
Experiment No.:1: Program
Experiment No.:1: Program
You might also like
- TRM-CH 5 Frappy RubricDocument3 pagesTRM-CH 5 Frappy Rubricapi-2619568050% (1)
- Appendix PDFDocument5 pagesAppendix PDFRamaNo ratings yet
- Data Science ManualDocument16 pagesData Science ManualKRISHNAVENI RNo ratings yet
- Big Data MergedDocument7 pagesBig Data MergedIngame IdNo ratings yet
- MLDocument2 pagesMLwovova9230No ratings yet
- Cancer Disease ClassificationDocument6 pagesCancer Disease ClassificationBARATH PNo ratings yet
- ML 1-10Document53 pagesML 1-1022128008No ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Import Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadDocument20 pagesImport Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadSaloni TuliNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- Aiml Ex 5Document3 pagesAiml Ex 5Tasmiya DzNo ratings yet
- HOUSE PRICINGDocument15 pagesHOUSE PRICINGsanjana.devarapalli7No ratings yet
- Coca Cola StartDocument1 pageCoca Cola StartxtremewhizNo ratings yet
- Stocs PredictDocument2 pagesStocs PredictSanjay ReddyNo ratings yet
- EAI 3rdDocument2 pagesEAI 3rdI yr IT 10-Cherisha SNo ratings yet
- Machine FileDocument27 pagesMachine FileJyoti GodaraNo ratings yet
- LAB FILE-Shelly SharmaDocument47 pagesLAB FILE-Shelly SharmaShelly SharmaNo ratings yet
- MLDocument7 pagesML21eg105f37No ratings yet
- AI Salary Expt 9Document1 pageAI Salary Expt 9004Prasanna TayareNo ratings yet
- Raj Practical File (ML)Document16 pagesRaj Practical File (ML)RajNo ratings yet
- CodeDocument6 pagesCodeKeerti GulatiNo ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (2)
- Da ProgramDocument18 pagesDa Programalishacalista238No ratings yet
- Data Science Lab ManualDocument32 pagesData Science Lab ManualRavishankar GautamNo ratings yet
- My CodeDocument7 pagesMy Codeoyelekeayomide1No ratings yet
- Abhiml ML FileDocument74 pagesAbhiml ML FileBhawna ChandlaNo ratings yet
- EAI4 THDocument2 pagesEAI4 THI yr IT 10-Cherisha SNo ratings yet
- 2020 CS 64Document1 page2020 CS 64Qazi MaazNo ratings yet
- Stock PredDocument2 pagesStock PredSrijeeta SenNo ratings yet
- House Price PredictionDocument3 pagesHouse Price PredictionG SuriyanaraynanNo ratings yet
- The Goal of This Part Is To Use Descriptive Statistics and Visualization To Better Understand Your DataDocument3 pagesThe Goal of This Part Is To Use Descriptive Statistics and Visualization To Better Understand Your Datalyna mebarka BENYAKOUBNo ratings yet
- Linear RegressionDocument2 pagesLinear Regressionanish.t.pNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Unit1 ML ProgramsDocument5 pagesUnit1 ML Programsdiroja5648No ratings yet
- 2020 CS 95.pyDocument1 page2020 CS 95.pyQazi MaazNo ratings yet
- Tan Cian Code2Document4 pagesTan Cian Code2CIAN CARLO ANDRE TANNo ratings yet
- ML Lab RecordDocument15 pagesML Lab Recordrr3870044No ratings yet
- ML RecordDocument18 pagesML Recordharshitsr1234No ratings yet
- TP_JEUX_ML - CorrigéDocument5 pagesTP_JEUX_ML - CorrigéYoussef Jamma3No ratings yet
- PRJ Car Price Prediction For Data ScienceDocument10 pagesPRJ Car Price Prediction For Data Scienceshivaybhargava33No ratings yet
- Lab-5 ReportDocument11 pagesLab-5 Reportjithentar.cs21No ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- Import Pandas as PdDocument21 pagesImport Pandas as Pdcaptainsaad838No ratings yet
- Untitled DocumentDocument19 pagesUntitled Documents14utkarsh2111019No ratings yet
