
Berkley ARMA Estimation Recipes
Berkley ARMA Estimation Recipes
You might also like
- Wren 80i Gas Turbine Engine Tech SpecsDocument25 pagesWren 80i Gas Turbine Engine Tech SpecsAlex Stihi100% (1)
- Time Series Analysis Henrik MadsenDocument156 pagesTime Series Analysis Henrik MadsenAlex Stihi100% (1)
- FreeFEM Tutorial ShovkunDocument6 pagesFreeFEM Tutorial ShovkunMohamad TayeaNo ratings yet
- Form - Notice To ExplainDocument2 pagesForm - Notice To ExplainMyra Coronado100% (3)
- Guitar Setup GuideDocument6 pagesGuitar Setup GuideAlex StihiNo ratings yet
- Moniginis Case StudyDocument11 pagesMoniginis Case StudyNikhil AroraNo ratings yet
- 103 April 2000 SolutionDocument10 pages103 April 2000 SolutionKanika KanodiaNo ratings yet
- Continued Fractions and The Polygamma FunctionsDocument11 pagesContinued Fractions and The Polygamma Functionsdavid_bhattNo ratings yet
- Luminy Sep2006Document12 pagesLuminy Sep2006Leonardo BossiNo ratings yet
- Pair of Straight LinesDocument6 pagesPair of Straight LinesPRATHAMESH KodoleNo ratings yet
- Statistics 580 The EM AlgorithmDocument28 pagesStatistics 580 The EM AlgorithmyanxiaNo ratings yet
- Generalized Linear Model: Badr MissaouiDocument35 pagesGeneralized Linear Model: Badr MissaouiAbu Ahsan Al FatanahNo ratings yet
- Complex Arithmetic Through CordicDocument11 pagesComplex Arithmetic Through CordicZhi ChenNo ratings yet
- Tutorial Sheet 3Document2 pagesTutorial Sheet 3yash sononeNo ratings yet
- Polyfit ManualDocument4 pagesPolyfit ManualudayNo ratings yet
- LimitsDocument8 pagesLimitsAkshith IsolaNo ratings yet
- Mathematical Argument DraftDocument15 pagesMathematical Argument DraftBen Matthew Alferez CoNo ratings yet
- On Alternating Subsets of Integers: S.M.TannyDocument4 pagesOn Alternating Subsets of Integers: S.M.TannyCharlie PinedoNo ratings yet
- Qualitative Graphical Representation of Nyquist PlotsDocument20 pagesQualitative Graphical Representation of Nyquist PlotsSazy TP MisbidNo ratings yet
- Transfer Function ProsesDocument34 pagesTransfer Function ProsesMalasari NasutionNo ratings yet
- (1971) On Equidistant Cubic Spline Interpolation (Schoenberg)Document6 pages(1971) On Equidistant Cubic Spline Interpolation (Schoenberg)mlpsbirtNo ratings yet
- Analytic Continuation Dirichlet SeriesDocument6 pagesAnalytic Continuation Dirichlet SeriesTyterbipNo ratings yet
- University of Manitoba, CanadaDocument12 pagesUniversity of Manitoba, CanadaramziNo ratings yet
- Werner, Raab - The Truth of Riemann HypothesisDocument11 pagesWerner, Raab - The Truth of Riemann HypothesisJulie KalpoNo ratings yet
- 3P0 Wave Function PDFDocument30 pages3P0 Wave Function PDFMario SánchezNo ratings yet
- Transcendental Entire Functions of Finite Order Sharing Two Sets of Small Functions With Their Shift Differential OperatorsDocument16 pagesTranscendental Entire Functions of Finite Order Sharing Two Sets of Small Functions With Their Shift Differential OperatorsvedaNo ratings yet
- 9.5 The Transfer Function: N N N M M MDocument11 pages9.5 The Transfer Function: N N N M M MSeban AugustineNo ratings yet
- Journal of Pure and Applied Algebra 11 (1977) 53-59. at North-Holland Publishing CompanyDocument7 pagesJournal of Pure and Applied Algebra 11 (1977) 53-59. at North-Holland Publishing CompanyNguyễn Đức NgàNo ratings yet
