
Lecture0 12-Mamdani Sugeno
Lecture0 12-Mamdani Sugeno
You might also like
- 11.cluster Validation PDFDocument37 pages11.cluster Validation PDFTanmay KhandelwalNo ratings yet
- Cluster ValidationDocument47 pagesCluster ValidationZeeshan AliNo ratings yet
- Data Mining: Clustering Validation Minimum Description Length Information Theory Co-ClusteringDocument67 pagesData Mining: Clustering Validation Minimum Description Length Information Theory Co-ClusteringArul Kumar VenugopalNo ratings yet
- UntitledDocument1 pageUntitledPower LibraryNo ratings yet
- Example 1.1 Known Points Interpolated X ValueDocument2 pagesExample 1.1 Known Points Interpolated X ValueKendrick TanNo ratings yet
- Cluster Validation L25Document25 pagesCluster Validation L25Roy DeepNo ratings yet
- UjiDocument2 pagesUjiandikaNo ratings yet
- Desember 2022Document1 pageDesember 2022meiraNo ratings yet
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocument18 pages26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNo ratings yet
- Excel BezierDocument3 pagesExcel BezierNelly Sosa MartínezNo ratings yet
- Calculo De Momentos Mab= 17.78 Mbc= 90 Mba= -8.89 Mcb= -90 Calculo De Δ Kab= 4.00 Kcb= I= 12 Kbc= 2.00 Kcd= δBA= 0.67 δCB= δBC= 0.33 δCD=Document12 pagesCalculo De Momentos Mab= 17.78 Mbc= 90 Mba= -8.89 Mcb= -90 Calculo De Δ Kab= 4.00 Kcb= I= 12 Kbc= 2.00 Kcd= δBA= 0.67 δCB= δBC= 0.33 δCD=Jessica ChipanaNo ratings yet
- Validitas WFCDocument12 pagesValiditas WFCQueen Kuwera PrimaryNo ratings yet
- M. Abu Bakar SiddiqueDocument4 pagesM. Abu Bakar SiddiqueNasreen ClothNo ratings yet
- Waveand Wind RoseDocument6 pagesWaveand Wind RoseAldoNo ratings yet
- Machine Learning: An IntroductionDocument80 pagesMachine Learning: An IntroductionadminNo ratings yet
- ArmaduraDocument6 pagesArmaduraI.E. Manuel Scorza Torres - ccaccasiriNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- 5b - Word EmbeddingsDocument17 pages5b - Word EmbeddingsTalha darNo ratings yet
- LifestyleDocument18 pagesLifestyleShashwat JhaNo ratings yet
- Problemario MasmDocument9 pagesProblemario Masmmiguel angel salomon medrano (sammy)No ratings yet
- Count by 2s 5s 10s Girl LadderDocument2 pagesCount by 2s 5s 10s Girl LadderscribdaccountNo ratings yet
- Stat 890 Design of Computer ExperimentsDocument24 pagesStat 890 Design of Computer ExperimentsJoão MiguelNo ratings yet
- Graficos de EquilibrioDocument8 pagesGraficos de EquilibrioEvelyn PauyaNo ratings yet
- Static Moment Sse-Excel Section: The Author Will Not Be Responsible For Any Uses of This Software! v1.06Document1 pageStatic Moment Sse-Excel Section: The Author Will Not Be Responsible For Any Uses of This Software! v1.06SES DESIGNNo ratings yet
- Grafik Tugas LeachingDocument3 pagesGrafik Tugas LeachingChou ChouNo ratings yet
- Planilha Modelo ModeloDocument37 pagesPlanilha Modelo ModeloFernando WuNo ratings yet
- 1. Distribuci´on Binomial: ∼ Binom (n, θ)Document21 pages1. Distribuci´on Binomial: ∼ Binom (n, θ)Jimmy Santiago Soto AristizabalNo ratings yet
- Item AnalysisDocument1 pageItem AnalysisMarjorie MendozaNo ratings yet
- Tablas de DinamicaDocument3 pagesTablas de DinamicaDamian DNNo ratings yet
