentation of Data PDFDocument10 pagesMath 321E Presentation of Data PDFCyrus RivasNo ratings yet
- Knowledge and Competence of Barangay Officials in The Preparation of Annual and Supplemental Budget 1 3Document21 pagesKnowledge and Competence of Barangay Officials in The Preparation of Annual and Supplemental Budget 1 3rodante.villaflorNo ratings yet
- Reflective Paper On RizalDocument1 pageReflective Paper On RizalPj MaximoNo ratings yet
- Term Paper in ES 1Document13 pagesTerm Paper in ES 1Kirsty CorreaNo ratings yet
- Fin. Mar. Financial AnalysisDocument5 pagesFin. Mar. Financial AnalysisCatastropheNo ratings yet
- NSTP - Training Evaluation FormDocument1 pageNSTP - Training Evaluation FormCRox's BryNo ratings yet
- Partnership Dissolution Withdrawal Retirement Death and IncapacityDocument25 pagesPartnership Dissolution Withdrawal Retirement Death and IncapacityGale KnowsNo ratings yet
- Chapter 04 Channel Strat Devt DesignDocument12 pagesChapter 04 Channel Strat Devt DesignAj CapungganNo ratings yet
- Jose Rizal'S Life: Family, Childhood and Early EducationDocument13 pagesJose Rizal'S Life: Family, Childhood and Early EducationWai KikiNo ratings yet
- City Savings BankDocument42 pagesCity Savings Bankjackielyn abaoNo ratings yet
- Lesson 2-ObliconDocument14 pagesLesson 2-ObliconDrew BanlutaNo ratings yet
- Grp. 1 Case Study - The TransferDocument9 pagesGrp. 1 Case Study - The TransfermryanndvidNo ratings yet
- NSTP1 TaskDocument9 pagesNSTP1 TaskPRECIOUS MAENo ratings yet
- GHI Company Comparative Balance Sheet For The Year 2015 & 2016Document3 pagesGHI Company Comparative Balance Sheet For The Year 2015 & 2016Kl HumiwatNo ratings yet
- Polya S SolvingDocument10 pagesPolya S SolvingWendel RoiNo ratings yet
- Miguel López de LegazpiDocument8 pagesMiguel López de LegazpiKristel YeenNo ratings yet
- Synthesis On Cost of CapitalDocument2 pagesSynthesis On Cost of CapitalRu Martin100% (1)
- Midterm ParCorDocument5 pagesMidterm ParCorMae Ann RenlingNo ratings yet
- Worksheet 2 in RE 111Document5 pagesWorksheet 2 in RE 111Shiella marie VillaNo ratings yet
- Module 2 (Junel Dela Cruz)Document4 pagesModule 2 (Junel Dela Cruz)madara cruzNo ratings yet
- Activity 5Document3 pagesActivity 5MARLYNJHANE PEPITONo ratings yet
- Lapasan Cagayan de Oro City Misamis Oriental Philippines - PhilippinesDocument14 pagesLapasan Cagayan de Oro City Misamis Oriental Philippines - PhilippinesJohn Edenson VelonoNo ratings yet
- NSTP NotesDocument15 pagesNSTP Notesrheena espirituNo ratings yet
- What Is A Road MapDocument2 pagesWhat Is A Road MapShenivelChimChimNo ratings yet
- Assignment: The Rizal LawDocument3 pagesAssignment: The Rizal LawMary ruth DavidNo ratings yet
- Exercise 13Document40 pagesExercise 13JA Mie CompbellNo ratings yet
- Activity 1. SWOT ANALYSISDocument12 pagesActivity 1. SWOT ANALYSISNICOLE BURDEOSNo ratings yet
- GE1213 - 16-301 - (MODULE 2) Rio, ReignaDocument2 pagesGE1213 - 16-301 - (MODULE 2) Rio, ReignaReigna RioNo ratings yet
- Comparison of Online and Traditional Learning in 3 Year Students On Icct Colleges Foundation Inc. Main CampusDocument25 pagesComparison of Online and Traditional Learning in 3 Year Students On Icct Colleges Foundation Inc. Main CampusAltillero, Philmar T.No ratings yet
- Filipino Values and Moral DevelopmentDocument5 pagesFilipino Values and Moral DevelopmentMaanParrenoVillar100% (1)
- Chapter 2 ActivityDocument10 pagesChapter 2 ActivityBELARMINO LOUIE A.No ratings yet
- I. Make A Timeline by Filling in The Boxes With Significant Events of Rizal's Boyhood Years and Early EducationDocument1 pageI. Make A Timeline by Filling in The Boxes With Significant Events of Rizal's Boyhood Years and Early EducationArlene GarciaNo ratings yet
