
From Import: Image Image (Filename, Height, Width)
From Import: Image Image (Filename, Height, Width)
You might also like
- Food Delivery Time Prediction 1703681339Document8 pagesFood Delivery Time Prediction 1703681339Bhuvana Gopalam100% (1)
- IBT Practice Test Grade 6 MathsDocument6 pagesIBT Practice Test Grade 6 Mathsrsowmyasri100% (5)
- 1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyDocument50 pages1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyP Venkata Krishna Rao100% (19)
- PYC3704 Psychological Research Exam Questions and Answers: AdelesDocument168 pagesPYC3704 Psychological Research Exam Questions and Answers: AdelesOscar David67% (3)
- 024 Price and Everything PDFDocument12 pages024 Price and Everything PDFTman LetswaloNo ratings yet
- Jupyter Notebook Project DM Nikita Chaturvedi 25.07.2021Document83 pagesJupyter Notebook Project DM Nikita Chaturvedi 25.07.2021Nikita Chaturvedi100% (5)
- Hungerford Solution 6FIELDEXTDocument10 pagesHungerford Solution 6FIELDEXT23SquareNo ratings yet
- DataMiningProjectProblem1 ClusteringDocument20 pagesDataMiningProjectProblem1 ClusteringIndranil Das100% (4)
- Clustering Documentation R CodeDocument9 pagesClustering Documentation R Codenehal gundrapally100% (1)
- Process Modelling and Simulation - IntroductionDocument40 pagesProcess Modelling and Simulation - Introductiondppriya1984100% (3)
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- 02-Linear Regression Project - SolutionsDocument12 pages02-Linear Regression Project - SolutionsHellem BiersackNo ratings yet
- Data Mining - ProjectDocument11 pagesData Mining - Projectankitbhagat100% (2)
- Faseeh Chap 2 ReportDocument30 pagesFaseeh Chap 2 ReportSameer YounasNo ratings yet
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 pagesDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (2)
- Sklearn - Datasets Pandas PD Sklearn - Model - Selection Graphviz Sklearn - Datasets Sklearn Sklearn Sklearn - Metrics Sklearn - Metrics Sklearn - Preprocessing Sklearn - Tree SklearnDocument4 pagesSklearn - Datasets Pandas PD Sklearn - Model - Selection Graphviz Sklearn - Datasets Sklearn Sklearn Sklearn - Metrics Sklearn - Metrics Sklearn - Preprocessing Sklearn - Tree SklearnNguyen Trung ThinhNo ratings yet
- Analysing Ad BudgetDocument4 pagesAnalysing Ad BudgetSrikanth100% (1)
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- K Means AlgorithmDocument1 pageK Means AlgorithmROHAN G ANo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- Data SciDocument29 pagesData Sciketisi2987No ratings yet
- Sales Prediction Using PythonDocument6 pagesSales Prediction Using PythonSourabh YadavNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- 2Document5 pages2jeandanielflorestal70No ratings yet
- Python Assignment 1.ipynb - ColaboratoryDocument3 pagesPython Assignment 1.ipynb - ColaboratoryAmritaRupiniNo ratings yet
- Import As Import As Import AsDocument8 pagesImport As Import As Import AsDavid EsparzaArellanoNo ratings yet
- Churn For Bank CustomersDocument28 pagesChurn For Bank CustomersKrutika SapkalNo ratings yet
- Some Important Function of Pandas LibraryDocument24 pagesSome Important Function of Pandas LibraryRania DirarNo ratings yet
- ML Practical 1 CodeDocument1 pageML Practical 1 CodeC-34 Siddhesh Zajada100% (1)
- Know Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730Document1 pageKnow Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730SHANTI ROKKANo ratings yet
- Loading The Dataset: First We Load The Dataset and Find Out The Number of Columns, Rows, NULL Values, EtcDocument8 pagesLoading The Dataset: First We Load The Dataset and Find Out The Number of Columns, Rows, NULL Values, EtcDivyani Chavan100% (1)
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- ModelDocument164 pagesModelSanjayNo ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- Ash 4Document8 pagesAsh 4saurabhbborate0621No ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- Vietnam DX SaaS Landscape 2022 enDocument32 pagesVietnam DX SaaS Landscape 2022 enLinh Nguyễn VănNo ratings yet