- Bending Moment and Shear Force Diagram - Cantilever Both Ends Sse-Excel SectionDocument1 pageBending Moment and Shear Force Diagram - Cantilever Both Ends Sse-Excel SectionSES DESIGNNo ratings yet
- 3 Curva Éxito ManualDocument1,925 pages3 Curva Éxito ManualFUNDACION GEOAMBIENTALNo ratings yet
- AEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanDocument2 pagesAEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- Statistics Impact v.1.3.5Document15 pagesStatistics Impact v.1.3.5Ashley Jade DomalantaNo ratings yet
- паучокDocument2 pagesпаучокolegtushchencoNo ratings yet
- Grafik Permas WordDocument14 pagesGrafik Permas Worddela ayu FitriaNo ratings yet
- HW 5Document2 pagesHW 5Edgar Perea LópezNo ratings yet
- ICT Test RatingDocument6 pagesICT Test RatingDayana ZhurmetovaNo ratings yet
- Tutorial SVR01Document73 pagesTutorial SVR01albaroNo ratings yet
- Sample Lab Report.1Document5 pagesSample Lab Report.1Maooz BalochNo ratings yet
- Yassir Fernandez P1Document10 pagesYassir Fernandez P1Yassir FernandezNo ratings yet
- Fenper TutoriaDocument2 pagesFenper TutoriaHudi NurwendiNo ratings yet
- Program 1:: Figure 1 Figure 2Document5 pagesProgram 1:: Figure 1 Figure 2TRUE LOVERSNo ratings yet
- Productpage 3098Document2 pagesProductpage 3098rahmat hidayatNo ratings yet
- Metode Selisih TengahDocument9 pagesMetode Selisih TengahFilda Nur AiniNo ratings yet
- 6 - Series de FourierDocument21 pages6 - Series de Fourieroliveira1305No ratings yet
- Subtracting Decimals in ColumnsDocument22 pagesSubtracting Decimals in ColumnsSaenno KwanNo ratings yet
- Stripper, Atfd 4, Ro (SBT), NT Preheater Daily ReportDocument9 pagesStripper, Atfd 4, Ro (SBT), NT Preheater Daily ReportPriyanshu NayakNo ratings yet
- Binomial y PoissonDocument6 pagesBinomial y Poissonkatherin cheguenNo ratings yet
- Dividing Decimals With Partial Quotients: Answer KeyDocument3 pagesDividing Decimals With Partial Quotients: Answer KeyMUHAMMAD ARIFFUDDIN BIN SUKIAT MoeNo ratings yet
- ENTROPIADocument11 pagesENTROPIALILIAM CAMILA DIOSA SILVANo ratings yet
- CHEGR 2650: Computer Methods in Chemical EngineeringDocument27 pagesCHEGR 2650: Computer Methods in Chemical EngineeringNebojsa MihajlovicNo ratings yet
- Empirical Data Analysis in Accounting and FinanceDocument48 pagesEmpirical Data Analysis in Accounting and FinanceRa'fat JalladNo ratings yet
- Graficas Laboratorio 3Document9 pagesGraficas Laboratorio 3Camilo SanchezNo ratings yet
- Week7 PDFDocument27 pagesWeek7 PDFosmanfıratNo ratings yet
- Statistics Project - Final DraftDocument10 pagesStatistics Project - Final DraftShaurya ParnamiNo ratings yet
- Stiffness MethodDocument1 pageStiffness MethodasluznetNo ratings yet
- Tray KolomDocument4 pagesTray KolomMuchamad Cahya FirdausNo ratings yet
- 24.autoencoder Based Galaxy Image Search - SukKimDocument29 pages24.autoencoder Based Galaxy Image Search - SukKimMuskan ChaudharyNo ratings yet
- Quiz-CORRELATION 1 and 2Document3 pagesQuiz-CORRELATION 1 and 2Aina De LeonNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Theorizing Community Resilience To Earthquakes: Scott B. MilesDocument11 pagesTheorizing Community Resilience To Earthquakes: Scott B. Milessetiono 90No ratings yet
