Download as docx, pdf, or txt
You might also like
- INTRAPRENEURSHIPDocument16 pagesINTRAPRENEURSHIPABHISHEK SINGHNo ratings yet
- Dashboard Design by Michael Burch ..Document314 pagesDashboard Design by Michael Burch ..Omar FanoushNo ratings yet
- Segmentation at Sticks Kebob ShopDocument10 pagesSegmentation at Sticks Kebob ShopABHISHEK SINGHNo ratings yet
- Dragon Ball Z Final Stand AUTO FARM GUIDocument3 pagesDragon Ball Z Final Stand AUTO FARM GUIHelver OñateNo ratings yet
- Amazon KiranaDocument14 pagesAmazon KiranaABHISHEK SINGH100% (1)
- Basic Computer Skills - Module 1Document39 pagesBasic Computer Skills - Module 1Marvin RetutalNo ratings yet
- Activations, Loss Functions & Optimizers in MLDocument29 pagesActivations, Loss Functions & Optimizers in MLAniket DharNo ratings yet
- Soft Computing AssignmentDocument9 pagesSoft Computing AssignmentManohar SumanNo ratings yet
- Eem520l3 2023Document25 pagesEem520l3 2023Berkan TezcanNo ratings yet
- 3 Types of Gradient Descent Algorithms For Small & Large DatasetsDocument9 pages3 Types of Gradient Descent Algorithms For Small & Large Datasetscontactcenter2 LiderNo ratings yet
- Comparison of Gradient Descent Algorithms On Training Neural NetworksDocument20 pagesComparison of Gradient Descent Algorithms On Training Neural NetworksLoc LuongNo ratings yet
- CS 224n Assignment #3: Dependency Parsing: 1. Machine Learning & Neural Networks (8 Points)Document7 pagesCS 224n Assignment #3: Dependency Parsing: 1. Machine Learning & Neural Networks (8 Points)progisNo ratings yet
- Chap 2 Training Feed Forward Neural NetworksDocument22 pagesChap 2 Training Feed Forward Neural NetworksHRITWIK GHOSHNo ratings yet
- CS601 Machine Learning Unit 2 Notes 1672759753Document14 pagesCS601 Machine Learning Unit 2 Notes 1672759753XmaxNo ratings yet
- Op Tim IzationDocument22 pagesOp Tim IzationricsunNo ratings yet
- Acfrogd60he9sraxzzz4hguizwc9gn0rhy1l2ybdffmwwvtjqcqmhffvtpxgodsll Cw5pilxl6sjmbu7fqyymq8mxjhbk6gx4b Ca0nnhu0fzawiylwgrscj Spevmou2nw 4ngfzdxs6c 1azdDocument3 pagesAcfrogd60he9sraxzzz4hguizwc9gn0rhy1l2ybdffmwwvtjqcqmhffvtpxgodsll Cw5pilxl6sjmbu7fqyymq8mxjhbk6gx4b Ca0nnhu0fzawiylwgrscj Spevmou2nw 4ngfzdxs6c 1azdYo Yo Rajend YadavNo ratings yet
- Lec 5 - Gradient-DescentDocument31 pagesLec 5 - Gradient-DescentAnkur SarojNo ratings yet
- DeepLearing TheoryDocument51 pagesDeepLearing TheorytharunNo ratings yet
- CS601 - Machine Learning - Unit 2 - Notes - 1672759753Document14 pagesCS601 - Machine Learning - Unit 2 - Notes - 1672759753mohit jaiswalNo ratings yet
- Assignment - 4Document24 pagesAssignment - 4Durga prasad TNo ratings yet
- Linear Models (Unit II) Chapter III 1Document24 pagesLinear Models (Unit II) Chapter III 1AnilNo ratings yet
- Gradient Descent AlgorithmDocument5 pagesGradient Descent AlgorithmravinyseNo ratings yet
- Optimization Techniques in Deep LearningDocument14 pagesOptimization Techniques in Deep LearningayeshaNo ratings yet
- Sort Open MPDocument6 pagesSort Open MPMuhammad EahteshamNo ratings yet
- Wa0000.Document4 pagesWa0000.Sushant VyasNo ratings yet
- DSA Assignment 1Document8 pagesDSA Assignment 1Tendai ChigondoNo ratings yet
