
PDC Assing 1
PDC Assing 1
You might also like
- RE10, RG8, RF8 SeriesDocument330 pagesRE10, RG8, RF8 Seriesanggie93% (58)
- Name:: Abdulhannan KhawajaDocument6 pagesName:: Abdulhannan KhawajaSAMAR BUTTNo ratings yet
- 2 Parallel Computer Memory ArchitecturesDocument26 pages2 Parallel Computer Memory Architecturesraja usama201No ratings yet
- WINSEM2022-23 CSE4001 ETH VL2022230503162 ReferenceMaterialI TueFeb1400 00 00IST2023 Module4DistributedSystemsLecture2Document27 pagesWINSEM2022-23 CSE4001 ETH VL2022230503162 ReferenceMaterialI TueFeb1400 00 00IST2023 Module4DistributedSystemsLecture2Naveed ShaikNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument33 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Technical Seminar Report On: "High Performance Computing"Document14 pagesTechnical Seminar Report On: "High Performance Computing"mit_thakkar_2No ratings yet
- CP4253 Map Unit IiDocument23 pagesCP4253 Map Unit IiNivi VNo ratings yet
- CS0051 - Module 01Document52 pagesCS0051 - Module 01Ron BayaniNo ratings yet
- Distributed Shared MemoryDocument20 pagesDistributed Shared MemoryAsemSalehNo ratings yet
- CS0051 - Module 01 - Subtopic 1Document27 pagesCS0051 - Module 01 - Subtopic 1ronbayani2000No ratings yet
- Message Passing Fundamentals: Reference: Http://foxtrot - Ncsa.uiuc - edu:8900/public/MPIDocument22 pagesMessage Passing Fundamentals: Reference: Http://foxtrot - Ncsa.uiuc - edu:8900/public/MPIlizzylee94No ratings yet
- Lecture 1 - Parallel and Distributed ComputingDocument25 pagesLecture 1 - Parallel and Distributed ComputingSibgha IsrarNo ratings yet
- Part 1 - Lecture 3 - Parallel Software-1Document45 pagesPart 1 - Lecture 3 - Parallel Software-1Ahmad AbbaNo ratings yet
- Distributed Shared Memory For Advanced OsDocument21 pagesDistributed Shared Memory For Advanced OsmjspinoNo ratings yet
- High Performance ComputingDocument17 pagesHigh Performance ComputingPranav BansalNo ratings yet
- Unit 1Document25 pagesUnit 1rishisharma4201No ratings yet
- CS526 3 Design of Parallel ProgramsDocument83 pagesCS526 3 Design of Parallel ProgramsanonymousNo ratings yet
- OperatingSystem IntroductionDocument24 pagesOperatingSystem IntroductionAdviNo ratings yet
- CCunit 1Document69 pagesCCunit 1aman kumarNo ratings yet
- System Models For Distributed and Cloud ComputingDocument15 pagesSystem Models For Distributed and Cloud ComputingSubrahmanyam SudiNo ratings yet
- Chapter1 DosDocument51 pagesChapter1 DosnimmapreetuNo ratings yet
- Distributed SharDistributed Shared Memoryed MemoryDocument52 pagesDistributed SharDistributed Shared Memoryed Memorythiagu1985No ratings yet
- Parallel and Distributed Computing Lecture#12Document19 pagesParallel and Distributed Computing Lecture#12Ihsan UllahNo ratings yet
- ACA Unit 4Document41 pagesACA Unit 4sushil@irdNo ratings yet
- Parallel ComputingDocument24 pagesParallel ComputingMUHAMMAD AYUBNo ratings yet
- Basics of Parallel Programming: Unit-1Document79 pagesBasics of Parallel Programming: Unit-1jai shree krishnaNo ratings yet
- Disclaimer: - in Preparation of These Slides, Materials Have Been Taken FromDocument33 pagesDisclaimer: - in Preparation of These Slides, Materials Have Been Taken FromZara ShabirNo ratings yet
- BCSE412L - Parallel Computing 01Document27 pagesBCSE412L - Parallel Computing 01aavsgptNo ratings yet
- CCunit 1Document57 pagesCCunit 1Manish RoyNo ratings yet
