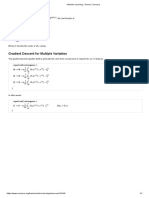
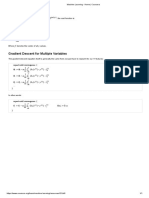
Download as pdf or txt
You might also like
- Machine Learning - Home - Coursera Quiz PDFDocument5 pagesMachine Learning - Home - Coursera Quiz PDFMary Peace100% (1)
- CS 229, Public Course Problem Set #1 Solutions: Supervised LearningDocument10 pagesCS 229, Public Course Problem Set #1 Solutions: Supervised Learningsuhar adiNo ratings yet
- Linear RegressionDocument75 pagesLinear RegressionAaqib InamNo ratings yet
- ML, WK 04-Questions With AnswersDocument4 pagesML, WK 04-Questions With AnswersravinyseNo ratings yet
- AC-ED L03 - RegressionDocument83 pagesAC-ED L03 - RegressionAbel EspinNo ratings yet
- 7 PDFDocument1 page7 PDFLaith BounenniNo ratings yet
- 7 PDFDocument1 page7 PDFLaith BounenniNo ratings yet
- NotesDocument8 pagesNotes박이삭No ratings yet
- Machine Learning - Home - Week 2 - Notes - CourseraDocument10 pagesMachine Learning - Home - Week 2 - Notes - CourseracopsamostoNo ratings yet
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- ML Lec 4Document38 pagesML Lec 4Saqlain ArshadNo ratings yet
- AC-ED L04 - Logistic Regression, RegularizationDocument80 pagesAC-ED L04 - Logistic Regression, RegularizationAbel EspinNo ratings yet
- Notes 3Document59 pagesNotes 3Nikita AggarwalNo ratings yet
- HW1Document4 pagesHW1sun_917443954No ratings yet
- Proba GRP 5Document8 pagesProba GRP 5damasdaniel653No ratings yet
- cs229 Notes3Document30 pagescs229 Notes3hoangNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- Simula CH 5Document8 pagesSimula CH 5Hussein Turi HtgNo ratings yet
- Lange TalkDocument40 pagesLange Talksanka csaatNo ratings yet
- 40 LogisticRegression-1Document2 pages40 LogisticRegression-1Abderrahmane KraiouchNo ratings yet
- Practice Problems Set 2Document5 pagesPractice Problems Set 2kahmad6266No ratings yet
- Logistic RegressionDocument25 pagesLogistic Regressionshahmed6646No ratings yet
- ML Week 4 To 10 PDFDocument146 pagesML Week 4 To 10 PDFdcs sfscollegeNo ratings yet
- Department of Electrical Engineering School of Science and Engineering EE514/CS535 Machine Learning Homework 1Document11 pagesDepartment of Electrical Engineering School of Science and Engineering EE514/CS535 Machine Learning Homework 1Muhammad HusnainNo ratings yet
- Applied Machine Learning: One Variable (Simple) Linear RegressionDocument38 pagesApplied Machine Learning: One Variable (Simple) Linear RegressionWanida KrataeNo ratings yet
- Digital Image Processing - Sampling TheoryDocument56 pagesDigital Image Processing - Sampling TheoryLong Đặng HoàngNo ratings yet
- APP2Document3 pagesAPP2Dayana JimenezNo ratings yet
- Note 4: EECS 189 Introduction To Machine Learning Fall 2020 1 MLE and MAP For Regression (Part I)Document6 pagesNote 4: EECS 189 Introduction To Machine Learning Fall 2020 1 MLE and MAP For Regression (Part I)Rohan DebNo ratings yet
- Ass 1Document3 pagesAss 1Vibhanshu LodhiNo ratings yet
- Affine Processes and Applications in Finance: (With D. Duffie and W. Schachermayer)Document25 pagesAffine Processes and Applications in Finance: (With D. Duffie and W. Schachermayer)karasa1No ratings yet
- Linearization TheoriesDocument174 pagesLinearization Theoriessafeer_siddickyNo ratings yet
- Gradient Descent and SGDDocument8 pagesGradient Descent and SGDROHIT ARORANo ratings yet
