Download as docx, pdf, or txt
You might also like
- 1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyDocument50 pages1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyP Venkata Krishna Rao100% (19)
- Capstone Project Final Full ReportDocument22 pagesCapstone Project Final Full ReportRobert100% (1)
- Thera Bank - ProjectDocument34 pagesThera Bank - Projectbhumika singh100% (4)
- Presentation On Plant Disease Identification Using MatlabDocument20 pagesPresentation On Plant Disease Identification Using MatlabSayantan Banerjee100% (1)
- Resource 5e85c2740f5e5963197435 PDFDocument133 pagesResource 5e85c2740f5e5963197435 PDFTooniNo ratings yet
- First WeekDocument13 pagesFirst Weekayed academyNo ratings yet
- Xii-Pass Neet - NR - FT-2 - 24.07.2023 - KeyDocument7 pagesXii-Pass Neet - NR - FT-2 - 24.07.2023 - Keyraghaviraja01No ratings yet
- Practical 2 51Document5 pagesPractical 2 51Royal EmpireNo ratings yet
- Overlapping MultiplesDocument2 pagesOverlapping Multiplesrasha.a.ghabbounNo ratings yet
- F23 HW5 Hclust StudentDocument4 pagesF23 HW5 Hclust StudentnzpisnumberoneNo ratings yet
- Maths Daily Review wk10 - Skip Count Split Strategy Near Doubles Halves Fractions Column StrategyDocument48 pagesMaths Daily Review wk10 - Skip Count Split Strategy Near Doubles Halves Fractions Column Strategyapi-349843039No ratings yet
- BT307 Biological Data Analysis Assignment 1Document2 pagesBT307 Biological Data Analysis Assignment 1Karthik KashalNo ratings yet
- 2581 DBDDF 575Document9 pages2581 DBDDF 575fatimaNo ratings yet
- Untitled7.ipynb - ColaboratoryDocument12 pagesUntitled7.ipynb - ColaboratoryGopala krishna SeelamneniNo ratings yet
- GE 333 (Geographic Information Systems)Document5 pagesGE 333 (Geographic Information Systems)BASILIO CONCRENIONo ratings yet
- Problem Set 2Document2 pagesProblem Set 2GdeNo ratings yet
- Week01 Introduction and Set TheoryDocument81 pagesWeek01 Introduction and Set TheoryMahad ElahiNo ratings yet
- Q Bank Class III MathsDocument68 pagesQ Bank Class III MathsTeja BhushanNo ratings yet
- Unsupervised Learning ExampleDocument5 pagesUnsupervised Learning Examplemichaelkotze03No ratings yet
- Grand Test-6Document2 pagesGrand Test-6K.A PadmanabhamNo ratings yet
- Subject Reference: Mathematics 2.5 Internal Assessment Resource Reference NumberDocument14 pagesSubject Reference: Mathematics 2.5 Internal Assessment Resource Reference NumberKenny WuNo ratings yet
- First Session WorksheetDocument8 pagesFirst Session WorksheetAstraX EducationNo ratings yet
- XII-STU-NEET-FTN-2 - MAIN PAPER Key & SolutionsDocument23 pagesXII-STU-NEET-FTN-2 - MAIN PAPER Key & SolutionsJатжпNo ratings yet
- Discipline: "Managerial decision-making methods" Course: 2 Group: М-91an Teacher: Denys Smolennikov Deadline: 24.12.2020Document4 pagesDiscipline: "Managerial decision-making methods" Course: 2 Group: М-91an Teacher: Denys Smolennikov Deadline: 24.12.2020София КалюжнаяNo ratings yet
- VSDA Category-III PostDocument4 pagesVSDA Category-III Postnenu na bangaramNo ratings yet
- Id No Inst Time Status Ag e Se X Ph. Ecog Ph. Karno Pat. Karno Meal - Cal WT - LossDocument4 pagesId No Inst Time Status Ag e Se X Ph. Ecog Ph. Karno Pat. Karno Meal - Cal WT - LosslikhithNo ratings yet
- Logarithms PDFDocument4 pagesLogarithms PDFD NAGA VAMSINo ratings yet
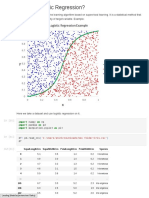
- Logistic RegressionDocument4 pagesLogistic RegressionParamita HalderNo ratings yet
- Charmi Shah - 20BCP299 Assignment-4Document11 pagesCharmi Shah - 20BCP299 Assignment-4PrincyNo ratings yet