- Parallel and Distributed Computing Lecture#14Document17 pagesParallel and Distributed Computing Lecture#14Ihsan UllahNo ratings yet
- DoS - Unit 1Document57 pagesDoS - Unit 1John DoeNo ratings yet
- Infrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITDocument32 pagesInfrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITTanushree ShenviNo ratings yet
- Distributed Computing OverviewsDocument30 pagesDistributed Computing OverviewssharikNo ratings yet
- DOS LecturesDocument116 pagesDOS Lecturesankit.singh.47No ratings yet
- SystemModelsforDistributedandCloudComputing PDFDocument15 pagesSystemModelsforDistributedandCloudComputing PDFRavinderNo ratings yet
- Darshan Institute of Engineering & TechnologyDocument49 pagesDarshan Institute of Engineering & TechnologyDhrumil DancerNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- CICS 504 Computer OrganizationDocument35 pagesCICS 504 Computer OrganizationdollykaushalNo ratings yet
- Unit 1 NotesDocument31 pagesUnit 1 NotesRanjith SKNo ratings yet
- Memory in Multiprocessor SystemDocument52 pagesMemory in Multiprocessor SystemPriyanka MadaanNo ratings yet
- Unit 3-Explaining The Memory Management Logical and and Physical Data Flow DiagramsDocument38 pagesUnit 3-Explaining The Memory Management Logical and and Physical Data Flow DiagramsLeah RachaelNo ratings yet
- Lecture1 Introduction PDFDocument43 pagesLecture1 Introduction PDFDeepesh MeenaNo ratings yet
- Lecture 2Document19 pagesLecture 2HasnainNo ratings yet
- Lecture 1 Introduction To Distributed Systems - 034922Document6 pagesLecture 1 Introduction To Distributed Systems - 034922leonardkigen100No ratings yet
- Client/Server Computing: Operating Systems: Internals and Design Principles, 6/EDocument79 pagesClient/Server Computing: Operating Systems: Internals and Design Principles, 6/Enaumanahmed19No ratings yet
- Introduction To: Parallel DistributedDocument32 pagesIntroduction To: Parallel Distributedaliha ghaffarNo ratings yet
- Distributed SystemDocument26 pagesDistributed SystemSMARTELLIGENT100% (1)
- Parallel and Distributed ComputingDocument90 pagesParallel and Distributed ComputingWell WisherNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- Distributed CS571Document36 pagesDistributed CS571ajassuhail9No ratings yet
- Mpi CourseDocument202 pagesMpi CourseKiarie Jimmy NjugunahNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- Chapter2 - CLO1 The Architecture and Algorithm DesignDocument81 pagesChapter2 - CLO1 The Architecture and Algorithm DesignmelvynNo ratings yet
- Introduction-Multicore ProgrammingDocument3 pagesIntroduction-Multicore ProgrammingPrinco DeeNo ratings yet
- Lecture 5Document31 pagesLecture 5Mohsin AliNo ratings yet
- Instruction Level ParallelismDocument20 pagesInstruction Level ParallelismPhani KumarNo ratings yet
- HPC NoteDocument39 pagesHPC NoteAlaa AliNo ratings yet
- Symmetric Multiprocessing and MicrokernelDocument6 pagesSymmetric Multiprocessing and MicrokernelManoraj PannerselumNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- New Microsoft Office Excel WorksheetDocument12 pagesNew Microsoft Office Excel WorksheetRam Krishna AdhikariNo ratings yet
- Top Ten Questions About Land TrustsDocument17 pagesTop Ten Questions About Land TrustsRandy Hughes50% (2)
- 9-Pipes and Cisterns-06-01-2023Document18 pages9-Pipes and Cisterns-06-01-2023Srikar Prasad D 21BEC2075No ratings yet
- Project Report On Ulip & Mutual FundDocument55 pagesProject Report On Ulip & Mutual FundGovind BhakuniNo ratings yet
