Download as pdf or txt
You might also like
- 2008 Mech PDFDocument82 pages2008 Mech PDFmotuandgoluNo ratings yet
- SMSC 52 Command Reference Manual PDFDocument1,508 pagesSMSC 52 Command Reference Manual PDFTomNo ratings yet
- 3D-Shapes Symmetry Patterns-Term2 WorksheetDocument3 pages3D-Shapes Symmetry Patterns-Term2 Worksheetmahroof50% (2)
- Asr2000 Final FooterDocument8 pagesAsr2000 Final Footerقرين لطفيNo ratings yet
- Speech Analysis in Search of Speakers With MFCC, PLP, Jitter and ShimmerDocument4 pagesSpeech Analysis in Search of Speakers With MFCC, PLP, Jitter and ShimmerLuis Carlos EspeletaNo ratings yet
- Improvement of Text Dependent Speaker Identification System Using Neuro-Genetic Hybrid Algorithm in Office Environmental ConditionsDocument6 pagesImprovement of Text Dependent Speaker Identification System Using Neuro-Genetic Hybrid Algorithm in Office Environmental ConditionsShiv Ram ChNo ratings yet
- SC ReportDocument3 pagesSC ReportABHISHEK BNo ratings yet
- Analysis of Feature Extraction Techniques For Speech Recognition SystemDocument4 pagesAnalysis of Feature Extraction Techniques For Speech Recognition SystemsridharchandrasekarNo ratings yet
- Gender Detection by Voice Using Deep LearningDocument5 pagesGender Detection by Voice Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- A Class of Physical Modeling Recurrent Networks For Analysis / Synthesis of Plucked String InstrumentsDocument12 pagesA Class of Physical Modeling Recurrent Networks For Analysis / Synthesis of Plucked String InstrumentsinassociavelNo ratings yet
- Se 4Document5 pagesSe 4pravin2275767No ratings yet
- Speech Emotion Recognition With Deep LearningDocument5 pagesSpeech Emotion Recognition With Deep LearningHari HaranNo ratings yet
- Speech Recognition Using AANNDocument4 pagesSpeech Recognition Using AANNtestNo ratings yet
- Reconocimiento de Voz - MATLABDocument5 pagesReconocimiento de Voz - MATLABJulitoNo ratings yet
- ECE - Improved Speech - HiteshDocument8 pagesECE - Improved Speech - HiteshTJPRC PublicationsNo ratings yet
- Documents Audio Super Resolution Using Neural NetworksDocument8 pagesDocuments Audio Super Resolution Using Neural NetworksmahefatheoduleNo ratings yet
- 3 Deec 51 Ae 28 Ba 013 A 4Document5 pages3 Deec 51 Ae 28 Ba 013 A 4Carrot ItCsNo ratings yet
- Urban Sound ClassificationDocument6 pagesUrban Sound Classificationamit kNo ratings yet
- Audio Enhancement and Denoising Using Online Non-Negative Matrix Factorization and Deep LearningDocument9 pagesAudio Enhancement and Denoising Using Online Non-Negative Matrix Factorization and Deep LearningIJRASETPublicationsNo ratings yet
- Applsci 12 09000 v3 PDFDocument14 pagesApplsci 12 09000 v3 PDFRaviShankar PrasadNo ratings yet
- Dushyant Sharma, Patrick A. Naylor, Nikolay D. Gaubitch and Mike BrookesDocument4 pagesDushyant Sharma, Patrick A. Naylor, Nikolay D. Gaubitch and Mike Brookescreatedon2003No ratings yet
- Paper 3Document8 pagesPaper 3NavneetNo ratings yet
- Experimental Study On Extreme Learning Machine Applications For Speech EnhancementDocument13 pagesExperimental Study On Extreme Learning Machine Applications For Speech EnhancementJBNo ratings yet
- Wang 2010Document6 pagesWang 2010manishscryNo ratings yet
- A Comparison of LPC and FFT-based Acoustic FeatureDocument5 pagesA Comparison of LPC and FFT-based Acoustic FeatureAriel FerreiraNo ratings yet
- s13636 021 00204 9 PDFDocument15 pagess13636 021 00204 9 PDFRkeA RkeRNo ratings yet
- Preprocessing SignalDocument6 pagesPreprocessing SignalMEMNo ratings yet
- Comparison of Speech Enhancement Algorithms: SciencedirectDocument11 pagesComparison of Speech Enhancement Algorithms: SciencedirectRoberto MouraNo ratings yet
- Partial Instance Reduction For Noise EliminationDocument8 pagesPartial Instance Reduction For Noise EliminationmuhammadrizNo ratings yet
