
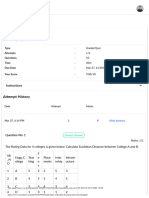
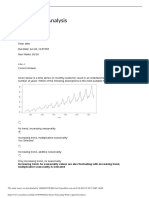
Quiz Week 8 - Unsupervised Learning Clustering
Quiz Week 8 - Unsupervised Learning Clustering
You might also like
- Ai FundaDocument354 pagesAi FundaLyn FloresNo ratings yet
- Low Code AIML USL Project CreditCardCustomerSegmentation Vijay Borade Aug23Document66 pagesLow Code AIML USL Project CreditCardCustomerSegmentation Vijay Borade Aug23borade.vijay50% (2)
- Azure AI Fundamentals (AI-900) Student WorkbookDocument92 pagesAzure AI Fundamentals (AI-900) Student WorkbookYash Kumar Singh Jha ae19b0160% (2)
- Weekly Quiz 1 Machine Learning Great Learning PDFDocument7 pagesWeekly Quiz 1 Machine Learning Great Learning PDFRobertKimtai100% (2)
- Easy Visa Project PDFDocument17 pagesEasy Visa Project PDFRobertKimtai100% (2)
- Time Series Forecasting Week 1 Quiz Part 2Document2 pagesTime Series Forecasting Week 1 Quiz Part 2ARCHANA R100% (2)
- Cargo Calculations On Tankers With ASTM Tables - Here Is All You Need To Know - MySeaTimeDocument52 pagesCargo Calculations On Tankers With ASTM Tables - Here Is All You Need To Know - MySeaTimecharu.hitechrobot2889No ratings yet
- Problem Statement 1Document17 pagesProblem Statement 1SHYAM VIVIN100% (1)
- Clustering Clean Ads - DataDocument1,657 pagesClustering Clean Ads - Dataaman gautam0% (1)
- Logistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1Document1 pageLogistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1AbhijitSinha0% (1)
- Asphalt Shingles Data Analysis PDFDocument4 pagesAsphalt Shingles Data Analysis PDFsonali PradhanNo ratings yet
- Project: Advanced Statistics: Anova, Eda and PcaDocument35 pagesProject: Advanced Statistics: Anova, Eda and PcaBhagyaSree JNo ratings yet
- Data Mining Project - 27.06.2021Document6 pagesData Mining Project - 27.06.2021vansh guptaNo ratings yet
- Step by Step Document For Simple BRM Rule Set - SAP BlogsDocument21 pagesStep by Step Document For Simple BRM Rule Set - SAP Blogscharu.hitechrobot2889No ratings yet
- Quartz 2020 Media Kit PDFDocument10 pagesQuartz 2020 Media Kit PDFJamil Diab100% (1)
- Logistic Regression Quiz SolvedDocument4 pagesLogistic Regression Quiz SolvedRohit Yadav100% (1)
- Week 1 Graded Quiz On Solution PDFDocument2 pagesWeek 1 Graded Quiz On Solution PDFlikhith krishnaNo ratings yet
- ML Assignemnt PDFDocument21 pagesML Assignemnt PDFEric NormanNo ratings yet
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 pagesDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (2)
- ML Quiz-2Document5 pagesML Quiz-2Saikat BhattacharyyaNo ratings yet
- SMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBADocument14 pagesSMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBASatish Kumar100% (1)
- Vidhya - SMDM ProjectDocument21 pagesVidhya - SMDM Projectvidyaramesh50% (2)
- Business Report: Predictive ModellingDocument37 pagesBusiness Report: Predictive Modellinghepzi selvam100% (1)
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- SMDM Project ReportDocument19 pagesSMDM Project ReportSANJAY ANANDAN100% (1)
- Business Report Project - Sheetal - SMDMDocument20 pagesBusiness Report Project - Sheetal - SMDMSheetal Mayanale100% (1)
- Random Forest - US - Heart - Patients - ClassDocument24 pagesRandom Forest - US - Heart - Patients - ClassShripad H100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- Pranjal - Singh - 27.11.2022 AS ProjectDocument9 pagesPranjal - Singh - 27.11.2022 AS ProjectPranjal SinghNo ratings yet
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Project Advanced Statistics UMESHHASIJA SEP2021 Jupyter FileDocument25 pagesProject Advanced Statistics UMESHHASIJA SEP2021 Jupyter Fileumesh hasijaNo ratings yet