- University Solution 19-20Document33 pagesUniversity Solution 19-20picsichubNo ratings yet
- RPROP PaperDocument6 pagesRPROP PaperAli Raxa100% (1)
- Image Compression Using Resilient-Propagation Neural NetworkDocument5 pagesImage Compression Using Resilient-Propagation Neural NetworkInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- CORE - 14: Algorithm Design Techniques (Unit - 1)Document7 pagesCORE - 14: Algorithm Design Techniques (Unit - 1)Priyaranjan SorenNo ratings yet
- DAA NOTES FinalDocument9 pagesDAA NOTES FinalswatiNo ratings yet
- ADAM StochasticOptimiz 1412.6980Document15 pagesADAM StochasticOptimiz 1412.6980amirbekr100% (1)
- I RPROPDocument7 pagesI RPROPTaras ZakharchenkoNo ratings yet
- Multi PerceptorDocument37 pagesMulti Perceptordr.shashiprabhaNo ratings yet
- DL Assignment 1Document3 pagesDL Assignment 1SrinathNo ratings yet
- CS253 Report 3 Wilhelm AaronDocument35 pagesCS253 Report 3 Wilhelm Aaronb4826494No ratings yet
- HW 1Document8 pagesHW 1Mayur AgrawalNo ratings yet
- CmdieDocument8 pagesCmdieBeny AbdouNo ratings yet
- Control Example Using MatlabDocument37 pagesControl Example Using MatlabRizkie Denny PratamaNo ratings yet
- Prim's Algorithm For A Growing MSTDocument9 pagesPrim's Algorithm For A Growing MSTErno LedderNo ratings yet
- Chicago16 CorreiaDocument33 pagesChicago16 Correia212011414No ratings yet
- 2021 - Praktikum DinSis - Modul 4Document6 pages2021 - Praktikum DinSis - Modul 4ok dokterNo ratings yet
- Gradient DescentDocument9 pagesGradient Descentalwyn.benNo ratings yet
- Advantages BpaDocument38 pagesAdvantages BpaSelva KumarNo ratings yet
- Algorithms For Parallel MachinesDocument7 pagesAlgorithms For Parallel Machinesshinde_jayesh2005No ratings yet
- EEE 4706 Lab 1Document6 pagesEEE 4706 Lab 1Rummanur RahadNo ratings yet
- Optimization Principles: 7.1.1 The General Optimization ProblemDocument13 pagesOptimization Principles: 7.1.1 The General Optimization ProblemPrathak JienkulsawadNo ratings yet
- Assignment - 3 SolutionDocument28 pagesAssignment - 3 SolutionRitesh SutraveNo ratings yet
- Fuzzy ClasteringDocument24 pagesFuzzy ClasteringАлександар ЈовановићNo ratings yet
- Code Adam Optimization Algorithm From ScratchDocument28 pagesCode Adam Optimization Algorithm From ScratchValentin LungershausenNo ratings yet
- Number TheoryDocument85 pagesNumber TheoryArjunRanaNo ratings yet
- Some Efficient Heuristic Methods For The Flow Shop Sequencing ProblemDocument21 pagesSome Efficient Heuristic Methods For The Flow Shop Sequencing ProblemDeba SahooNo ratings yet
- Control System LabDocument15 pagesControl System Labhassan ullah khanNo ratings yet
- Assignment LUfactorisationDocument5 pagesAssignment LUfactorisationwebforderNo ratings yet
- Assignment 1Document13 pagesAssignment 1Si Woo LeeNo ratings yet
- Curs6site PDFDocument40 pagesCurs6site PDFGigi FloricaNo ratings yet
- Unit1 DaaDocument21 pagesUnit1 DaaArunachalam SelvaNo ratings yet
- Lab Manual DAADocument42 pagesLab Manual DAAdharun0704No ratings yet
- LPP Compte Rendu TP 1 Taibeche Ahmed Et Fezzai OussamaDocument11 pagesLPP Compte Rendu TP 1 Taibeche Ahmed Et Fezzai Oussamami doNo ratings yet
- Deep Learning - DL-2Document44 pagesDeep Learning - DL-2Hasnain AhmadNo ratings yet