- Itc Review 3 PDFDocument8 pagesItc Review 3 PDFGvj VamsiNo ratings yet
- Home Automation Please Read This ShitDocument5 pagesHome Automation Please Read This ShitEnh ManlaiNo ratings yet
- Audio Steganograpgy by Phase Modification: Fatiha Djebbar Beghdad AyadDocument5 pagesAudio Steganograpgy by Phase Modification: Fatiha Djebbar Beghdad AyadNgà TrầnNo ratings yet
- Confusion Matrix Validation of An Urdu Language Speech Number SystemDocument7 pagesConfusion Matrix Validation of An Urdu Language Speech Number SystemhekhtiyarNo ratings yet
- Audio Steganography Coding Using The Discrete Wavelet TransformsDocument15 pagesAudio Steganography Coding Using The Discrete Wavelet TransformsDeivid CArpioNo ratings yet
- Attention Audio Visual Speech RecognitionDocument5 pagesAttention Audio Visual Speech RecognitionEmna BouhajebNo ratings yet
- Sampling Phased Array - A New Technique For Signal Processing and Ultrasonic ImagingDocument12 pagesSampling Phased Array - A New Technique For Signal Processing and Ultrasonic ImagingBoulHich BoulHichNo ratings yet
- Some Refelexions and Results About Adeqaute Speech Denoising Technique According To Desired QualityDocument4 pagesSome Refelexions and Results About Adeqaute Speech Denoising Technique According To Desired QualityAnis Ben AichaNo ratings yet
- BirdDocument10 pagesBirdAkhil Jabbar MeerjaNo ratings yet
- Voice Recognition System Using Machine LDocument7 pagesVoice Recognition System Using Machine LShahriyar Chowdhury ShawonNo ratings yet
- ReportDocument14 pagesReportjithin jayNo ratings yet
- Discriminatively Trained Recurrent Neural Networks For Single-Channel Speech SeparationDocument5 pagesDiscriminatively Trained Recurrent Neural Networks For Single-Channel Speech SeparationJoseph FranklinNo ratings yet
- Identification of Underwater Acoustic NoDocument6 pagesIdentification of Underwater Acoustic Nonhan1999.ntNo ratings yet
- Speaker Recognition System Using MFCC and Vector QuantizationDocument7 pagesSpeaker Recognition System Using MFCC and Vector QuantizationlambanaveenNo ratings yet
- Pitch Recognition Through Template Matching: Salim PerchyDocument11 pagesPitch Recognition Through Template Matching: Salim PerchyWerdika YudiNo ratings yet
- Echo Cancellation ThesisDocument5 pagesEcho Cancellation Thesisafjrqxflw100% (2)
- 8834 PDFDocument8 pages8834 PDFAnubhavNo ratings yet
- Vision Transformer Based Audio Classification Using Patch-Level Feature FusionDocument5 pagesVision Transformer Based Audio Classification Using Patch-Level Feature FusioncacaNo ratings yet
- Laboratory5 ELECTIVE2Document5 pagesLaboratory5 ELECTIVE2Ed LozadaNo ratings yet
- Stop Gap Removal Using Spectral Parameters For Stuttered Speech SignalDocument5 pagesStop Gap Removal Using Spectral Parameters For Stuttered Speech SignalVelumani sNo ratings yet
- Transient Detection in Speech and Audio SignalsDocument8 pagesTransient Detection in Speech and Audio SignalsThanuja adepuNo ratings yet
- EHaCON - 2019 Paper 8Document20 pagesEHaCON - 2019 Paper 8Himadri Sekhar DuttaNo ratings yet
- Rasta PLP 1 EditedDocument16 pagesRasta PLP 1 EditedSri HariNo ratings yet
- Expert Systems With Applications: P. Dhanalakshmi, S. Palanivel, V. RamalingamDocument7 pagesExpert Systems With Applications: P. Dhanalakshmi, S. Palanivel, V. Ramalingampurple raNo ratings yet
- Ijacst04742018 PDFDocument4 pagesIjacst04742018 PDFkaushikNo ratings yet
- Musical Gesture Recognition Using Machine Learning and Audio DescriptorsDocument5 pagesMusical Gesture Recognition Using Machine Learning and Audio DescriptorsNagendra NagshaNo ratings yet
- Voice RecognitionDocument18 pagesVoice Recognitionr100% (1)
- Final SynopsisDocument23 pagesFinal Synopsisatul narkhedeNo ratings yet
- RaveDocument15 pagesRavebugNo ratings yet
