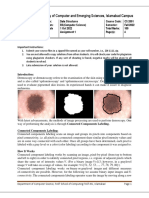
Download as pdf or txt
You might also like
- Goal 4Document7 pagesGoal 4NirmitNo ratings yet
- Coincent - Data Science With Python AssignmentDocument23 pagesCoincent - Data Science With Python AssignmentSai Nikhil Nellore100% (2)
- Chapter-5.PDF Charan LangtonDocument32 pagesChapter-5.PDF Charan Langtonumair rasheedNo ratings yet
- Signature Verification Entailing Principal Component Analysis As A Feature ExtractorDocument5 pagesSignature Verification Entailing Principal Component Analysis As A Feature Extractorscience2222No ratings yet
- Medical Image Processing - Detection of Cancer BrainDocument7 pagesMedical Image Processing - Detection of Cancer BrainIntegrated Intelligent ResearchNo ratings yet
- Ieee Conference Paper TemplateDocument4 pagesIeee Conference Paper TemplateMati ur rahman khanNo ratings yet
- Medical Image Processing Detection of Cancer BrainDocument6 pagesMedical Image Processing Detection of Cancer BrainijcnesNo ratings yet
- DSP ReportDocument6 pagesDSP Reportzunurainahmad173No ratings yet
- Events InfoDocument3 pagesEvents Info01fe22bca236No ratings yet
- Discriminant Analysis For Risk Classification and PredictionDocument23 pagesDiscriminant Analysis For Risk Classification and PredictionSumit SharmaNo ratings yet
- Table of ContentDocument7 pagesTable of ContentAmrutha reddy karumuruNo ratings yet
- Principal Components Analysis (PCA) FinalDocument23 pagesPrincipal Components Analysis (PCA) FinalendaleNo ratings yet
- Face Recognition Based On SVM and 2DPCADocument10 pagesFace Recognition Based On SVM and 2DPCAbmwliNo ratings yet
- Unit - IV - DIMENSIONALITY REDUCTION AND GRAPHICAL MODELSDocument59 pagesUnit - IV - DIMENSIONALITY REDUCTION AND GRAPHICAL MODELSIndumathy ParanthamanNo ratings yet
- Image Classification Using Backpropagation Neural Network Without Using Built-In FunctionDocument8 pagesImage Classification Using Backpropagation Neural Network Without Using Built-In FunctionMaisha MashiataNo ratings yet
- Real Time Face Recognition Based On Convolution Neural NetworkDocument4 pagesReal Time Face Recognition Based On Convolution Neural NetworkCNS CNSNo ratings yet
- A COMPLETE GUIDE TO PRINCIPAL COMPONENT ANALYSIS in ML 1598272724Document16 pagesA COMPLETE GUIDE TO PRINCIPAL COMPONENT ANALYSIS in ML 1598272724「瞳」你分享No ratings yet
- Rev Insurance Business ReportDocument4 pagesRev Insurance Business ReportPratigya pathakNo ratings yet
- Principal Component Analysis For Noise Reduction and Fraudulent Activity Detection in Scientific DataDocument10 pagesPrincipal Component Analysis For Noise Reduction and Fraudulent Activity Detection in Scientific DataDisant UpadhyayNo ratings yet
- ISOMAP in MLDocument12 pagesISOMAP in MLVishwa MuthukumarNo ratings yet
- 2003automatic Biometric Identification System by Hand GeometryDocument4 pages2003automatic Biometric Identification System by Hand GeometrySuchetana9No ratings yet
- Pveerina FinalDocument5 pagesPveerina FinalAbbyNo ratings yet
- Credit Card Fraud Detection 1Document38 pagesCredit Card Fraud Detection 1Thành Đạt NguyễnNo ratings yet
- AssignmentDocument24 pagesAssignmentSanthi PalanisamyNo ratings yet
- Principal Component AnalysisDocument13 pagesPrincipal Component AnalysisShil ShambharkarNo ratings yet
- Data Mining Problem 2 ReportDocument13 pagesData Mining Problem 2 ReportBabu ShaikhNo ratings yet
- Modelling and Error AnalysisDocument8 pagesModelling and Error AnalysisAtmuri GaneshNo ratings yet
- ISOMAPDocument11 pagesISOMAPVishwa Muthukumar100% (1)
- Samulski Classification07Document11 pagesSamulski Classification07Perry GrootNo ratings yet