- Gradient Descent OptimizationDocument27 pagesGradient Descent OptimizationAkash Raj BeheraNo ratings yet
- Learning To Learn by Gradient Descent by Gradient DescentDocument10 pagesLearning To Learn by Gradient Descent by Gradient DescentAnkit BiswasNo ratings yet
- Staggering Proportions: Design Lab 5 6.01 - Spring 2013Document6 pagesStaggering Proportions: Design Lab 5 6.01 - Spring 2013elvagojpNo ratings yet
- Deep Neural Network (DNN)Document80 pagesDeep Neural Network (DNN)20210802144No ratings yet
- MTamis ConstraintBasedPhysicsSolverDocument31 pagesMTamis ConstraintBasedPhysicsSolverlucianobuglioniNo ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- The Impact of Music Background in AdvertisementDocument6 pagesThe Impact of Music Background in AdvertisementABHISHEK SINGHNo ratings yet
- Brannig AN Foods: Marketing MetricsDocument7 pagesBrannig AN Foods: Marketing MetricsABHISHEK SINGHNo ratings yet
- ES-Report Final - DM22204 Abhishek Singh, DM22286 Zaheen, DM22273 SivaDocument23 pagesES-Report Final - DM22204 Abhishek Singh, DM22286 Zaheen, DM22273 SivaABHISHEK SINGHNo ratings yet
- XXX Master Thesis Mit NieuwboerDocument33 pagesXXX Master Thesis Mit NieuwboerABHISHEK SINGHNo ratings yet
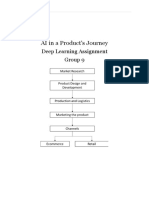
- AI in A Product's Journey: Deep Learning Assignment Group 9Document11 pagesAI in A Product's Journey: Deep Learning Assignment Group 9ABHISHEK SINGHNo ratings yet
- Meaning of The MusicDocument27 pagesMeaning of The MusicABHISHEK SINGHNo ratings yet
- This Study Resource Was: Consumer Behaviour Project SubmissionDocument4 pagesThis Study Resource Was: Consumer Behaviour Project SubmissionABHISHEK SINGHNo ratings yet
- Retailing Strategies Case Study: 7: Name DM NumberDocument3 pagesRetailing Strategies Case Study: 7: Name DM NumberABHISHEK SINGHNo ratings yet
- Returns Scenario 1 Scenario 2 Scenario 3 Scenario 4 Scenario 5Document4 pagesReturns Scenario 1 Scenario 2 Scenario 3 Scenario 4 Scenario 5ABHISHEK SINGHNo ratings yet
- Cognizant Recruitment Drive - Hall Ticket For Interview (Programmer Analyst Trainee)Document3 pagesCognizant Recruitment Drive - Hall Ticket For Interview (Programmer Analyst Trainee)ABHISHEK SINGHNo ratings yet
- This Study Resource Was: The Rise of Patanjali AyurvedaDocument5 pagesThis Study Resource Was: The Rise of Patanjali AyurvedaABHISHEK SINGHNo ratings yet
- Consumer Behaviour Assignment - Submisson 3: Analyse The Rise of Patanjali AyurvedaDocument15 pagesConsumer Behaviour Assignment - Submisson 3: Analyse The Rise of Patanjali AyurvedaABHISHEK SINGHNo ratings yet
- Abhishek HyperloopDocument27 pagesAbhishek HyperloopABHISHEK SINGHNo ratings yet
- Website Selected:: Nutrition/whey-ProteinDocument6 pagesWebsite Selected:: Nutrition/whey-ProteinABHISHEK SINGHNo ratings yet
- UnileverpresentationDocument33 pagesUnileverpresentationABHISHEK SINGHNo ratings yet
- DM22204 - Abhishek - Singh - How Can Ready To Eat Mixes Can Be Marketed BetterDocument12 pagesDM22204 - Abhishek - Singh - How Can Ready To Eat Mixes Can Be Marketed BetterABHISHEK SINGHNo ratings yet
- DM IndividualDocument4 pagesDM IndividualABHISHEK SINGHNo ratings yet