- 2 Text Independent Voice Based Students Attendance System Under Noisy Environment Using RASTA-MFCC FeatureDocument6 pages2 Text Independent Voice Based Students Attendance System Under Noisy Environment Using RASTA-MFCC FeatureSusanta SarangiNo ratings yet
- Attention Gated Encoder-Decoder For Ultrasonic Signal DenoisingDocument9 pagesAttention Gated Encoder-Decoder For Ultrasonic Signal DenoisingIAES IJAINo ratings yet
- Eurospeech2001 Wavel PDFDocument4 pagesEurospeech2001 Wavel PDFHaripriya RadhakrishnanNo ratings yet
- Software Radio: Sampling Rate Selection, Design and SynchronizationFrom EverandSoftware Radio: Sampling Rate Selection, Design and SynchronizationNo ratings yet
- Audio Visual Speech Recognition: Advancements, Applications, and InsightsFrom EverandAudio Visual Speech Recognition: Advancements, Applications, and InsightsNo ratings yet
- Artificial Intelligence in Education Technologies: New Development and Innovative PracticesDocument224 pagesArtificial Intelligence in Education Technologies: New Development and Innovative PracticesAbdelkbir WsNo ratings yet
- IEEEMELECON2022Document6 pagesIEEEMELECON2022Abdelkbir WsNo ratings yet
- Artificial Intelligence in Education An Argument of Chat-GPT Use in EducationDocument6 pagesArtificial Intelligence in Education An Argument of Chat-GPT Use in EducationAbdelkbir WsNo ratings yet
- Merajul Hasan 1Document11 pagesMerajul Hasan 1Abdelkbir WsNo ratings yet
- Cosentino 2020Document5 pagesCosentino 2020Abdelkbir WsNo ratings yet
- Performanceanalysisof ASRModelfor Santhalilanguageon Kaldiand Matlab ToolkitDocument5 pagesPerformanceanalysisof ASRModelfor Santhalilanguageon Kaldiand Matlab ToolkitAbdelkbir WsNo ratings yet
- Noise Effect On Amazigh Digits in SpeechDocument8 pagesNoise Effect On Amazigh Digits in SpeechAbdelkbir WsNo ratings yet
- DEMAND: A Collection of Multi-Channel Recordings of Acoustic Noise in Diverse EnvironmentsDocument6 pagesDEMAND: A Collection of Multi-Channel Recordings of Acoustic Noise in Diverse EnvironmentsAbdelkbir WsNo ratings yet
- Speech Recognition in Noisy EnvironmentsDocument130 pagesSpeech Recognition in Noisy EnvironmentsAbdelkbir WsNo ratings yet
- 1 s2.0 S0167639322000292 MainDocument16 pages1 s2.0 S0167639322000292 MainAbdelkbir WsNo ratings yet
- 1 s2.0 S0885230821000620 MainDocument13 pages1 s2.0 S0885230821000620 MainAbdelkbir WsNo ratings yet
- Comparative Analysis of Automatic Speech Recognition TechniquesDocument8 pagesComparative Analysis of Automatic Speech Recognition TechniquesAbdelkbir WsNo ratings yet
- Noise Effect On Arabic Alphadigits in AuDocument4 pagesNoise Effect On Arabic Alphadigits in AuAbdelkbir WsNo ratings yet
- 1 s2.0 S0885230819302992 MainDocument16 pages1 s2.0 S0885230819302992 MainAbdelkbir WsNo ratings yet
- 1 s2.0 S1877050916300588 MainDocument8 pages1 s2.0 S1877050916300588 MainAbdelkbir WsNo ratings yet
- Spasov Ski 2015Document8 pagesSpasov Ski 2015Abdelkbir WsNo ratings yet
- Moroccan Dialect Speech Recognition System Based On Cmu SphinxtoolsDocument5 pagesMoroccan Dialect Speech Recognition System Based On Cmu SphinxtoolsAbdelkbir WsNo ratings yet
- Arabic Language Learning Assistance BaseDocument7 pagesArabic Language Learning Assistance BaseAbdelkbir WsNo ratings yet
- Comparing Open-Source Speech Recognition ToolkitsDocument12 pagesComparing Open-Source Speech Recognition ToolkitsAbdelkbir WsNo ratings yet
- 2014 SLT Ali Complete Arabic KaldiDocument6 pages2014 SLT Ali Complete Arabic KaldiAbdelkbir WsNo ratings yet
- Chapter I. Introduction 1-13Document5 pagesChapter I. Introduction 1-13Abdelkbir WsNo ratings yet
- Advancing RNN Transducer Technology For Speech RecognitionDocument5 pagesAdvancing RNN Transducer Technology For Speech RecognitionAbdelkbir WsNo ratings yet
- A Complete Kaldi Recipe For Building Arabic Speech Recognition SystemsDocument5 pagesA Complete Kaldi Recipe For Building Arabic Speech Recognition SystemsAbdelkbir WsNo ratings yet