- Chapter 2Document17 pagesChapter 2Đức Anh Lê NgọcNo ratings yet
- Face Recognition Using DSP: Ii. E ADocument6 pagesFace Recognition Using DSP: Ii. E ARenukaprasad SulakheNo ratings yet
- Ensemble U-Net Model For Efficient Polyp SegmentationDocument3 pagesEnsemble U-Net Model For Efficient Polyp SegmentationshrutiNo ratings yet
- Machine Learning Performance Evaluation ReportDocument40 pagesMachine Learning Performance Evaluation ReportPeace EmmanuelNo ratings yet
- Project Report: Optical Character Recognition Using Artificial Neural NetworkDocument9 pagesProject Report: Optical Character Recognition Using Artificial Neural NetworkRichard JamesNo ratings yet
- 2 Description of T He Proposed SystemDocument10 pages2 Description of T He Proposed SystemGautham ShettyNo ratings yet
- SCSA3015 Deep Learning Unit 3Document23 pagesSCSA3015 Deep Learning Unit 3pooja vikirthini100% (1)
- ML Model Paper 3 SolutionDocument22 pagesML Model Paper 3 SolutionRoger kujurNo ratings yet
- unit 4 part 2Document17 pagesunit 4 part 2Prince RathoreNo ratings yet
- Data Structures Assignment 1Document4 pagesData Structures Assignment 1Adil AzherNo ratings yet
- WQD7005 Final Exam - 17219402Document12 pagesWQD7005 Final Exam - 17219402AdamZain788100% (1)
- Emotion Classification On Face Images: Stanford UniversityDocument6 pagesEmotion Classification On Face Images: Stanford UniversityHarshit MogalapalliNo ratings yet
- Biometric Face RecognitionDocument21 pagesBiometric Face RecognitionLokindra DangiNo ratings yet
- MACHINE LEARNING WITH PYTHON - Digit Recognition With Scikit-Learn and MnistDocument11 pagesMACHINE LEARNING WITH PYTHON - Digit Recognition With Scikit-Learn and MnistalexandreNo ratings yet
- Multi Character RecognitionDocument19 pagesMulti Character RecognitionAnkit KumarNo ratings yet
- Sign Language Classification Using Webcam ImagesDocument4 pagesSign Language Classification Using Webcam ImagesAarav KumarNo ratings yet
- WQD7005 Final Exam - 17219402Document12 pagesWQD7005 Final Exam - 17219402AdamZain788No ratings yet
- Automatic Cephalometric Landmark Detection On X-Ray Images Using A Deep-Learning MethodDocument16 pagesAutomatic Cephalometric Landmark Detection On X-Ray Images Using A Deep-Learning MethodOussema GazzehNo ratings yet
- AI Unit-5Document53 pagesAI Unit-5Jyoti MishraNo ratings yet
- JTD3E - Group8 - Major Assigment Practicum ReportDocument10 pagesJTD3E - Group8 - Major Assigment Practicum ReportMikhail RachmanNo ratings yet
- Logistic Regression For Malignancy Prediction in Cancer - by Luca Zammataro - Towards Data ScienceDocument32 pagesLogistic Regression For Malignancy Prediction in Cancer - by Luca Zammataro - Towards Data ScienceGhifari RakaNo ratings yet
- Character Recognition Using Neural Networks: Rókus Arnold, Póth MiklósDocument4 pagesCharacter Recognition Using Neural Networks: Rókus Arnold, Póth MiklósSharath JagannathanNo ratings yet
- A Novel Approach For Content Retrieval From Recognition AlgorithmDocument5 pagesA Novel Approach For Content Retrieval From Recognition AlgorithmInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- An Explainable Model-Agnostic Algorithm For CNN-based Biometrics VerificationDocument6 pagesAn Explainable Model-Agnostic Algorithm For CNN-based Biometrics VerificationLuzNo ratings yet
- Article EdaDocument7 pagesArticle Edagunda pavanNo ratings yet
- TEAM DS Final ReportDocument14 pagesTEAM DS Final ReportGurucharan ReddyNo ratings yet
- Top 10 Machine Learning Algorithms With Their UseDocument12 pagesTop 10 Machine Learning Algorithms With Their Useirma komariahNo ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- Low Resolution Face Recognition Using Mixture of ExpertsDocument5 pagesLow Resolution Face Recognition Using Mixture of ExpertsTALLA_LOKESHNo ratings yet
