Download as pdf or txt
You might also like
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVZohaib Imam88% (16)
- Capgemini Interview Questions & AnswersDocument11 pagesCapgemini Interview Questions & AnswersVamsi Karthik50% (10)
- Data Preprocessing in Machine LearningDocument27 pagesData Preprocessing in Machine LearningNaashit HashmiNo ratings yet
- Psychology of Web DesignDocument271 pagesPsychology of Web DesignAlexandru Cosor100% (1)
- Styrene Pressure Drop Tutorial ASPEN PDFDocument10 pagesStyrene Pressure Drop Tutorial ASPEN PDFTomNo ratings yet
- ML (Prac1)Document12 pagesML (Prac1)dk9859164No ratings yet
- Implementing Artificial Neural Network in Python From ScratchDocument16 pagesImplementing Artificial Neural Network in Python From Scratchsidrakhalid1357No ratings yet
- How To Prepare Your Dataset For Machine Learning in PythonDocument14 pagesHow To Prepare Your Dataset For Machine Learning in PythonBulbula KumedaNo ratings yet
- FDS Unit 2Document8 pagesFDS Unit 2Amit AdhikariNo ratings yet
- Exp 6Document9 pagesExp 6hemanthsairavipatiNo ratings yet
- Principal Component AnalysisDocument13 pagesPrincipal Component AnalysisShil ShambharkarNo ratings yet
- Group A Assignment No2 WriteupDocument9 pagesGroup A Assignment No2 Writeup403 Chaudhari Sanika SagarNo ratings yet
- CSL0777 L09Document29 pagesCSL0777 L09Konkobo Ulrich ArthurNo ratings yet
- A Neural Network Model Using PythonDocument10 pagesA Neural Network Model Using PythonKarol SkowronskiNo ratings yet
- Surabhi Charu ProjectDocument16 pagesSurabhi Charu Projectsachin joshiNo ratings yet
- 7 محاضراتDocument36 pages7 محاضراتnnnn403010No ratings yet
- Chapter-4 Data ManipulationDocument33 pagesChapter-4 Data Manipulation4PS19EC071 Lakshmi.MNo ratings yet
- A COMPLETE GUIDE TO PRINCIPAL COMPONENT ANALYSIS in ML 1598272724Document16 pagesA COMPLETE GUIDE TO PRINCIPAL COMPONENT ANALYSIS in ML 1598272724「瞳」你分享No ratings yet
- Neuro Data EngineeringDocument11 pagesNeuro Data EngineeringNoob masterNo ratings yet
- 2.1 ML (Implementation of Simple Linear Regression in Python)Document8 pages2.1 ML (Implementation of Simple Linear Regression in Python)Muhammad shayan umarNo ratings yet
- Analysis and Prediction of House Prices by Linear Regression ModelDocument91 pagesAnalysis and Prediction of House Prices by Linear Regression Model2001 SinceNo ratings yet
- Unit 2 MLMMDocument41 pagesUnit 2 MLMMface the fearNo ratings yet
- Curve Fitting in MATLAB NotesDocument7 pagesCurve Fitting in MATLAB Notesextramailm2No ratings yet
- Data Understanding and PreparationDocument48 pagesData Understanding and PreparationMohamedYounesNo ratings yet
- FAQ - ReCellDocument5 pagesFAQ - ReCellNkechi KokoNo ratings yet
- ML Unit 2Document41 pagesML Unit 2abhijit kateNo ratings yet
- Data PreprocessingDocument47 pagesData Preprocessingyeswanth chowdary nidamanuriNo ratings yet
- Tutorial On Stored Procedures (For Use in VB)Document5 pagesTutorial On Stored Procedures (For Use in VB)Justin Shinorlax YoonAddictNo ratings yet
- Project 1Document4 pagesProject 1aqsa yousafNo ratings yet
- Table of Contents:: Predictnow - Ai Lets You Apply Machine Learning Predictions To Your Data Without Any ProgrammingDocument15 pagesTable of Contents:: Predictnow - Ai Lets You Apply Machine Learning Predictions To Your Data Without Any ProgrammingsgNo ratings yet
- Explorotary Data AnalysisDocument30 pagesExplorotary Data AnalysisSanjaya Kumar KhadangaNo ratings yet
- MLP Project - VarunDocument6 pagesMLP Project - VarunTangirala Ashwini100% (1)
- What Is Compiler in Datastage - Compilation Process in DatastageDocument14 pagesWhat Is Compiler in Datastage - Compilation Process in DatastageshivnatNo ratings yet
- Deep LearningDocument25 pagesDeep Learningdevansh misraNo ratings yet
- MLDocument49 pagesMLgetap85298No ratings yet
- MIT6 0002F16 ProblemSet5Document13 pagesMIT6 0002F16 ProblemSet5DevendraReddyPoreddyNo ratings yet