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- Predictive Modelling Project Gloria Susan Raju 11 APR 2021 PDFDocument56 pagesPredictive Modelling Project Gloria Susan Raju 11 APR 2021 PDFpreetiNo ratings yet
- SMDM-Project Report (Madhur Dhananiwala)Document43 pagesSMDM-Project Report (Madhur Dhananiwala)madhur dhananiwala100% (1)
- Mini Project - Factor Hair Analysis: Sravanthi.MDocument24 pagesMini Project - Factor Hair Analysis: Sravanthi.MSweety Sekhar100% (1)
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Dbms db03 2020 Assessment (Solved) : Find Study ResourcesDocument12 pagesDbms db03 2020 Assessment (Solved) : Find Study ResourcesGupta Anacoolz50% (2)
- Pranjal - Singh - 30.10.2022 SMDM PROJECT REPORTDocument9 pagesPranjal - Singh - 30.10.2022 SMDM PROJECT REPORTPranjal SinghNo ratings yet
- KADIYALA SRIBALAJI RAM - 02-Apr-2021 (Business Report)Document13 pagesKADIYALA SRIBALAJI RAM - 02-Apr-2021 (Business Report)Sri Balaji RamNo ratings yet
- State Wise Health Income Clustering 18th December 2021 PDFDocument29 pagesState Wise Health Income Clustering 18th December 2021 PDFAnkita Mishra100% (1)
- Data Mining Project PCA ReportDocument27 pagesData Mining Project PCA Reportcrispin anthony100% (1)
- Business Report Data MiningDocument29 pagesBusiness Report Data Mininghepzi selvamNo ratings yet
- Advanced Statistics Project - Jayant ChandraDocument20 pagesAdvanced Statistics Project - Jayant Chandrajayant chandraNo ratings yet
- Arnab Chowdhury As1Document12 pagesArnab Chowdhury As1ARNAB CHOWDHURY.No ratings yet
- QUIZ Week 2 CART Practice PDFDocument10 pagesQUIZ Week 2 CART Practice PDFNagarajan ThandayuthamNo ratings yet
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Advanced Statistics: Business Report Ranvijay SharmaDocument16 pagesAdvanced Statistics: Business Report Ranvijay Sharmasandeep_genialNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- AV Project Shivakumar VangaDocument37 pagesAV Project Shivakumar VangaVanga Shiva100% (1)
- Predictive Modelling ProjectDocument29 pagesPredictive Modelling ProjectPranjal SinghNo ratings yet
- Graded Project ASDocument14 pagesGraded Project ASJimmi PranamiNo ratings yet
- Assignment Report - Advanced StatisticsDocument12 pagesAssignment Report - Advanced StatisticsRahulNo ratings yet
- Pranjal - Singh - 25.12.2022 - Data Mining ProjectDocument8 pagesPranjal - Singh - 25.12.2022 - Data Mining ProjectPranjal SinghNo ratings yet
- SMDM Project: Submitted By: Tina DasDocument15 pagesSMDM Project: Submitted By: Tina DasTina100% (1)
- DSBA SMDM Project - AnulaDocument7 pagesDSBA SMDM Project - AnulaAnula Bramhanand100% (1)
- Assignment 1Document7 pagesAssignment 1Being Indian100% (1)
- Advance Statistics-Project ReportDocument17 pagesAdvance Statistics-Project ReportJimmi Pranami50% (2)
- Machine Learning Project - HTML PDFDocument72 pagesMachine Learning Project - HTML PDFRaveena100% (3)
- PROJECT Advanced StatisticsDocument58 pagesPROJECT Advanced StatisticsBhagyaSree JNo ratings yet
- VARUNSAINI - 11 Dec 2022Document16 pagesVARUNSAINI - 11 Dec 2022Varun SainiNo ratings yet
- Detail Project Report SMDMDocument25 pagesDetail Project Report SMDMDeepak Padiyar100% (1)
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- Data Mining - ProjectDocument11 pagesData Mining - Projectankitbhagat100% (2)
- AS Project ReportDocument22 pagesAS Project ReportLohitha PakalapatiNo ratings yet
