Download as pdf or txt
You might also like
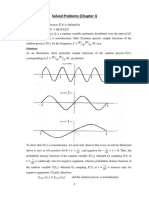
- Peter Bak in Cam Profile For Sony Cameras V2Document6 pagesPeter Bak in Cam Profile For Sony Cameras V2irfan syam100% (1)
- Install Elastix 4 On CentOS (VPS)Document4 pagesInstall Elastix 4 On CentOS (VPS)mahmoud nawwerNo ratings yet
- Social Issues and Professional Practice in It Syllabus (S.y. 2022-2023)Document7 pagesSocial Issues and Professional Practice in It Syllabus (S.y. 2022-2023)Mark Louise Pacis0% (1)
- FIN701 Kendall Summer 2020 AP1 AccessibleDocument9 pagesFIN701 Kendall Summer 2020 AP1 AccessibleMA RazaNo ratings yet
- Permutation Tests - FinalDocument19 pagesPermutation Tests - FinaleysNo ratings yet
- Lesson 2 Statistical InferenceDocument45 pagesLesson 2 Statistical InferencemaartenwildersNo ratings yet
- Module02 ANOVADocument28 pagesModule02 ANOVAasdfNo ratings yet
- Additional Notes 2 - Correlation and Stationary Time SeriesDocument7 pagesAdditional Notes 2 - Correlation and Stationary Time SeriesrheatrishasantosNo ratings yet
- Stochastic Process - IntroductionDocument16 pagesStochastic Process - IntroductionRajesh BathijaNo ratings yet
- Com Solved Proble4ms IDocument6 pagesCom Solved Proble4ms INatyBNo ratings yet
- SAHADEB - Logistic Reg - Sessions 8-10Document145 pagesSAHADEB - Logistic Reg - Sessions 8-10Writabrata BhattacharyaNo ratings yet
- Skew NessDocument13 pagesSkew NessBibek GaireNo ratings yet
- Formula SheetDocument7 pagesFormula SheetMohit RakyanNo ratings yet
- Module01 ProbabilityAndStatisticsDocument68 pagesModule01 ProbabilityAndStatisticsDevansh GuptaNo ratings yet
- Chapter 4: Probability Distributions: Discrete Random Variables Continuous Random VariablesDocument64 pagesChapter 4: Probability Distributions: Discrete Random Variables Continuous Random VariablesDaNo ratings yet
- Stats 2 NotesDocument17 pagesStats 2 Notesrachelmvaz99No ratings yet
- Class 12 Applied Mathematics Complete TheoryDocument15 pagesClass 12 Applied Mathematics Complete Theoryadwitanegi068No ratings yet
- Univariate Time Series Modelling and ForecastingDocument72 pagesUnivariate Time Series Modelling and Forecastingjamesburden100% (2)
- Measurement Techniques - Week 4Document19 pagesMeasurement Techniques - Week 4fhggdhdNo ratings yet
- 07 Fenton SimulationDocument52 pages07 Fenton SimulationAndres Pino100% (2)
- Controllability For A Wave Equation With Moving BoundaryDocument7 pagesControllability For A Wave Equation With Moving Boundary37 TANNUNo ratings yet
- Osobine VarDocument19 pagesOsobine Varenes_osmić_1No ratings yet
- Quality MidsemDocument179 pagesQuality MidsemHEMANTH KAJULURINo ratings yet
- Random Processes Sept 25 26 Oct 3 5Document53 pagesRandom Processes Sept 25 26 Oct 3 5Shravani KodeNo ratings yet
- 1.2 Discrete-Time Random Processes: 1.2.1 Sample Spaces and EventsDocument7 pages1.2 Discrete-Time Random Processes: 1.2.1 Sample Spaces and EventsÖmer Faruk DemirNo ratings yet
- I. Variational Formulation.: Student: Victor Pugliese R#: 11492336 Course: MATH 5345 Numerical Analysis Project 01Document6 pagesI. Variational Formulation.: Student: Victor Pugliese R#: 11492336 Course: MATH 5345 Numerical Analysis Project 01Victor Pugliese ManotasNo ratings yet
- Statistics Notes - Normal Distribution, Confidence Interval & Hypothesis TestingDocument2 pagesStatistics Notes - Normal Distribution, Confidence Interval & Hypothesis Testingwxc1252No ratings yet