- Structures: SciencedirectDocument10 pagesStructures: Sciencedirectsetiono 90No ratings yet
- International Journal of Disaster Risk Reduction: SciencedirectDocument11 pagesInternational Journal of Disaster Risk Reduction: Sciencedirectsetiono 90No ratings yet
- Lecture 013-Mamdani SugenoDocument72 pagesLecture 013-Mamdani Sugenosetiono 90No ratings yet
- Data Mining and Knowledge DiscoveryDocument32 pagesData Mining and Knowledge Discoverysetiono 90No ratings yet
- Fuzzy Lecture 011 - Mamdani SugenoDocument63 pagesFuzzy Lecture 011 - Mamdani Sugenosetiono 90No ratings yet
- Fuzzy Lecture05-Mamdani SugenoDocument51 pagesFuzzy Lecture05-Mamdani Sugenosetiono 90No ratings yet
- Artificial Intelligence ICS461 Fall 2010: Informed SearchesDocument14 pagesArtificial Intelligence ICS461 Fall 2010: Informed SearchesLawlietNo ratings yet
- Literature Review of Newspaper IndustryDocument10 pagesLiterature Review of Newspaper IndustryVikram Pratap SinghNo ratings yet
- Integer Linear Programming: Management ScienceDocument14 pagesInteger Linear Programming: Management ScienceAlrick BarwaNo ratings yet
- 06 Barreto, John Lloyd D.Document42 pages06 Barreto, John Lloyd D.Johnlloyd BarretoNo ratings yet
- Quantum Approximate Optimization Algorithm: Performance, Mechanism, and Implementation On Near-Term DevicesDocument23 pagesQuantum Approximate Optimization Algorithm: Performance, Mechanism, and Implementation On Near-Term DevicesSakibul Islam SazzadNo ratings yet
- Hackathon - SuridDocument6 pagesHackathon - SuridSamin AfnanNo ratings yet
- DAA Lesson PlanDocument5 pagesDAA Lesson Planrajshreed2014No ratings yet
- FALLSEM2018-19 - CSE1001 - LO - TT238 - VL2018191005495 - Reference Material I - Session 17-TuplesDocument29 pagesFALLSEM2018-19 - CSE1001 - LO - TT238 - VL2018191005495 - Reference Material I - Session 17-TuplesVhan DarshNo ratings yet
- Shortest PathDocument10 pagesShortest PathOporajitaNo ratings yet
- Introduction To Algorithms: Prof. Shafi Goldwasser Prof. Erik DemaineDocument54 pagesIntroduction To Algorithms: Prof. Shafi Goldwasser Prof. Erik Demaineprincipal lnbcNo ratings yet
- Part 3 - Building A Deep Q-Network To Play Gridworld - Learning Instability and Target Networks - by NandaKishore Joshi - Towards Data ScienceDocument7 pagesPart 3 - Building A Deep Q-Network To Play Gridworld - Learning Instability and Target Networks - by NandaKishore Joshi - Towards Data Science배영광No ratings yet
- 4x4 Gaussian ExampleDocument2 pages4x4 Gaussian ExamplerhiyaNo ratings yet
- Data Structures Using CDocument7 pagesData Structures Using CVikram RaoNo ratings yet
- Coin Change Problem Solution Using Dynamic ProgrammingDocument2 pagesCoin Change Problem Solution Using Dynamic Programmingstudy hubNo ratings yet
- Here Is A Pascal Program To Solve Small Problems Using The Simplex AlgorithmDocument12 pagesHere Is A Pascal Program To Solve Small Problems Using The Simplex AlgorithmRodolfo Sergio Cruz FuentesNo ratings yet
- Bytewise Computation of CRC Without Look Up TableDocument3 pagesBytewise Computation of CRC Without Look Up TableKalpana DasNo ratings yet
