
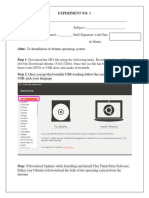
$ Python - Version: Hint: You Can Exit An Interactive Python Environment by Entering
$ Python - Version: Hint: You Can Exit An Interactive Python Environment by Entering
You might also like
- If You Are Preparing For Interviews For Linux Admin Jobs You Should Be Familiar With Below Concepts.Document54 pagesIf You Are Preparing For Interviews For Linux Admin Jobs You Should Be Familiar With Below Concepts.Praveen Raj Thakur83% (6)
- Homework 3Document4 pagesHomework 3Jenny MatuteNo ratings yet
- CNIOT Lab AssignmentDocument7 pagesCNIOT Lab Assignmentishidhim17No ratings yet
- Introduction To LINUX OS: ObjectivesDocument68 pagesIntroduction To LINUX OS: ObjectivesVeerubglrKumarNo ratings yet
- Linux Programming SolutionDocument28 pagesLinux Programming Solutionamaankazi1793No ratings yet
- OS ManualDocument26 pagesOS ManualSakshi GoleNo ratings yet
- Linux Interview Question_AnswersDocument39 pagesLinux Interview Question_Answersravi_kishore21No ratings yet
- Linux Adminnn 5Document43 pagesLinux Adminnn 5chaits258No ratings yet
- AnywayDocument116 pagesAnywayAnonymous nzfEotriWKNo ratings yet
- 10 Lab Manual Basic Linux CommandsDocument16 pages10 Lab Manual Basic Linux Commandsharin9079No ratings yet
- Os Lab ManualDocument98 pagesOs Lab ManualSai KumarNo ratings yet
- Linux Interview QuestionsDocument23 pagesLinux Interview QuestionsAshish Yadav100% (1)
- Operating System LAb 1Document7 pagesOperating System LAb 1ajnobi hueseNo ratings yet
- OS_lab_manual_PPPDocument41 pagesOS_lab_manual_PPPvidya maliNo ratings yet
- Iitdelhi Lab AssignmentDocument4 pagesIitdelhi Lab AssignmentNitishkumarreddyervaNo ratings yet
- LinuxDocument89 pagesLinuxC Rithin ChakravarthyNo ratings yet
- Os Lab Manual FinalDocument17 pagesOs Lab Manual FinalMubaraka KundawalaNo ratings yet
- Lab Manual: Internet of Things Lab (7CS4-21)Document37 pagesLab Manual: Internet of Things Lab (7CS4-21)Abhishek NairNo ratings yet
- Linux Admin 5Document44 pagesLinux Admin 5chaits258No ratings yet
- Os Lab ManualDocument37 pagesOs Lab ManualJASPER WESSLYNo ratings yet
- Unix Interview QuestionsDocument6 pagesUnix Interview QuestionsOmkar Rayapeddi100% (1)
- Os Lab Manual-1Document65 pagesOs Lab Manual-1diranj0% (1)
- Linux Admin QuestionsDocument44 pagesLinux Admin Questionschaits258No ratings yet
- IntroDocument4 pagesIntroVinod SolankeNo ratings yet
- Linux Interview Questions and AnswersDocument11 pagesLinux Interview Questions and Answersdillip21100% (1)
- Top 50 Raspberry Pi Commands List Cheat SheetDocument4 pagesTop 50 Raspberry Pi Commands List Cheat SheetYassin EzzNo ratings yet
- Linux LabDocument37 pagesLinux Labsrilakshmi nageshNo ratings yet
- Answers To Even-Numbered Exercises: From Page 1077Document7 pagesAnswers To Even-Numbered Exercises: From Page 1077Mark HoldenNo ratings yet
- Linux Privilege EscalationDocument17 pagesLinux Privilege Escalationilykillit325No ratings yet
- Operating System LabDocument33 pagesOperating System LabCasey MoralesNo ratings yet
- OS LabsDocument63 pagesOS Labsroman naeemNo ratings yet
- Linux Admin Interview QuestionsDocument4 pagesLinux Admin Interview Questionsapi-3780913No ratings yet
- Linux AdminDocument44 pagesLinux Adminchaits258No ratings yet
- Nixes and IntDocument43 pagesNixes and Intchaits258No ratings yet
- Interview Questions2Document3 pagesInterview Questions2sandeep.hasa775No ratings yet
- Simple ShellDocument8 pagesSimple ShellBrian MutembeiNo ratings yet