- Supervised Learning For Data Science...Document14 pagesSupervised Learning For Data Science...shivaybhargava33No ratings yet
- Pattern Report FinalDocument10 pagesPattern Report FinalMD Rubel AminNo ratings yet
- Prototype 13Document1 pagePrototype 13Yemi TowobolaNo ratings yet
- Python Note 3Document11 pagesPython Note 3Coding KnowledgeNo ratings yet
- Heart Disease PredictionDocument2 pagesHeart Disease Predictionmamtadevi07764No ratings yet
- Pattern Recognition LabDocument24 pagesPattern Recognition LabPrashant KumarNo ratings yet
- Face Recognition Using Facenet3Document4 pagesFace Recognition Using Facenet3Harini MurugananthamNo ratings yet
- ML Manual finalDocument35 pagesML Manual finalPriya MohanaNo ratings yet
- Online Payment Fraud Detection Using Machine LearningDocument2 pagesOnline Payment Fraud Detection Using Machine LearningDev Ranjan RautNo ratings yet
- Breadth First Search and Iterative Depth First Search: Practical 1Document21 pagesBreadth First Search and Iterative Depth First Search: Practical 1ssaahil.o6o4No ratings yet
- Print: Program 7Document3 pagesPrint: Program 7Impu anandNo ratings yet
- XII - Informatics Practices (LAB MANUAL)Document42 pagesXII - Informatics Practices (LAB MANUAL)ghun assudani100% (1)
- Experiment 3Document2 pagesExperiment 321-524No ratings yet
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- ML PracticalsDocument11 pagesML Practicals05. Yash DaroleNo ratings yet
- CH4.ipynb - ColabDocument8 pagesCH4.ipynb - Colabjerry4101comtwNo ratings yet
- Linear Regression With Length Predicted by Dose-1Document7 pagesLinear Regression With Length Predicted by Dose-1f.ember02No ratings yet
- Csd201 Pe Instructions Students Are ONLY Allowed To Use:: Not Submit The Un-Edited Given ProjectDocument2 pagesCsd201 Pe Instructions Students Are ONLY Allowed To Use:: Not Submit The Un-Edited Given ProjectLong NguyễnNo ratings yet
- M3 DS21-Data Mining Dan Statistik - RevDocument101 pagesM3 DS21-Data Mining Dan Statistik - RevrinNo ratings yet
- Worksheet Classification1Document15 pagesWorksheet Classification1Partha Pritom GhoshNo ratings yet
- Panimalar Engineering College Department of Electronics and InstrumentationDocument2 pagesPanimalar Engineering College Department of Electronics and InstrumentationDr.L.Balaji, ECE Vel Tech, ChennaiNo ratings yet
- Trigo DerivationDocument12 pagesTrigo DerivationMabrouk YemadNo ratings yet
- 1breohbaq 289967Document94 pages1breohbaq 289967Mac JeffersonNo ratings yet
- ANN - Session 4 CO 1Document7 pagesANN - Session 4 CO 1joxekojNo ratings yet
- Fyp IdeasDocument3 pagesFyp IdeasAltamash KhuwajaNo ratings yet
- Tugas Geostat Ke-1 - Elvira Mutiara S - 12117019 PDFDocument15 pagesTugas Geostat Ke-1 - Elvira Mutiara S - 12117019 PDFElvira M ShaumiNo ratings yet
- OR MCQDocument7 pagesOR MCQBadder Danbad100% (1)
- Question-Regular-Cs205 Data Structures (CS, It), December 2017Document2 pagesQuestion-Regular-Cs205 Data Structures (CS, It), December 2017For FunNo ratings yet
- A Review of Quantum Key Distribution Protocols in The Perspective of Smart Grid Communication SecurityDocument14 pagesA Review of Quantum Key Distribution Protocols in The Perspective of Smart Grid Communication SecurityNati ManNo ratings yet
- Obd 04 PDFDocument14 pagesObd 04 PDFAgustín EstramilNo ratings yet
- Array Exercise VIDocument2 pagesArray Exercise VISboNo ratings yet
- 3.1 Multiple Linear Regression ModelDocument11 pages3.1 Multiple Linear Regression ModelMaria Paola Velasquez RoyNo ratings yet