- Simplified Optimal Parenthesization Scheme For Matrix Chain Multiplication Problem Using Bottom-Up Practice in 2-Tree StructureDocument6 pagesSimplified Optimal Parenthesization Scheme For Matrix Chain Multiplication Problem Using Bottom-Up Practice in 2-Tree StructureLucian PalieviciNo ratings yet
- YozologDocument6 pagesYozologcharu.hitechrobot2889No ratings yet
- Ogsd en PDFDocument346 pagesOgsd en PDFcharu.hitechrobot2889No ratings yet
- Consumer Behavior-Certificate 24949Document1 pageConsumer Behavior-Certificate 24949charu.hitechrobot2889No ratings yet
- BCS 3.0 Calculation Issue Questionnaire 2018-02Document19 pagesBCS 3.0 Calculation Issue Questionnaire 2018-02charu.hitechrobot2889No ratings yet
- Infosys-Broadcom E2E Continuous Testing Platform Business Process Automation SolutionDocument16 pagesInfosys-Broadcom E2E Continuous Testing Platform Business Process Automation Solutioncharu.hitechrobot2889No ratings yet
- XII. Support Vector MachinesDocument6 pagesXII. Support Vector Machinescharu.hitechrobot2889No ratings yet
- Home SAP Development ABAP Statements Help Docs SAP Tables S4Hana Tables T-Code List FM'sDocument4 pagesHome SAP Development ABAP Statements Help Docs SAP Tables S4Hana Tables T-Code List FM'scharu.hitechrobot2889No ratings yet
- Quiz Week 7 - Support Vector MachinesDocument3 pagesQuiz Week 7 - Support Vector Machinescharu.hitechrobot2889100% (1)
- Helloviewmodel: Namespace Class Public String Get Return Public String Get Set Public String Get SetDocument10 pagesHelloviewmodel: Namespace Class Public String Get Return Public String Get Set Public String Get Setcharu.hitechrobot2889No ratings yet
- BRFplus - A Hidden Gem Within Your SAP System - XpertMINDSDocument7 pagesBRFplus - A Hidden Gem Within Your SAP System - XpertMINDScharu.hitechrobot2889No ratings yet
- BRF Plus-A Real Time Example - SAP BlogsDocument20 pagesBRF Plus-A Real Time Example - SAP Blogscharu.hitechrobot2889No ratings yet
- Service RecoveryDocument7 pagesService Recoverycharu.hitechrobot2889No ratings yet
- Blue Grey Internet Digital Technology History PresentationDocument1 pageBlue Grey Internet Digital Technology History Presentationcharu.hitechrobot2889No ratings yet
- Abap Internal TablesDocument10 pagesAbap Internal Tablescharu.hitechrobot2889No ratings yet
- First Name Last Name Age Gender Email Phone NumberDocument1 pageFirst Name Last Name Age Gender Email Phone Numbercharu.hitechrobot2889No ratings yet
- Classification Using Decision Tree: CSE-454: Data Warehousing and Data Mining SessionalDocument23 pagesClassification Using Decision Tree: CSE-454: Data Warehousing and Data Mining SessionalAsif AnowarNo ratings yet
- Music Genre RecognitionDocument5 pagesMusic Genre RecognitionJibin Rajan VargheseNo ratings yet
- Jyotish Aur Hum-O.KDocument29 pagesJyotish Aur Hum-O.KKALSHUBHNo ratings yet
- 01.query-By-Example On-Device Keyword SpottingDocument7 pages01.query-By-Example On-Device Keyword SpottingHoàng PhạmNo ratings yet
- Zhao Adaptation Topics 2022Document33 pagesZhao Adaptation Topics 2022pecataasenovNo ratings yet
- Yeah1 Group Presentation OriginalDocument46 pagesYeah1 Group Presentation OriginalphuNo ratings yet
- OBIEE Vs OAS Key Differences Features and BenefitsDocument10 pagesOBIEE Vs OAS Key Differences Features and Benefitsquintas omondiNo ratings yet
- WEF BookDocument78 pagesWEF BookZerohedge100% (1)
- Large Language ModelDocument38 pagesLarge Language Model21020641No ratings yet
- AI MarketingDocument2 pagesAI MarketingsusgheelNo ratings yet
- Ai Final PaperDocument13 pagesAi Final Paperapi-563773782No ratings yet
- Towards Effective Governance of Foundation Models and Generative AIDocument57 pagesTowards Effective Governance of Foundation Models and Generative AILeslie GordilloNo ratings yet