- Data Management: I. Importing Data From Excel To SPSSDocument9 pagesData Management: I. Importing Data From Excel To SPSSLucyl MendozaNo ratings yet
- Big Data AnalysisDocument38 pagesBig Data Analysisrathodrohit2121No ratings yet
- Building Good Training Sets UNIT 1 PART2Document46 pagesBuilding Good Training Sets UNIT 1 PART2Aditya SharmaNo ratings yet
- Multi-Output Classification With Machine LearningDocument10 pagesMulti-Output Classification With Machine Learningpanigrahisuman7No ratings yet
- 2324 BigData Lab3Document6 pages2324 BigData Lab3Elie Al HowayekNo ratings yet
- Machine Learning in PythonDocument5 pagesMachine Learning in PythonKatlo KayNo ratings yet
- Lab 08 - Data PreprocessingDocument9 pagesLab 08 - Data PreprocessingridaNo ratings yet
- Regression Week 2: Multiple Linear Regression Assignment 1: If You Are Using Graphlab CreateDocument1 pageRegression Week 2: Multiple Linear Regression Assignment 1: If You Are Using Graphlab CreateSamNo ratings yet
- Pratical1 TRP 2013 2014Document3 pagesPratical1 TRP 2013 2014António MarquesNo ratings yet
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Develop A Program To Implement Data Preprocessing UsingDocument19 pagesDevelop A Program To Implement Data Preprocessing UsingFucker JamunNo ratings yet
- Lab Manual-ANNDocument7 pagesLab Manual-ANNfaizan majidNo ratings yet
- Feature EngineeringDocument20 pagesFeature Engineeringamrendra kumarNo ratings yet
- Machine Learning 2Document45 pagesMachine Learning 2Arti RajuNo ratings yet
- Machine Learning SVM - SupervisedDocument32 pagesMachine Learning SVM - SuperviseddanielNo ratings yet
- Exercise and Experiment 3Document14 pagesExercise and Experiment 3h8792670No ratings yet
- Lab 1: Preprocessing Using PythonDocument5 pagesLab 1: Preprocessing Using PythonPF 21 Disha GidwaniNo ratings yet
- Using Categorical Data With One Hot Encoding - Kaggle PDFDocument4 pagesUsing Categorical Data With One Hot Encoding - Kaggle PDFMathias MbizvoNo ratings yet
- Project Occupancy Alfonso Vicente AraguesDocument18 pagesProject Occupancy Alfonso Vicente AraguesAlfonsoNo ratings yet
- Excel HintsDocument3 pagesExcel Hintsmaxillo693No ratings yet
- Chapter-2. Array & StringDocument15 pagesChapter-2. Array & StringQuazi Hasnat IrfanNo ratings yet
- 2 - T.test ActivityDocument13 pages2 - T.test ActivitySirius2409No ratings yet
- Project - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Document38 pagesProject - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Ravi KotharuNo ratings yet
- Mining and Visualising Real-World Data: About This ModuleDocument16 pagesMining and Visualising Real-World Data: About This ModuleAlexandra Veres100% (1)
- Prasanth CV 1657961362Document1 pagePrasanth CV 1657961362NAVYA TadisettyNo ratings yet
- Admn Updates Summer24 - 1716899779588Document13 pagesAdmn Updates Summer24 - 1716899779588NAVYA TadisettyNo ratings yet
- By Parimal BandalDocument9 pagesBy Parimal BandalNAVYA TadisettyNo ratings yet
- Digitally Signed by Shobha Ranjit Shetty Date: 2024.05.18 14:20:01 +05'30'Document71 pagesDigitally Signed by Shobha Ranjit Shetty Date: 2024.05.18 14:20:01 +05'30'NAVYA TadisettyNo ratings yet
- Infosys PartyDocument13 pagesInfosys PartyNAVYA TadisettyNo ratings yet
- RRB Group D Exam: Previous Year PaperDocument36 pagesRRB Group D Exam: Previous Year PaperNAVYA TadisettyNo ratings yet
- ITB1 Documentation Detection of Phishing Website Using MLDocument49 pagesITB1 Documentation Detection of Phishing Website Using MLNAVYA TadisettyNo ratings yet
- Indian History 4Document4 pagesIndian History 4NAVYA TadisettyNo ratings yet
- RPF SyllabusDocument3 pagesRPF SyllabusNAVYA TadisettyNo ratings yet
- Removed Few Points in ResumeDocument4 pagesRemoved Few Points in ResumeNAVYA TadisettyNo ratings yet
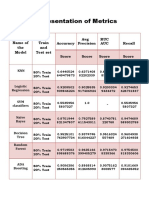
- Representation of Metrics: Name of The Model Train and Test Set Accuracy Avg Precision RUC AUC RecallDocument3 pagesRepresentation of Metrics: Name of The Model Train and Test Set Accuracy Avg Precision RUC AUC RecallNAVYA TadisettyNo ratings yet