- DV 9Document11 pagesDV 9Anish NayakNo ratings yet
- Country - Data (Record) - Jupyter NotebookDocument5 pagesCountry - Data (Record) - Jupyter Notebookpragyaparik16No ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Linear Regression (Cellphone - Prices)Document14 pagesLinear Regression (Cellphone - Prices)Ali YaqoobNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- TrabajoDocument5 pagesTrabajoJAVIER OCHOANo ratings yet
- Clustering - Jupyter NotebookDocument11 pagesClustering - Jupyter Notebookreema dsouza100% (1)
- Data Analysis With Python - Jupyter NotebookDocument10 pagesData Analysis With Python - Jupyter NotebookNitish RavuvariNo ratings yet
- DL RecordDocument37 pagesDL RecordNAWAS HussainNo ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- 6 XG Boost - Jupyter NotebookDocument3 pages6 XG Boost - Jupyter Notebookvenkatesh m100% (1)
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Load Dataset: Import AsDocument8 pagesLoad Dataset: Import AsZESTYNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- Assumption of Linear RegressionDocument6 pagesAssumption of Linear RegressionKagade AjinkyaNo ratings yet
- Intro To PandasDocument7 pagesIntro To PandasThe path to AllahNo ratings yet
- Importing Libraries and Loading Data: Import As Import As Import As Import As From ImportDocument13 pagesImporting Libraries and Loading Data: Import As Import As Import As Import As From Importuchiha itachNo ratings yet
- 1233Document4 pages1233Pendu JattNo ratings yet
- Prepared by Asif Bhat Exploratory Data Analysis: Explore DatasetDocument143 pagesPrepared by Asif Bhat Exploratory Data Analysis: Explore DatasetrealtluuNo ratings yet
- Linear and Multilinear RegressionDocument5 pagesLinear and Multilinear RegressionHarisankar R N RNo ratings yet
- KMeans Clustering Bidimensional Daniel Ames CamayoDocument15 pagesKMeans Clustering Bidimensional Daniel Ames CamayoEl RusnderNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- Multi-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignFrom EverandMulti-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignNo ratings yet
- Introduction To Clustering: From ImportDocument3 pagesIntroduction To Clustering: From ImportTrishala KumariNo ratings yet
- From Import: Image Image (Filename, Height, Width)Document5 pagesFrom Import: Image Image (Filename, Height, Width)Trishala KumariNo ratings yet
- Activity-1: Student Name USNDocument16 pagesActivity-1: Student Name USNTrishala KumariNo ratings yet
- Map Reduce ReportDocument16 pagesMap Reduce ReportTrishala KumariNo ratings yet
- Jss Academy of Technical Education: MultithreadingDocument11 pagesJss Academy of Technical Education: MultithreadingTrishala KumariNo ratings yet
- Lecture 11Document29 pagesLecture 11ahsan puriNo ratings yet
- Proyecto Andres 2Document25 pagesProyecto Andres 2anjibeNo ratings yet
- One-Repetition Maximum: Calculating Approximate 1RMDocument3 pagesOne-Repetition Maximum: Calculating Approximate 1RMkarzinom100% (1)
- A Novel Coupled Optimization Prediction Model For Air QualityDocument19 pagesA Novel Coupled Optimization Prediction Model For Air QualityFresy NugrohoNo ratings yet
- Kane & Mertz - Debunking Myths About Gender and Mathematics PerformanceDocument12 pagesKane & Mertz - Debunking Myths About Gender and Mathematics Performancemorganlo_at_ubNo ratings yet
- Using Scientific MethodsDocument2 pagesUsing Scientific MethodsReynaPolNo ratings yet
- Hydrogen Spectrum Lab Student SheetDocument4 pagesHydrogen Spectrum Lab Student Sheets bNo ratings yet
- Answers PHDocument325 pagesAnswers PHbob petersNo ratings yet
- Floatation and Upending AnalysisDocument7 pagesFloatation and Upending AnalysisAbdul Hamid HamatNo ratings yet
- Reliability Indices For Road Geometric DesignDocument7 pagesReliability Indices For Road Geometric DesignyoukesiNo ratings yet
- LPP FormulationDocument16 pagesLPP FormulationLalit SapkaleNo ratings yet