- Lecture14 LogisticDocument25 pagesLecture14 Logisticmohammed.elbakkalielammariNo ratings yet
- Sample Research PaperDocument26 pagesSample Research Paperfb8ndyffmcNo ratings yet
- Linear RegressionDocument51 pagesLinear RegressionKunal Langer100% (1)
- Problem Set 8Document5 pagesProblem Set 8clouds lauNo ratings yet
- Assignment 1Document4 pagesAssignment 1PAPANo ratings yet
- 16.323 Principles of Optimal Control: Mit OpencoursewareDocument24 pages16.323 Principles of Optimal Control: Mit OpencoursewareTomas SalmoiraghiNo ratings yet
- Ps 1Document5 pagesPs 1Emre UysalNo ratings yet
- Foundations of Deep LearningDocument30 pagesFoundations of Deep LearningNelson Ubaldo Quispe MNo ratings yet
- Lecture Notes On Nonparametric AnalysisDocument99 pagesLecture Notes On Nonparametric AnalysisquanduchungNo ratings yet
- Lecture 14 Functional Linear ModelsDocument12 pagesLecture 14 Functional Linear Modelsljz302660107No ratings yet
- Neural NetworkDocument6 pagesNeural NetworkToshinari TongNo ratings yet
- SVM Dual Problem ProofDocument2 pagesSVM Dual Problem ProofSat AdhaNo ratings yet
- 1551 FinalExam ProblemBankDocument12 pages1551 FinalExam ProblemBankPedro TNo ratings yet
- 8.2 Convolución GráficaDocument42 pages8.2 Convolución GráficaAlvaro Pardo SandovalNo ratings yet
- Taller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoDocument8 pagesTaller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoangieNo ratings yet
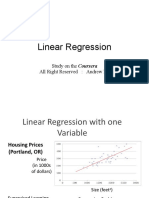
- Linear Regression: Study On The Coursera All Right Reserved: Andrew NGDocument29 pagesLinear Regression: Study On The Coursera All Right Reserved: Andrew NGRabbia KhalidNo ratings yet
- A Short Report On MATLAB Implementation of The Girsanov Transformation For Reliability AnalysisDocument8 pagesA Short Report On MATLAB Implementation of The Girsanov Transformation For Reliability AnalysisYoung EngineerNo ratings yet
- Sam HW2Document4 pagesSam HW2Ali HassanNo ratings yet
- Cost FunctionDocument17 pagesCost Functionjuanka82No ratings yet
- 189 Cheat Sheet MinicardsDocument2 pages189 Cheat Sheet Minicardst rex422No ratings yet
- Lec8 PDFDocument5 pagesLec8 PDFjuanagallardo01No ratings yet
- Jacobian MethodsDocument23 pagesJacobian MethodsOdhieNo ratings yet
- Sol Advriskmin 3Document4 pagesSol Advriskmin 3toluei.s29No ratings yet
- Lab Report #1: Transient Stability Analysis For Single Machine Infinite Bus Bar Using MATLABDocument5 pagesLab Report #1: Transient Stability Analysis For Single Machine Infinite Bus Bar Using MATLABIjaz Ahmad0% (1)
- Lec 3Document22 pagesLec 3mohammed.elbakkalielammariNo ratings yet
- Class XII - Math Chapter: Differential Calculus: X C X C +Document5 pagesClass XII - Math Chapter: Differential Calculus: X C X C +sudha.kriNo ratings yet
- 04 Logistic RegressionDocument46 pages04 Logistic RegressionKHUSHI JAINNo ratings yet
- CGP 11 Module7Document6 pagesCGP 11 Module7ElmcioencinaNo ratings yet
- Cambridge O Level: Arabic 3180/02 May/June 2021Document15 pagesCambridge O Level: Arabic 3180/02 May/June 2021Mohammed AbouelhassanNo ratings yet
- Artificial Intelligence Application in Bone Fracture DetectionDocument6 pagesArtificial Intelligence Application in Bone Fracture DetectionMEHDI JAHANIRADNo ratings yet