- The Effect of Social Media Influencer On Brand Image, Self-Concept, and Purchase IntentionDocument14 pagesThe Effect of Social Media Influencer On Brand Image, Self-Concept, and Purchase IntentionLiza NoraNo ratings yet
- School Enrollment System AbstractDocument3 pagesSchool Enrollment System AbstractsunnyNo ratings yet
- ISR4321-V/K9 Datasheet: Quick SpecsDocument6 pagesISR4321-V/K9 Datasheet: Quick SpecsDjibril FayeNo ratings yet
- Enfants-du-Mekong-Web-based-Application-System ResearchDocument58 pagesEnfants-du-Mekong-Web-based-Application-System ResearchRalp James TilosNo ratings yet
- PBL2 - PRJ9 / PLC - 1 (CPU 1212C DC/DC/DC) / Program Blocks: Main (OB1)Document1 pagePBL2 - PRJ9 / PLC - 1 (CPU 1212C DC/DC/DC) / Program Blocks: Main (OB1)Dat NguyenNo ratings yet
- XDeclaration of The Naturalization Act of JulyDocument2 pagesXDeclaration of The Naturalization Act of JulyMegan bergNo ratings yet
- Finalised GSM OverviewDocument33 pagesFinalised GSM OverviewishanrajdorNo ratings yet
- GenC Hiring - Student BrochureDocument5 pagesGenC Hiring - Student BrochureSweety QuotesNo ratings yet
- AACI Professional ServicesDocument7 pagesAACI Professional ServicesRandy CrohnNo ratings yet
- Pre-Image-Kit Release Notes R22Document7 pagesPre-Image-Kit Release Notes R22Abdelmadjid BouamamaNo ratings yet
- Astm f2164 PDFDocument5 pagesAstm f2164 PDFLuis J Villa Roel Bullon100% (1)
- FranchiseDocument4 pagesFranchiseAivan De LeonNo ratings yet
- Route 22 23 September 2023Document3 pagesRoute 22 23 September 2023api-523195650No ratings yet
- Irlr8726Pbf Irlu8726Pbf: ApplicationsDocument11 pagesIrlr8726Pbf Irlu8726Pbf: Applicationsselmir_9No ratings yet
- VxWorks - Real-Time Operating SystemDocument10 pagesVxWorks - Real-Time Operating SystemmukeshNo ratings yet
- Expert Witness DissertationDocument6 pagesExpert Witness DissertationPaySomeoneToWriteYourPaperUK100% (1)
- P-T-T Paths: (Type Text) (Type Text) (Type Text)Document8 pagesP-T-T Paths: (Type Text) (Type Text) (Type Text)Thirukumaran VenugopalNo ratings yet
- Solution Manual For Introduction To Electrodynamics 4 e 4thDocument17 pagesSolution Manual For Introduction To Electrodynamics 4 e 4thglaivefang2a8v67100% (22)
- MT..KPBF Series: Three Phase Bridge Power ModulesDocument7 pagesMT..KPBF Series: Three Phase Bridge Power ModulesEduardo SouzaNo ratings yet
- Individual Daily Log and Accomplishment Report: Enclosure No. 3 To Deped Order No. 011, S. 2020Document2 pagesIndividual Daily Log and Accomplishment Report: Enclosure No. 3 To Deped Order No. 011, S. 2020cristina maquintoNo ratings yet
- 6866587D12 - A TCR1000 Basic Service Manual - MR9.6Document78 pages6866587D12 - A TCR1000 Basic Service Manual - MR9.6rjmsantosNo ratings yet
- Holacracy - The New Management System: October 2016Document11 pagesHolacracy - The New Management System: October 2016Alejandro VilladaNo ratings yet
- An Order Constituting The Barangay Tourism Development Council of Barangay Puro, Aroroy, MasbateDocument2 pagesAn Order Constituting The Barangay Tourism Development Council of Barangay Puro, Aroroy, MasbateJohn Paul M. Morado0% (1)
- Web D Worksheet 3Document19 pagesWeb D Worksheet 3aditya polNo ratings yet
- DILRMP by Sharlin - EditedDocument10 pagesDILRMP by Sharlin - Edited18212 NEELESH CHANDRANo ratings yet
























































