- 2019 AW (Summer) Sem III Mathematics IIIDocument3 pages2019 AW (Summer) Sem III Mathematics IIIRakesh JoshiNo ratings yet
- Autoregressive Neural NetworkDocument56 pagesAutoregressive Neural NetworkTejaNo ratings yet
- In-Plane Behavior of Beam-ColumnsDocument27 pagesIn-Plane Behavior of Beam-ColumnsQazi Abdul MoeedNo ratings yet
- Narayana Educational Society: Star Super Chaina Campus QuizDocument4 pagesNarayana Educational Society: Star Super Chaina Campus QuizAkshith IsolaNo ratings yet
- TC Asgn3-1Document2 pagesTC Asgn3-1Pradnya UkeyNo ratings yet
- 3.use of Laplase Transform PDFDocument5 pages3.use of Laplase Transform PDFLeonard PhilipNo ratings yet
- MTHS2007 Formula SheetwithtablescorrectedDocument3 pagesMTHS2007 Formula SheetwithtablescorrectedBenjamin OpokuNo ratings yet
- SM212 Practice Test 3, Prof Joyner: Sin (T) (The Convolution of TDocument5 pagesSM212 Practice Test 3, Prof Joyner: Sin (T) (The Convolution of THelbert PaatNo ratings yet
- Answer To ExercisesDocument65 pagesAnswer To ExercisesMarco Antonio Tumiri LópezNo ratings yet
- ch03 Sol FG 10thDocument83 pagesch03 Sol FG 10th김서진No ratings yet
- 1958 11sequencesDocument11 pages1958 11sequencesvahidmesic45No ratings yet
- Sergey K. SekatskiiDocument9 pagesSergey K. SekatskiipuyoshitNo ratings yet
- CH 30Document12 pagesCH 30aNo ratings yet
- K, R R R R JK Exp) R, R (G: (3) Finite-Difference Time-Domain (FDTD) MethodDocument8 pagesK, R R R R JK Exp) R, R (G: (3) Finite-Difference Time-Domain (FDTD) MethodJosNo ratings yet
- Bardaro 2012Document17 pagesBardaro 2012beharNo ratings yet
- Rad 1Document11 pagesRad 1digitalnapismenost2022No ratings yet
- Advanced Mathematics 2 Jan 2014Document2 pagesAdvanced Mathematics 2 Jan 2014Prasad C MNo ratings yet
- Cycle Structure of Affine Transformations of Vector Spaces Over GF (P)Document5 pagesCycle Structure of Affine Transformations of Vector Spaces Over GF (P)polonium rescentiNo ratings yet
- CLRS Solution Chapter 32Document10 pagesCLRS Solution Chapter 32Kawsar AhmedNo ratings yet
- 117Document11 pages117Mohammad Imran ShafiNo ratings yet
- Unit 3 Common Fourier Transforms Questions and Answers - Sanfoundry PDFDocument8 pagesUnit 3 Common Fourier Transforms Questions and Answers - Sanfoundry PDFzohaibNo ratings yet
- HW1 SolutionsDocument3 pagesHW1 SolutionsMuhammad AbubakerNo ratings yet
- Hopf Bifurcation For FlowsDocument5 pagesHopf Bifurcation For FlowsKyostaa MNo ratings yet
- On Certain Schlomilch-Type SeriesDocument13 pagesOn Certain Schlomilch-Type Seriesdavid_bhattNo ratings yet
- 8 X TransferDocument12 pages8 X TransferTaku Angwa Otto CHENo ratings yet
- P524 Higher-GenusDocument3 pagesP524 Higher-Genusm rNo ratings yet
- Calculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschDocument10 pagesCalculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschlapuNo ratings yet
- Solutions: (Sect, Tant) T T (2cost, 3sint)Document52 pagesSolutions: (Sect, Tant) T T (2cost, 3sint)DrGudimella Vrk SagarNo ratings yet
- Ps 1Document25 pagesPs 1Khả UyênNo ratings yet
- Indian Institute of Technology Roorkee Department of Electronics & Computer Engineering Signals & Systems (ECN 203) Tutorial Sheet No: 5Document2 pagesIndian Institute of Technology Roorkee Department of Electronics & Computer Engineering Signals & Systems (ECN 203) Tutorial Sheet No: 5Black ReaperNo ratings yet