- Process Capability Index (CPK)Document5 pagesProcess Capability Index (CPK)lovlinNo ratings yet
- Cambridge Secondary 1 CheckpointDocument12 pagesCambridge Secondary 1 CheckpointF1yguy4No ratings yet
- ECON6001 F2021 Topic4Document76 pagesECON6001 F2021 Topic4zxyNo ratings yet
- Analysis of Corrugated Web Beam To Column Extended End Plate Connection UsingDocument75 pagesAnalysis of Corrugated Web Beam To Column Extended End Plate Connection UsingLina Lina LoulouNo ratings yet
- Mintzberg's Managerial Roles Role Description Examples of Identifiable Activities FigureheadDocument27 pagesMintzberg's Managerial Roles Role Description Examples of Identifiable Activities Figureheadpanchtani100% (1)
- Circle Theorem TipsDocument2 pagesCircle Theorem TipsAntwayne Hardie60% (5)
- Chapter 4 Part 2 - Truss Method of SectionsDocument17 pagesChapter 4 Part 2 - Truss Method of SectionsLyzette LeanderNo ratings yet
- S. Chand's Catalogue On Higher Academic Books 2010-11Document176 pagesS. Chand's Catalogue On Higher Academic Books 2010-11akumar_277100% (1)
- Adaptive Feature Extraction For EEG Signal Classification: &) Æ C. ZhangDocument5 pagesAdaptive Feature Extraction For EEG Signal Classification: &) Æ C. ZhangADARSH OJHANo ratings yet
- Water WheelDocument4 pagesWater WheelSivanesan KupusamyNo ratings yet
- Probably The Most Probable: Discrete Probability DistributionsDocument1 pageProbably The Most Probable: Discrete Probability DistributionsJohn RoaNo ratings yet
- Set 3Document3 pagesSet 3murthy0% (2)
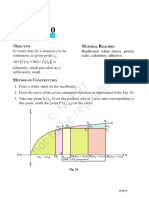
- Activity 10: Hardboard, White Sheets, Pencil, Scale, Calculator, AdhesiveDocument3 pagesActivity 10: Hardboard, White Sheets, Pencil, Scale, Calculator, AdhesiveSudhanshu singh XIl-ANo ratings yet
- 400 - Lecture 8 ProblemsDocument6 pages400 - Lecture 8 Problemslasha mashaNo ratings yet
- IMT Preparation Guide PGE 2017Document6 pagesIMT Preparation Guide PGE 2017Miguel Esteban MartinezNo ratings yet





























































































Download as pdf or txt
You might also like
- Food Delivery Time Prediction 1703681339Document8 pagesFood Delivery Time Prediction 1703681339Bhuvana Gopalam100% (1)
- IBT Practice Test Grade 6 MathsDocument6 pagesIBT Practice Test Grade 6 Mathsrsowmyasri100% (5)
- 1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyDocument50 pages1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyP Venkata Krishna Rao100% (19)
- PYC3704 Psychological Research Exam Questions and Answers: AdelesDocument168 pagesPYC3704 Psychological Research Exam Questions and Answers: AdelesOscar David67% (3)
- 024 Price and Everything PDFDocument12 pages024 Price and Everything PDFTman LetswaloNo ratings yet
- Jupyter Notebook Project DM Nikita Chaturvedi 25.07.2021Document83 pagesJupyter Notebook Project DM Nikita Chaturvedi 25.07.2021Nikita Chaturvedi100% (5)
- Hungerford Solution 6FIELDEXTDocument10 pagesHungerford Solution 6FIELDEXT23SquareNo ratings yet
- DataMiningProjectProblem1 ClusteringDocument20 pagesDataMiningProjectProblem1 ClusteringIndranil Das100% (4)
- Clustering Documentation R CodeDocument9 pagesClustering Documentation R Codenehal gundrapally100% (1)
- Process Modelling and Simulation - IntroductionDocument40 pagesProcess Modelling and Simulation - Introductiondppriya1984100% (3)
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- 02-Linear Regression Project - SolutionsDocument12 pages02-Linear Regression Project - SolutionsHellem BiersackNo ratings yet
- Data Mining - ProjectDocument11 pagesData Mining - Projectankitbhagat100% (2)
- Faseeh Chap 2 ReportDocument30 pagesFaseeh Chap 2 ReportSameer YounasNo ratings yet
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 pagesDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (2)