- Only AIDocument6 pagesOnly AIThiyaga RajanNo ratings yet
- Curriculum Management SystemDocument81 pagesCurriculum Management SystemLynyakat TañonNo ratings yet
- 25112-Article Text-29175-1-2-20230626Document9 pages25112-Article Text-29175-1-2-20230626Muhammad WahajNo ratings yet
- Solving Edge Computing Infrastructure Challenges: White Paper 277Document12 pagesSolving Edge Computing Infrastructure Challenges: White Paper 277Yashveer TakooryNo ratings yet
- Biologically Inspired Cognitive Architectures 2019: Alexei V. Samsonovich EditorDocument636 pagesBiologically Inspired Cognitive Architectures 2019: Alexei V. Samsonovich EditorSchifosita Pusheena BlackNo ratings yet
- Unity For Mobile Games: Solution GuideDocument9 pagesUnity For Mobile Games: Solution GuideAlexaNo ratings yet
- ENGLISH 9 - Lesson 9Document29 pagesENGLISH 9 - Lesson 9Prince Kim SubolNo ratings yet
- Gen AI - V2 - 2Document4 pagesGen AI - V2 - 2VintiNo ratings yet
- Computer Fundamentals Tutorial PDFDocument27 pagesComputer Fundamentals Tutorial PDFJP Abando75% (4)
- The Ethics of Artificial IntelligenceDocument2 pagesThe Ethics of Artificial Intelligencedragon knightNo ratings yet
- A Data Language That Understands Your Grid.: Data Engineering To Make Answers SimpleDocument9 pagesA Data Language That Understands Your Grid.: Data Engineering To Make Answers SimpleNAVDEEPNo ratings yet
- Resume 2019Document2 pagesResume 2019Mihir Kumar MechNo ratings yet
- Nptel: NOC:Introduction To Data Analytics - Video CourseDocument2 pagesNptel: NOC:Introduction To Data Analytics - Video CourseKanhaNo ratings yet
- Fuzzy Diagnostic System For Railway BridgesDocument6 pagesFuzzy Diagnostic System For Railway BridgesMahmoud SamiNo ratings yet
- English EssayDocument1 pageEnglish EssayBrian TrujilloNo ratings yet





































































































Download as pdf or txt
You might also like
- Ai FundaDocument354 pagesAi FundaLyn FloresNo ratings yet
- Low Code AIML USL Project CreditCardCustomerSegmentation Vijay Borade Aug23Document66 pagesLow Code AIML USL Project CreditCardCustomerSegmentation Vijay Borade Aug23borade.vijay50% (2)
- Azure AI Fundamentals (AI-900) Student WorkbookDocument92 pagesAzure AI Fundamentals (AI-900) Student WorkbookYash Kumar Singh Jha ae19b0160% (2)
- Weekly Quiz 1 Machine Learning Great Learning PDFDocument7 pagesWeekly Quiz 1 Machine Learning Great Learning PDFRobertKimtai100% (2)
- Easy Visa Project PDFDocument17 pagesEasy Visa Project PDFRobertKimtai100% (2)
- Time Series Forecasting Week 1 Quiz Part 2Document2 pagesTime Series Forecasting Week 1 Quiz Part 2ARCHANA R100% (2)
- Cargo Calculations On Tankers With ASTM Tables - Here Is All You Need To Know - MySeaTimeDocument52 pagesCargo Calculations On Tankers With ASTM Tables - Here Is All You Need To Know - MySeaTimecharu.hitechrobot2889No ratings yet
- Problem Statement 1Document17 pagesProblem Statement 1SHYAM VIVIN100% (1)
- Clustering Clean Ads - DataDocument1,657 pagesClustering Clean Ads - Dataaman gautam0% (1)
- Logistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1Document1 pageLogistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1AbhijitSinha0% (1)
- Asphalt Shingles Data Analysis PDFDocument4 pagesAsphalt Shingles Data Analysis PDFsonali PradhanNo ratings yet
- Project: Advanced Statistics: Anova, Eda and PcaDocument35 pagesProject: Advanced Statistics: Anova, Eda and PcaBhagyaSree JNo ratings yet
- Data Mining Project - 27.06.2021Document6 pagesData Mining Project - 27.06.2021vansh guptaNo ratings yet