- E-Caps-10: Mathematics: CF & Second Step For JEE (Main & Advanced) - 2020Document3 pagesE-Caps-10: Mathematics: CF & Second Step For JEE (Main & Advanced) - 2020Gaurav SinghNo ratings yet
- Jee Main 2021 PYQDocument422 pagesJee Main 2021 PYQAnant JainNo ratings yet
- HW 5Document6 pagesHW 5Нурболат ТаласбайNo ratings yet
- Application of Definite IntegrationDocument6 pagesApplication of Definite IntegrationAaditya HasabnisNo ratings yet
- Excel Study Guide - Solutions 2Document5 pagesExcel Study Guide - Solutions 2Yon Seo YooNo ratings yet
- Linear Regression by Maximum Likelihood Maximumm A Posteriori and Bayesian LearningDocument14 pagesLinear Regression by Maximum Likelihood Maximumm A Posteriori and Bayesian LearningAlex StihiNo ratings yet
- Statistical LearningDocument25 pagesStatistical LearningAlex StihiNo ratings yet
- MISO ARX TheoryDocument29 pagesMISO ARX TheoryAlex StihiNo ratings yet
- Columbus Tubes 2018 Catalogue V3 PDFDocument34 pagesColumbus Tubes 2018 Catalogue V3 PDFAlex StihiNo ratings yet
- Sparse Gaussian Process ApproximationsDocument119 pagesSparse Gaussian Process ApproximationsAlex StihiNo ratings yet
- Advanced Signal Processing Linear Stochastic ProcessesDocument66 pagesAdvanced Signal Processing Linear Stochastic ProcessesAlex StihiNo ratings yet
- Advanced Signal Processing Introduction To Estimation TheoryDocument40 pagesAdvanced Signal Processing Introduction To Estimation TheoryAlex StihiNo ratings yet
- Tutorial Sheet 5Document1 pageTutorial Sheet 5Alex StihiNo ratings yet
- Trek Emonda ALR 5 Disc SpecificationsDocument2 pagesTrek Emonda ALR 5 Disc SpecificationsAlex StihiNo ratings yet
- Ansys Fluent Guide - Creating Simple GeometriesDocument18 pagesAnsys Fluent Guide - Creating Simple GeometriesAlex StihiNo ratings yet
- Cheats For GTA San AndreasDocument4 pagesCheats For GTA San AndreasAlex StihiNo ratings yet
- E-Learning Presentation by Slidesgo PDFDocument13 pagesE-Learning Presentation by Slidesgo PDFABHISHEK CHANCHALNo ratings yet
- Analysis of MichelinDocument1 pageAnalysis of MichelinreganhinesNo ratings yet
- HAIL MARY (Je Vous Salue Marie) : SortieDocument1 pageHAIL MARY (Je Vous Salue Marie) : SortieFidèle Borîse AgrNo ratings yet
- Final Report - Foot Orthosis PDFDocument79 pagesFinal Report - Foot Orthosis PDFAdnan4466No ratings yet
- The Evil Consequence of Insulting Muhammad ( ) (Notes) - AuthenticTauheed PublicationsDocument17 pagesThe Evil Consequence of Insulting Muhammad ( ) (Notes) - AuthenticTauheed PublicationsAuthenticTauheedNo ratings yet
- History of CanadaDocument34 pagesHistory of Canada'Rafique Ahmed KhokharNo ratings yet
- Averia v. AveriaDocument12 pagesAveria v. AveriaEmma Ruby Aguilar-ApradoNo ratings yet
- Micro-Teach LPDocument5 pagesMicro-Teach LPapi-509217128No ratings yet
- 1Document2 pages1japonpuntocomNo ratings yet
- Accenture Building Analytics Driven OrganizationDocument16 pagesAccenture Building Analytics Driven Organizationpeterche100% (2)
- Various Committees On Corporate GovernanceDocument33 pagesVarious Committees On Corporate GovernanceAarti Chavan100% (4)
- Ambag Ni Dexter Beig Sa Meridian HehezDocument4 pagesAmbag Ni Dexter Beig Sa Meridian HehezALLYSSA JEAN ASCANNo ratings yet