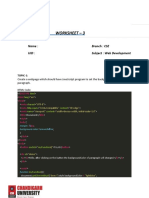

Download as txt, pdf, or txt
You might also like
- RE10, RG8, RF8 SeriesDocument330 pagesRE10, RG8, RF8 Seriesanggie93% (58)
- Name:: Abdulhannan KhawajaDocument6 pagesName:: Abdulhannan KhawajaSAMAR BUTTNo ratings yet
- 2 Parallel Computer Memory ArchitecturesDocument26 pages2 Parallel Computer Memory Architecturesraja usama201No ratings yet
- WINSEM2022-23 CSE4001 ETH VL2022230503162 ReferenceMaterialI TueFeb1400 00 00IST2023 Module4DistributedSystemsLecture2Document27 pagesWINSEM2022-23 CSE4001 ETH VL2022230503162 ReferenceMaterialI TueFeb1400 00 00IST2023 Module4DistributedSystemsLecture2Naveed ShaikNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument33 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Technical Seminar Report On: "High Performance Computing"Document14 pagesTechnical Seminar Report On: "High Performance Computing"mit_thakkar_2No ratings yet
- CP4253 Map Unit IiDocument23 pagesCP4253 Map Unit IiNivi VNo ratings yet
- CS0051 - Module 01Document52 pagesCS0051 - Module 01Ron BayaniNo ratings yet
- Distributed Shared MemoryDocument20 pagesDistributed Shared MemoryAsemSalehNo ratings yet
- CS0051 - Module 01 - Subtopic 1Document27 pagesCS0051 - Module 01 - Subtopic 1ronbayani2000No ratings yet
- Message Passing Fundamentals: Reference: Http://foxtrot - Ncsa.uiuc - edu:8900/public/MPIDocument22 pagesMessage Passing Fundamentals: Reference: Http://foxtrot - Ncsa.uiuc - edu:8900/public/MPIlizzylee94No ratings yet
- Lecture 1 - Parallel and Distributed ComputingDocument25 pagesLecture 1 - Parallel and Distributed ComputingSibgha IsrarNo ratings yet
- Part 1 - Lecture 3 - Parallel Software-1Document45 pagesPart 1 - Lecture 3 - Parallel Software-1Ahmad AbbaNo ratings yet
- Distributed Shared Memory For Advanced OsDocument21 pagesDistributed Shared Memory For Advanced OsmjspinoNo ratings yet
- High Performance ComputingDocument17 pagesHigh Performance ComputingPranav BansalNo ratings yet
- Unit 1Document25 pagesUnit 1rishisharma4201No ratings yet
- CS526 3 Design of Parallel ProgramsDocument83 pagesCS526 3 Design of Parallel ProgramsanonymousNo ratings yet
- OperatingSystem IntroductionDocument24 pagesOperatingSystem IntroductionAdviNo ratings yet
- CCunit 1Document69 pagesCCunit 1aman kumarNo ratings yet
- System Models For Distributed and Cloud ComputingDocument15 pagesSystem Models For Distributed and Cloud ComputingSubrahmanyam SudiNo ratings yet
- Chapter1 DosDocument51 pagesChapter1 DosnimmapreetuNo ratings yet
- Distributed SharDistributed Shared Memoryed MemoryDocument52 pagesDistributed SharDistributed Shared Memoryed Memorythiagu1985No ratings yet
- Parallel and Distributed Computing Lecture#12Document19 pagesParallel and Distributed Computing Lecture#12Ihsan UllahNo ratings yet
- ACA Unit 4Document41 pagesACA Unit 4sushil@irdNo ratings yet
- Parallel ComputingDocument24 pagesParallel ComputingMUHAMMAD AYUBNo ratings yet
- Basics of Parallel Programming: Unit-1Document79 pagesBasics of Parallel Programming: Unit-1jai shree krishnaNo ratings yet
- Disclaimer: - in Preparation of These Slides, Materials Have Been Taken FromDocument33 pagesDisclaimer: - in Preparation of These Slides, Materials Have Been Taken FromZara ShabirNo ratings yet
- BCSE412L - Parallel Computing 01Document27 pagesBCSE412L - Parallel Computing 01aavsgptNo ratings yet