- 12.probstat - Ch12-Tes Hipotesis 2Document45 pages12.probstat - Ch12-Tes Hipotesis 2misterNo ratings yet
- Lesson 8 The Poisson Probability DistributionDocument22 pagesLesson 8 The Poisson Probability DistributionLUMA-AS, Gerald P.No ratings yet
- Chapter 5 PDF Lecture NotesDocument56 pagesChapter 5 PDF Lecture NotesMostafa El HajjarNo ratings yet
- Solution Basic EconometricsDocument10 pagesSolution Basic EconometricsMadhav ।No ratings yet
- Httpswebeep - Polimi.itpluginfile - Php903867mod Foldercontent04.B20 20crystallization - Pdfforcedownload 1Document29 pagesHttpswebeep - Polimi.itpluginfile - Php903867mod Foldercontent04.B20 20crystallization - Pdfforcedownload 1Alfo PascaNo ratings yet
- Lecture PPT ProbabilityDocument16 pagesLecture PPT ProbabilityMohamed AlgilyNo ratings yet
- Sheet (2) (Basic Concepts of Measurements)Document3 pagesSheet (2) (Basic Concepts of Measurements)mohamed orifNo ratings yet
- Analysis of ResidualsDocument15 pagesAnalysis of ResidualsPayal shahNo ratings yet
- Lecture - 4 Box-Jenkins ModelDocument16 pagesLecture - 4 Box-Jenkins ModelNuur Ahmed100% (1)
- 72073931-8e00-4107-bdde-c19d4ec282cbDocument5 pages72073931-8e00-4107-bdde-c19d4ec282cbÖmer Faruk DemirNo ratings yet
- Chapter 10 Hypothesis TestingDocument10 pagesChapter 10 Hypothesis TestingMarie BtaichNo ratings yet
- Notes Formulas TestsDocument7 pagesNotes Formulas TestsGfdileonlineNo ratings yet
- Experimental Uncertainties (Errors)Document5 pagesExperimental Uncertainties (Errors)Stephen WilliamsNo ratings yet
- QuizDocument21 pagesQuizEko RudiawanNo ratings yet
- Linear Stationary ModelsDocument16 pagesLinear Stationary ModelsKaled AbodeNo ratings yet
- Stats101A - Chapter 2Document59 pagesStats101A - Chapter 2Zhen WangNo ratings yet
- Standard ScoresDocument26 pagesStandard ScoresJennie Mendoza0% (1)
- Lecture 8Document20 pagesLecture 8Krishnav SharmaNo ratings yet
- Chapter 7 PDF Lecture NotesDocument42 pagesChapter 7 PDF Lecture NotesMostafa El HajjarNo ratings yet
- Analisis Sistem Dinamis 1D: Ali KusnantoDocument108 pagesAnalisis Sistem Dinamis 1D: Ali KusnantoNafisah PutriNo ratings yet
- 統計摘要Document12 pages統計摘要harrison61704No ratings yet
- A Brief Introduction To Nonlinear Vibrations: 1 General CommentsDocument20 pagesA Brief Introduction To Nonlinear Vibrations: 1 General CommentsMjNo ratings yet
- An5087 PDFDocument9 pagesAn5087 PDFgottdammerNo ratings yet
- Statisctic ExcercisesDocument3 pagesStatisctic Excercisesnnanhnhi04No ratings yet
- Covariance & CorrelationDocument5 pagesCovariance & CorrelationMuhammad Saad UmarNo ratings yet
- Problem Set 9 WK30 Answers 2023-24Document7 pagesProblem Set 9 WK30 Answers 2023-24Soham AherNo ratings yet
- Chapter 3 - Variance Reduction MethodsDocument20 pagesChapter 3 - Variance Reduction MethodsCharbel MerhiNo ratings yet
- Empirical and Tchebysheff's TheoremDocument7 pagesEmpirical and Tchebysheff's TheoremLee Yee RunNo ratings yet
- 3lesson 2 Tests Involving The Population Mean 1Document14 pages3lesson 2 Tests Involving The Population Mean 1AzodNo ratings yet
- 0 C4 04Document39 pages0 C4 04Cartoon WorldNo ratings yet
- Chapters 8 (Part I) & 9 - PPTsDocument34 pagesChapters 8 (Part I) & 9 - PPTsKristine Joyce PortilloNo ratings yet
- Lecture 5: Statistical Inference by Dr. Javed IqbalDocument4 pagesLecture 5: Statistical Inference by Dr. Javed IqbalHamna AghaNo ratings yet
