Download as pdf or txt
You might also like
- CSIT1114 - Lab2 - 1230 - Ms. Sara Majed - 8192959Document7 pagesCSIT1114 - Lab2 - 1230 - Ms. Sara Majed - 8192959adam hopeNo ratings yet
- J.C. Penneys Fair and Square Strategy AbDocument7 pagesJ.C. Penneys Fair and Square Strategy AbParul JainNo ratings yet
- DSME2051CDocument5 pagesDSME2051Choi chingNo ratings yet
- GCS0805B - NX-HUỲNH NHẬT NAM-GCS190293-MÔN DATA ASSIGNMENT 2Document24 pagesGCS0805B - NX-HUỲNH NHẬT NAM-GCS190293-MÔN DATA ASSIGNMENT 2Huynh Nhat Nam (FGW HCM)No ratings yet
- Practical Design of Experiments: DoE Made EasyFrom EverandPractical Design of Experiments: DoE Made EasyRating: 4.5 out of 5 stars4.5/5 (7)
- SIM335 Assignment Aug 2013Document7 pagesSIM335 Assignment Aug 2013talha149No ratings yet
- R Programming NotesDocument32 pagesR Programming NotesShanmugasundaram Muthuswamy100% (1)
- Data Mining Lab 1Document16 pagesData Mining Lab 1Usama NaveedNo ratings yet
- DWDM Lab Manual: Department of Computer Science and EngineeringDocument46 pagesDWDM Lab Manual: Department of Computer Science and EngineeringDilli BooksNo ratings yet
- Narrative Report in Linear ProgrammingDocument3 pagesNarrative Report in Linear Programmingnhel72100% (1)
- Labmanual: Bcse2321: Data Structures Using C++ Lab ManualDocument60 pagesLabmanual: Bcse2321: Data Structures Using C++ Lab ManualANMOL CHAUHANNo ratings yet
- 2-StatProb11 Q4 Mod2 Correlation-Analysis Version3Document28 pages2-StatProb11 Q4 Mod2 Correlation-Analysis Version3Analou AvilaNo ratings yet
- Compro1-C++ Syllabus 1011Document4 pagesCompro1-C++ Syllabus 1011Eloisa LecarozNo ratings yet
- Ecf Ech, Eck Ecd, Ecf, EcgDocument10 pagesEcf Ech, Eck Ecd, Ecf, EcgKim Patrick GuevarraNo ratings yet
- Predictive Analytics Exam-June 2019: Exam PA Home PageDocument9 pagesPredictive Analytics Exam-June 2019: Exam PA Home PagejusttestitNo ratings yet
- Math Lesson Plan For WikiDocument3 pagesMath Lesson Plan For WikimexitravNo ratings yet
- SIM335 January 2017 TNE Top-Up AssessmentDocument6 pagesSIM335 January 2017 TNE Top-Up AssessmenttechnicalvijayNo ratings yet
- Institute Vision and Mission Vision: PEO1: PEO2: PEO3Document35 pagesInstitute Vision and Mission Vision: PEO1: PEO2: PEO3Faisal AhmadNo ratings yet
- Step Template ModifiedDocument25 pagesStep Template Modifiedapi-695402539No ratings yet
- Quantitative Analysis Lecture - 1-Introduction: Associate Professor, Anwar Mahmoud Mohamed, PHD, Mba, PMPDocument41 pagesQuantitative Analysis Lecture - 1-Introduction: Associate Professor, Anwar Mahmoud Mohamed, PHD, Mba, PMPEngMohamedReyadHelesyNo ratings yet
- Fifth Math Unit 4Document3 pagesFifth Math Unit 4Jellai LascamanaNo ratings yet
- Predictive Analytics Exam-December 2018: Exam PA Home PageDocument8 pagesPredictive Analytics Exam-December 2018: Exam PA Home PagekidNo ratings yet
- PPS0335 ProjectGuidelines T3 - 2015 2016Document4 pagesPPS0335 ProjectGuidelines T3 - 2015 2016Shaun Ng WesNo ratings yet
- Developing An Algorithm: 8.2 Introduction To Software DevelopmentDocument4 pagesDeveloping An Algorithm: 8.2 Introduction To Software DevelopmentKiran SEEROONo ratings yet
- Spreadsheet Analytics PGPM IM 2017-20Document4 pagesSpreadsheet Analytics PGPM IM 2017-20Abhishek SharmaNo ratings yet
- MAKSI-Pemodelan Dan Visualisasi Data Gasal 2122Document5 pagesMAKSI-Pemodelan Dan Visualisasi Data Gasal 2122anggi anythingNo ratings yet
- SIM335Document7 pagesSIM335Asif IslamNo ratings yet
- Comp Prog 12 W3 W4Document27 pagesComp Prog 12 W3 W4Michael Vernice B NievaNo ratings yet
- As1 - 1651 Gcs0802 - NX - Le Vo Hong Ngoc - Tcs18005Document28 pagesAs1 - 1651 Gcs0802 - NX - Le Vo Hong Ngoc - Tcs18005Mit To PiNo ratings yet
- 18 Ie 22, Experiment 10Document20 pages18 Ie 22, Experiment 10usama khanNo ratings yet
- QT Syllabus RevisedDocument3 pagesQT Syllabus RevisedprasadkulkarnigitNo ratings yet