- CCunit 1Document57 pagesCCunit 1Manish RoyNo ratings yet
- Parallel and Distributed Computing Lecture#14Document17 pagesParallel and Distributed Computing Lecture#14Ihsan UllahNo ratings yet
- DoS - Unit 1Document57 pagesDoS - Unit 1John DoeNo ratings yet
- Infrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITDocument32 pagesInfrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITTanushree ShenviNo ratings yet
- Distributed Computing OverviewsDocument30 pagesDistributed Computing OverviewssharikNo ratings yet
- DOS LecturesDocument116 pagesDOS Lecturesankit.singh.47No ratings yet
- SystemModelsforDistributedandCloudComputing PDFDocument15 pagesSystemModelsforDistributedandCloudComputing PDFRavinderNo ratings yet
- Darshan Institute of Engineering & TechnologyDocument49 pagesDarshan Institute of Engineering & TechnologyDhrumil DancerNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- CICS 504 Computer OrganizationDocument35 pagesCICS 504 Computer OrganizationdollykaushalNo ratings yet
- Unit 1 NotesDocument31 pagesUnit 1 NotesRanjith SKNo ratings yet
- Memory in Multiprocessor SystemDocument52 pagesMemory in Multiprocessor SystemPriyanka MadaanNo ratings yet
- Unit 3-Explaining The Memory Management Logical and and Physical Data Flow DiagramsDocument38 pagesUnit 3-Explaining The Memory Management Logical and and Physical Data Flow DiagramsLeah RachaelNo ratings yet
- Lecture1 Introduction PDFDocument43 pagesLecture1 Introduction PDFDeepesh MeenaNo ratings yet
- Lecture 2Document19 pagesLecture 2HasnainNo ratings yet
- Lecture 1 Introduction To Distributed Systems - 034922Document6 pagesLecture 1 Introduction To Distributed Systems - 034922leonardkigen100No ratings yet
- Client/Server Computing: Operating Systems: Internals and Design Principles, 6/EDocument79 pagesClient/Server Computing: Operating Systems: Internals and Design Principles, 6/Enaumanahmed19No ratings yet
- Introduction To: Parallel DistributedDocument32 pagesIntroduction To: Parallel Distributedaliha ghaffarNo ratings yet
- Distributed SystemDocument26 pagesDistributed SystemSMARTELLIGENT100% (1)
- Parallel and Distributed ComputingDocument90 pagesParallel and Distributed ComputingWell WisherNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- Distributed CS571Document36 pagesDistributed CS571ajassuhail9No ratings yet
- Mpi CourseDocument202 pagesMpi CourseKiarie Jimmy NjugunahNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- Chapter2 - CLO1 The Architecture and Algorithm DesignDocument81 pagesChapter2 - CLO1 The Architecture and Algorithm DesignmelvynNo ratings yet
- Introduction-Multicore ProgrammingDocument3 pagesIntroduction-Multicore ProgrammingPrinco DeeNo ratings yet
- Lecture 5Document31 pagesLecture 5Mohsin AliNo ratings yet
- Instruction Level ParallelismDocument20 pagesInstruction Level ParallelismPhani KumarNo ratings yet
- HPC NoteDocument39 pagesHPC NoteAlaa AliNo ratings yet
- Symmetric Multiprocessing and MicrokernelDocument6 pagesSymmetric Multiprocessing and MicrokernelManoraj PannerselumNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- New Microsoft Office Excel WorksheetDocument12 pagesNew Microsoft Office Excel WorksheetRam Krishna AdhikariNo ratings yet
- Top Ten Questions About Land TrustsDocument17 pagesTop Ten Questions About Land TrustsRandy Hughes50% (2)
- 9-Pipes and Cisterns-06-01-2023Document18 pages9-Pipes and Cisterns-06-01-2023Srikar Prasad D 21BEC2075No ratings yet
