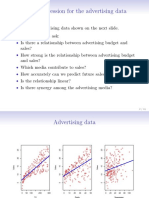
Download as pdf or txt
You might also like
- Assignment 9Document8 pagesAssignment 9Ray GuoNo ratings yet
- Mathematical Modeling 4th Edition Meerschaert Solutions ManualDocument18 pagesMathematical Modeling 4th Edition Meerschaert Solutions ManualKylieWilsonkpzrg100% (14)
- SQL Case Study - BasicDocument3 pagesSQL Case Study - BasicHasan Naqvi0% (2)
- SQL Case Study-Advance: Business ScenarioDocument2 pagesSQL Case Study-Advance: Business ScenarioSarthak SharmaNo ratings yet
- Mastering Metrics PDFDocument47 pagesMastering Metrics PDFandres57042No ratings yet
- AnalytixLabs - Sports Equipment Case StudyDocument2 pagesAnalytixLabs - Sports Equipment Case StudySarthak SharmaNo ratings yet
- AnalytixLabs - Laptops Case StudyDocument4 pagesAnalytixLabs - Laptops Case StudySarthak SharmaNo ratings yet
- Correlation Regression - 2023Document69 pagesCorrelation Regression - 2023Writabrata BhattacharyaNo ratings yet
- Business Maths ScopeDocument9 pagesBusiness Maths ScopeAbdul Razzaq KhanNo ratings yet
- Session 13 - Wednesday 19th OctoberDocument37 pagesSession 13 - Wednesday 19th OctoberSana SoomroNo ratings yet
- GR 9 O. Math Project Work - 1 SampleDocument8 pagesGR 9 O. Math Project Work - 1 Sampleshresthahardik03No ratings yet
- WK4 Session 8 Workshop (CH 10)Document28 pagesWK4 Session 8 Workshop (CH 10)Zaeem AsgharNo ratings yet
- ML L6 Linear RegresionDocument54 pagesML L6 Linear RegresionMickey MouseNo ratings yet
- TH E PL Ofit Grai H: Graph 1Document13 pagesTH E PL Ofit Grai H: Graph 1aprilNo ratings yet
- Optimisation TechniquesDocument32 pagesOptimisation TechniquesAGRAWAL UTKARSHNo ratings yet
- 3 Linear Regression-Handout PDFDocument48 pages3 Linear Regression-Handout PDFTaylor TamNo ratings yet
- Regression Analysis Using ExcelDocument85 pagesRegression Analysis Using ExcelCarlos Hoyos100% (1)
- National Institute of Business ManagementDocument10 pagesNational Institute of Business ManagementSonali RajapakseNo ratings yet
- Chapter 4.T2sDocument15 pagesChapter 4.T2sTrình Lan AnhNo ratings yet
- 6 ASAP Advanced Statistics-RegressionDocument53 pages6 ASAP Advanced Statistics-RegressionGeorge MathewNo ratings yet
- Optimization ProjectDocument6 pagesOptimization Projectapi-255608351No ratings yet
- Business Statistics - AssignmentDocument7 pagesBusiness Statistics - AssignmentAkshatNo ratings yet
- Practical Exam QuestionsDocument23 pagesPractical Exam QuestionsPriyobroto Chokroborty57% (21)
- Practice Questions For Practical Exam-Final PDFDocument23 pagesPractice Questions For Practical Exam-Final PDFPriyobroto Chokroborty100% (1)
- Unit 7 Regration and CorrelationDocument11 pagesUnit 7 Regration and CorrelationhayelomNo ratings yet
- Multiple Linear RegressionDocument7 pagesMultiple Linear RegressionAka GNo ratings yet
- 7 0 0 4 MBA (Sem I) Theory Examination 2017-18 Business StatisticsDocument3 pages7 0 0 4 MBA (Sem I) Theory Examination 2017-18 Business StatisticsNishant TripathiNo ratings yet
- Regression Analysis: Estimating RelationshipsDocument12 pagesRegression Analysis: Estimating RelationshipsandreyNo ratings yet
- 5 Noman Naseer Linear RegressionDocument15 pages5 Noman Naseer Linear Regression057GV Văn HiếuNo ratings yet
- Ardl 1Document166 pagesArdl 1sunil kumarNo ratings yet
- Chapter 2 SlidesDocument55 pagesChapter 2 SlidesaliNo ratings yet
- Fuzzy Lec2Document34 pagesFuzzy Lec2rishivm2003No ratings yet
- Regression AnalysisDocument2 pagesRegression AnalysisJasmin EismaNo ratings yet
- Vol - Jum E: Graph 1 Graj HDocument13 pagesVol - Jum E: Graph 1 Graj HaprilNo ratings yet