- Name: - Total Stars: - Name: - Total StarsDocument1 pageName: - Total Stars: - Name: - Total StarsGracil NavalesNo ratings yet
- Lec 01 F20 IntroductionDocument47 pagesLec 01 F20 IntroductionAbu HurairaNo ratings yet
- STA641 Final Term PaperDocument11 pagesSTA641 Final Term Paperhamzafiaz.jtcNo ratings yet
- Pier Francesco Roggero, Michele Nardelli, Francesco Di Noto - "Study On The Sierpinski and Riesel Numbers"Document79 pagesPier Francesco Roggero, Michele Nardelli, Francesco Di Noto - "Study On The Sierpinski and Riesel Numbers"Michele NardelliNo ratings yet
- Year 5 Maths Grab Pack 4ansDocument11 pagesYear 5 Maths Grab Pack 4ansglen rossNo ratings yet
- Araling Panlipunan 9 Audio Activity 2 Quarter 1 Week 2Document6 pagesAraling Panlipunan 9 Audio Activity 2 Quarter 1 Week 2junielNo ratings yet
- Ntaneet - Nic.in WWW - Nta.ac - inDocument25 pagesNtaneet - Nic.in WWW - Nta.ac - inTr Mazhar PunjabiNo ratings yet
- Notice 20200926075405 PDFDocument25 pagesNotice 20200926075405 PDFprabhakarNo ratings yet
- Notice 20200926075405Document25 pagesNotice 20200926075405MD Arbaaz HussainNo ratings yet
- Ntaneet - Nic.in WWW - Nta.ac - inDocument25 pagesNtaneet - Nic.in WWW - Nta.ac - inSougata Sur Roy ChowdhuryNo ratings yet
- Notice 20200926075405Document25 pagesNotice 20200926075405RjNo ratings yet
- Notice 20200926075405Document25 pagesNotice 20200926075405RjNo ratings yet
- 21-04-2024 - ICON ALL (Mains Percentile Less Then 70) - EAMCET - PTE-05 - Key & Sol'sDocument25 pages21-04-2024 - ICON ALL (Mains Percentile Less Then 70) - EAMCET - PTE-05 - Key & Sol'sAshok GuptaNo ratings yet
- Page No 25 h6 Ans SheetDocument25 pagesPage No 25 h6 Ans SheetDinuNo ratings yet
- ShowPdf PDFDocument25 pagesShowPdf PDFLaxmanNo ratings yet
- Notice 20200926075405Document25 pagesNotice 20200926075405RjNo ratings yet
- Organizing Data EDADocument20 pagesOrganizing Data EDADan PadillaNo ratings yet
- Report WarningDocument5 pagesReport WarningnudewaNo ratings yet
- ML#07Document21 pagesML#07Kiki NhabindeNo ratings yet
- Brigham Young University - IdahoDocument13 pagesBrigham Young University - IdahoJoe SarkcessNo ratings yet
- Major 1 SolutionDocument8 pagesMajor 1 Solutionkaransinghabcd2005No ratings yet
- Ds Classes Group: NEET - 2019 Answer Key Set - P6Document1 pageDs Classes Group: NEET - 2019 Answer Key Set - P6FarhanNo ratings yet
- Solutions Spring 2019 HWDocument67 pagesSolutions Spring 2019 HWMaryna MakeienkoNo ratings yet
- Solutions Spring 2019 HWDocument67 pagesSolutions Spring 2019 HWMohdNo ratings yet
- Data Science Practical No 03Document5 pagesData Science Practical No 03Satyavan MestryNo ratings yet
- Chapter 3 PDFDocument112 pagesChapter 3 PDFAnonymous BJMMLHLKNo ratings yet
- Imocha - Question 1 ReplacementDocument8 pagesImocha - Question 1 ReplacementAnshu SinghNo ratings yet
- Dokumen - Tips - Quantitative Methods Problems Explanation 11 20 2012Document13 pagesDokumen - Tips - Quantitative Methods Problems Explanation 11 20 2012Raghu NandanNo ratings yet
- Full download Business Analytics Data Analysis and Decision Making 6th Edition Albright Solutions Manual all chapter 2024 pdfDocument44 pagesFull download Business Analytics Data Analysis and Decision Making 6th Edition Albright Solutions Manual all chapter 2024 pdfcorbestabako100% (8)
- 01.EGT-01 Key BT1&2Document1 page01.EGT-01 Key BT1&2Sohan KrishnaNo ratings yet
- Doc-20240218-Wa0008. 2Document48 pagesDoc-20240218-Wa0008. 2vijaymmeiiitnNo ratings yet
- XI NEET NR FT-02 DT. 03-07-2023 - Key&SolDocument14 pagesXI NEET NR FT-02 DT. 03-07-2023 - Key&Solazmath pkNo ratings yet