- Submissions S Itcs123 Bit16 Intermediate Programming Lec 2nd Sem 2022 2023 S Itcs123 Finals Summative Dlsu D College GsDocument9 pagesSubmissions S Itcs123 Bit16 Intermediate Programming Lec 2nd Sem 2022 2023 S Itcs123 Finals Summative Dlsu D College GsAdlei Jed TanNo ratings yet
- Chap7 Basic Cluster AnalysisDocument49 pagesChap7 Basic Cluster Analysisمحمد إحسنNo ratings yet
- List of Unsolved Problems in Computer ScienceDocument3 pagesList of Unsolved Problems in Computer ScienceRaghav SingalNo ratings yet
- Data StructureDocument25 pagesData StructureSamuel DavisNo ratings yet
- Neurocomputing: Bao-Di Liu, Bin Shen, Liangke Gui, Yu-Xiong Wang, Xue Li, Fei Yan, Yan-Jiang WangDocument13 pagesNeurocomputing: Bao-Di Liu, Bin Shen, Liangke Gui, Yu-Xiong Wang, Xue Li, Fei Yan, Yan-Jiang WangMeHaK KhAliDNo ratings yet
- Queue PPTDocument19 pagesQueue PPTharshvardhanshinde.2504No ratings yet
- What Is An Abstract Data Type?Document12 pagesWhat Is An Abstract Data Type?Syed FahadNo ratings yet
- Java Notes: 15.1 Learning OutcomesDocument9 pagesJava Notes: 15.1 Learning OutcomesKule AnthonyNo ratings yet
- FDS PresentationDocument17 pagesFDS PresentationIshaan MattooNo ratings yet
- 3 StacksDocument3 pages3 StacksShru SinghNo ratings yet
- 18cs32 - Data Structure and Its ApplicationDocument22 pages18cs32 - Data Structure and Its Applicationvenkatesh prasadNo ratings yet
- DAA Assignment-1Document15 pagesDAA Assignment-1Vignesh DevamullaNo ratings yet
- Must Save and Share: Tagged Problems FromDocument8 pagesMust Save and Share: Tagged Problems FromASHISHNo ratings yet
- Unit 2Document60 pagesUnit 2Shashwat MishraNo ratings yet


































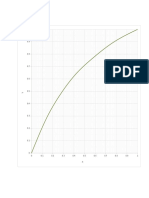




















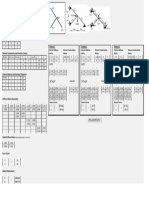
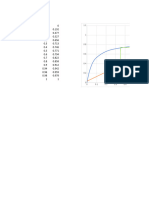







































Download as pdf or txt
You might also like
- 11.cluster Validation PDFDocument37 pages11.cluster Validation PDFTanmay KhandelwalNo ratings yet
- Cluster ValidationDocument47 pagesCluster ValidationZeeshan AliNo ratings yet
- Data Mining: Clustering Validation Minimum Description Length Information Theory Co-ClusteringDocument67 pagesData Mining: Clustering Validation Minimum Description Length Information Theory Co-ClusteringArul Kumar VenugopalNo ratings yet
- UntitledDocument1 pageUntitledPower LibraryNo ratings yet
- Example 1.1 Known Points Interpolated X ValueDocument2 pagesExample 1.1 Known Points Interpolated X ValueKendrick TanNo ratings yet
- Cluster Validation L25Document25 pagesCluster Validation L25Roy DeepNo ratings yet
- UjiDocument2 pagesUjiandikaNo ratings yet
- Desember 2022Document1 pageDesember 2022meiraNo ratings yet
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocument18 pages26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNo ratings yet
- Excel BezierDocument3 pagesExcel BezierNelly Sosa MartínezNo ratings yet
- Calculo De Momentos Mab= 17.78 Mbc= 90 Mba= -8.89 Mcb= -90 Calculo De Δ Kab= 4.00 Kcb= I= 12 Kbc= 2.00 Kcd= δBA= 0.67 δCB= δBC= 0.33 δCD=Document12 pagesCalculo De Momentos Mab= 17.78 Mbc= 90 Mba= -8.89 Mcb= -90 Calculo De Δ Kab= 4.00 Kcb= I= 12 Kbc= 2.00 Kcd= δBA= 0.67 δCB= δBC= 0.33 δCD=Jessica ChipanaNo ratings yet
- Validitas WFCDocument12 pagesValiditas WFCQueen Kuwera PrimaryNo ratings yet