- Calculus ProjectDocument4 pagesCalculus Projecti233046No ratings yet
- Instructional Module and Its Components (Guide)Document10 pagesInstructional Module and Its Components (Guide)Rovell AsideraNo ratings yet
- Final Assignment On orDocument23 pagesFinal Assignment On orRahul GuptaNo ratings yet
- 1651 GCS0701B - Gcs17556 - Nguyen Cao TriDocument38 pages1651 GCS0701B - Gcs17556 - Nguyen Cao TriRAY LEENo ratings yet
- Assignment On Operations Research by Rahul GuptaDocument21 pagesAssignment On Operations Research by Rahul GuptaKalai SNo ratings yet
- Predictive Analytics Exam-December 2019: Exam PA Home PageDocument9 pagesPredictive Analytics Exam-December 2019: Exam PA Home PagejusttestitNo ratings yet
- SIM335 Assessment Brief January19Document4 pagesSIM335 Assessment Brief January19Quyên VũNo ratings yet
- Subject Code Subject Title Credit Value Level Normal Duration Pre-Requisite / Co-Requisite/ Exclusion Role and PurposesDocument3 pagesSubject Code Subject Title Credit Value Level Normal Duration Pre-Requisite / Co-Requisite/ Exclusion Role and Purposesums6120No ratings yet
- Brief Introduction: Employee Payroll ManagementDocument12 pagesBrief Introduction: Employee Payroll ManagementSiddhant GunjalNo ratings yet
- 2018 Exam Pa SyllabiDocument9 pages2018 Exam Pa SyllabijusttestitNo ratings yet
- Syllabus MNGT 403 Fall 2017-18Document5 pagesSyllabus MNGT 403 Fall 2017-18Dr. Mohammad Noor AlamNo ratings yet
- Exercises Week 02 Flow DiagramsDocument12 pagesExercises Week 02 Flow DiagramsMARK GOSLING PEÑACOBANo ratings yet
- MGMT 524 Online Syllabus 0314Document8 pagesMGMT 524 Online Syllabus 0314HeatherNo ratings yet
- Iaa202 Ia17a Lab3 Team1Document8 pagesIaa202 Ia17a Lab3 Team1Lý Ngọc HiếuNo ratings yet
- End of Course Memo CS 101 - Intro To Computing Aaron Bloomfield (Fall 2005)Document4 pagesEnd of Course Memo CS 101 - Intro To Computing Aaron Bloomfield (Fall 2005)Mohammad Sa-ad L IndarNo ratings yet
- Java Week 1-10Document32 pagesJava Week 1-10chadskie20No ratings yet
- HPX100 1 Jul Dec2022 SA1 CZ V2 27062022 PDFDocument5 pagesHPX100 1 Jul Dec2022 SA1 CZ V2 27062022 PDFThembisa NobethaNo ratings yet
- EPD Assignment Brief Fall 2015Document7 pagesEPD Assignment Brief Fall 2015Khoa NguyễnNo ratings yet
- Course Syllabus MATH317 Spring2022 Dept Version FinalDocument6 pagesCourse Syllabus MATH317 Spring2022 Dept Version FinalHABIB RebeiNo ratings yet
- Assignment Brief 1 (RQF) : Higher National Certificate/Diploma in ComputingDocument20 pagesAssignment Brief 1 (RQF) : Higher National Certificate/Diploma in ComputingDuy TrungNo ratings yet
- Syllabus Computer 5 2017-2018 1stDocument7 pagesSyllabus Computer 5 2017-2018 1stSelegna YahcNo ratings yet
- Morales Corrected Lesson Plan 1Document11 pagesMorales Corrected Lesson Plan 1api-712929511No ratings yet
- Assignment Brief 1 (RQF) : Higher National Certificate/Diploma in ComputingDocument2 pagesAssignment Brief 1 (RQF) : Higher National Certificate/Diploma in ComputingNguyen Van Minh (FGW HN)No ratings yet
- CSF111 CP HandoutDocument3 pagesCSF111 CP HandoutPratik Kumar BeheraNo ratings yet
- PU Syllabus PDFDocument5 pagesPU Syllabus PDFCharitharthreddi VenumbakaNo ratings yet
- Predictive Analytics Exam-June 2021: Exam PA Home PageDocument10 pagesPredictive Analytics Exam-June 2021: Exam PA Home Pagehninyi theintNo ratings yet
- Significant Figures Homework WorksheetDocument6 pagesSignificant Figures Homework Worksheetfzj693s6100% (1)
- Step Standards 1-7 Elementary EducationDocument17 pagesStep Standards 1-7 Elementary Educationapi-524269323100% (1)
- MGT 212 - Spring 2024 - Course OutlineDocument3 pagesMGT 212 - Spring 2024 - Course OutlineShaon KhanNo ratings yet
- Design and Implementation of An Online Death and Birth Registration System PDFDocument20 pagesDesign and Implementation of An Online Death and Birth Registration System PDFLove ANo ratings yet
