Download as pdf or txt
You might also like
- Bell 30 EDocument918 pagesBell 30 Esfe100% (12)
- LS Swaps: How to Swap GM LS Engines into Almost AnythingFrom EverandLS Swaps: How to Swap GM LS Engines into Almost AnythingRating: 3.5 out of 5 stars3.5/5 (2)
- Fuse Box Diagram Astra GDocument14 pagesFuse Box Diagram Astra GLászló SzabóNo ratings yet
- +diagramas Electricos Peugeot Partner 2008 - 2017 Ingles-1Document88 pages+diagramas Electricos Peugeot Partner 2008 - 2017 Ingles-1Upvanessithap Tholedop Diazp100% (3)
- Fd50t9 ChassisDocument453 pagesFd50t9 ChassisDani Setiawan100% (1)
- Strategic Group MapDocument3 pagesStrategic Group MapCalonneFrNo ratings yet
- Fuse Box Diagram Mercedes Sprinter W901 W902 W903 W904 W905Document8 pagesFuse Box Diagram Mercedes Sprinter W901 W902 W903 W904 W905Klasserei Lda67% (3)
- OBDLINK MX+app - SupportDocument69 pagesOBDLINK MX+app - SupportVanessa Dalessandro100% (1)
- Fuse Box Renault Megane 2Document12 pagesFuse Box Renault Megane 2JosetongoNo ratings yet
- Fuse Box Passat b6Document19 pagesFuse Box Passat b6Ionut AlbuicaNo ratings yet
- EX.5 - Assembly and Disassembly of Ic Engine PartsDocument6 pagesEX.5 - Assembly and Disassembly of Ic Engine PartsDipesh Baral75% (12)
- M145 Gl-EnDocument0 pagesM145 Gl-Enaiigee100% (4)
- DataViz Ggplot SampleDocument23 pagesDataViz Ggplot SampleK Anantha KrishnanNo ratings yet
- Perceptual Map Template Someka Excel V2 Free VersionDocument2 pagesPerceptual Map Template Someka Excel V2 Free VersionnaveenkrealNo ratings yet
- US Val EuroVehicle 0W40 MO ENDocument1 pageUS Val EuroVehicle 0W40 MO ENAnond UseryNo ratings yet
- Ford PRES. FinalDocument18 pagesFord PRES. FinalAkash PatelNo ratings yet
- NullDocument2 pagesNullapi-26309397No ratings yet
- Kelistrikan AvanzaDocument5 pagesKelistrikan AvanzaAdi HeriadiNo ratings yet
- TTIW018-DC Power Train Architecture For EVs-EN-FINALDocument8 pagesTTIW018-DC Power Train Architecture For EVs-EN-FINALPawin seesamleeNo ratings yet
- Team Sputnik: Achyut - Parag - PoojaDocument17 pagesTeam Sputnik: Achyut - Parag - PoojaHrangbung DarthangNo ratings yet
- Strategic Management Presentation On VW (FINAL)Document32 pagesStrategic Management Presentation On VW (FINAL)manelisir43% (7)
- SPM Project Report1Document10 pagesSPM Project Report1KOTHAPALLI SAI SARADA MYTHILINo ratings yet
- Modeling Tools For Predicting The Impact of Rolling Resistance On Energy Usage and Fuel Efficiency For Realistic Driving CyclesDocument28 pagesModeling Tools For Predicting The Impact of Rolling Resistance On Energy Usage and Fuel Efficiency For Realistic Driving Cyclesjos3No ratings yet
- U.S. VdsDocument5 pagesU.S. VdsБогдан ГулаNo ratings yet
- Typical Mercedes-Benz Electric Truck PowertrainDocument8 pagesTypical Mercedes-Benz Electric Truck Powertrainmujahid0 irfanNo ratings yet
- Tunisian Automobile Market: Cars Dealers, Brands and Sales FiguresDocument14 pagesTunisian Automobile Market: Cars Dealers, Brands and Sales FiguresbeddaNo ratings yet
- Golf PlusDocument22 pagesGolf PluseduardNo ratings yet
- Corolla TRD PortafolioDocument23 pagesCorolla TRD Portafolioh4seeb10No ratings yet