- 1.article Hamdaoui 2016 ScopusDocument8 pages1.article Hamdaoui 2016 Scopussimsim HamdaouiNo ratings yet
- Omkar Pokalekar 3 Sem ResultDocument1 pageOmkar Pokalekar 3 Sem ResultomssNo ratings yet
- PUMaC2013 NumberTheoryBSolDocument3 pagesPUMaC2013 NumberTheoryBSolau auNo ratings yet
- Refleks ArcsDocument34 pagesRefleks Arcskiedd_04100% (1)
- Ap Exam Instructions Human Geography 2016 PDFDocument5 pagesAp Exam Instructions Human Geography 2016 PDFHojung YiNo ratings yet
- End of Term Test - 6a10Document4 pagesEnd of Term Test - 6a10Đinh Nguyệt HàNo ratings yet
- Validating The DiFluid R2 Extract (Quantitative Café)Document2 pagesValidating The DiFluid R2 Extract (Quantitative Café)Bryan FonsecaNo ratings yet
- Write A Report To Analyse The Key Factors Which Drive GlobalizationDocument7 pagesWrite A Report To Analyse The Key Factors Which Drive GlobalizationChúc Linh Đặng ThịNo ratings yet
- Ec3361-Edc Lab ManualDocument47 pagesEc3361-Edc Lab ManualperiyasamyNo ratings yet
- Purlins ManualDocument104 pagesPurlins ManualPhilip WalkerNo ratings yet
- Makalah B.inggris Kelompok 5Document9 pagesMakalah B.inggris Kelompok 5antoniNo ratings yet
- Chapter 17: Interventions For Thinking (2) 290 - 309Document5 pagesChapter 17: Interventions For Thinking (2) 290 - 309Sofea JaafarNo ratings yet
- Solid Liquid Filtration and Separation Technology - 1996 - Rushton - Appendix A Particle Size Shape and SizeDocument15 pagesSolid Liquid Filtration and Separation Technology - 1996 - Rushton - Appendix A Particle Size Shape and SizeDevpriy sahuNo ratings yet
- g9 System of Quadratic Equation.Document15 pagesg9 System of Quadratic Equation.Dorothy Julia Dela CruzNo ratings yet
- EOT Crane Mechanical Equipment Calculation 1Document17 pagesEOT Crane Mechanical Equipment Calculation 1satendra sharmaNo ratings yet
- MSDS NaOH 0.1 NDocument5 pagesMSDS NaOH 0.1 NYoga Maulana RahmanNo ratings yet
- CH 1 PDFDocument14 pagesCH 1 PDFShaurya DeorajNo ratings yet
- Lesson 4Document28 pagesLesson 4Manuel SapaoNo ratings yet
- Original Paper LinkDocument3 pagesOriginal Paper LinkVinus yaduvanshiNo ratings yet
- Evs Bibliography 1Document9 pagesEvs Bibliography 1Unnati NihalaniNo ratings yet
- Tactful Diplomatic Email ExamplesDocument7 pagesTactful Diplomatic Email ExamplesdufangrongNo ratings yet
- Compare The Following Startling Discrepancies (Surveyor)Document3 pagesCompare The Following Startling Discrepancies (Surveyor)tjmigoto@hotmail.comNo ratings yet
- Int J Consumer Studies - 2020 - Rebou As - Voluntary Simplicity A Literature Review and Research AgendaDocument17 pagesInt J Consumer Studies - 2020 - Rebou As - Voluntary Simplicity A Literature Review and Research AgendaSana IrfanNo ratings yet
- Grade 9 Notes Logic GateDocument10 pagesGrade 9 Notes Logic GateButterfly HuexNo ratings yet
- Mud Density Lab Report 1Document11 pagesMud Density Lab Report 1kurddoski2880% (5)
- Ottery Field - A History and Current Perspective070221Document20 pagesOttery Field - A History and Current Perspective070221Michael RiffelNo ratings yet
- Metal X: 85 School ST, Watertown, MA 02472 All Specifications Approximate and Subject To Change Without NoticeDocument1 pageMetal X: 85 School ST, Watertown, MA 02472 All Specifications Approximate and Subject To Change Without NoticeKKK BitchNo ratings yet