- AD. Exercise 10a. El FilibusterismoDocument2 pagesAD. Exercise 10a. El FilibusterismoMARIELLE SANDRA T. TOBESNo ratings yet
- Module 1 Sys100 & SMP3Document20 pagesModule 1 Sys100 & SMP3Neivil Jean N. EgoniaNo ratings yet
- CWTS: Good CitizenshipDocument10 pagesCWTS: Good CitizenshipMyannmar SinatadNo ratings yet
- Volunteerism of Human Act SchoologyDocument12 pagesVolunteerism of Human Act SchoologyAlice KrodeNo ratings yet
- Session 2 Multimedia Resources: Learning Objectives: at The End of The Session, Students CanDocument6 pagesSession 2 Multimedia Resources: Learning Objectives: at The End of The Session, Students CanAlice KrodeNo ratings yet
- BlankDocument1 pageBlankAlice KrodeNo ratings yet
- Meeting With Parents of Graduating Class Summary of DiscussionDocument2 pagesMeeting With Parents of Graduating Class Summary of DiscussionAlice KrodeNo ratings yet
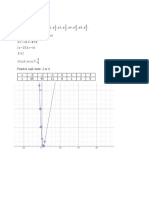
- F (X) 3 X Possible Rational Roots 1,, 2,, 4, , 8, - F (X) 3 X F (X) 0Document2 pagesF (X) 3 X Possible Rational Roots 1,, 2,, 4, , 8, - F (X) 3 X F (X) 0Alice KrodeNo ratings yet
- CE 10 4th Quarter Exam ReviewerDocument2 pagesCE 10 4th Quarter Exam ReviewerAlice KrodeNo ratings yet
- Modifiers of Human ActDocument12 pagesModifiers of Human ActAlice KrodeNo ratings yet
- Christian Education 10 4th Quarter Lesson 4Document3 pagesChristian Education 10 4th Quarter Lesson 4Alice KrodeNo ratings yet
- Research Paper Outline TemplateDocument4 pagesResearch Paper Outline TemplateAlice KrodeNo ratings yet
- Christian Education 10 4th Quarter Lesson 2Document2 pagesChristian Education 10 4th Quarter Lesson 2Alice KrodeNo ratings yet
- Christian Education 10 4th Quarter Lesson 1Document2 pagesChristian Education 10 4th Quarter Lesson 1Alice KrodeNo ratings yet
- Music+ +4th+Quarter+Lesson+1+&+2+ (Philippine+Operas,+Musicals,+and+Ballets)Document22 pagesMusic+ +4th+Quarter+Lesson+1+&+2+ (Philippine+Operas,+Musicals,+and+Ballets)Alice KrodeNo ratings yet
- Learning Objectives: at The End of The Session, Students CanDocument7 pagesLearning Objectives: at The End of The Session, Students CanAlice KrodeNo ratings yet
- Learning Objectives: at The End of The Session, Students CanDocument7 pagesLearning Objectives: at The End of The Session, Students CanAlice KrodeNo ratings yet
- PE - 4th Quarter Lesson 1 & 2 (Contemporary Dance)Document25 pagesPE - 4th Quarter Lesson 1 & 2 (Contemporary Dance)Alice KrodeNo ratings yet
- Measures of Position: Ungrouped DataDocument26 pagesMeasures of Position: Ungrouped DataAlice KrodeNo ratings yet
- Christian Education 10 3rd Quarter Lesson 6Document3 pagesChristian Education 10 3rd Quarter Lesson 6Alice KrodeNo ratings yet
- #Theinside: - Imagine That You Are Speaking On Stage and in Front of An Audience. - Draw What You FeelDocument9 pages#Theinside: - Imagine That You Are Speaking On Stage and in Front of An Audience. - Draw What You FeelAlice KrodeNo ratings yet
- S7 KurtosisDocument33 pagesS7 KurtosisAlice KrodeNo ratings yet
- Session 11Document14 pagesSession 11Alice KrodeNo ratings yet
- Doctrines Show The Marvelous, Inconceivable, Infinite Love of God To Poor Sinful Humanity." - DRDocument3 pagesDoctrines Show The Marvelous, Inconceivable, Infinite Love of God To Poor Sinful Humanity." - DRAlice KrodeNo ratings yet
- Care For The EnvironmentDocument18 pagesCare For The EnvironmentAlice KrodeNo ratings yet
- Learning Objectives: at The End of The Session, Students CanDocument6 pagesLearning Objectives: at The End of The Session, Students CanAlice KrodeNo ratings yet
- Learning Objectives: at The End of The Session, Students CanDocument10 pagesLearning Objectives: at The End of The Session, Students CanAlice KrodeNo ratings yet