- Quantitative Group AssigmentDocument10 pagesQuantitative Group AssigmentAbrahamNo ratings yet
- Statistische Auswertung WiederfindungsfunktionDocument7 pagesStatistische Auswertung WiederfindungsfunktionMichael HuberNo ratings yet
- Week 8 (Causal Forecasting 18-27) - 2Document10 pagesWeek 8 (Causal Forecasting 18-27) - 2AHSAN ANSARINo ratings yet
- Caso 04Document17 pagesCaso 04ENMANUELPANDUROPELAEZNo ratings yet
- Non Negative Assumption Solution by Graphical Method:: Linear ProgrammingDocument11 pagesNon Negative Assumption Solution by Graphical Method:: Linear ProgrammingSayantani SamantaNo ratings yet
- Regression NotesDocument20 pagesRegression NotesOmkar Todkar100% (1)
- Linear RegressionDocument46 pagesLinear RegressionRajkiran PatilNo ratings yet
- BBFH 202 Business Finance 1Document4 pagesBBFH 202 Business Finance 1tawandaNo ratings yet
- Monte Carlo SimulationDocument5 pagesMonte Carlo SimulationIulia Roman GaroafaNo ratings yet
- CS1B April 2024Document9 pagesCS1B April 2024mahaveerkankaliya07No ratings yet
- MAS 2 Midterms Module No. 1 StudentsDocument6 pagesMAS 2 Midterms Module No. 1 StudentsJoan Marie AgnesNo ratings yet
- DISC 212 Session 13Document29 pagesDISC 212 Session 13Sneha KumariNo ratings yet
- Linear Programming Model BESTDocument123 pagesLinear Programming Model BESTDaniel TackieNo ratings yet
- BEP Formulae and Example 9Document4 pagesBEP Formulae and Example 9anupsuchakNo ratings yet
- Lec 12 - Regresi Multi-LinierDocument22 pagesLec 12 - Regresi Multi-LinierAsal ReviewNo ratings yet
- Objective: Decision VariablesDocument18 pagesObjective: Decision VariablesShaneNo ratings yet
- OptimizingprojectDocument4 pagesOptimizingprojectapi-191920769No ratings yet
- Approximations and Round-Off ErrorsDocument14 pagesApproximations and Round-Off ErrorsPetrosian PutraNo ratings yet
- Ration AnalysisDocument35 pagesRation AnalysisMuhammad EjazNo ratings yet
- Chapter - 2 - Week 4-11 FebDocument45 pagesChapter - 2 - Week 4-11 FebahalalamiNo ratings yet
- Example Following Programming Problem Graphically.: MaximizeDocument6 pagesExample Following Programming Problem Graphically.: MaximizeKaran RawatNo ratings yet
- IS4242 W3 Regression AnalysesDocument67 pagesIS4242 W3 Regression Analyseswongdeshun4No ratings yet
- Linear Regression: What Is Regression Analysis?Document21 pagesLinear Regression: What Is Regression Analysis?sailusha100% (1)
- QuesDocument7 pagesQuesSupali BasuNo ratings yet
- Lecture PDFDocument115 pagesLecture PDFAnwar HussainNo ratings yet
- Measure of AssociationDocument66 pagesMeasure of AssociationF.Ramesh DhanaseelanNo ratings yet
- Applied Linguistics Error - AnalysisDocument5 pagesApplied Linguistics Error - AnalysisÃßdØüLégềndàrioÇristÃlNo ratings yet
- Frequency Distibution Graphs SlidesDocument54 pagesFrequency Distibution Graphs SlidesISAACNo ratings yet
- Successive Percent Change SummaryDocument5 pagesSuccessive Percent Change SummaryAMAN SINGHNo ratings yet
- Coefficient of Variation (CV) - 100 (Sample) Coefficient of Variation (CV) - 100 (Population)Document5 pagesCoefficient of Variation (CV) - 100 (Sample) Coefficient of Variation (CV) - 100 (Population)Mohamed ZizoNo ratings yet
- Sales Data - Sports EquipmentDocument1,083 pagesSales Data - Sports EquipmentSarthak SharmaNo ratings yet
- Am Am Charla 2011Document10 pagesAm Am Charla 2011Raul Diaz TorresNo ratings yet
- Egypt BathDocument6 pagesEgypt BathLennert PronkNo ratings yet