- Data And Methodology: Table2:Datacoverageformaintechnicalcharacteristics,2008 Nonͳ Oecd Oecd GlobalDocument2 pagesData And Methodology: Table2:Datacoverageformaintechnicalcharacteristics,2008 Nonͳ Oecd Oecd Globalmanoj262400/2No ratings yet
- Matrix Plot: 2017 by Statgraphics Technologies, IncDocument7 pagesMatrix Plot: 2017 by Statgraphics Technologies, IncRuben MaciasNo ratings yet
- Rav4 4DR 2WL 4cylDocument12 pagesRav4 4DR 2WL 4cylyogesh.chicago5143No ratings yet
- Saadiq Auto Finance Pricing: New VehiclesDocument2 pagesSaadiq Auto Finance Pricing: New VehiclesNedian Sarfaraz Ahmed ShaikhNo ratings yet
- 2023 CamryDocument8 pages2023 CamrybhargavNo ratings yet
- Toyota Electrification Strategy in Europe Today and TomorrowDocument35 pagesToyota Electrification Strategy in Europe Today and TomorrowAntoine BurgerNo ratings yet
- SUV Aerodynamics v10Document17 pagesSUV Aerodynamics v10Dang Tien PhucNo ratings yet
- Window StickerDocument1 pageWindow StickerS ANo ratings yet
- Partner Spec Sheet.91391Document12 pagesPartner Spec Sheet.91391Projetos Marimar 001No ratings yet
- RAM 1000 Put To The Test: Does It Deserve To Take The 'Ram' On The Front? (+video)Document2 pagesRAM 1000 Put To The Test: Does It Deserve To Take The 'Ram' On The Front? (+video)janNo ratings yet
- KumhoPatternDigest 2015 ScreenversionDocument76 pagesKumhoPatternDigest 2015 Screenversiondionisio emilio reyes jimenezNo ratings yet
- Mazda CX 5 2016 CADocument14 pagesMazda CX 5 2016 CAWA laundryNo ratings yet
- Libro de LlavesDocument142 pagesLibro de Llavesadris banquethNo ratings yet
- Conce Sion A RioDocument6 pagesConce Sion A RioMENGUAL IVARS AINHOANo ratings yet
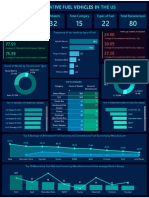
- Alternative Fuel Vehicles US-1Document1 pageAlternative Fuel Vehicles US-1Shreyash TiwariNo ratings yet
- Learning/"Document39 pagesLearning/"Art DedajNo ratings yet
- LRDI - 08: Pie-Chart & Bar GraphsDocument9 pagesLRDI - 08: Pie-Chart & Bar GraphsxyzNo ratings yet
- Motor Trend MPG Data AnalysisDocument4 pagesMotor Trend MPG Data AnalysisPeter ThaiNo ratings yet
- PracticeExam JUTCDocument7 pagesPracticeExam JUTCkadenemills22No ratings yet
- Learning/"Document32 pagesLearning/"Art DedajNo ratings yet
- Guia Aplicaciones T-CODEDocument145 pagesGuia Aplicaciones T-CODEHyb CerrajeriaNo ratings yet
- Customer Letter MailingDocument5 pagesCustomer Letter MailingDiego orrego guajardoNo ratings yet
- Fuse Box Peugeot 206Document4 pagesFuse Box Peugeot 206TierNo ratings yet
- 3 GAIKINDO Wholesales Data Janapr2024Document3 pages3 GAIKINDO Wholesales Data Janapr2024fikri.a.nugrohoNo ratings yet
- gs8 21my Spec Sheet 4wd GTDocument1 pagegs8 21my Spec Sheet 4wd GTKhaled ElwassiefNo ratings yet
- 2010 Ginn Motor Company Colorado Atlanta GADocument8 pages2010 Ginn Motor Company Colorado Atlanta GAatlantachevroletNo ratings yet
- LearningDocument32 pagesLearningArt DedajNo ratings yet
- Car AssignmentDocument14 pagesCar Assignmentapi-349838341No ratings yet
- Data WranglingDocument24 pagesData WranglingLuiz Arthur MedeirosNo ratings yet
- Wang XingchunDocument55 pagesWang XingchunAbdulafeezNo ratings yet