- Hypothesis TestingDocument57 pagesHypothesis TestingPranavMachingalNo ratings yet
- Methods of Research (2 Semester, 2020-2021) Pedrito Jose V. Bermudo, Edd PHD ProfessorDocument154 pagesMethods of Research (2 Semester, 2020-2021) Pedrito Jose V. Bermudo, Edd PHD ProfessorYuriiNo ratings yet
- Compiled Notes: Mscfe 610 EconometricsDocument29 pagesCompiled Notes: Mscfe 610 Econometricssadiqpmp100% (1)
- ANOVADocument23 pagesANOVAAkash Raj BeheraNo ratings yet
- Function of Stochastic ProcessDocument58 pagesFunction of Stochastic ProcessbiruckNo ratings yet
- Determining A-Weighted Sound Power Level of Central Vacuum Power UnitsDocument8 pagesDetermining A-Weighted Sound Power Level of Central Vacuum Power UnitsAhmad Zubair RasulyNo ratings yet
- Assessment of The Level of Confidence of Female SPS Students in Luis Palad Integrated High SchoolDocument33 pagesAssessment of The Level of Confidence of Female SPS Students in Luis Palad Integrated High SchoolJunell Mathew Catilo100% (1)
- Safety Executive (HSE) Almost Half A Million People in Britain Experience Some Stresses Resulted From Their Jobs and Cause Many Increasing DiseasesDocument5 pagesSafety Executive (HSE) Almost Half A Million People in Britain Experience Some Stresses Resulted From Their Jobs and Cause Many Increasing DiseasesCătălina BodnariucNo ratings yet
- Pengaruh Pengalaman Kerja, Independensi, Integritas, Kompetensi Dan Etika Auditor Kualitas AuditDocument13 pagesPengaruh Pengalaman Kerja, Independensi, Integritas, Kompetensi Dan Etika Auditor Kualitas AuditsaridNo ratings yet
- Democracy, Economic Development, and Income InequalityDocument20 pagesDemocracy, Economic Development, and Income InequalityNeel Kurupassery100% (1)
- M.L. 3,5,6 Unit 3Document6 pagesM.L. 3,5,6 Unit 3atharv moreNo ratings yet
- Simulation Composing Mozart 1Document3 pagesSimulation Composing Mozart 1api-490493590No ratings yet
- Js Roulette 2006Document125 pagesJs Roulette 2006lien219No ratings yet
- Data Science - ProbabilityDocument53 pagesData Science - ProbabilityNguyen Van TienNo ratings yet
- Seminar Presentation For CvSU Thesis Form Style 2016Document52 pagesSeminar Presentation For CvSU Thesis Form Style 2016Julianna RamirezNo ratings yet
- MBA Syllabus 1st SemesterDocument10 pagesMBA Syllabus 1st SemesterAditya RajNo ratings yet
- Composite SamplesDocument4 pagesComposite SamplesMas BroNo ratings yet
- Mehran Riaz - 17232720-016 - QTBDocument13 pagesMehran Riaz - 17232720-016 - QTBMehran MalikNo ratings yet
- Lecture On Sampling and Sample SizeDocument16 pagesLecture On Sampling and Sample SizePRITI DASNo ratings yet
- Panel Data Methods For Microeconometrics Using Stata: A. Colin Cameron Univ. of California - DavisDocument55 pagesPanel Data Methods For Microeconometrics Using Stata: A. Colin Cameron Univ. of California - DavisLennard Pang100% (1)
- Project ReportDocument27 pagesProject ReportPanchami MPNo ratings yet
- Cost 336 - FWDDocument66 pagesCost 336 - FWDRobert Adrian SanduNo ratings yet
- Impact of Internet Research PaperDocument4 pagesImpact of Internet Research PaperJune Econg100% (1)
- Moore 16Document26 pagesMoore 16ankuriitbNo ratings yet
- Corporate Governance Issues Regarding Transfer PriDocument17 pagesCorporate Governance Issues Regarding Transfer PriShelviDyanPrastiwiNo ratings yet
- ArtikelDocument7 pagesArtikelaisyah nabilaNo ratings yet
- 2018 04 Exam Stam QuestionsDocument14 pages2018 04 Exam Stam QuestionsInsani Putri EdiNo ratings yet
- Pemanfaatan Pelayanan Kesehatan Oleh Peserta BPJS PDFDocument8 pagesPemanfaatan Pelayanan Kesehatan Oleh Peserta BPJS PDFAdam SINo ratings yet