- ACTION Lab HPC Install MannulDocument10 pagesACTION Lab HPC Install MannulMandoiu StefanNo ratings yet
- OS Assign1Document3 pagesOS Assign1anon_608090223No ratings yet
- Os LabDocument63 pagesOs LabsuriyakrishnanNo ratings yet
- Unix Programming and Compiler DesignDocument68 pagesUnix Programming and Compiler DesignRaghu GowdaNo ratings yet
- Linux Admin 4Document44 pagesLinux Admin 4chaits258No ratings yet
- Tutorial 0Document10 pagesTutorial 0wwpretty faceNo ratings yet
- My Linux CommandsDocument5 pagesMy Linux CommandsMorgan KisienyaNo ratings yet
- UnixDocument11 pagesUnixffrakeshNo ratings yet
- Linux Admin Interview QuestionsDocument7 pagesLinux Admin Interview QuestionsSree SankarNo ratings yet
- Basic50linuscommand 100602035730 Phpapp02Document11 pagesBasic50linuscommand 100602035730 Phpapp02logcabinnNo ratings yet
- OS Practical FileDocument25 pagesOS Practical Filekanika MittalNo ratings yet
- Linux Admin Interview Questions: Back To TopDocument40 pagesLinux Admin Interview Questions: Back To Topkoseyiw439No ratings yet
- Linux System Administrator Interview Questions You'll Most Likely Be AskedFrom EverandLinux System Administrator Interview Questions You'll Most Likely Be AskedNo ratings yet
- The Mac Terminal Reference and Scripting PrimerFrom EverandThe Mac Terminal Reference and Scripting PrimerRating: 4.5 out of 5 stars4.5/5 (3)
- UNIX Shell Programming Interview Questions You'll Most Likely Be AskedFrom EverandUNIX Shell Programming Interview Questions You'll Most Likely Be AskedNo ratings yet
- Footprinting, Reconnaissance, Scanning and Enumeration Techniques of Computer NetworksFrom EverandFootprinting, Reconnaissance, Scanning and Enumeration Techniques of Computer NetworksNo ratings yet
- Configuration of a Simple Samba File Server, Quota and Schedule BackupFrom EverandConfiguration of a Simple Samba File Server, Quota and Schedule BackupNo ratings yet
- Python for Beginners: An Introduction to Learn Python Programming with Tutorials and Hands-On ExamplesFrom EverandPython for Beginners: An Introduction to Learn Python Programming with Tutorials and Hands-On ExamplesRating: 4 out of 5 stars4/5 (2)
- Hacking of Computer Networks: Full Course on Hacking of Computer NetworksFrom EverandHacking of Computer Networks: Full Course on Hacking of Computer NetworksNo ratings yet
- Lecture Outlines: Species Interactions and Community EcologyDocument96 pagesLecture Outlines: Species Interactions and Community EcologyEUNAH LimNo ratings yet
- Climate Change and Ozone LossDocument10 pagesClimate Change and Ozone LossEUNAH LimNo ratings yet
- Ch5 NoteDocument77 pagesCh5 NoteEUNAH LimNo ratings yet
- Lecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyDocument90 pagesLecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyEUNAH LimNo ratings yet
- Apes 1 Semester Review Questions: Chapters Covered On Final Exam (1-5, 7 (LAWS), 8-10, 11, 13)Document3 pagesApes 1 Semester Review Questions: Chapters Covered On Final Exam (1-5, 7 (LAWS), 8-10, 11, 13)EUNAH LimNo ratings yet
- Solid and Hazardous WasteDocument22 pagesSolid and Hazardous WasteEUNAH LimNo ratings yet
- AP Environmental Science: Environmental Problems, Causes, and SustainabilityDocument24 pagesAP Environmental Science: Environmental Problems, Causes, and SustainabilityEUNAH LimNo ratings yet
- Lecture Outlines: Evolution, Biodiversity, and Population EcologyDocument80 pagesLecture Outlines: Evolution, Biodiversity, and Population EcologyEUNAH LimNo ratings yet