- Sermon Title:: Four Principles of VictoryDocument6 pagesSermon Title:: Four Principles of VictoryGlenn SampayanNo ratings yet
- Transcendentalism UnitDocument14 pagesTranscendentalism Unitapi-402466117No ratings yet
- Research ReviewerDocument14 pagesResearch ReviewerSnowball MeowwNo ratings yet
- Operating Room TechniqueDocument2 pagesOperating Room TechniqueDENNROSE DECLARONo ratings yet
- Simla Agreement 1972Document1 pageSimla Agreement 1972Neil DevNo ratings yet
- Management of Neuromuscular Hip Dysplasia In.8Document7 pagesManagement of Neuromuscular Hip Dysplasia In.8El encantador De chairosNo ratings yet
- Capital One Doing Business The Digital Way 0Document7 pagesCapital One Doing Business The Digital Way 0Santanu MukherjeeNo ratings yet
- Cavitation PaperDocument6 pagesCavitation PaperTony KadatzNo ratings yet
- Aws Training and Certification PuneDocument12 pagesAws Training and Certification PuneakttripathiNo ratings yet
- Fronting in English With Reference To TranslationDocument16 pagesFronting in English With Reference To TranslationNi Wayan Eni SuastiniNo ratings yet
- Math TriviaDocument1 pageMath TriviaAnonymous V0YlTN100% (1)
- Bing Pas Ganjil 2022-2023Document8 pagesBing Pas Ganjil 2022-2023karci ardianyNo ratings yet
- ShigalovismDocument1 pageShigalovismkatzenklohNo ratings yet
- CT04 Voice LessonsDocument13 pagesCT04 Voice LessonsGlydelMorionInsoNo ratings yet
- Minimal Hepatitis Clinical Case - by SlidesgoDocument85 pagesMinimal Hepatitis Clinical Case - by SlidesgoAndi Annisa DianputriNo ratings yet
- Blackboard Manage Data SourcesDocument52 pagesBlackboard Manage Data SourcesAlexToaderNo ratings yet





































































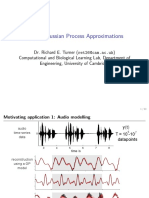

































Download as pdf or txt
You might also like
- Wren 80i Gas Turbine Engine Tech SpecsDocument25 pagesWren 80i Gas Turbine Engine Tech SpecsAlex Stihi100% (1)
- Time Series Analysis Henrik MadsenDocument156 pagesTime Series Analysis Henrik MadsenAlex Stihi100% (1)
- FreeFEM Tutorial ShovkunDocument6 pagesFreeFEM Tutorial ShovkunMohamad TayeaNo ratings yet
- Form - Notice To ExplainDocument2 pagesForm - Notice To ExplainMyra Coronado100% (3)
- Guitar Setup GuideDocument6 pagesGuitar Setup GuideAlex StihiNo ratings yet
- Moniginis Case StudyDocument11 pagesMoniginis Case StudyNikhil AroraNo ratings yet
- 103 April 2000 SolutionDocument10 pages103 April 2000 SolutionKanika KanodiaNo ratings yet
- Continued Fractions and The Polygamma FunctionsDocument11 pagesContinued Fractions and The Polygamma Functionsdavid_bhattNo ratings yet
- Luminy Sep2006Document12 pagesLuminy Sep2006Leonardo BossiNo ratings yet
- Pair of Straight LinesDocument6 pagesPair of Straight LinesPRATHAMESH KodoleNo ratings yet
- Statistics 580 The EM AlgorithmDocument28 pagesStatistics 580 The EM AlgorithmyanxiaNo ratings yet
- Generalized Linear Model: Badr MissaouiDocument35 pagesGeneralized Linear Model: Badr MissaouiAbu Ahsan Al FatanahNo ratings yet
- Complex Arithmetic Through CordicDocument11 pagesComplex Arithmetic Through CordicZhi ChenNo ratings yet
- Tutorial Sheet 3Document2 pagesTutorial Sheet 3yash sononeNo ratings yet
- Polyfit ManualDocument4 pagesPolyfit ManualudayNo ratings yet
- LimitsDocument8 pagesLimitsAkshith IsolaNo ratings yet