- DC PPT Unit 1Document23 pagesDC PPT Unit 1Sai Kumar RapetiNo ratings yet
- Math2101Stat 5Document23 pagesMath2101Stat 5iamtawhidhassanNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- ML LabDocument62 pagesML LabANJALI PATELNo ratings yet
- How To Install Encs On Furuno Ecdis-Step by Step GuideDocument22 pagesHow To Install Encs On Furuno Ecdis-Step by Step GuidePanagiotis Mouzenidis100% (1)
- 2018 Winter Question Paper (Msbte Study Resources)Document2 pages2018 Winter Question Paper (Msbte Study Resources)Rohit DevrukheNo ratings yet
- Syllabus - UNEP UNSIAP and UNITAR e Course On Environmental SDG IndicatorsDocument9 pagesSyllabus - UNEP UNSIAP and UNITAR e Course On Environmental SDG Indicatorsedmund carterNo ratings yet
- MES1428 2428 DatasheetDocument4 pagesMES1428 2428 Datasheetantonije44No ratings yet
- PP3 C917eDocument1,441 pagesPP3 C917ecarlos alves100% (1)
- Compal LA-4491P - LA-4495PDocument52 pagesCompal LA-4491P - LA-4495Pfirman firdausNo ratings yet
- Design Thinking Unit 2Document23 pagesDesign Thinking Unit 2Divyansh ChandraNo ratings yet
- Standard C++ IOStreams and LocalesDocument672 pagesStandard C++ IOStreams and LocaleszhaoxiaoyongNo ratings yet
- Tejaswini Nakkina ResumeDocument3 pagesTejaswini Nakkina Resumesivunimanasa01No ratings yet
- Cover Letter For Bank Customer ServiceDocument9 pagesCover Letter For Bank Customer Servicepkznbbifg100% (2)
- F3A 1 More About Factorization of PolynomialsDocument18 pagesF3A 1 More About Factorization of PolynomialsIsCチャーンNo ratings yet
- Ho30 - S7S - Tle-He - Sample SLRP TransferDocument17 pagesHo30 - S7S - Tle-He - Sample SLRP TransferCharish RebañoNo ratings yet
- UOM-IP Phone TroubleshootingDocument1 pageUOM-IP Phone TroubleshootingSL VineNo ratings yet
- Assignement # 1Document36 pagesAssignement # 1Rameez RajaNo ratings yet
- AWS Pricing Calculator PDFDocument1 pageAWS Pricing Calculator PDFBratescu StefanNo ratings yet
- Linear Time-Invariant Discrete-Time (LTID) System AnalysisDocument41 pagesLinear Time-Invariant Discrete-Time (LTID) System AnalysisDawood Najem SalehNo ratings yet
- Project Management AssignmentDocument22 pagesProject Management AssignmentYuSri88 ChannelNo ratings yet
- Ayush Jain Final 7th Sem Seminar ReportDocument33 pagesAyush Jain Final 7th Sem Seminar ReportKUSHAGRA JHUNJHUNWALANo ratings yet
- Abcd QzieDocument4 pagesAbcd QzieShreya AgrawalNo ratings yet
- DBMS Lab Week3Document2 pagesDBMS Lab Week3nawazNo ratings yet
- (BS EN 62271-3) - High-Voltage Switchgear and Controlgear. Part 3. Digital Interfaces Based On IEC 61850Document51 pages(BS EN 62271-3) - High-Voltage Switchgear and Controlgear. Part 3. Digital Interfaces Based On IEC 61850Leonardo DelgadoNo ratings yet
- Adams CarDocument1,068 pagesAdams CarJuan ClimentNo ratings yet
- Trouble Shooting Guide - 003Document71 pagesTrouble Shooting Guide - 003Cassiano Sponton PintoNo ratings yet
- Scans 124 ARFCN's Locks On To Best Searches For FCH Lock On To Next Best A Locks On To Next Best in BA ListDocument186 pagesScans 124 ARFCN's Locks On To Best Searches For FCH Lock On To Next Best A Locks On To Next Best in BA Listsegooo100% (1)
- Full Download Introduction To Mechanical Engineering Si Edition 4th Edition Wickert Solutions ManualDocument13 pagesFull Download Introduction To Mechanical Engineering Si Edition 4th Edition Wickert Solutions Manualirisybarrous100% (27)