- Project Report On Ulip & Mutual FundDocument55 pagesProject Report On Ulip & Mutual FundGovind BhakuniNo ratings yet
- The Effect of Social Media Influencer On Brand Image, Self-Concept, and Purchase IntentionDocument14 pagesThe Effect of Social Media Influencer On Brand Image, Self-Concept, and Purchase IntentionLiza NoraNo ratings yet
- School Enrollment System AbstractDocument3 pagesSchool Enrollment System AbstractsunnyNo ratings yet
- ISR4321-V/K9 Datasheet: Quick SpecsDocument6 pagesISR4321-V/K9 Datasheet: Quick SpecsDjibril FayeNo ratings yet
- Enfants-du-Mekong-Web-based-Application-System ResearchDocument58 pagesEnfants-du-Mekong-Web-based-Application-System ResearchRalp James TilosNo ratings yet
- PBL2 - PRJ9 / PLC - 1 (CPU 1212C DC/DC/DC) / Program Blocks: Main (OB1)Document1 pagePBL2 - PRJ9 / PLC - 1 (CPU 1212C DC/DC/DC) / Program Blocks: Main (OB1)Dat NguyenNo ratings yet
- XDeclaration of The Naturalization Act of JulyDocument2 pagesXDeclaration of The Naturalization Act of JulyMegan bergNo ratings yet
- Finalised GSM OverviewDocument33 pagesFinalised GSM OverviewishanrajdorNo ratings yet
- GenC Hiring - Student BrochureDocument5 pagesGenC Hiring - Student BrochureSweety QuotesNo ratings yet
- AACI Professional ServicesDocument7 pagesAACI Professional ServicesRandy CrohnNo ratings yet
- Pre-Image-Kit Release Notes R22Document7 pagesPre-Image-Kit Release Notes R22Abdelmadjid BouamamaNo ratings yet
- Astm f2164 PDFDocument5 pagesAstm f2164 PDFLuis J Villa Roel Bullon100% (1)
- FranchiseDocument4 pagesFranchiseAivan De LeonNo ratings yet
- Route 22 23 September 2023Document3 pagesRoute 22 23 September 2023api-523195650No ratings yet
- Irlr8726Pbf Irlu8726Pbf: ApplicationsDocument11 pagesIrlr8726Pbf Irlu8726Pbf: Applicationsselmir_9No ratings yet
- VxWorks - Real-Time Operating SystemDocument10 pagesVxWorks - Real-Time Operating SystemmukeshNo ratings yet
- Expert Witness DissertationDocument6 pagesExpert Witness DissertationPaySomeoneToWriteYourPaperUK100% (1)
- P-T-T Paths: (Type Text) (Type Text) (Type Text)Document8 pagesP-T-T Paths: (Type Text) (Type Text) (Type Text)Thirukumaran VenugopalNo ratings yet
- Solution Manual For Introduction To Electrodynamics 4 e 4thDocument17 pagesSolution Manual For Introduction To Electrodynamics 4 e 4thglaivefang2a8v67100% (22)
- MT..KPBF Series: Three Phase Bridge Power ModulesDocument7 pagesMT..KPBF Series: Three Phase Bridge Power ModulesEduardo SouzaNo ratings yet
- Individual Daily Log and Accomplishment Report: Enclosure No. 3 To Deped Order No. 011, S. 2020Document2 pagesIndividual Daily Log and Accomplishment Report: Enclosure No. 3 To Deped Order No. 011, S. 2020cristina maquintoNo ratings yet
- 6866587D12 - A TCR1000 Basic Service Manual - MR9.6Document78 pages6866587D12 - A TCR1000 Basic Service Manual - MR9.6rjmsantosNo ratings yet
- Holacracy - The New Management System: October 2016Document11 pagesHolacracy - The New Management System: October 2016Alejandro VilladaNo ratings yet
- An Order Constituting The Barangay Tourism Development Council of Barangay Puro, Aroroy, MasbateDocument2 pagesAn Order Constituting The Barangay Tourism Development Council of Barangay Puro, Aroroy, MasbateJohn Paul M. Morado0% (1)
- Web D Worksheet 3Document19 pagesWeb D Worksheet 3aditya polNo ratings yet
- DILRMP by Sharlin - EditedDocument10 pagesDILRMP by Sharlin - Edited18212 NEELESH CHANDRANo ratings yet