- Mathematical Argument DraftDocument15 pagesMathematical Argument DraftBen Matthew Alferez CoNo ratings yet
- On Alternating Subsets of Integers: S.M.TannyDocument4 pagesOn Alternating Subsets of Integers: S.M.TannyCharlie PinedoNo ratings yet
- Qualitative Graphical Representation of Nyquist PlotsDocument20 pagesQualitative Graphical Representation of Nyquist PlotsSazy TP MisbidNo ratings yet
- Transfer Function ProsesDocument34 pagesTransfer Function ProsesMalasari NasutionNo ratings yet
- (1971) On Equidistant Cubic Spline Interpolation (Schoenberg)Document6 pages(1971) On Equidistant Cubic Spline Interpolation (Schoenberg)mlpsbirtNo ratings yet
- Analytic Continuation Dirichlet SeriesDocument6 pagesAnalytic Continuation Dirichlet SeriesTyterbipNo ratings yet
- University of Manitoba, CanadaDocument12 pagesUniversity of Manitoba, CanadaramziNo ratings yet
- Werner, Raab - The Truth of Riemann HypothesisDocument11 pagesWerner, Raab - The Truth of Riemann HypothesisJulie KalpoNo ratings yet
- 3P0 Wave Function PDFDocument30 pages3P0 Wave Function PDFMario SánchezNo ratings yet
- Transcendental Entire Functions of Finite Order Sharing Two Sets of Small Functions With Their Shift Differential OperatorsDocument16 pagesTranscendental Entire Functions of Finite Order Sharing Two Sets of Small Functions With Their Shift Differential OperatorsvedaNo ratings yet
- 9.5 The Transfer Function: N N N M M MDocument11 pages9.5 The Transfer Function: N N N M M MSeban AugustineNo ratings yet
- Journal of Pure and Applied Algebra 11 (1977) 53-59. at North-Holland Publishing CompanyDocument7 pagesJournal of Pure and Applied Algebra 11 (1977) 53-59. at North-Holland Publishing CompanyNguyễn Đức NgàNo ratings yet
- 2019 AW (Summer) Sem III Mathematics IIIDocument3 pages2019 AW (Summer) Sem III Mathematics IIIRakesh JoshiNo ratings yet
- Autoregressive Neural NetworkDocument56 pagesAutoregressive Neural NetworkTejaNo ratings yet
- In-Plane Behavior of Beam-ColumnsDocument27 pagesIn-Plane Behavior of Beam-ColumnsQazi Abdul MoeedNo ratings yet
- Narayana Educational Society: Star Super Chaina Campus QuizDocument4 pagesNarayana Educational Society: Star Super Chaina Campus QuizAkshith IsolaNo ratings yet
- TC Asgn3-1Document2 pagesTC Asgn3-1Pradnya UkeyNo ratings yet
- 3.use of Laplase Transform PDFDocument5 pages3.use of Laplase Transform PDFLeonard PhilipNo ratings yet
- MTHS2007 Formula SheetwithtablescorrectedDocument3 pagesMTHS2007 Formula SheetwithtablescorrectedBenjamin OpokuNo ratings yet
- SM212 Practice Test 3, Prof Joyner: Sin (T) (The Convolution of TDocument5 pagesSM212 Practice Test 3, Prof Joyner: Sin (T) (The Convolution of THelbert PaatNo ratings yet
- Answer To ExercisesDocument65 pagesAnswer To ExercisesMarco Antonio Tumiri LópezNo ratings yet
- ch03 Sol FG 10thDocument83 pagesch03 Sol FG 10th김서진No ratings yet
- 1958 11sequencesDocument11 pages1958 11sequencesvahidmesic45No ratings yet
- Sergey K. SekatskiiDocument9 pagesSergey K. SekatskiipuyoshitNo ratings yet
- CH 30Document12 pagesCH 30aNo ratings yet
- K, R R R R JK Exp) R, R (G: (3) Finite-Difference Time-Domain (FDTD) MethodDocument8 pagesK, R R R R JK Exp) R, R (G: (3) Finite-Difference Time-Domain (FDTD) MethodJosNo ratings yet
- Bardaro 2012Document17 pagesBardaro 2012beharNo ratings yet
- Rad 1Document11 pagesRad 1digitalnapismenost2022No ratings yet