- M. Abu Bakar SiddiqueDocument4 pagesM. Abu Bakar SiddiqueNasreen ClothNo ratings yet
- Waveand Wind RoseDocument6 pagesWaveand Wind RoseAldoNo ratings yet
- Machine Learning: An IntroductionDocument80 pagesMachine Learning: An IntroductionadminNo ratings yet
- ArmaduraDocument6 pagesArmaduraI.E. Manuel Scorza Torres - ccaccasiriNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- 5b - Word EmbeddingsDocument17 pages5b - Word EmbeddingsTalha darNo ratings yet
- LifestyleDocument18 pagesLifestyleShashwat JhaNo ratings yet
- Problemario MasmDocument9 pagesProblemario Masmmiguel angel salomon medrano (sammy)No ratings yet
- Count by 2s 5s 10s Girl LadderDocument2 pagesCount by 2s 5s 10s Girl LadderscribdaccountNo ratings yet
- Stat 890 Design of Computer ExperimentsDocument24 pagesStat 890 Design of Computer ExperimentsJoão MiguelNo ratings yet
- Graficos de EquilibrioDocument8 pagesGraficos de EquilibrioEvelyn PauyaNo ratings yet
- Static Moment Sse-Excel Section: The Author Will Not Be Responsible For Any Uses of This Software! v1.06Document1 pageStatic Moment Sse-Excel Section: The Author Will Not Be Responsible For Any Uses of This Software! v1.06SES DESIGNNo ratings yet
- Grafik Tugas LeachingDocument3 pagesGrafik Tugas LeachingChou ChouNo ratings yet
- Planilha Modelo ModeloDocument37 pagesPlanilha Modelo ModeloFernando WuNo ratings yet
- 1. Distribuci´on Binomial: ∼ Binom (n, θ)Document21 pages1. Distribuci´on Binomial: ∼ Binom (n, θ)Jimmy Santiago Soto AristizabalNo ratings yet
- Item AnalysisDocument1 pageItem AnalysisMarjorie MendozaNo ratings yet
- Tablas de DinamicaDocument3 pagesTablas de DinamicaDamian DNNo ratings yet
- Bending Moment and Shear Force Diagram - Cantilever Both Ends Sse-Excel SectionDocument1 pageBending Moment and Shear Force Diagram - Cantilever Both Ends Sse-Excel SectionSES DESIGNNo ratings yet
- 3 Curva Éxito ManualDocument1,925 pages3 Curva Éxito ManualFUNDACION GEOAMBIENTALNo ratings yet
- AEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanDocument2 pagesAEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- Statistics Impact v.1.3.5Document15 pagesStatistics Impact v.1.3.5Ashley Jade DomalantaNo ratings yet
- паучокDocument2 pagesпаучокolegtushchencoNo ratings yet
- Grafik Permas WordDocument14 pagesGrafik Permas Worddela ayu FitriaNo ratings yet
- HW 5Document2 pagesHW 5Edgar Perea LópezNo ratings yet
- ICT Test RatingDocument6 pagesICT Test RatingDayana ZhurmetovaNo ratings yet
- Tutorial SVR01Document73 pagesTutorial SVR01albaroNo ratings yet
- Sample Lab Report.1Document5 pagesSample Lab Report.1Maooz BalochNo ratings yet
- Yassir Fernandez P1Document10 pagesYassir Fernandez P1Yassir FernandezNo ratings yet
- Fenper TutoriaDocument2 pagesFenper TutoriaHudi NurwendiNo ratings yet
- Program 1:: Figure 1 Figure 2Document5 pagesProgram 1:: Figure 1 Figure 2TRUE LOVERSNo ratings yet
- Productpage 3098Document2 pagesProductpage 3098rahmat hidayatNo ratings yet
- Metode Selisih TengahDocument9 pagesMetode Selisih TengahFilda Nur AiniNo ratings yet
- 6 - Series de FourierDocument21 pages6 - Series de Fourieroliveira1305No ratings yet
- Subtracting Decimals in ColumnsDocument22 pagesSubtracting Decimals in ColumnsSaenno KwanNo ratings yet