- Mloa Exp2 C121Document20 pagesMloa Exp2 C121Devanshu MaheshwariNo ratings yet
- Identity and Gender Recognition Using The ENCARA Real-Time Face DetectorDocument4 pagesIdentity and Gender Recognition Using The ENCARA Real-Time Face DetectorNinet NabilNo ratings yet
- Understanding Principal Component PDFDocument10 pagesUnderstanding Principal Component PDFFrancisco Jácome SarmentoNo ratings yet
- Contextual Image Classification: Understanding Visual Data for Effective ClassificationFrom EverandContextual Image Classification: Understanding Visual Data for Effective ClassificationNo ratings yet
- Low-Dimensional Procedure For The Characterization of Human FacesDocument6 pagesLow-Dimensional Procedure For The Characterization of Human FacesKrishna KumarNo ratings yet
- On The Reverse Blocking Characteristics of Schottky Power DiodesDocument2 pagesOn The Reverse Blocking Characteristics of Schottky Power DiodesKrishna KumarNo ratings yet
- Face Recognition With Python: Philipp WagnerDocument16 pagesFace Recognition With Python: Philipp WagnerKrishna KumarNo ratings yet
- Sic Appli-EDocument89 pagesSic Appli-EKrishna KumarNo ratings yet
- Advances in Logic Device ScalingDocument9 pagesAdvances in Logic Device ScalingKrishna KumarNo ratings yet
- System Modeling and Characterization of Sic Schottky Power DiodesDocument6 pagesSystem Modeling and Characterization of Sic Schottky Power DiodesKrishna KumarNo ratings yet
- Sic Schottky Barrier Diodes: Semiconductor Storage ProductsDocument4 pagesSic Schottky Barrier Diodes: Semiconductor Storage ProductsKrishna KumarNo ratings yet
- Parameter Extraction Procedure For A Physics-Based Power Sic Schottky Diode ModelDocument11 pagesParameter Extraction Procedure For A Physics-Based Power Sic Schottky Diode ModelKrishna KumarNo ratings yet
- Silicon Power Schottky Diodes Model Implemented in SPICE: Jacek Dąbrowski, Janusz ZarębskiDocument4 pagesSilicon Power Schottky Diodes Model Implemented in SPICE: Jacek Dąbrowski, Janusz ZarębskiKrishna KumarNo ratings yet
- Modelling Power Schottky Diodes: ZarqbskiDocument4 pagesModelling Power Schottky Diodes: ZarqbskiKrishna KumarNo ratings yet
- Sic Schottky Power Diode Modelling in SpiceDocument4 pagesSic Schottky Power Diode Modelling in SpiceKrishna KumarNo ratings yet
- Tortuga Logic Detect and Prevent Security Vulnerabilities in Your Hardware Root of Trust 1Document15 pagesTortuga Logic Detect and Prevent Security Vulnerabilities in Your Hardware Root of Trust 1Krishna KumarNo ratings yet
- Extracting of Silicon Carbide Schottky Diode Model Parameters Using Lateral Optimization Method Including The Parallel ConductanceDocument5 pagesExtracting of Silicon Carbide Schottky Diode Model Parameters Using Lateral Optimization Method Including The Parallel ConductanceKrishna KumarNo ratings yet
- Al. (9), Though The Feature Here Is Less Pronounced. The: ReferencesDocument3 pagesAl. (9), Though The Feature Here Is Less Pronounced. The: ReferencesKrishna KumarNo ratings yet
- Security Verification of Secure Processor Architectures and SystemsDocument13 pagesSecurity Verification of Secure Processor Architectures and SystemsKrishna KumarNo ratings yet
- TVS Hardware Security Challenges and SolutionsDocument30 pagesTVS Hardware Security Challenges and SolutionsKrishna KumarNo ratings yet
- HSM Draft PDFDocument30 pagesHSM Draft PDFKrishna KumarNo ratings yet
- Hardware Security: From Concept To Application: Florent Bruguier, Pascal Benoit, and Lionel Torres Lilian BossuetDocument6 pagesHardware Security: From Concept To Application: Florent Bruguier, Pascal Benoit, and Lionel Torres Lilian BossuetKrishna KumarNo ratings yet