- Sklearn - Datasets Pandas PD Sklearn - Model - Selection Graphviz Sklearn - Datasets Sklearn Sklearn Sklearn - Metrics Sklearn - Metrics Sklearn - Preprocessing Sklearn - Tree SklearnDocument4 pagesSklearn - Datasets Pandas PD Sklearn - Model - Selection Graphviz Sklearn - Datasets Sklearn Sklearn Sklearn - Metrics Sklearn - Metrics Sklearn - Preprocessing Sklearn - Tree SklearnNguyen Trung ThinhNo ratings yet
- Analysing Ad BudgetDocument4 pagesAnalysing Ad BudgetSrikanth100% (1)
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- K Means AlgorithmDocument1 pageK Means AlgorithmROHAN G ANo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- Data SciDocument29 pagesData Sciketisi2987No ratings yet
- Sales Prediction Using PythonDocument6 pagesSales Prediction Using PythonSourabh YadavNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- 2Document5 pages2jeandanielflorestal70No ratings yet
- Python Assignment 1.ipynb - ColaboratoryDocument3 pagesPython Assignment 1.ipynb - ColaboratoryAmritaRupiniNo ratings yet
- Import As Import As Import AsDocument8 pagesImport As Import As Import AsDavid EsparzaArellanoNo ratings yet
- Churn For Bank CustomersDocument28 pagesChurn For Bank CustomersKrutika SapkalNo ratings yet
- Some Important Function of Pandas LibraryDocument24 pagesSome Important Function of Pandas LibraryRania DirarNo ratings yet
- ML Practical 1 CodeDocument1 pageML Practical 1 CodeC-34 Siddhesh Zajada100% (1)
- Know Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730Document1 pageKnow Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730SHANTI ROKKANo ratings yet
- Loading The Dataset: First We Load The Dataset and Find Out The Number of Columns, Rows, NULL Values, EtcDocument8 pagesLoading The Dataset: First We Load The Dataset and Find Out The Number of Columns, Rows, NULL Values, EtcDivyani Chavan100% (1)
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- ModelDocument164 pagesModelSanjayNo ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- Ash 4Document8 pagesAsh 4saurabhbborate0621No ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- Vietnam DX SaaS Landscape 2022 enDocument32 pagesVietnam DX SaaS Landscape 2022 enLinh Nguyễn VănNo ratings yet
- DV 9Document11 pagesDV 9Anish NayakNo ratings yet
- Country - Data (Record) - Jupyter NotebookDocument5 pagesCountry - Data (Record) - Jupyter Notebookpragyaparik16No ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Linear Regression (Cellphone - Prices)Document14 pagesLinear Regression (Cellphone - Prices)Ali YaqoobNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- TrabajoDocument5 pagesTrabajoJAVIER OCHOANo ratings yet
- Clustering - Jupyter NotebookDocument11 pagesClustering - Jupyter Notebookreema dsouza100% (1)
- Data Analysis With Python - Jupyter NotebookDocument10 pagesData Analysis With Python - Jupyter NotebookNitish RavuvariNo ratings yet
- DL RecordDocument37 pagesDL RecordNAWAS HussainNo ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- 6 XG Boost - Jupyter NotebookDocument3 pages6 XG Boost - Jupyter Notebookvenkatesh m100% (1)
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Load Dataset: Import AsDocument8 pagesLoad Dataset: Import AsZESTYNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- Assumption of Linear RegressionDocument6 pagesAssumption of Linear RegressionKagade AjinkyaNo ratings yet
- Intro To PandasDocument7 pagesIntro To PandasThe path to AllahNo ratings yet
- Importing Libraries and Loading Data: Import As Import As Import As Import As From ImportDocument13 pagesImporting Libraries and Loading Data: Import As Import As Import As Import As From Importuchiha itachNo ratings yet
- 1233Document4 pages1233Pendu JattNo ratings yet
- Prepared by Asif Bhat Exploratory Data Analysis: Explore DatasetDocument143 pagesPrepared by Asif Bhat Exploratory Data Analysis: Explore DatasetrealtluuNo ratings yet
- Linear and Multilinear RegressionDocument5 pagesLinear and Multilinear RegressionHarisankar R N RNo ratings yet