- Stripper, Atfd 4, Ro (SBT), NT Preheater Daily ReportDocument9 pagesStripper, Atfd 4, Ro (SBT), NT Preheater Daily ReportPriyanshu NayakNo ratings yet
- Binomial y PoissonDocument6 pagesBinomial y Poissonkatherin cheguenNo ratings yet
- Dividing Decimals With Partial Quotients: Answer KeyDocument3 pagesDividing Decimals With Partial Quotients: Answer KeyMUHAMMAD ARIFFUDDIN BIN SUKIAT MoeNo ratings yet
- ENTROPIADocument11 pagesENTROPIALILIAM CAMILA DIOSA SILVANo ratings yet
- CHEGR 2650: Computer Methods in Chemical EngineeringDocument27 pagesCHEGR 2650: Computer Methods in Chemical EngineeringNebojsa MihajlovicNo ratings yet
- Empirical Data Analysis in Accounting and FinanceDocument48 pagesEmpirical Data Analysis in Accounting and FinanceRa'fat JalladNo ratings yet
- Graficas Laboratorio 3Document9 pagesGraficas Laboratorio 3Camilo SanchezNo ratings yet
- Week7 PDFDocument27 pagesWeek7 PDFosmanfıratNo ratings yet
- Statistics Project - Final DraftDocument10 pagesStatistics Project - Final DraftShaurya ParnamiNo ratings yet
- Stiffness MethodDocument1 pageStiffness MethodasluznetNo ratings yet
- Tray KolomDocument4 pagesTray KolomMuchamad Cahya FirdausNo ratings yet
- 24.autoencoder Based Galaxy Image Search - SukKimDocument29 pages24.autoencoder Based Galaxy Image Search - SukKimMuskan ChaudharyNo ratings yet
- Quiz-CORRELATION 1 and 2Document3 pagesQuiz-CORRELATION 1 and 2Aina De LeonNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Theorizing Community Resilience To Earthquakes: Scott B. MilesDocument11 pagesTheorizing Community Resilience To Earthquakes: Scott B. Milessetiono 90No ratings yet
- Structures: SciencedirectDocument10 pagesStructures: Sciencedirectsetiono 90No ratings yet
- International Journal of Disaster Risk Reduction: SciencedirectDocument11 pagesInternational Journal of Disaster Risk Reduction: Sciencedirectsetiono 90No ratings yet
- Lecture 013-Mamdani SugenoDocument72 pagesLecture 013-Mamdani Sugenosetiono 90No ratings yet
- Data Mining and Knowledge DiscoveryDocument32 pagesData Mining and Knowledge Discoverysetiono 90No ratings yet
- Fuzzy Lecture 011 - Mamdani SugenoDocument63 pagesFuzzy Lecture 011 - Mamdani Sugenosetiono 90No ratings yet
- Fuzzy Lecture05-Mamdani SugenoDocument51 pagesFuzzy Lecture05-Mamdani Sugenosetiono 90No ratings yet
- Artificial Intelligence ICS461 Fall 2010: Informed SearchesDocument14 pagesArtificial Intelligence ICS461 Fall 2010: Informed SearchesLawlietNo ratings yet
- Literature Review of Newspaper IndustryDocument10 pagesLiterature Review of Newspaper IndustryVikram Pratap SinghNo ratings yet
- Integer Linear Programming: Management ScienceDocument14 pagesInteger Linear Programming: Management ScienceAlrick BarwaNo ratings yet
- 06 Barreto, John Lloyd D.Document42 pages06 Barreto, John Lloyd D.Johnlloyd BarretoNo ratings yet
- Quantum Approximate Optimization Algorithm: Performance, Mechanism, and Implementation On Near-Term DevicesDocument23 pagesQuantum Approximate Optimization Algorithm: Performance, Mechanism, and Implementation On Near-Term DevicesSakibul Islam SazzadNo ratings yet
- Hackathon - SuridDocument6 pagesHackathon - SuridSamin AfnanNo ratings yet