- Roll No Thapar University School of Humanities and Social Sciences Time: 3 Hours MM: 100 UHU00.5 Humanities For Engineers Instructions: Attempt AllDocument1 pageRoll No Thapar University School of Humanities and Social Sciences Time: 3 Hours MM: 100 UHU00.5 Humanities For Engineers Instructions: Attempt AllAnjam Jot SinghNo ratings yet
- Customer Relationship Management in Banking Sector: Problems and Challenges Dr. D.R. Bajwa Associate Professor Dept. of Commerce & Management Government P.G. College, Ambala Cantt, Haryana (India)Document14 pagesCustomer Relationship Management in Banking Sector: Problems and Challenges Dr. D.R. Bajwa Associate Professor Dept. of Commerce & Management Government P.G. College, Ambala Cantt, Haryana (India)MIKIYASNo ratings yet
- Yanmar Mini Excavator Vio25Document8 pagesYanmar Mini Excavator Vio25ashahulhjNo ratings yet
- Reserve Bank of IndiaDocument17 pagesReserve Bank of IndiaPrachi PatilNo ratings yet
- Gmail - Booking Confirmation On IRCTC, Train - 14005, 22-Sep-2022, SL, CPR - ANVTDocument1 pageGmail - Booking Confirmation On IRCTC, Train - 14005, 22-Sep-2022, SL, CPR - ANVT01. ABHINAV KANTINo ratings yet
- IAS Chapter 1 EditedDocument36 pagesIAS Chapter 1 Editedteshu wodesaNo ratings yet
- DD EPA04S60 ActuatorturboDocument5 pagesDD EPA04S60 ActuatorturboCuong DinhNo ratings yet
- Lect 09Document23 pagesLect 09Anvesh KadimiNo ratings yet
- Partial FractionsDocument8 pagesPartial FractionsEkaKurniawanNo ratings yet
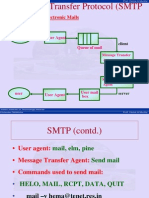
- Simple Mail Transfer Protocol (SMTP: Out Line of Internet Electronic MailsDocument15 pagesSimple Mail Transfer Protocol (SMTP: Out Line of Internet Electronic Mails23wingsNo ratings yet
- National Working Plan CodeDocument8 pagesNational Working Plan Codejunk mattum1No ratings yet
- ListDocument36 pagesListsldjadNo ratings yet
- Int J Hydrogen Energy 2004Document7 pagesInt J Hydrogen Energy 2004NicolásRipollKameidNo ratings yet
- Imds Newsletter 53Document4 pagesImds Newsletter 53taleshNo ratings yet
- WWW Techomsystems Com AuDocument7 pagesWWW Techomsystems Com Autechomsystems stemsNo ratings yet
- SBI Scholar Loan SchemeDocument2 pagesSBI Scholar Loan Schemekanv gulatiNo ratings yet
- Business Math Notes PDFDocument12 pagesBusiness Math Notes PDFCzareena Sulica DiamaNo ratings yet
- SBR Summary NotesDocument11 pagesSBR Summary NotesOzzNo ratings yet
- Architectural Design and Regulation - 05Document10 pagesArchitectural Design and Regulation - 05Yusron WitarsaNo ratings yet
- United States of America Ex Rel. Maria Horta v. John Deyoung, Warden Passaic County Jail, 523 F.2d 807, 3rd Cir. (1975)Document5 pagesUnited States of America Ex Rel. Maria Horta v. John Deyoung, Warden Passaic County Jail, 523 F.2d 807, 3rd Cir. (1975)Scribd Government DocsNo ratings yet
- OFB NagpurDocument3 pagesOFB NagpurArun KumarNo ratings yet
- IBF-ITF-Reederei NORD CBA 2012-2014 PDFDocument29 pagesIBF-ITF-Reederei NORD CBA 2012-2014 PDFGeorge TopoleanuNo ratings yet
- Decisions in Coca Cola and ABB Clears Mist Over Definition of Input Service'Document29 pagesDecisions in Coca Cola and ABB Clears Mist Over Definition of Input Service'Prashant KumarNo ratings yet
- Pranto CV 2021 UpDocument3 pagesPranto CV 2021 UpPranto Martin CruzeNo ratings yet
- HDR - WideColor in Final Cut ProDocument19 pagesHDR - WideColor in Final Cut Procarlo2610.coNo ratings yet
- Delivering Value Efficiently To The Customer IntroductionDocument5 pagesDelivering Value Efficiently To The Customer IntroductionJose Antonio Arancibia MarinNo ratings yet
- ACT - Driving License Appointments - Detailed AppointmentDocument3 pagesACT - Driving License Appointments - Detailed AppointmentVettri CezhiyanNo ratings yet
- GUNN DiodeDocument29 pagesGUNN DiodePriyanka DasNo ratings yet