- A Presentation On Renault'S Upcomoing Model " ": Prepared by - Avinandan Karmakar JSB (2014-16)Document14 pagesA Presentation On Renault'S Upcomoing Model " ": Prepared by - Avinandan Karmakar JSB (2014-16)Rishijit PanigrahiNo ratings yet
- Tutorial 4 QA Decision AnalysisDocument20 pagesTutorial 4 QA Decision AnalysismulianiNo ratings yet
- CSharp-OOP-Working-with-Abstraction-ExerciseDocument10 pagesCSharp-OOP-Working-with-Abstraction-ExerciseBob LongNo ratings yet
- CSD Brochure 2021Document6 pagesCSD Brochure 2021Tapan Rishi BhatnagarNo ratings yet
- Random MotorsDocument11 pagesRandom MotorsAbhishek ChowdhuryNo ratings yet
- NPR Anilla 2020Document159 pagesNPR Anilla 2020Armando Jacinto100% (5)
- DC9 EssentialsDocument12 pagesDC9 EssentialsCyriac JoseNo ratings yet
- Airbag 18 01 2014Document97 pagesAirbag 18 01 2014awesome 0No ratings yet
- Glenn Laken Heavy Truck Driver Sample ResumeDocument1 pageGlenn Laken Heavy Truck Driver Sample ResumeGlenn LakenNo ratings yet
- Dvic LucasDocument4 pagesDvic LucasGeorge VitalariuNo ratings yet
- 5R55W-S VacTestLocations PDFDocument2 pages5R55W-S VacTestLocations PDFMichael LealNo ratings yet
- Reclist 2017 WebDocument56 pagesReclist 2017 Webrajanaqib3434No ratings yet
- Performance of An AutomobileDocument46 pagesPerformance of An AutomobileRajnish KumarNo ratings yet
- GH60RS RSVRST Procedures MAR 15.pptversion 2Document103 pagesGH60RS RSVRST Procedures MAR 15.pptversion 2Ionut TanaseNo ratings yet
- Engine Report Sriwantha PDFDocument14 pagesEngine Report Sriwantha PDFSriwantha HewageNo ratings yet
- Fuel PumpsDocument157 pagesFuel PumpskisukecmpNo ratings yet
- Daimler Buses at A Glance.: Edition 2010Document21 pagesDaimler Buses at A Glance.: Edition 2010Teguh PXNo ratings yet
- Laguna ReprogrammingDocument5 pagesLaguna ReprogrammingEmilia Andrada DarsyNo ratings yet
- Integrated Automobile Car Jack (IAJ)Document35 pagesIntegrated Automobile Car Jack (IAJ)Lorenz SchmidNo ratings yet
- Evoque 2011-13 - Engine Ignition - GTDi 2.0L PetrolDocument9 pagesEvoque 2011-13 - Engine Ignition - GTDi 2.0L PetrolAliNo ratings yet
- Computadora Mazda 6Document2 pagesComputadora Mazda 6jose de jesusNo ratings yet
- Stage IIIB (2011 and After) PDFDocument3 pagesStage IIIB (2011 and After) PDFabdallah harrabNo ratings yet
- Anand Sardar - NIPPON CLUTCHES MRP LIST DT 01.01.2021Document3 pagesAnand Sardar - NIPPON CLUTCHES MRP LIST DT 01.01.2021sssakol1981No ratings yet
- PCM - Ma022Document61 pagesPCM - Ma022Nofriagara Davit HarnawanNo ratings yet
- 7a Weatherman Speed 2010Document2 pages7a Weatherman Speed 2010samwebmasterNo ratings yet
- Tata Indica V2 Turbo: Car BrochureDocument3 pagesTata Indica V2 Turbo: Car BrochureRohit ChatterjeeNo ratings yet
- Nissan FrontierDocument36 pagesNissan FrontierKerbin Enrique NuñezNo ratings yet
- Active Suspension: Automotive SuspensionsDocument1 pageActive Suspension: Automotive SuspensionshakishankzNo ratings yet
- Arctic Cat 2012 DVX 90 and 90 Utility Service ManualDocument8 pagesArctic Cat 2012 DVX 90 and 90 Utility Service Manualcarol100% (62)
- Ready Project of PLC of Maruti 800Document27 pagesReady Project of PLC of Maruti 800bha_goNo ratings yet