- Advanced Mathematics 2 Jan 2014Document2 pagesAdvanced Mathematics 2 Jan 2014Prasad C MNo ratings yet
- Cycle Structure of Affine Transformations of Vector Spaces Over GF (P)Document5 pagesCycle Structure of Affine Transformations of Vector Spaces Over GF (P)polonium rescentiNo ratings yet
- CLRS Solution Chapter 32Document10 pagesCLRS Solution Chapter 32Kawsar AhmedNo ratings yet
- 117Document11 pages117Mohammad Imran ShafiNo ratings yet
- Unit 3 Common Fourier Transforms Questions and Answers - Sanfoundry PDFDocument8 pagesUnit 3 Common Fourier Transforms Questions and Answers - Sanfoundry PDFzohaibNo ratings yet
- HW1 SolutionsDocument3 pagesHW1 SolutionsMuhammad AbubakerNo ratings yet
- Hopf Bifurcation For FlowsDocument5 pagesHopf Bifurcation For FlowsKyostaa MNo ratings yet
- On Certain Schlomilch-Type SeriesDocument13 pagesOn Certain Schlomilch-Type Seriesdavid_bhattNo ratings yet
- 8 X TransferDocument12 pages8 X TransferTaku Angwa Otto CHENo ratings yet
- P524 Higher-GenusDocument3 pagesP524 Higher-Genusm rNo ratings yet
- Calculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschDocument10 pagesCalculation of Gauss Quadrature Rules : by Gene H. Golub and John H. WelschlapuNo ratings yet
- Solutions: (Sect, Tant) T T (2cost, 3sint)Document52 pagesSolutions: (Sect, Tant) T T (2cost, 3sint)DrGudimella Vrk SagarNo ratings yet
- Ps 1Document25 pagesPs 1Khả UyênNo ratings yet
- Indian Institute of Technology Roorkee Department of Electronics & Computer Engineering Signals & Systems (ECN 203) Tutorial Sheet No: 5Document2 pagesIndian Institute of Technology Roorkee Department of Electronics & Computer Engineering Signals & Systems (ECN 203) Tutorial Sheet No: 5Black ReaperNo ratings yet
- E-Caps-10: Mathematics: CF & Second Step For JEE (Main & Advanced) - 2020Document3 pagesE-Caps-10: Mathematics: CF & Second Step For JEE (Main & Advanced) - 2020Gaurav SinghNo ratings yet
- Jee Main 2021 PYQDocument422 pagesJee Main 2021 PYQAnant JainNo ratings yet
- HW 5Document6 pagesHW 5Нурболат ТаласбайNo ratings yet
- Application of Definite IntegrationDocument6 pagesApplication of Definite IntegrationAaditya HasabnisNo ratings yet
- Excel Study Guide - Solutions 2Document5 pagesExcel Study Guide - Solutions 2Yon Seo YooNo ratings yet
- Linear Regression by Maximum Likelihood Maximumm A Posteriori and Bayesian LearningDocument14 pagesLinear Regression by Maximum Likelihood Maximumm A Posteriori and Bayesian LearningAlex StihiNo ratings yet
- Statistical LearningDocument25 pagesStatistical LearningAlex StihiNo ratings yet
- MISO ARX TheoryDocument29 pagesMISO ARX TheoryAlex StihiNo ratings yet
- Columbus Tubes 2018 Catalogue V3 PDFDocument34 pagesColumbus Tubes 2018 Catalogue V3 PDFAlex StihiNo ratings yet
- Sparse Gaussian Process ApproximationsDocument119 pagesSparse Gaussian Process ApproximationsAlex StihiNo ratings yet
- Advanced Signal Processing Linear Stochastic ProcessesDocument66 pagesAdvanced Signal Processing Linear Stochastic ProcessesAlex StihiNo ratings yet
- Advanced Signal Processing Introduction To Estimation TheoryDocument40 pagesAdvanced Signal Processing Introduction To Estimation TheoryAlex StihiNo ratings yet
- Tutorial Sheet 5Document1 pageTutorial Sheet 5Alex StihiNo ratings yet