- CH 21Document20 pagesCH 21EUNAH LimNo ratings yet
- Test Review Energy Efficiency and Renewable EnergyDocument39 pagesTest Review Energy Efficiency and Renewable EnergyEUNAH LimNo ratings yet
- CH 15Document71 pagesCH 15EUNAH LimNo ratings yet
- Water Resources and Water PollutionDocument122 pagesWater Resources and Water PollutionEUNAH LimNo ratings yet
- CH 18Document36 pagesCH 18EUNAH LimNo ratings yet
- Living in The Environment, 18E: Urbanization and SustainabilityDocument54 pagesLiving in The Environment, 18E: Urbanization and SustainabilityEUNAH LimNo ratings yet
- Nonrenewable Energy ResourcesDocument54 pagesNonrenewable Energy ResourcesEUNAH LimNo ratings yet
- Climate and Terrestrial BiodiversityDocument99 pagesClimate and Terrestrial BiodiversityEUNAH LimNo ratings yet
- CH 19Document35 pagesCH 19EUNAH LimNo ratings yet
- Evolution of BiodiversityDocument56 pagesEvolution of BiodiversityEUNAH LimNo ratings yet
- CH 8Document29 pagesCH 8EUNAH LimNo ratings yet
- CH 6Document18 pagesCH 6EUNAH LimNo ratings yet
- CH 7Document24 pagesCH 7EUNAH LimNo ratings yet
- CH 2Document40 pagesCH 2EUNAH LimNo ratings yet
- Solutions To Practice Problems For Genetics, Session 4: Biochemical GeneticsDocument4 pagesSolutions To Practice Problems For Genetics, Session 4: Biochemical GeneticsEUNAH LimNo ratings yet
- This Section Is in Addition To Chapter 3Document30 pagesThis Section Is in Addition To Chapter 3EUNAH LimNo ratings yet
- Practice Problems For Genetics, Session 4: Biochemical GeneticsDocument3 pagesPractice Problems For Genetics, Session 4: Biochemical GeneticsEUNAH LimNo ratings yet
- Ecology, Ecosystems and Food WebsDocument33 pagesEcology, Ecosystems and Food WebsEUNAH LimNo ratings yet
- Molecular Biology Unit ExamDocument7 pagesMolecular Biology Unit ExamEUNAH LimNo ratings yet
- Unifying Timer and Interrupt Management For An ARM-RISC-V-Heterogeneous Multi-CoreDocument8 pagesUnifying Timer and Interrupt Management For An ARM-RISC-V-Heterogeneous Multi-CoreShrinidhi RaoNo ratings yet
- Automation Anywhere - Foundation TrainingDocument12 pagesAutomation Anywhere - Foundation Traininguk_oopsNo ratings yet
- 5 - Q2 Emp TechDocument42 pages5 - Q2 Emp TechDiana Rose Puebla TomoricNo ratings yet
- A7IV Brochure FA LRDocument28 pagesA7IV Brochure FA LRtonywong1925No ratings yet
- RocPlane Tutorial 2 - SupportDocument11 pagesRocPlane Tutorial 2 - SupportVandi SetiawanNo ratings yet
- OmniPage Professional 15 DatasheetDocument2 pagesOmniPage Professional 15 DatasheetmarckosalexNo ratings yet
- Install Ubuntu On Oracle VirtualBoxDocument51 pagesInstall Ubuntu On Oracle VirtualBoxjohnNo ratings yet
- Task Management ToolDocument55 pagesTask Management Toolshinderavi1905No ratings yet
- Intro To Web3Document24 pagesIntro To Web3dontknowNo ratings yet
- Mimosa TutorialDocument53 pagesMimosa TutorialAgus RahmatNo ratings yet
- List TermDocument276 pagesList TermIndraNo ratings yet
- My Ai Cheat ListDocument3 pagesMy Ai Cheat ListALLIAH CARRIE FERRER100% (9)
- Computer Graphics - Course OutlineDocument3 pagesComputer Graphics - Course OutlineasamenekNo ratings yet
- Embedded SystemsDocument18 pagesEmbedded Systemsnaveenbandi62No ratings yet
- Chapter 1 - Data RepresentationDocument48 pagesChapter 1 - Data RepresentationMOG FBUINo ratings yet
- MSFencode - Metasploit UnleashedDocument7 pagesMSFencode - Metasploit UnleashedHuols4mNo ratings yet
