Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5834)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (350)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- GS 35F 0511T - 259Document21 pagesGS 35F 0511T - 259Vijaylaxmi DhakaNo ratings yet
- MIS602 - Assessment 3 - Database Case Study Report - Case Study - FinalDocument2 pagesMIS602 - Assessment 3 - Database Case Study Report - Case Study - FinalGabriel ZuanettiNo ratings yet
- Wcdma Call FlowDocument15 pagesWcdma Call FlowShantanu MukherjeeNo ratings yet
- Leica Spider Software SuiteDocument179 pagesLeica Spider Software Suiteأوسكار تشالي100% (1)
- Itil 4 Co-Create Value and Drive Business Success in The Digital EraDocument16 pagesItil 4 Co-Create Value and Drive Business Success in The Digital EraĐoàn Đức ĐềNo ratings yet
- 3-2 Cloud-RAN PDFDocument14 pages3-2 Cloud-RAN PDFShantanu MukherjeeNo ratings yet
- AAU3902 Installation Guide (04) (PDF) - EN PDFDocument75 pagesAAU3902 Installation Guide (04) (PDF) - EN PDFShantanu Mukherjee0% (1)
- AWS Amazon VPC Connectivity Options PDFDocument31 pagesAWS Amazon VPC Connectivity Options PDFShantanu MukherjeeNo ratings yet
- AAU3902 LTE CELL - No RRU Carrier Resources Available Troubleshooting Case MOPDocument3 pagesAAU3902 LTE CELL - No RRU Carrier Resources Available Troubleshooting Case MOPShantanu MukherjeeNo ratings yet
- Complete Sun Solaris Commands ListDocument32 pagesComplete Sun Solaris Commands ListShantanu Mukherjee0% (1)
- 5G Wireless TechnologyDocument30 pages5G Wireless TechnologyShantanu Mukherjee100% (2)
- Asynchronous Transfer Mode (ATM)Document34 pagesAsynchronous Transfer Mode (ATM)Shantanu MukherjeeNo ratings yet
- Rethinking Productivity in Software EngineeringDocument320 pagesRethinking Productivity in Software EngineeringWallie BillingsleyNo ratings yet
- Gis Data: Processing: Arctoolbox, Geoprocessing and ModelbuilderDocument41 pagesGis Data: Processing: Arctoolbox, Geoprocessing and ModelbuilderYounes NekkaNo ratings yet
- Symitar FoEP1Document9 pagesSymitar FoEP1charlie jwNo ratings yet
- Consume Azure Machine Learning Models in Power BI - TutorialDocument860 pagesConsume Azure Machine Learning Models in Power BI - TutorialElenaNo ratings yet
- CCSP SyllabusDocument2 pagesCCSP SyllabusChitij ChauhanNo ratings yet
- Trace LogDocument2,074 pagesTrace Logholagerman041995No ratings yet
- Final Lab Examination Version 1:: 3 December 2019Document11 pagesFinal Lab Examination Version 1:: 3 December 2019kashifNo ratings yet
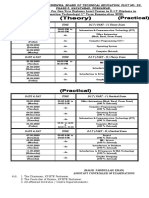
- DIT 1st Term Exam 2020 Date Sheet (Theory & Practical)Document1 pageDIT 1st Term Exam 2020 Date Sheet (Theory & Practical)Sana KhanNo ratings yet
- Amazon Interview QuestionsDocument17 pagesAmazon Interview QuestionsNagarajan Balasubramanian100% (1)
- Online Quiz Portal ProjectDocument55 pagesOnline Quiz Portal ProjectAnonymous fc1OJnbNo ratings yet
- Intel (R) SCS 7.0 User GuideDocument147 pagesIntel (R) SCS 7.0 User GuideRon DdashNo ratings yet
- Best Practices With SAS 9 Metadata Security: Paul Homes SAS Forum ANZ (12aug2010)Document23 pagesBest Practices With SAS 9 Metadata Security: Paul Homes SAS Forum ANZ (12aug2010)rajeshmsitNo ratings yet
- 2017 Advanced Computer Networks Homework 1Document6 pages2017 Advanced Computer Networks Homework 1Fadhli RahimNo ratings yet
- Connection of A SIMATIC S7-1x00 To A SQL Database: SQL / Tabular Data Stream (SQL)Document69 pagesConnection of A SIMATIC S7-1x00 To A SQL Database: SQL / Tabular Data Stream (SQL)tokgozcNo ratings yet
- Company Criteria - 3 Years 33 43Document11 pagesCompany Criteria - 3 Years 33 43Akshat PradhanNo ratings yet
- Sample Question Paper 1: Class Xii Computer Science (083) Term IiDocument13 pagesSample Question Paper 1: Class Xii Computer Science (083) Term IiHarpreet KaurNo ratings yet
- Composing Big Data Jobs: A Literature Review: Abdallah Elshamy CS 846 - Fall 2021Document15 pagesComposing Big Data Jobs: A Literature Review: Abdallah Elshamy CS 846 - Fall 2021Wei HuNo ratings yet
- Oracle 19c - Database Client Installation Guide For Microsoft WindowsDocument76 pagesOracle 19c - Database Client Installation Guide For Microsoft WindowsBupBeChanhNo ratings yet
- Project Control ProcedureDocument25 pagesProject Control ProcedureOscar PalaciosNo ratings yet
- Os Question BankDocument3 pagesOs Question Bankmeghal prajapatiNo ratings yet
- BGP Configuration Guide 1 - Cisco RoutersDocument3 pagesBGP Configuration Guide 1 - Cisco RoutersWaqasNo ratings yet
- OS Lab ManualDocument89 pagesOS Lab ManualLaiba BabarNo ratings yet
- Walkthrough 2Document38 pagesWalkthrough 2Bhavin PatelNo ratings yet
- Madhav - Rathod CVDocument1 pageMadhav - Rathod CVMadhav RathodNo ratings yet
- Template Jurnal Performa 2021Document17 pagesTemplate Jurnal Performa 2021GalihMaulanaGumilangPartIINo ratings yet
- COA Chapter 1 NotesDocument14 pagesCOA Chapter 1 NotesAmitesh ki class For engineeringNo ratings yet