- Isolated Digit Recognizer Using Gaussian Mixture ModelsDocument44 pagesIsolated Digit Recognizer Using Gaussian Mixture ModelsAbdelkbir WsNo ratings yet
- Automatic Isolated Digit Recognition System: An Approach Using HMMDocument3 pagesAutomatic Isolated Digit Recognition System: An Approach Using HMMAbdelkbir WsNo ratings yet
- Arabic Speech Recognition SystemsDocument8 pagesArabic Speech Recognition SystemsAbdelkbir WsNo ratings yet
- pxc3872774 PDFDocument7 pagespxc3872774 PDFAbdelkbir WsNo ratings yet
- Speaker and Language Recognition by GMMDocument5 pagesSpeaker and Language Recognition by GMMAbdelkbir WsNo ratings yet
- Electrolux Gen4000 Service W465-W4330H S N CompassDocument140 pagesElectrolux Gen4000 Service W465-W4330H S N CompassThếSơnNguyễnNo ratings yet
- Technical Catalogue IzopanelDocument118 pagesTechnical Catalogue IzopanelBen TotoiNo ratings yet
- Properties of Corn Cob Ash ConcreteDocument238 pagesProperties of Corn Cob Ash ConcreteENgřMuhăɱɱadRiǺzAhɱad88% (8)
- 19 LO4 Measures of Central Tendency and SpreadDocument9 pages19 LO4 Measures of Central Tendency and SpreadwmathematicsNo ratings yet
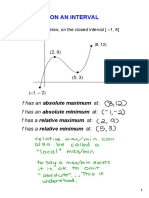
- 3-1 Extrema On An IntervalDocument9 pages3-1 Extrema On An IntervalAbbyNo ratings yet
- Scattering Coefficient Damis CacavelosDocument17 pagesScattering Coefficient Damis CacavelosFederico Nahuel CacavelosNo ratings yet
- Frequency Distribution & HistogramDocument3 pagesFrequency Distribution & HistogramJahangir AliNo ratings yet
- General AnesthesiaDocument2 pagesGeneral AnesthesiadhaineyNo ratings yet
- Power Factor Correction: Wiseman Nene Eit - Electrical Eston Sugar MillDocument42 pagesPower Factor Correction: Wiseman Nene Eit - Electrical Eston Sugar MillPushpendraMeenaNo ratings yet
- AI Lab1Document8 pagesAI Lab1M ANAS BIN MOINNo ratings yet
- Unwinding StationDocument34 pagesUnwinding StationDeniMestiWidiantoNo ratings yet
- Al55 66 Technical Manual v11 EngDocument60 pagesAl55 66 Technical Manual v11 EngProblem VelikiNo ratings yet
- Project Noah - Climatex: Accurate Rain Forecasting For The PhilippinesDocument5 pagesProject Noah - Climatex: Accurate Rain Forecasting For The PhilippinesJaja Ordinario Quiachon-AbarcaNo ratings yet
- Maths Progress International Year 8 Student Book SampleDocument35 pagesMaths Progress International Year 8 Student Book Samplessu371837No ratings yet
- A Comparison Between LDPE and HDPE Cable Insulation Properties Following Lightning Impulse AgeingDocument4 pagesA Comparison Between LDPE and HDPE Cable Insulation Properties Following Lightning Impulse AgeingGilang Satria PasekaNo ratings yet
- Levo Tablets USPDocument2 pagesLevo Tablets USPNikhil Sindhav100% (3)
- Bio-Med Devices Ic-2A Adult Intensive Care Ventilator Instruction ManualDocument40 pagesBio-Med Devices Ic-2A Adult Intensive Care Ventilator Instruction ManualIngenieria NemoconNo ratings yet
- 46R 111 PDFDocument22 pages46R 111 PDFkhaeruzzamanNo ratings yet
- Mav Ip Physics-1Document8 pagesMav Ip Physics-1poojitnatarajanNo ratings yet
- Tableau Text Table - Tableau Crosstab: 1. ObjectiveDocument5 pagesTableau Text Table - Tableau Crosstab: 1. ObjectiveGiri RajNo ratings yet
- ParallelismDocument22 pagesParallelismdeivasigamaniNo ratings yet
- Flow Meter Demonstration Lab ReportDocument25 pagesFlow Meter Demonstration Lab ReportNor Elina Ahmad100% (1)
- Unit IDocument54 pagesUnit ISrivatsan SureshNo ratings yet
- Lms Length Boys 3mon PDocument1 pageLms Length Boys 3mon PArdi IswaraNo ratings yet
- Lab Report A763319Document7 pagesLab Report A763319David EvansNo ratings yet
- Module 11: Ipv4 Addressing: Introduction To Networks V7.0 (Itn)Document58 pagesModule 11: Ipv4 Addressing: Introduction To Networks V7.0 (Itn)Diana YacchiremaNo ratings yet
- Voltage Drop & Cable Sizing & Electrical LoadDocument26 pagesVoltage Drop & Cable Sizing & Electrical Loadfd270% (1)