- Definitions: What Is The Difference Between Data Flow Diagram and Flow ChartDocument5 pagesDefinitions: What Is The Difference Between Data Flow Diagram and Flow ChartZarnigar AltafNo ratings yet
- Documentation Batch1Document64 pagesDocumentation Batch1Chowdary Srinivas 143 UppuluriNo ratings yet
- Samra - Graphical PasswordsDocument11 pagesSamra - Graphical PasswordsSamra Afzal100% (3)
- STAR8800 User ManualDocument99 pagesSTAR8800 User ManualVikasNo ratings yet
- Simulink To Autosar Code Made EasyDocument44 pagesSimulink To Autosar Code Made Easyoussama zemziNo ratings yet
- Labview Thesis PDFDocument4 pagesLabview Thesis PDFInstantPaperWriterSpringfield100% (2)
- Createand Deploy ARM AzureDocument1,342 pagesCreateand Deploy ARM AzureCarlos Enrique Ureta Casas-corderoNo ratings yet
- Altair Winprop: Wave Propagation and Radio Network PlanningDocument2 pagesAltair Winprop: Wave Propagation and Radio Network Planningstanpjames2309No ratings yet
- IGIS1 - Exercise 3Document21 pagesIGIS1 - Exercise 3Abolghasem Sadeghi-NiarakiNo ratings yet
- Anjuman College of Engineering & TechnologyDocument12 pagesAnjuman College of Engineering & TechnologyZaky MuzaffarNo ratings yet
- List of Useful FMs Reports and Module Wise TablesDocument89 pagesList of Useful FMs Reports and Module Wise Tablesmu118bNo ratings yet
- SIMIT-GettingStarted DOC V1.0 enDocument26 pagesSIMIT-GettingStarted DOC V1.0 enRonoNo ratings yet
- PC Software Installation and Manual TracerkwDocument15 pagesPC Software Installation and Manual TracerkwHyacinthe KOSSINo ratings yet
- Dicom Conformance Statement: Kodak Dryview 8900 Laser ImagerDocument41 pagesDicom Conformance Statement: Kodak Dryview 8900 Laser ImagerphcalvinsxeNo ratings yet



















































































































Download as docx, pdf, or txt
You might also like
- If You Are Preparing For Interviews For Linux Admin Jobs You Should Be Familiar With Below Concepts.Document54 pagesIf You Are Preparing For Interviews For Linux Admin Jobs You Should Be Familiar With Below Concepts.Praveen Raj Thakur83% (6)
- Homework 3Document4 pagesHomework 3Jenny MatuteNo ratings yet
- CNIOT Lab AssignmentDocument7 pagesCNIOT Lab Assignmentishidhim17No ratings yet
- Introduction To LINUX OS: ObjectivesDocument68 pagesIntroduction To LINUX OS: ObjectivesVeerubglrKumarNo ratings yet
- Linux Programming SolutionDocument28 pagesLinux Programming Solutionamaankazi1793No ratings yet
- OS ManualDocument26 pagesOS ManualSakshi GoleNo ratings yet
- Linux Interview Question_AnswersDocument39 pagesLinux Interview Question_Answersravi_kishore21No ratings yet
- Linux Adminnn 5Document43 pagesLinux Adminnn 5chaits258No ratings yet
- AnywayDocument116 pagesAnywayAnonymous nzfEotriWKNo ratings yet
- 10 Lab Manual Basic Linux CommandsDocument16 pages10 Lab Manual Basic Linux Commandsharin9079No ratings yet
- Os Lab ManualDocument98 pagesOs Lab ManualSai KumarNo ratings yet
- Linux Interview QuestionsDocument23 pagesLinux Interview QuestionsAshish Yadav100% (1)
- Operating System LAb 1Document7 pagesOperating System LAb 1ajnobi hueseNo ratings yet
- OS_lab_manual_PPPDocument41 pagesOS_lab_manual_PPPvidya maliNo ratings yet
- Iitdelhi Lab AssignmentDocument4 pagesIitdelhi Lab AssignmentNitishkumarreddyervaNo ratings yet
- LinuxDocument89 pagesLinuxC Rithin ChakravarthyNo ratings yet