- Step by Step Document For Simple BRM Rule Set - SAP BlogsDocument21 pagesStep by Step Document For Simple BRM Rule Set - SAP Blogscharu.hitechrobot2889No ratings yet
- Quartz 2020 Media Kit PDFDocument10 pagesQuartz 2020 Media Kit PDFJamil Diab100% (1)
- Logistic Regression Quiz SolvedDocument4 pagesLogistic Regression Quiz SolvedRohit Yadav100% (1)
- Week 1 Graded Quiz On Solution PDFDocument2 pagesWeek 1 Graded Quiz On Solution PDFlikhith krishnaNo ratings yet
- ML Assignemnt PDFDocument21 pagesML Assignemnt PDFEric NormanNo ratings yet
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 pagesDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (2)
- ML Quiz-2Document5 pagesML Quiz-2Saikat BhattacharyyaNo ratings yet
- SMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBADocument14 pagesSMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBASatish Kumar100% (1)
- Vidhya - SMDM ProjectDocument21 pagesVidhya - SMDM Projectvidyaramesh50% (2)
- Business Report: Predictive ModellingDocument37 pagesBusiness Report: Predictive Modellinghepzi selvam100% (1)
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- SMDM Project ReportDocument19 pagesSMDM Project ReportSANJAY ANANDAN100% (1)
- Business Report Project - Sheetal - SMDMDocument20 pagesBusiness Report Project - Sheetal - SMDMSheetal Mayanale100% (1)
- Random Forest - US - Heart - Patients - ClassDocument24 pagesRandom Forest - US - Heart - Patients - ClassShripad H100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- Pranjal - Singh - 27.11.2022 AS ProjectDocument9 pagesPranjal - Singh - 27.11.2022 AS ProjectPranjal SinghNo ratings yet
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Project Advanced Statistics UMESHHASIJA SEP2021 Jupyter FileDocument25 pagesProject Advanced Statistics UMESHHASIJA SEP2021 Jupyter Fileumesh hasijaNo ratings yet
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- Predictive Modelling Project Gloria Susan Raju 11 APR 2021 PDFDocument56 pagesPredictive Modelling Project Gloria Susan Raju 11 APR 2021 PDFpreetiNo ratings yet
- SMDM-Project Report (Madhur Dhananiwala)Document43 pagesSMDM-Project Report (Madhur Dhananiwala)madhur dhananiwala100% (1)
- Mini Project - Factor Hair Analysis: Sravanthi.MDocument24 pagesMini Project - Factor Hair Analysis: Sravanthi.MSweety Sekhar100% (1)
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Dbms db03 2020 Assessment (Solved) : Find Study ResourcesDocument12 pagesDbms db03 2020 Assessment (Solved) : Find Study ResourcesGupta Anacoolz50% (2)
- Pranjal - Singh - 30.10.2022 SMDM PROJECT REPORTDocument9 pagesPranjal - Singh - 30.10.2022 SMDM PROJECT REPORTPranjal SinghNo ratings yet
- KADIYALA SRIBALAJI RAM - 02-Apr-2021 (Business Report)Document13 pagesKADIYALA SRIBALAJI RAM - 02-Apr-2021 (Business Report)Sri Balaji RamNo ratings yet
- State Wise Health Income Clustering 18th December 2021 PDFDocument29 pagesState Wise Health Income Clustering 18th December 2021 PDFAnkita Mishra100% (1)
- Data Mining Project PCA ReportDocument27 pagesData Mining Project PCA Reportcrispin anthony100% (1)
- Business Report Data MiningDocument29 pagesBusiness Report Data Mininghepzi selvamNo ratings yet
- Advanced Statistics Project - Jayant ChandraDocument20 pagesAdvanced Statistics Project - Jayant Chandrajayant chandraNo ratings yet
- Arnab Chowdhury As1Document12 pagesArnab Chowdhury As1ARNAB CHOWDHURY.No ratings yet
- QUIZ Week 2 CART Practice PDFDocument10 pagesQUIZ Week 2 CART Practice PDFNagarajan ThandayuthamNo ratings yet