- One-Port NetworkDocument9 pagesOne-Port NetworkGiwrgosMthNo ratings yet
- Evaluation of The Partition Function of Fermions Using Grassmann Coherent States Without Path IntegralsDocument92 pagesEvaluation of The Partition Function of Fermions Using Grassmann Coherent States Without Path IntegralsParanoidhumanNo ratings yet
- Thesis MainDocument144 pagesThesis MainIvan GrkajacNo ratings yet
- A Systematic Review and Meta-Analysis of SWARA and WASPAS Methods: Theory and Applications With Recent Fuzzy DevelopmentsDocument28 pagesA Systematic Review and Meta-Analysis of SWARA and WASPAS Methods: Theory and Applications With Recent Fuzzy DevelopmentsMia AmaliaNo ratings yet
- Submission Type Due Date Total Score Available From DescriptionDocument3 pagesSubmission Type Due Date Total Score Available From DescriptiondonnaNo ratings yet
- Dbs3e PPT ch14Document91 pagesDbs3e PPT ch14raraNo ratings yet
- B.P. Poddar Institute of Management and TechnologyDocument20 pagesB.P. Poddar Institute of Management and TechnologynikitaNo ratings yet
- Binary Search Tree: Reny JoseDocument36 pagesBinary Search Tree: Reny JoseReny JoseNo ratings yet
- Kca University Simulation and Modeling Assignment Group 7 Definition of Key TermsDocument4 pagesKca University Simulation and Modeling Assignment Group 7 Definition of Key TermsGideon YegonNo ratings yet
- AI NLP Engineer-JD-updatedDocument2 pagesAI NLP Engineer-JD-updatedPratik BoseNo ratings yet
- CS229 Lecture Notes: Supervised LearningDocument293 pagesCS229 Lecture Notes: Supervised LearningmahithaNo ratings yet
- Huawei Questions: True or FalseDocument24 pagesHuawei Questions: True or FalsemadelNo ratings yet












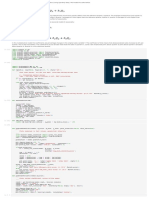


















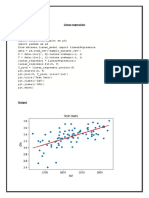

























































Download as docx, pdf, or txt
You might also like
- TRM-CH 5 Frappy RubricDocument3 pagesTRM-CH 5 Frappy Rubricapi-2619568050% (1)
- Appendix PDFDocument5 pagesAppendix PDFRamaNo ratings yet
- Data Science ManualDocument16 pagesData Science ManualKRISHNAVENI RNo ratings yet
- Big Data MergedDocument7 pagesBig Data MergedIngame IdNo ratings yet
- MLDocument2 pagesMLwovova9230No ratings yet
- Cancer Disease ClassificationDocument6 pagesCancer Disease ClassificationBARATH PNo ratings yet
- ML 1-10Document53 pagesML 1-1022128008No ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Import Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadDocument20 pagesImport Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadSaloni TuliNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- Aiml Ex 5Document3 pagesAiml Ex 5Tasmiya DzNo ratings yet
- HOUSE PRICINGDocument15 pagesHOUSE PRICINGsanjana.devarapalli7No ratings yet
- Coca Cola StartDocument1 pageCoca Cola StartxtremewhizNo ratings yet
- Stocs PredictDocument2 pagesStocs PredictSanjay ReddyNo ratings yet
- EAI 3rdDocument2 pagesEAI 3rdI yr IT 10-Cherisha SNo ratings yet
- Machine FileDocument27 pagesMachine FileJyoti GodaraNo ratings yet
- LAB FILE-Shelly SharmaDocument47 pagesLAB FILE-Shelly SharmaShelly SharmaNo ratings yet
- MLDocument7 pagesML21eg105f37No ratings yet
- AI Salary Expt 9Document1 pageAI Salary Expt 9004Prasanna TayareNo ratings yet
- Raj Practical File (ML)Document16 pagesRaj Practical File (ML)RajNo ratings yet
- CodeDocument6 pagesCodeKeerti GulatiNo ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (2)
- Da ProgramDocument18 pagesDa Programalishacalista238No ratings yet