- Trek Emonda ALR 5 Disc SpecificationsDocument2 pagesTrek Emonda ALR 5 Disc SpecificationsAlex StihiNo ratings yet
- Ansys Fluent Guide - Creating Simple GeometriesDocument18 pagesAnsys Fluent Guide - Creating Simple GeometriesAlex StihiNo ratings yet
- Cheats For GTA San AndreasDocument4 pagesCheats For GTA San AndreasAlex StihiNo ratings yet
- E-Learning Presentation by Slidesgo PDFDocument13 pagesE-Learning Presentation by Slidesgo PDFABHISHEK CHANCHALNo ratings yet
- Analysis of MichelinDocument1 pageAnalysis of MichelinreganhinesNo ratings yet
- HAIL MARY (Je Vous Salue Marie) : SortieDocument1 pageHAIL MARY (Je Vous Salue Marie) : SortieFidèle Borîse AgrNo ratings yet
- Final Report - Foot Orthosis PDFDocument79 pagesFinal Report - Foot Orthosis PDFAdnan4466No ratings yet
- The Evil Consequence of Insulting Muhammad ( ) (Notes) - AuthenticTauheed PublicationsDocument17 pagesThe Evil Consequence of Insulting Muhammad ( ) (Notes) - AuthenticTauheed PublicationsAuthenticTauheedNo ratings yet
- History of CanadaDocument34 pagesHistory of Canada'Rafique Ahmed KhokharNo ratings yet
- Averia v. AveriaDocument12 pagesAveria v. AveriaEmma Ruby Aguilar-ApradoNo ratings yet
- Micro-Teach LPDocument5 pagesMicro-Teach LPapi-509217128No ratings yet
- 1Document2 pages1japonpuntocomNo ratings yet
- Accenture Building Analytics Driven OrganizationDocument16 pagesAccenture Building Analytics Driven Organizationpeterche100% (2)
- Various Committees On Corporate GovernanceDocument33 pagesVarious Committees On Corporate GovernanceAarti Chavan100% (4)
- Ambag Ni Dexter Beig Sa Meridian HehezDocument4 pagesAmbag Ni Dexter Beig Sa Meridian HehezALLYSSA JEAN ASCANNo ratings yet
- Sermon Title:: Four Principles of VictoryDocument6 pagesSermon Title:: Four Principles of VictoryGlenn SampayanNo ratings yet
- Transcendentalism UnitDocument14 pagesTranscendentalism Unitapi-402466117No ratings yet
- Research ReviewerDocument14 pagesResearch ReviewerSnowball MeowwNo ratings yet
- Operating Room TechniqueDocument2 pagesOperating Room TechniqueDENNROSE DECLARONo ratings yet
- Simla Agreement 1972Document1 pageSimla Agreement 1972Neil DevNo ratings yet
- Management of Neuromuscular Hip Dysplasia In.8Document7 pagesManagement of Neuromuscular Hip Dysplasia In.8El encantador De chairosNo ratings yet
- Capital One Doing Business The Digital Way 0Document7 pagesCapital One Doing Business The Digital Way 0Santanu MukherjeeNo ratings yet
- Cavitation PaperDocument6 pagesCavitation PaperTony KadatzNo ratings yet
- Aws Training and Certification PuneDocument12 pagesAws Training and Certification PuneakttripathiNo ratings yet
- Fronting in English With Reference To TranslationDocument16 pagesFronting in English With Reference To TranslationNi Wayan Eni SuastiniNo ratings yet
- Math TriviaDocument1 pageMath TriviaAnonymous V0YlTN100% (1)
- Bing Pas Ganjil 2022-2023Document8 pagesBing Pas Ganjil 2022-2023karci ardianyNo ratings yet
- ShigalovismDocument1 pageShigalovismkatzenklohNo ratings yet
- CT04 Voice LessonsDocument13 pagesCT04 Voice LessonsGlydelMorionInsoNo ratings yet
- Minimal Hepatitis Clinical Case - by SlidesgoDocument85 pagesMinimal Hepatitis Clinical Case - by SlidesgoAndi Annisa DianputriNo ratings yet
- Blackboard Manage Data SourcesDocument52 pagesBlackboard Manage Data SourcesAlexToaderNo ratings yet