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Advanced Statistics: Business Report Ranvijay SharmaDocument16 pagesAdvanced Statistics: Business Report Ranvijay Sharmasandeep_genialNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- AV Project Shivakumar VangaDocument37 pagesAV Project Shivakumar VangaVanga Shiva100% (1)
- Predictive Modelling ProjectDocument29 pagesPredictive Modelling ProjectPranjal SinghNo ratings yet
- Graded Project ASDocument14 pagesGraded Project ASJimmi PranamiNo ratings yet
- Assignment Report - Advanced StatisticsDocument12 pagesAssignment Report - Advanced StatisticsRahulNo ratings yet
- Pranjal - Singh - 25.12.2022 - Data Mining ProjectDocument8 pagesPranjal - Singh - 25.12.2022 - Data Mining ProjectPranjal SinghNo ratings yet
- SMDM Project: Submitted By: Tina DasDocument15 pagesSMDM Project: Submitted By: Tina DasTina100% (1)
- DSBA SMDM Project - AnulaDocument7 pagesDSBA SMDM Project - AnulaAnula Bramhanand100% (1)
- Assignment 1Document7 pagesAssignment 1Being Indian100% (1)
- Advance Statistics-Project ReportDocument17 pagesAdvance Statistics-Project ReportJimmi Pranami50% (2)
- Machine Learning Project - HTML PDFDocument72 pagesMachine Learning Project - HTML PDFRaveena100% (3)
- PROJECT Advanced StatisticsDocument58 pagesPROJECT Advanced StatisticsBhagyaSree JNo ratings yet
- VARUNSAINI - 11 Dec 2022Document16 pagesVARUNSAINI - 11 Dec 2022Varun SainiNo ratings yet
- Detail Project Report SMDMDocument25 pagesDetail Project Report SMDMDeepak Padiyar100% (1)
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- Data Mining - ProjectDocument11 pagesData Mining - Projectankitbhagat100% (2)
- AS Project ReportDocument22 pagesAS Project ReportLohitha PakalapatiNo ratings yet
- Simplified Optimal Parenthesization Scheme For Matrix Chain Multiplication Problem Using Bottom-Up Practice in 2-Tree StructureDocument6 pagesSimplified Optimal Parenthesization Scheme For Matrix Chain Multiplication Problem Using Bottom-Up Practice in 2-Tree StructureLucian PalieviciNo ratings yet
- YozologDocument6 pagesYozologcharu.hitechrobot2889No ratings yet
- Ogsd en PDFDocument346 pagesOgsd en PDFcharu.hitechrobot2889No ratings yet
- Consumer Behavior-Certificate 24949Document1 pageConsumer Behavior-Certificate 24949charu.hitechrobot2889No ratings yet
- BCS 3.0 Calculation Issue Questionnaire 2018-02Document19 pagesBCS 3.0 Calculation Issue Questionnaire 2018-02charu.hitechrobot2889No ratings yet
- Infosys-Broadcom E2E Continuous Testing Platform Business Process Automation SolutionDocument16 pagesInfosys-Broadcom E2E Continuous Testing Platform Business Process Automation Solutioncharu.hitechrobot2889No ratings yet
- XII. Support Vector MachinesDocument6 pagesXII. Support Vector Machinescharu.hitechrobot2889No ratings yet
- Home SAP Development ABAP Statements Help Docs SAP Tables S4Hana Tables T-Code List FM'sDocument4 pagesHome SAP Development ABAP Statements Help Docs SAP Tables S4Hana Tables T-Code List FM'scharu.hitechrobot2889No ratings yet
- Quiz Week 7 - Support Vector MachinesDocument3 pagesQuiz Week 7 - Support Vector Machinescharu.hitechrobot2889100% (1)
- Helloviewmodel: Namespace Class Public String Get Return Public String Get Set Public String Get SetDocument10 pagesHelloviewmodel: Namespace Class Public String Get Return Public String Get Set Public String Get Setcharu.hitechrobot2889No ratings yet
- BRFplus - A Hidden Gem Within Your SAP System - XpertMINDSDocument7 pagesBRFplus - A Hidden Gem Within Your SAP System - XpertMINDScharu.hitechrobot2889No ratings yet
- BRF Plus-A Real Time Example - SAP BlogsDocument20 pagesBRF Plus-A Real Time Example - SAP Blogscharu.hitechrobot2889No ratings yet