- Data Science Lab ManualDocument32 pagesData Science Lab ManualRavishankar GautamNo ratings yet
- My CodeDocument7 pagesMy Codeoyelekeayomide1No ratings yet
- Abhiml ML FileDocument74 pagesAbhiml ML FileBhawna ChandlaNo ratings yet
- EAI4 THDocument2 pagesEAI4 THI yr IT 10-Cherisha SNo ratings yet
- 2020 CS 64Document1 page2020 CS 64Qazi MaazNo ratings yet
- Stock PredDocument2 pagesStock PredSrijeeta SenNo ratings yet
- House Price PredictionDocument3 pagesHouse Price PredictionG SuriyanaraynanNo ratings yet
- The Goal of This Part Is To Use Descriptive Statistics and Visualization To Better Understand Your DataDocument3 pagesThe Goal of This Part Is To Use Descriptive Statistics and Visualization To Better Understand Your Datalyna mebarka BENYAKOUBNo ratings yet
- Linear RegressionDocument2 pagesLinear Regressionanish.t.pNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Unit1 ML ProgramsDocument5 pagesUnit1 ML Programsdiroja5648No ratings yet
- 2020 CS 95.pyDocument1 page2020 CS 95.pyQazi MaazNo ratings yet
- Tan Cian Code2Document4 pagesTan Cian Code2CIAN CARLO ANDRE TANNo ratings yet
- ML Lab RecordDocument15 pagesML Lab Recordrr3870044No ratings yet
- ML RecordDocument18 pagesML Recordharshitsr1234No ratings yet
- TP_JEUX_ML - CorrigéDocument5 pagesTP_JEUX_ML - CorrigéYoussef Jamma3No ratings yet
- PRJ Car Price Prediction For Data ScienceDocument10 pagesPRJ Car Price Prediction For Data Scienceshivaybhargava33No ratings yet
- Lab-5 ReportDocument11 pagesLab-5 Reportjithentar.cs21No ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- Import Pandas as PdDocument21 pagesImport Pandas as Pdcaptainsaad838No ratings yet
- Untitled DocumentDocument19 pagesUntitled Documents14utkarsh2111019No ratings yet
- Supervised Learning For Data Science...Document14 pagesSupervised Learning For Data Science...shivaybhargava33No ratings yet
- Pattern Report FinalDocument10 pagesPattern Report FinalMD Rubel AminNo ratings yet
- Prototype 13Document1 pagePrototype 13Yemi TowobolaNo ratings yet
- Python Note 3Document11 pagesPython Note 3Coding KnowledgeNo ratings yet
- Heart Disease PredictionDocument2 pagesHeart Disease Predictionmamtadevi07764No ratings yet
- Pattern Recognition LabDocument24 pagesPattern Recognition LabPrashant KumarNo ratings yet
- Face Recognition Using Facenet3Document4 pagesFace Recognition Using Facenet3Harini MurugananthamNo ratings yet
- ML Manual finalDocument35 pagesML Manual finalPriya MohanaNo ratings yet
- Online Payment Fraud Detection Using Machine LearningDocument2 pagesOnline Payment Fraud Detection Using Machine LearningDev Ranjan RautNo ratings yet
- Breadth First Search and Iterative Depth First Search: Practical 1Document21 pagesBreadth First Search and Iterative Depth First Search: Practical 1ssaahil.o6o4No ratings yet
- Print: Program 7Document3 pagesPrint: Program 7Impu anandNo ratings yet
- XII - Informatics Practices (LAB MANUAL)Document42 pagesXII - Informatics Practices (LAB MANUAL)ghun assudani100% (1)
- Experiment 3Document2 pagesExperiment 321-524No ratings yet
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- ML PracticalsDocument11 pagesML Practicals05. Yash DaroleNo ratings yet
- CH4.ipynb - ColabDocument8 pagesCH4.ipynb - Colabjerry4101comtwNo ratings yet
- Linear Regression With Length Predicted by Dose-1Document7 pagesLinear Regression With Length Predicted by Dose-1f.ember02No ratings yet