- K Mean ClusteringDocument27 pagesK Mean Clusteringashishamitav123No ratings yet
- Parallelizing - K Means Clustering: A Project ReportDocument32 pagesParallelizing - K Means Clustering: A Project ReportADITYA SINGHNo ratings yet
- 6 Real-World Case Studies: Data Science For BusinessDocument18 pages6 Real-World Case Studies: Data Science For BusinessSqaure PodNo ratings yet
- Data Mining Dan BigdataDocument38 pagesData Mining Dan BigdataMuhammad Iman SantosoNo ratings yet
- Personalized Diet Recommendation System in HealthcareDocument31 pagesPersonalized Diet Recommendation System in HealthcareAshwin chaudhariNo ratings yet
- Lab1-Algorithms For Information Retrieval. IntroductionDocument13 pagesLab1-Algorithms For Information Retrieval. IntroductionshanthinisampathNo ratings yet
- Intro To Data MinningDocument24 pagesIntro To Data MinningAkshay MathurNo ratings yet
- Mathematics: A Smoke Detection Model Based On Improved Yolov5Document13 pagesMathematics: A Smoke Detection Model Based On Improved Yolov5Khôi TrầnNo ratings yet
- Cluster AnalysisDocument77 pagesCluster AnalysisDennis Atygurasiwi KunarsitoNo ratings yet
- Abnormal Humans Activity DetectionDocument36 pagesAbnormal Humans Activity DetectionCHANDANA MNo ratings yet
- ClusteringDocument39 pagesClusteringSourav MondalNo ratings yet
- cs189 Lecture 1Document113 pagescs189 Lecture 1Yuhua WangNo ratings yet
- 20bce0630 VL2022230504993 Pe003Document11 pages20bce0630 VL2022230504993 Pe003Dominic TorettoNo ratings yet
- Advanced Machine Learning and Artificial IntelligenceDocument9 pagesAdvanced Machine Learning and Artificial IntelligenceKannan SNo ratings yet
- W05.data Mining FunctionalitiesDocument31 pagesW05.data Mining FunctionalitiesRifqi Dwi RamadhaniNo ratings yet
- Image Segmentation Using Firefly Algorithm: Akash Sharma Smriti SehgalDocument4 pagesImage Segmentation Using Firefly Algorithm: Akash Sharma Smriti SehgalAnindya ApriliyantiNo ratings yet
- Ubiquitous Computing PDFDocument515 pagesUbiquitous Computing PDFSrToshi100% (1)
- Introduction To WekaDocument39 pagesIntroduction To WekaFaiz DarNo ratings yet
- Inline Image Vision Technique For Tires Industry 4.0: Quality and Defect Monitoring in Tires AssemblyDocument4 pagesInline Image Vision Technique For Tires Industry 4.0: Quality and Defect Monitoring in Tires AssemblyHorst SmogerNo ratings yet
- DataMining and Emotional Intelli - ClusterAnalysisDocument4 pagesDataMining and Emotional Intelli - ClusterAnalysisjeffconnorsNo ratings yet
- An Overview On Application of Machine Learning Techniques in Optical NetworksDocument26 pagesAn Overview On Application of Machine Learning Techniques in Optical NetworksFarhan FarhanNo ratings yet
- Analysis of Accident Times For Highway Locations Using K-Means Clustering and Decision Rules Extracted From Decision Trees.Document11 pagesAnalysis of Accident Times For Highway Locations Using K-Means Clustering and Decision Rules Extracted From Decision Trees.ATSNo ratings yet
- Lesson 09 - Introduction To Model BuildingDocument85 pagesLesson 09 - Introduction To Model BuildingSumanta SinhatalNo ratings yet
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- Chapter 7. Cluster AnalysisDocument120 pagesChapter 7. Cluster AnalysiskarimanrlfNo ratings yet
- Computer Vision MCQ's For InterviewDocument12 pagesComputer Vision MCQ's For InterviewMallikarjun patilNo ratings yet
- Assigment 3Document2 pagesAssigment 3Erick MenjivarNo ratings yet
- GPS: A Graph Processing SystemDocument31 pagesGPS: A Graph Processing SystemmarcusNo ratings yet