- Service RecoveryDocument7 pagesService Recoverycharu.hitechrobot2889No ratings yet
- Blue Grey Internet Digital Technology History PresentationDocument1 pageBlue Grey Internet Digital Technology History Presentationcharu.hitechrobot2889No ratings yet
- Abap Internal TablesDocument10 pagesAbap Internal Tablescharu.hitechrobot2889No ratings yet
- First Name Last Name Age Gender Email Phone NumberDocument1 pageFirst Name Last Name Age Gender Email Phone Numbercharu.hitechrobot2889No ratings yet
- Classification Using Decision Tree: CSE-454: Data Warehousing and Data Mining SessionalDocument23 pagesClassification Using Decision Tree: CSE-454: Data Warehousing and Data Mining SessionalAsif AnowarNo ratings yet
- Music Genre RecognitionDocument5 pagesMusic Genre RecognitionJibin Rajan VargheseNo ratings yet
- Jyotish Aur Hum-O.KDocument29 pagesJyotish Aur Hum-O.KKALSHUBHNo ratings yet
- 01.query-By-Example On-Device Keyword SpottingDocument7 pages01.query-By-Example On-Device Keyword SpottingHoàng PhạmNo ratings yet
- Zhao Adaptation Topics 2022Document33 pagesZhao Adaptation Topics 2022pecataasenovNo ratings yet
- Yeah1 Group Presentation OriginalDocument46 pagesYeah1 Group Presentation OriginalphuNo ratings yet
- OBIEE Vs OAS Key Differences Features and BenefitsDocument10 pagesOBIEE Vs OAS Key Differences Features and Benefitsquintas omondiNo ratings yet
- WEF BookDocument78 pagesWEF BookZerohedge100% (1)
- Large Language ModelDocument38 pagesLarge Language Model21020641No ratings yet
- AI MarketingDocument2 pagesAI MarketingsusgheelNo ratings yet
- Ai Final PaperDocument13 pagesAi Final Paperapi-563773782No ratings yet
- Towards Effective Governance of Foundation Models and Generative AIDocument57 pagesTowards Effective Governance of Foundation Models and Generative AILeslie GordilloNo ratings yet
- Only AIDocument6 pagesOnly AIThiyaga RajanNo ratings yet
- Curriculum Management SystemDocument81 pagesCurriculum Management SystemLynyakat TañonNo ratings yet
- 25112-Article Text-29175-1-2-20230626Document9 pages25112-Article Text-29175-1-2-20230626Muhammad WahajNo ratings yet
- Solving Edge Computing Infrastructure Challenges: White Paper 277Document12 pagesSolving Edge Computing Infrastructure Challenges: White Paper 277Yashveer TakooryNo ratings yet
- Biologically Inspired Cognitive Architectures 2019: Alexei V. Samsonovich EditorDocument636 pagesBiologically Inspired Cognitive Architectures 2019: Alexei V. Samsonovich EditorSchifosita Pusheena BlackNo ratings yet
- Unity For Mobile Games: Solution GuideDocument9 pagesUnity For Mobile Games: Solution GuideAlexaNo ratings yet
- ENGLISH 9 - Lesson 9Document29 pagesENGLISH 9 - Lesson 9Prince Kim SubolNo ratings yet
- Gen AI - V2 - 2Document4 pagesGen AI - V2 - 2VintiNo ratings yet
- Computer Fundamentals Tutorial PDFDocument27 pagesComputer Fundamentals Tutorial PDFJP Abando75% (4)
- The Ethics of Artificial IntelligenceDocument2 pagesThe Ethics of Artificial Intelligencedragon knightNo ratings yet
- A Data Language That Understands Your Grid.: Data Engineering To Make Answers SimpleDocument9 pagesA Data Language That Understands Your Grid.: Data Engineering To Make Answers SimpleNAVDEEPNo ratings yet
- Resume 2019Document2 pagesResume 2019Mihir Kumar MechNo ratings yet
- Nptel: NOC:Introduction To Data Analytics - Video CourseDocument2 pagesNptel: NOC:Introduction To Data Analytics - Video CourseKanhaNo ratings yet
- Fuzzy Diagnostic System For Railway BridgesDocument6 pagesFuzzy Diagnostic System For Railway BridgesMahmoud SamiNo ratings yet
- English EssayDocument1 pageEnglish EssayBrian TrujilloNo ratings yet