- Os Lab Manual FinalDocument17 pagesOs Lab Manual FinalMubaraka KundawalaNo ratings yet
- Lab Manual: Internet of Things Lab (7CS4-21)Document37 pagesLab Manual: Internet of Things Lab (7CS4-21)Abhishek NairNo ratings yet
- Linux Admin 5Document44 pagesLinux Admin 5chaits258No ratings yet
- Os Lab ManualDocument37 pagesOs Lab ManualJASPER WESSLYNo ratings yet
- Unix Interview QuestionsDocument6 pagesUnix Interview QuestionsOmkar Rayapeddi100% (1)
- Os Lab Manual-1Document65 pagesOs Lab Manual-1diranj0% (1)
- Linux Admin QuestionsDocument44 pagesLinux Admin Questionschaits258No ratings yet
- IntroDocument4 pagesIntroVinod SolankeNo ratings yet
- Linux Interview Questions and AnswersDocument11 pagesLinux Interview Questions and Answersdillip21100% (1)
- Top 50 Raspberry Pi Commands List Cheat SheetDocument4 pagesTop 50 Raspberry Pi Commands List Cheat SheetYassin EzzNo ratings yet
- Linux LabDocument37 pagesLinux Labsrilakshmi nageshNo ratings yet
- Answers To Even-Numbered Exercises: From Page 1077Document7 pagesAnswers To Even-Numbered Exercises: From Page 1077Mark HoldenNo ratings yet
- Linux Privilege EscalationDocument17 pagesLinux Privilege Escalationilykillit325No ratings yet
- Operating System LabDocument33 pagesOperating System LabCasey MoralesNo ratings yet
- OS LabsDocument63 pagesOS Labsroman naeemNo ratings yet
- Linux Admin Interview QuestionsDocument4 pagesLinux Admin Interview Questionsapi-3780913No ratings yet
- Linux AdminDocument44 pagesLinux Adminchaits258No ratings yet
- Nixes and IntDocument43 pagesNixes and Intchaits258No ratings yet
- Interview Questions2Document3 pagesInterview Questions2sandeep.hasa775No ratings yet
- Simple ShellDocument8 pagesSimple ShellBrian MutembeiNo ratings yet
- ACTION Lab HPC Install MannulDocument10 pagesACTION Lab HPC Install MannulMandoiu StefanNo ratings yet
- OS Assign1Document3 pagesOS Assign1anon_608090223No ratings yet
- Os LabDocument63 pagesOs LabsuriyakrishnanNo ratings yet
- Unix Programming and Compiler DesignDocument68 pagesUnix Programming and Compiler DesignRaghu GowdaNo ratings yet
- Linux Admin 4Document44 pagesLinux Admin 4chaits258No ratings yet
- Tutorial 0Document10 pagesTutorial 0wwpretty faceNo ratings yet
- My Linux CommandsDocument5 pagesMy Linux CommandsMorgan KisienyaNo ratings yet
- UnixDocument11 pagesUnixffrakeshNo ratings yet
- Linux Admin Interview QuestionsDocument7 pagesLinux Admin Interview QuestionsSree SankarNo ratings yet
- Basic50linuscommand 100602035730 Phpapp02Document11 pagesBasic50linuscommand 100602035730 Phpapp02logcabinnNo ratings yet
- OS Practical FileDocument25 pagesOS Practical Filekanika MittalNo ratings yet
- Linux Admin Interview Questions: Back To TopDocument40 pagesLinux Admin Interview Questions: Back To Topkoseyiw439No ratings yet
- Linux System Administrator Interview Questions You'll Most Likely Be AskedFrom EverandLinux System Administrator Interview Questions You'll Most Likely Be AskedNo ratings yet
- The Mac Terminal Reference and Scripting PrimerFrom EverandThe Mac Terminal Reference and Scripting PrimerRating: 4.5 out of 5 stars4.5/5 (3)
- UNIX Shell Programming Interview Questions You'll Most Likely Be AskedFrom EverandUNIX Shell Programming Interview Questions You'll Most Likely Be AskedNo ratings yet
- Footprinting, Reconnaissance, Scanning and Enumeration Techniques of Computer NetworksFrom EverandFootprinting, Reconnaissance, Scanning and Enumeration Techniques of Computer NetworksNo ratings yet