- Statistics and Probability q4 Mod21 Calculating The Slope and Y Intercept of A Regression Line V2Document24 pagesStatistics and Probability q4 Mod21 Calculating The Slope and Y Intercept of A Regression Line V2Dwayne DizonNo ratings yet
- 361 Assignment#2Document4 pages361 Assignment#2azeem niaziNo ratings yet
- Samuel's PaperDocument30 pagesSamuel's Papersamuel azmerawNo ratings yet
- A Mathematical and Statistical Approach For Predicting The Population GrowthDocument11 pagesA Mathematical and Statistical Approach For Predicting The Population GrowthBrix Lander C. CastroNo ratings yet
- Ridge Regression: Patrick BrehenyDocument22 pagesRidge Regression: Patrick BrehenyDjordje MiladinovicNo ratings yet
- Advantages and Disadvantages of Information SystemsDocument42 pagesAdvantages and Disadvantages of Information SystemsAnnu BhatiaNo ratings yet
- Project Paper Proposal DONE!!!!Document24 pagesProject Paper Proposal DONE!!!!Azri AlimorNo ratings yet
- Telecom Customer Churn Prediction Assessment PDFDocument23 pagesTelecom Customer Churn Prediction Assessment PDFPrakash Jha100% (1)
- NPTEL Online Certification Courses Indian Institute of Technology KharagpurDocument4 pagesNPTEL Online Certification Courses Indian Institute of Technology KharagpurSURENDRAN D CS085No ratings yet
- Child, Maternal, and Family Characteristics Associated WithDocument8 pagesChild, Maternal, and Family Characteristics Associated WithJL0653906No ratings yet
- ST5212: Survival Analysis: ScheduleDocument4 pagesST5212: Survival Analysis: ScheduleSnu Cho IDNo ratings yet
- M.a.M.sc. Statistics SyllabusDocument14 pagesM.a.M.sc. Statistics Syllabusmittalnipun2009No ratings yet
- Factors Impacting The Adoption and Implementation of Business Intelligence and Analytics Projects in OrganizationsDocument356 pagesFactors Impacting The Adoption and Implementation of Business Intelligence and Analytics Projects in OrganizationsEduardo MenaNo ratings yet
- AI Feynman, A Physics Inspired Method For Symbolic Regression, Uderscu, 2020 PDFDocument17 pagesAI Feynman, A Physics Inspired Method For Symbolic Regression, Uderscu, 2020 PDFMario Leon GaticaNo ratings yet
- Jurnal Bahasa Inggris - Dwi Angga Winata - enDocument11 pagesJurnal Bahasa Inggris - Dwi Angga Winata - enDWI ANGGA WINATA WINATANo ratings yet
- Polynomial Regression ModelsDocument5 pagesPolynomial Regression ModelsmustafaNo ratings yet
- Regression Modeling Strategies - E-Bok - Frank E Harrell ... - BokusDocument2 pagesRegression Modeling Strategies - E-Bok - Frank E Harrell ... - BokusasdlasjdlkaNo ratings yet
- Chapter 2 - Regression and Correlation PDFDocument26 pagesChapter 2 - Regression and Correlation PDFCayce EvansNo ratings yet
- MAS First Preboard 2021Document12 pagesMAS First Preboard 2021Ser Crz Jy50% (2)
- Correlation and Regression Notes 2.0Document6 pagesCorrelation and Regression Notes 2.0DtwaNo ratings yet
- 1 PDFDocument6 pages1 PDFMohamed MansourNo ratings yet
- Business Fundamentals Course - CORe - HBS OnlineDocument7 pagesBusiness Fundamentals Course - CORe - HBS OnlineWong kang xianNo ratings yet
- Correlation and RegressionDocument12 pagesCorrelation and RegressionShahariar KabirNo ratings yet
- USIT204 Numerical and Statistical MethodsDocument240 pagesUSIT204 Numerical and Statistical MethodsPrabhat Mishra100% (1)
- XL Miner User GuideDocument420 pagesXL Miner User GuideMary WilliamsNo ratings yet
- Business Analytics (MGT 555) Individual Assignment Assignment 2Document5 pagesBusiness Analytics (MGT 555) Individual Assignment Assignment 2Syakirah HusniNo ratings yet
- ACAP 2022 HandbookDocument42 pagesACAP 2022 Handbookcesar cuchoNo ratings yet