- KMeans Clustering Bidimensional Daniel Ames CamayoDocument15 pagesKMeans Clustering Bidimensional Daniel Ames CamayoEl RusnderNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- Multi-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignFrom EverandMulti-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignNo ratings yet
- Introduction To Clustering: From ImportDocument3 pagesIntroduction To Clustering: From ImportTrishala KumariNo ratings yet
- From Import: Image Image (Filename, Height, Width)Document5 pagesFrom Import: Image Image (Filename, Height, Width)Trishala KumariNo ratings yet
- Activity-1: Student Name USNDocument16 pagesActivity-1: Student Name USNTrishala KumariNo ratings yet
- Map Reduce ReportDocument16 pagesMap Reduce ReportTrishala KumariNo ratings yet
- Jss Academy of Technical Education: MultithreadingDocument11 pagesJss Academy of Technical Education: MultithreadingTrishala KumariNo ratings yet
- Lecture 11Document29 pagesLecture 11ahsan puriNo ratings yet
- Proyecto Andres 2Document25 pagesProyecto Andres 2anjibeNo ratings yet
- One-Repetition Maximum: Calculating Approximate 1RMDocument3 pagesOne-Repetition Maximum: Calculating Approximate 1RMkarzinom100% (1)
- A Novel Coupled Optimization Prediction Model For Air QualityDocument19 pagesA Novel Coupled Optimization Prediction Model For Air QualityFresy NugrohoNo ratings yet
- Kane & Mertz - Debunking Myths About Gender and Mathematics PerformanceDocument12 pagesKane & Mertz - Debunking Myths About Gender and Mathematics Performancemorganlo_at_ubNo ratings yet
- Using Scientific MethodsDocument2 pagesUsing Scientific MethodsReynaPolNo ratings yet
- Hydrogen Spectrum Lab Student SheetDocument4 pagesHydrogen Spectrum Lab Student Sheets bNo ratings yet
- Answers PHDocument325 pagesAnswers PHbob petersNo ratings yet
- Floatation and Upending AnalysisDocument7 pagesFloatation and Upending AnalysisAbdul Hamid HamatNo ratings yet
- Reliability Indices For Road Geometric DesignDocument7 pagesReliability Indices For Road Geometric DesignyoukesiNo ratings yet
- LPP FormulationDocument16 pagesLPP FormulationLalit SapkaleNo ratings yet
- Process Capability Index (CPK)Document5 pagesProcess Capability Index (CPK)lovlinNo ratings yet
- Cambridge Secondary 1 CheckpointDocument12 pagesCambridge Secondary 1 CheckpointF1yguy4No ratings yet
- ECON6001 F2021 Topic4Document76 pagesECON6001 F2021 Topic4zxyNo ratings yet
- Analysis of Corrugated Web Beam To Column Extended End Plate Connection UsingDocument75 pagesAnalysis of Corrugated Web Beam To Column Extended End Plate Connection UsingLina Lina LoulouNo ratings yet
- Mintzberg's Managerial Roles Role Description Examples of Identifiable Activities FigureheadDocument27 pagesMintzberg's Managerial Roles Role Description Examples of Identifiable Activities Figureheadpanchtani100% (1)
- Circle Theorem TipsDocument2 pagesCircle Theorem TipsAntwayne Hardie60% (5)
- Chapter 4 Part 2 - Truss Method of SectionsDocument17 pagesChapter 4 Part 2 - Truss Method of SectionsLyzette LeanderNo ratings yet
- S. Chand's Catalogue On Higher Academic Books 2010-11Document176 pagesS. Chand's Catalogue On Higher Academic Books 2010-11akumar_277100% (1)
- Adaptive Feature Extraction For EEG Signal Classification: &) Æ C. ZhangDocument5 pagesAdaptive Feature Extraction For EEG Signal Classification: &) Æ C. ZhangADARSH OJHANo ratings yet
- Water WheelDocument4 pagesWater WheelSivanesan KupusamyNo ratings yet
- Probably The Most Probable: Discrete Probability DistributionsDocument1 pageProbably The Most Probable: Discrete Probability DistributionsJohn RoaNo ratings yet
- Set 3Document3 pagesSet 3murthy0% (2)
- Activity 10: Hardboard, White Sheets, Pencil, Scale, Calculator, AdhesiveDocument3 pagesActivity 10: Hardboard, White Sheets, Pencil, Scale, Calculator, AdhesiveSudhanshu singh XIl-ANo ratings yet
- 400 - Lecture 8 ProblemsDocument6 pages400 - Lecture 8 Problemslasha mashaNo ratings yet
- IMT Preparation Guide PGE 2017Document6 pagesIMT Preparation Guide PGE 2017Miguel Esteban MartinezNo ratings yet