- DAA Lesson PlanDocument5 pagesDAA Lesson Planrajshreed2014No ratings yet
- FALLSEM2018-19 - CSE1001 - LO - TT238 - VL2018191005495 - Reference Material I - Session 17-TuplesDocument29 pagesFALLSEM2018-19 - CSE1001 - LO - TT238 - VL2018191005495 - Reference Material I - Session 17-TuplesVhan DarshNo ratings yet
- Shortest PathDocument10 pagesShortest PathOporajitaNo ratings yet
- Introduction To Algorithms: Prof. Shafi Goldwasser Prof. Erik DemaineDocument54 pagesIntroduction To Algorithms: Prof. Shafi Goldwasser Prof. Erik Demaineprincipal lnbcNo ratings yet
- Part 3 - Building A Deep Q-Network To Play Gridworld - Learning Instability and Target Networks - by NandaKishore Joshi - Towards Data ScienceDocument7 pagesPart 3 - Building A Deep Q-Network To Play Gridworld - Learning Instability and Target Networks - by NandaKishore Joshi - Towards Data Science배영광No ratings yet
- 4x4 Gaussian ExampleDocument2 pages4x4 Gaussian ExamplerhiyaNo ratings yet
- Data Structures Using CDocument7 pagesData Structures Using CVikram RaoNo ratings yet
- Coin Change Problem Solution Using Dynamic ProgrammingDocument2 pagesCoin Change Problem Solution Using Dynamic Programmingstudy hubNo ratings yet
- Here Is A Pascal Program To Solve Small Problems Using The Simplex AlgorithmDocument12 pagesHere Is A Pascal Program To Solve Small Problems Using The Simplex AlgorithmRodolfo Sergio Cruz FuentesNo ratings yet
- Bytewise Computation of CRC Without Look Up TableDocument3 pagesBytewise Computation of CRC Without Look Up TableKalpana DasNo ratings yet
- Submissions S Itcs123 Bit16 Intermediate Programming Lec 2nd Sem 2022 2023 S Itcs123 Finals Summative Dlsu D College GsDocument9 pagesSubmissions S Itcs123 Bit16 Intermediate Programming Lec 2nd Sem 2022 2023 S Itcs123 Finals Summative Dlsu D College GsAdlei Jed TanNo ratings yet
- Chap7 Basic Cluster AnalysisDocument49 pagesChap7 Basic Cluster Analysisمحمد إحسنNo ratings yet
- List of Unsolved Problems in Computer ScienceDocument3 pagesList of Unsolved Problems in Computer ScienceRaghav SingalNo ratings yet
- Data StructureDocument25 pagesData StructureSamuel DavisNo ratings yet
- Neurocomputing: Bao-Di Liu, Bin Shen, Liangke Gui, Yu-Xiong Wang, Xue Li, Fei Yan, Yan-Jiang WangDocument13 pagesNeurocomputing: Bao-Di Liu, Bin Shen, Liangke Gui, Yu-Xiong Wang, Xue Li, Fei Yan, Yan-Jiang WangMeHaK KhAliDNo ratings yet
- Queue PPTDocument19 pagesQueue PPTharshvardhanshinde.2504No ratings yet
- What Is An Abstract Data Type?Document12 pagesWhat Is An Abstract Data Type?Syed FahadNo ratings yet
- Java Notes: 15.1 Learning OutcomesDocument9 pagesJava Notes: 15.1 Learning OutcomesKule AnthonyNo ratings yet
- FDS PresentationDocument17 pagesFDS PresentationIshaan MattooNo ratings yet
- 3 StacksDocument3 pages3 StacksShru SinghNo ratings yet
- 18cs32 - Data Structure and Its ApplicationDocument22 pages18cs32 - Data Structure and Its Applicationvenkatesh prasadNo ratings yet
- DAA Assignment-1Document15 pagesDAA Assignment-1Vignesh DevamullaNo ratings yet
- Must Save and Share: Tagged Problems FromDocument8 pagesMust Save and Share: Tagged Problems FromASHISHNo ratings yet
- Unit 2Document60 pagesUnit 2Shashwat MishraNo ratings yet