- Should Horlicks Extend To New Categories?Document10 pagesShould Horlicks Extend To New Categories?ABHISHEK SINGHNo ratings yet
- Avinash - Data Engineer (AutoRecovered)Document10 pagesAvinash - Data Engineer (AutoRecovered)arifmuhmmad8No ratings yet
- Python 1Document14 pagesPython 1yash saravgiNo ratings yet
- FAQ Intellispace PortalDocument5 pagesFAQ Intellispace PortalLyht TVNo ratings yet
- Computer System Servicing NC IIDocument14 pagesComputer System Servicing NC IIrommel patoritoNo ratings yet
- Infra 3 - ATS2023 Shared Purpose - Collaborating To Transform The Datacenter and Beyond - Imran YusufDocument18 pagesInfra 3 - ATS2023 Shared Purpose - Collaborating To Transform The Datacenter and Beyond - Imran YusufAndy WuNo ratings yet
- MMC Module 1Document76 pagesMMC Module 1Sourabh dhNo ratings yet
- 1Ch1-Introduction To Microprocessor and Computer, Brey BarryDocument110 pages1Ch1-Introduction To Microprocessor and Computer, Brey BarryChanchan LebumfacilNo ratings yet
- Electrohydraulic Actuator: Analog PVE Series 7Document2 pagesElectrohydraulic Actuator: Analog PVE Series 7jose manuel barroso pantojaNo ratings yet
- Exjun16 ProvisionalDocument60 pagesExjun16 ProvisionalstiasopaNo ratings yet
- NetApp ONTAP 9 DatasheetDocument4 pagesNetApp ONTAP 9 DatasheetGary BinnsNo ratings yet
- CS6303 - Load Testing - Prelim Lab Quiz 1 - Attempt ReviewDocument3 pagesCS6303 - Load Testing - Prelim Lab Quiz 1 - Attempt ReviewLolita CrebilloNo ratings yet
- 2Gb LPDDR4 A Die Component DatasheetDocument325 pages2Gb LPDDR4 A Die Component DatasheetSudhir SainiNo ratings yet
- CCS0007 Midterm Machine ProblemBSVZamora 1Document7 pagesCCS0007 Midterm Machine ProblemBSVZamora 1brandonsydzamoraNo ratings yet
- Big Data Assignment - 7Document7 pagesBig Data Assignment - 7Rajeev MukheshNo ratings yet
- Vocational TrainingDocument19 pagesVocational TrainingAvinash Singh 50ANo ratings yet
- R Mini-CompilerDocument16 pagesR Mini-CompilerAsmiNo ratings yet
- Online Movie Ticket Reservation APP FYP DOC New SidraDocument62 pagesOnline Movie Ticket Reservation APP FYP DOC New SidrasidrahNo ratings yet
- III Sem BSC (CBCS)Document4 pagesIII Sem BSC (CBCS)Karthik RaoNo ratings yet
- Minimization Model ExampleDocument22 pagesMinimization Model ExampleSherilyn LozanoNo ratings yet
- Computer Aided DesignDocument2 pagesComputer Aided DesignKeyur TNo ratings yet
- LogcatDocument2 pagesLogcatblablaNo ratings yet
- A Novel Approach of Women Safety Assistant Device With Biometric Verification in Real ScenarioDocument6 pagesA Novel Approach of Women Safety Assistant Device With Biometric Verification in Real ScenarioGeetha Priyanka GuggullaNo ratings yet
- Systems Engineer With Experience in DevelopingDocument3 pagesSystems Engineer With Experience in DevelopingAlexis Guzman ValverdeNo ratings yet
- Qianli Thermal Camera User Guide v3Document4 pagesQianli Thermal Camera User Guide v3Abdulrahman AlabdanNo ratings yet
- SF DumpDocument18 pagesSF DumpJorge Alberto Perez LopezNo ratings yet
- Tsnappnote 052920 MD 1591014409061Document3 pagesTsnappnote 052920 MD 1591014409061Jose ValenzuelaNo ratings yet
- Lindell MBC ManualDocument10 pagesLindell MBC ManualJaime SaldanhaNo ratings yet