- Configuration of a Simple Samba File Server, Quota and Schedule BackupFrom EverandConfiguration of a Simple Samba File Server, Quota and Schedule BackupNo ratings yet
- Python for Beginners: An Introduction to Learn Python Programming with Tutorials and Hands-On ExamplesFrom EverandPython for Beginners: An Introduction to Learn Python Programming with Tutorials and Hands-On ExamplesRating: 4 out of 5 stars4/5 (2)
- Hacking of Computer Networks: Full Course on Hacking of Computer NetworksFrom EverandHacking of Computer Networks: Full Course on Hacking of Computer NetworksNo ratings yet
- Lecture Outlines: Species Interactions and Community EcologyDocument96 pagesLecture Outlines: Species Interactions and Community EcologyEUNAH LimNo ratings yet
- Climate Change and Ozone LossDocument10 pagesClimate Change and Ozone LossEUNAH LimNo ratings yet
- Ch5 NoteDocument77 pagesCh5 NoteEUNAH LimNo ratings yet
- Lecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyDocument90 pagesLecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyEUNAH LimNo ratings yet
- Apes 1 Semester Review Questions: Chapters Covered On Final Exam (1-5, 7 (LAWS), 8-10, 11, 13)Document3 pagesApes 1 Semester Review Questions: Chapters Covered On Final Exam (1-5, 7 (LAWS), 8-10, 11, 13)EUNAH LimNo ratings yet
- Solid and Hazardous WasteDocument22 pagesSolid and Hazardous WasteEUNAH LimNo ratings yet
- AP Environmental Science: Environmental Problems, Causes, and SustainabilityDocument24 pagesAP Environmental Science: Environmental Problems, Causes, and SustainabilityEUNAH LimNo ratings yet
- Lecture Outlines: Evolution, Biodiversity, and Population EcologyDocument80 pagesLecture Outlines: Evolution, Biodiversity, and Population EcologyEUNAH LimNo ratings yet
- CH 21Document20 pagesCH 21EUNAH LimNo ratings yet
- Test Review Energy Efficiency and Renewable EnergyDocument39 pagesTest Review Energy Efficiency and Renewable EnergyEUNAH LimNo ratings yet
- CH 15Document71 pagesCH 15EUNAH LimNo ratings yet
- Water Resources and Water PollutionDocument122 pagesWater Resources and Water PollutionEUNAH LimNo ratings yet
- CH 18Document36 pagesCH 18EUNAH LimNo ratings yet
- Living in The Environment, 18E: Urbanization and SustainabilityDocument54 pagesLiving in The Environment, 18E: Urbanization and SustainabilityEUNAH LimNo ratings yet
- Nonrenewable Energy ResourcesDocument54 pagesNonrenewable Energy ResourcesEUNAH LimNo ratings yet
- Climate and Terrestrial BiodiversityDocument99 pagesClimate and Terrestrial BiodiversityEUNAH LimNo ratings yet
- CH 19Document35 pagesCH 19EUNAH LimNo ratings yet
- Evolution of BiodiversityDocument56 pagesEvolution of BiodiversityEUNAH LimNo ratings yet
- CH 8Document29 pagesCH 8EUNAH LimNo ratings yet
- CH 6Document18 pagesCH 6EUNAH LimNo ratings yet
- CH 7Document24 pagesCH 7EUNAH LimNo ratings yet
- CH 2Document40 pagesCH 2EUNAH LimNo ratings yet
- Solutions To Practice Problems For Genetics, Session 4: Biochemical GeneticsDocument4 pagesSolutions To Practice Problems For Genetics, Session 4: Biochemical GeneticsEUNAH LimNo ratings yet
- This Section Is in Addition To Chapter 3Document30 pagesThis Section Is in Addition To Chapter 3EUNAH LimNo ratings yet
- Practice Problems For Genetics, Session 4: Biochemical GeneticsDocument3 pagesPractice Problems For Genetics, Session 4: Biochemical GeneticsEUNAH LimNo ratings yet
- Ecology, Ecosystems and Food WebsDocument33 pagesEcology, Ecosystems and Food WebsEUNAH LimNo ratings yet