- 2+ Salesforce ResumeDocument4 pages2+ Salesforce ResumeNAVYA TadisettyNo ratings yet
- Winter 24 Key PointsDocument56 pagesWinter 24 Key PointsNAVYA TadisettyNo ratings yet
- Python IntroductionDocument29 pagesPython IntroductionNAVYA TadisettyNo ratings yet
- Final - AI Associate DumpDocument108 pagesFinal - AI Associate DumpNAVYA TadisettyNo ratings yet
- V.K.R, V.N.B & A.G.K College of Engineering: Explain The Two Uses of Features in Machine LearningDocument2 pagesV.K.R, V.N.B & A.G.K College of Engineering: Explain The Two Uses of Features in Machine LearningNAVYA TadisettyNo ratings yet
- Machine Learning Most Compressive Perfect BookDocument136 pagesMachine Learning Most Compressive Perfect BookNAVYA TadisettyNo ratings yet
- Vignesh P-RojectDocument33 pagesVignesh P-RojectJITHINNo ratings yet
- AcademyFm - Ultimate Guide To Compression - V1Document19 pagesAcademyFm - Ultimate Guide To Compression - V1Ed O Edgar100% (2)
- Stratos 2700 Series: Bioptic Scanner/ScaleDocument2 pagesStratos 2700 Series: Bioptic Scanner/ScaleRiyan PratamaNo ratings yet
- Consuming-Web-Services-with-CSharpDocument20 pagesConsuming-Web-Services-with-CSharpAlexandre Rocha Lima e MarcondesNo ratings yet
- Desma Corporate Catalogue 2014Document20 pagesDesma Corporate Catalogue 2014Jigar M. Upadhyay100% (2)
- Disk Defrag Manual PDFDocument20 pagesDisk Defrag Manual PDFDondont DocNo ratings yet
- H-W22 Product Introduction V2 20070628Document24 pagesH-W22 Product Introduction V2 20070628marcelogiacobiniNo ratings yet
- 06 Implementing A Group Policy InfrastructureDocument44 pages06 Implementing A Group Policy Infrastructuremystic_guy100% (1)
- Compliance, Data and Identity ProtectionDocument48 pagesCompliance, Data and Identity ProtectionEcaterina Stan100% (1)
- Getting Started With Mastercam SolidsDocument78 pagesGetting Started With Mastercam SolidsKRATOS_SNo ratings yet
- English W - 5 Vol. Commentary - Holy Qur'an Online 3.6Document2 pagesEnglish W - 5 Vol. Commentary - Holy Qur'an Online 3.6Thomas WilsonNo ratings yet
- WWW - Nsw.gov - PH FaqsDocument4 pagesWWW - Nsw.gov - PH FaqsChristian CayabaNo ratings yet
- Optime BrochureDocument13 pagesOptime BrochureDuc Nguyen ThanhNo ratings yet
- 323 1701 190.3.r11.2 Backup Restore TL1 (Local) PDFDocument374 pages323 1701 190.3.r11.2 Backup Restore TL1 (Local) PDFMartin MakenaNo ratings yet
- KubernetesDocument17 pagesKubernetesAnkit GoyalNo ratings yet
- Advance Python ProgrammingDocument3 pagesAdvance Python ProgrammingJohnnyNo ratings yet
- Online Notice Board Project DocumentationDocument6 pagesOnline Notice Board Project DocumentationGm Lakshman100% (5)
- Leica GS18 DSDocument2 pagesLeica GS18 DSCRV2011No ratings yet
- Test Bank For Systems Analysis and Design 8th Edition Kendall DownloadDocument12 pagesTest Bank For Systems Analysis and Design 8th Edition Kendall DownloadCrystalDavisibng100% (24)
- Dpdzero AssessmentDocument12 pagesDpdzero AssessmenthiteshNo ratings yet
- Kerio Connect Admin Guide en 7.1.0 1792Document412 pagesKerio Connect Admin Guide en 7.1.0 1792Paul Viegas SousaNo ratings yet
- Pre PH.D Reg & Supple June 2015.Pdf - 260236Document19 pagesPre PH.D Reg & Supple June 2015.Pdf - 260236nims1964No ratings yet
- PLCDocument936 pagesPLCjulio cidNo ratings yet
- Assignment 2Document3 pagesAssignment 2Faizan Arif100% (2)
- MTH 212Document10 pagesMTH 212CA Renu Goyal100% (1)
- Critical Information Infrastructures Security: Erich Rome Marianthi Theocharidou Stephen WolthusenDocument269 pagesCritical Information Infrastructures Security: Erich Rome Marianthi Theocharidou Stephen WolthusenVikasNo ratings yet
- AcceptLetter LopreiatoDocument1 pageAcceptLetter LopreiatoPaola LopreiatoNo ratings yet
- Company Address 1 Address 2, Division, Suite # City StateDocument12 pagesCompany Address 1 Address 2, Division, Suite # City Statemdick1975No ratings yet