- Recent Topics On Hardware Security: Naofumi Homma Tohoku University/Riec, Japan Télécomparistech/Comelec/SenDocument35 pagesRecent Topics On Hardware Security: Naofumi Homma Tohoku University/Riec, Japan Télécomparistech/Comelec/SenKrishna KumarNo ratings yet
- Basics of Digital Filter DesignDocument24 pagesBasics of Digital Filter DesignKrishna KumarNo ratings yet
- Basics of DFTDocument31 pagesBasics of DFTKrishna KumarNo ratings yet
- Bracketing Method QuizDocument4 pagesBracketing Method QuizNOVIARYA SUKMANINGRUMNo ratings yet
- 25-Tap Differentiator Using Rectangular, Bartlett and Hamming Window EX - NO: DateDocument6 pages25-Tap Differentiator Using Rectangular, Bartlett and Hamming Window EX - NO: DateSaresh KumarNo ratings yet
- The Remainder and Factor TheoremsDocument13 pagesThe Remainder and Factor Theoremsapi-285179261No ratings yet
- Nonlinear Systems: Rooting-Finding ProblemDocument28 pagesNonlinear Systems: Rooting-Finding ProblemLam WongNo ratings yet
- Interview Question: Anagram Detection: Difficulty: EasyDocument4 pagesInterview Question: Anagram Detection: Difficulty: EasySourajitDuttaNo ratings yet
- 8.5 Recurrent Neural NetworksDocument5 pages8.5 Recurrent Neural NetworksRajaNo ratings yet
- Lab No 3Document27 pagesLab No 3Ali MohsinNo ratings yet
- Self Driving Car Challenge BrochureDocument4 pagesSelf Driving Car Challenge BrochureSolejayNo ratings yet
- Fall 2023-2024 IE 451 Homework 3 SolutionsDocument15 pagesFall 2023-2024 IE 451 Homework 3 SolutionsAbdullah BingaziNo ratings yet
- H ClusterDocument4 pagesH ClusterVisalakshi VenkatNo ratings yet
- Math 10 Module - Q2, WK 1 - 2Document4 pagesMath 10 Module - Q2, WK 1 - 2Reygie FabrigaNo ratings yet
- 2.5 Block Diagram AlgebraDocument28 pages2.5 Block Diagram AlgebraAklilu AyeleNo ratings yet
- Ex Lecture1Document2 pagesEx Lecture1AlNo ratings yet
- Assignment 3Document20 pagesAssignment 3mahek saliaNo ratings yet
- Diseño de Estructuras Metálicas: Profesor: M.Sc. Ing. Alfredo Manchego MezaDocument24 pagesDiseño de Estructuras Metálicas: Profesor: M.Sc. Ing. Alfredo Manchego MezaArturo Gutierrez CalderónNo ratings yet
- 1 s2.0 S1342937X2200123X MainDocument17 pages1 s2.0 S1342937X2200123X Mainandriyan yulikasariNo ratings yet
- DID PrincetonDocument38 pagesDID PrincetoningNo ratings yet
- ch08 2019 03 27Document45 pagesch08 2019 03 27RamaKrishna ErrojuNo ratings yet
- Integration by SubstitutionDocument10 pagesIntegration by SubstitutionmukondimmagodaNo ratings yet
- NMCP Unit 3Document4 pagesNMCP Unit 3Shashikant Prasad100% (1)
- Backtracking Branch BoundDocument38 pagesBacktracking Branch BoundAbhijit BodheNo ratings yet
- State Space To Transfer Function Examples PDFDocument2 pagesState Space To Transfer Function Examples PDFGerald AguilarNo ratings yet
- OpMan LPDocument11 pagesOpMan LPprincess_camarilloNo ratings yet
- Direct Hashing and Pruning (Park-Chen-Yu) Direct Hashing and PruningDocument3 pagesDirect Hashing and Pruning (Park-Chen-Yu) Direct Hashing and PruningJubaida SaimaNo ratings yet
- Linear Programming: The Graphical and Simplex MethodsDocument11 pagesLinear Programming: The Graphical and Simplex MethodsKristienalyn De AsisNo ratings yet
- 5th Sem Octave - DSP ManualDocument68 pages5th Sem Octave - DSP ManualKuldeep KarmaNo ratings yet
- IT5409 Ch7 Part1 Object Detection v2Document97 pagesIT5409 Ch7 Part1 Object Detection v2Bui Minh DucNo ratings yet
- Sample Questions For COMP-424 Final Exam: Doina PrecupDocument4 pagesSample Questions For COMP-424 Final Exam: Doina PrecupgomathyNo ratings yet