- Csd201 Pe Instructions Students Are ONLY Allowed To Use:: Not Submit The Un-Edited Given ProjectDocument2 pagesCsd201 Pe Instructions Students Are ONLY Allowed To Use:: Not Submit The Un-Edited Given ProjectLong NguyễnNo ratings yet
- M3 DS21-Data Mining Dan Statistik - RevDocument101 pagesM3 DS21-Data Mining Dan Statistik - RevrinNo ratings yet
- Worksheet Classification1Document15 pagesWorksheet Classification1Partha Pritom GhoshNo ratings yet
- Panimalar Engineering College Department of Electronics and InstrumentationDocument2 pagesPanimalar Engineering College Department of Electronics and InstrumentationDr.L.Balaji, ECE Vel Tech, ChennaiNo ratings yet
- Trigo DerivationDocument12 pagesTrigo DerivationMabrouk YemadNo ratings yet
- 1breohbaq 289967Document94 pages1breohbaq 289967Mac JeffersonNo ratings yet
- ANN - Session 4 CO 1Document7 pagesANN - Session 4 CO 1joxekojNo ratings yet
- Fyp IdeasDocument3 pagesFyp IdeasAltamash KhuwajaNo ratings yet
- Tugas Geostat Ke-1 - Elvira Mutiara S - 12117019 PDFDocument15 pagesTugas Geostat Ke-1 - Elvira Mutiara S - 12117019 PDFElvira M ShaumiNo ratings yet
- OR MCQDocument7 pagesOR MCQBadder Danbad100% (1)
- Question-Regular-Cs205 Data Structures (CS, It), December 2017Document2 pagesQuestion-Regular-Cs205 Data Structures (CS, It), December 2017For FunNo ratings yet
- A Review of Quantum Key Distribution Protocols in The Perspective of Smart Grid Communication SecurityDocument14 pagesA Review of Quantum Key Distribution Protocols in The Perspective of Smart Grid Communication SecurityNati ManNo ratings yet
- Obd 04 PDFDocument14 pagesObd 04 PDFAgustín EstramilNo ratings yet
- Array Exercise VIDocument2 pagesArray Exercise VISboNo ratings yet
- 3.1 Multiple Linear Regression ModelDocument11 pages3.1 Multiple Linear Regression ModelMaria Paola Velasquez RoyNo ratings yet
- One-Port NetworkDocument9 pagesOne-Port NetworkGiwrgosMthNo ratings yet
- Evaluation of The Partition Function of Fermions Using Grassmann Coherent States Without Path IntegralsDocument92 pagesEvaluation of The Partition Function of Fermions Using Grassmann Coherent States Without Path IntegralsParanoidhumanNo ratings yet
- Thesis MainDocument144 pagesThesis MainIvan GrkajacNo ratings yet
- A Systematic Review and Meta-Analysis of SWARA and WASPAS Methods: Theory and Applications With Recent Fuzzy DevelopmentsDocument28 pagesA Systematic Review and Meta-Analysis of SWARA and WASPAS Methods: Theory and Applications With Recent Fuzzy DevelopmentsMia AmaliaNo ratings yet
- Submission Type Due Date Total Score Available From DescriptionDocument3 pagesSubmission Type Due Date Total Score Available From DescriptiondonnaNo ratings yet
- Dbs3e PPT ch14Document91 pagesDbs3e PPT ch14raraNo ratings yet
- B.P. Poddar Institute of Management and TechnologyDocument20 pagesB.P. Poddar Institute of Management and TechnologynikitaNo ratings yet
- Binary Search Tree: Reny JoseDocument36 pagesBinary Search Tree: Reny JoseReny JoseNo ratings yet
- Kca University Simulation and Modeling Assignment Group 7 Definition of Key TermsDocument4 pagesKca University Simulation and Modeling Assignment Group 7 Definition of Key TermsGideon YegonNo ratings yet
- AI NLP Engineer-JD-updatedDocument2 pagesAI NLP Engineer-JD-updatedPratik BoseNo ratings yet
- CS229 Lecture Notes: Supervised LearningDocument293 pagesCS229 Lecture Notes: Supervised LearningmahithaNo ratings yet
- Huawei Questions: True or FalseDocument24 pagesHuawei Questions: True or FalsemadelNo ratings yet