- Molecular Biology Unit ExamDocument7 pagesMolecular Biology Unit ExamEUNAH LimNo ratings yet
- Unifying Timer and Interrupt Management For An ARM-RISC-V-Heterogeneous Multi-CoreDocument8 pagesUnifying Timer and Interrupt Management For An ARM-RISC-V-Heterogeneous Multi-CoreShrinidhi RaoNo ratings yet
- Automation Anywhere - Foundation TrainingDocument12 pagesAutomation Anywhere - Foundation Traininguk_oopsNo ratings yet
- 5 - Q2 Emp TechDocument42 pages5 - Q2 Emp TechDiana Rose Puebla TomoricNo ratings yet
- A7IV Brochure FA LRDocument28 pagesA7IV Brochure FA LRtonywong1925No ratings yet
- RocPlane Tutorial 2 - SupportDocument11 pagesRocPlane Tutorial 2 - SupportVandi SetiawanNo ratings yet
- OmniPage Professional 15 DatasheetDocument2 pagesOmniPage Professional 15 DatasheetmarckosalexNo ratings yet
- Install Ubuntu On Oracle VirtualBoxDocument51 pagesInstall Ubuntu On Oracle VirtualBoxjohnNo ratings yet
- Task Management ToolDocument55 pagesTask Management Toolshinderavi1905No ratings yet
- Intro To Web3Document24 pagesIntro To Web3dontknowNo ratings yet
- Mimosa TutorialDocument53 pagesMimosa TutorialAgus RahmatNo ratings yet
- List TermDocument276 pagesList TermIndraNo ratings yet
- My Ai Cheat ListDocument3 pagesMy Ai Cheat ListALLIAH CARRIE FERRER100% (9)
- Computer Graphics - Course OutlineDocument3 pagesComputer Graphics - Course OutlineasamenekNo ratings yet
- Embedded SystemsDocument18 pagesEmbedded Systemsnaveenbandi62No ratings yet
- Chapter 1 - Data RepresentationDocument48 pagesChapter 1 - Data RepresentationMOG FBUINo ratings yet
- MSFencode - Metasploit UnleashedDocument7 pagesMSFencode - Metasploit UnleashedHuols4mNo ratings yet
- Definitions: What Is The Difference Between Data Flow Diagram and Flow ChartDocument5 pagesDefinitions: What Is The Difference Between Data Flow Diagram and Flow ChartZarnigar AltafNo ratings yet
- Documentation Batch1Document64 pagesDocumentation Batch1Chowdary Srinivas 143 UppuluriNo ratings yet
- Samra - Graphical PasswordsDocument11 pagesSamra - Graphical PasswordsSamra Afzal100% (3)
- STAR8800 User ManualDocument99 pagesSTAR8800 User ManualVikasNo ratings yet
- Simulink To Autosar Code Made EasyDocument44 pagesSimulink To Autosar Code Made Easyoussama zemziNo ratings yet
- Labview Thesis PDFDocument4 pagesLabview Thesis PDFInstantPaperWriterSpringfield100% (2)
- Createand Deploy ARM AzureDocument1,342 pagesCreateand Deploy ARM AzureCarlos Enrique Ureta Casas-corderoNo ratings yet
- Altair Winprop: Wave Propagation and Radio Network PlanningDocument2 pagesAltair Winprop: Wave Propagation and Radio Network Planningstanpjames2309No ratings yet
- IGIS1 - Exercise 3Document21 pagesIGIS1 - Exercise 3Abolghasem Sadeghi-NiarakiNo ratings yet
- Anjuman College of Engineering & TechnologyDocument12 pagesAnjuman College of Engineering & TechnologyZaky MuzaffarNo ratings yet
- List of Useful FMs Reports and Module Wise TablesDocument89 pagesList of Useful FMs Reports and Module Wise Tablesmu118bNo ratings yet
- SIMIT-GettingStarted DOC V1.0 enDocument26 pagesSIMIT-GettingStarted DOC V1.0 enRonoNo ratings yet
- PC Software Installation and Manual TracerkwDocument15 pagesPC Software Installation and Manual TracerkwHyacinthe KOSSINo ratings yet
- Dicom Conformance Statement: Kodak Dryview 8900 Laser ImagerDocument41 pagesDicom Conformance Statement: Kodak Dryview 8900 Laser ImagerphcalvinsxeNo ratings yet