
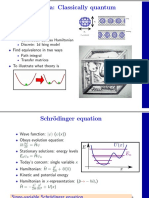
Slides Lecture6
Slides Lecture6
You might also like
- HW1 SolutionDocument7 pagesHW1 SolutionLê QuânNo ratings yet
- 4537 May 10 SDocument4 pages4537 May 10 STev WallaceNo ratings yet
- Generalized Linear Models: FX Axb C DX Axb C DXDocument11 pagesGeneralized Linear Models: FX Axb C DX Axb C DXAishat OmotolaNo ratings yet
- Qm Summary Final: h μ x σ σ s s σ s ρ δ dDocument13 pagesQm Summary Final: h μ x σ σ s s σ s ρ δ dJan BorowskiNo ratings yet
- X-Ray Notes Part2 of 3Document24 pagesX-Ray Notes Part2 of 3LillyOpenMindNo ratings yet
- DSP MidtermDocument4 pagesDSP MidtermRen Aldrin BobadillaNo ratings yet
- FIT5197 2021 S1 Formula SheetDocument20 pagesFIT5197 2021 S1 Formula Sheetrenu.tamsekarNo ratings yet
- Section06 SolutionsDocument15 pagesSection06 SolutionsMuhammad asafNo ratings yet
- Z TransformDocument21 pagesZ Transformadil1122100% (3)
- Imaging SummaryDocument39 pagesImaging SummarylepenguinNo ratings yet
- Worksheet Fourier SeriesDocument6 pagesWorksheet Fourier SeriesInnocent MbeleNo ratings yet
- TaleextraDocument15 pagesTaleextraIlja MeijerNo ratings yet
- Particle in A Box (Text 5.8) : Boundary ConditionsDocument7 pagesParticle in A Box (Text 5.8) : Boundary ConditionsRakib AhsanNo ratings yet
- Topics in Combinatorics 001 (BookFi)Document42 pagesTopics in Combinatorics 001 (BookFi)zainab hamedNo ratings yet
- Linear Regression: Volker Tresp 2017Document25 pagesLinear Regression: Volker Tresp 2017Sophie StroblNo ratings yet
- Rarefied Gas Dynamics - DSMC CourseDocument50 pagesRarefied Gas Dynamics - DSMC CourseyicdooNo ratings yet
- Modern Crypto 18 Homework 2 SolutionDocument5 pagesModern Crypto 18 Homework 2 Solutionعبدالله بحراويNo ratings yet
- Good McqsDocument4 pagesGood McqsJason DrakeNo ratings yet
- 2 Gaussian Process PDFDocument55 pages2 Gaussian Process PDFนนฐ์ทกร บุญรักชาติNo ratings yet
- 2022 Week 4 Ch.3 StochasticProcessDocument15 pages2022 Week 4 Ch.3 StochasticProcessseungnam kimNo ratings yet
- Fundamental Approximation Theorems: Kunal Narayan ChaudhuryDocument4 pagesFundamental Approximation Theorems: Kunal Narayan Chaudhuryabd 01No ratings yet
- Symmetry Analysis of Differential EquationsDocument88 pagesSymmetry Analysis of Differential EquationsShabbir ChaudharyNo ratings yet
- Choice PHD Consumer Proofs 1 18Document22 pagesChoice PHD Consumer Proofs 1 18bhaskkarNo ratings yet
- Formula PDFDocument3 pagesFormula PDFWong Kai YiNo ratings yet
- 03Document34 pages03Gagan JainNo ratings yet
- Assignment 1: Probability : Partial SolutionDocument7 pagesAssignment 1: Probability : Partial SolutionVirda SetyaniNo ratings yet
- All TasksDocument7 pagesAll TasksKrzysztof ToNo ratings yet
- Math Cheat SheetDocument2 pagesMath Cheat SheetQuito NituraNo ratings yet
- 專題二Document14 pages專題二Liang chun WuNo ratings yet
- Week 3 Lecture NotesDocument12 pagesWeek 3 Lecture NotesLilach NNo ratings yet
- 3 Random ProcessesDocument24 pages3 Random ProcessesSamson ImmanuelNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialIrmak ErkolNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialCajun SefNo ratings yet
- 1 More Dispersion: Weston Barger June 30, 2016Document6 pages1 More Dispersion: Weston Barger June 30, 2016ranvNo ratings yet
- Section06 SolutionsDocument11 pagesSection06 SolutionsKarimaNo ratings yet
- Chapter 5 Functions of Random VariablesDocument29 pagesChapter 5 Functions of Random VariablesAssimi DembéléNo ratings yet
- LinearDocument31 pagesLinearHiGrill25No ratings yet
- Machine Learning: Probabilistic View of Linear Regression Logistic Regression Hyperplane Based Classifiers and PerceptronDocument67 pagesMachine Learning: Probabilistic View of Linear Regression Logistic Regression Hyperplane Based Classifiers and PerceptronBoul chandra GaraiNo ratings yet
- Papers Dithered Noise Shapers: 1 1, Y,, X - Y,, X, X, XDocument10 pagesPapers Dithered Noise Shapers: 1 1, Y,, X - Y,, X, X, XTimos PapadopoulosNo ratings yet
- Mathematical Economics: 1 What To StudyDocument23 pagesMathematical Economics: 1 What To Studyjrvv2013gmailNo ratings yet
- Almost Everywhere Strong Summability of Fejer MeanDocument20 pagesAlmost Everywhere Strong Summability of Fejer Meangovindaraju annamalaiNo ratings yet
- Expected Values Expected Values: Alberto SuárezDocument6 pagesExpected Values Expected Values: Alberto SuárezVladimiro Ibañez QuispeNo ratings yet
- Random Variables: Presented by in Stochastic Analysis and Inverse ModellingDocument21 pagesRandom Variables: Presented by in Stochastic Analysis and Inverse ModellingAndres Pino100% (1)
- M401 Worksheet For Ch. 4Document2 pagesM401 Worksheet For Ch. 4Daily VideosNo ratings yet
- LectNotes 2013-02-26Document5 pagesLectNotes 2013-02-26Israel Rom Olguín GuzmanNo ratings yet
- Stochastic Processes and Time Series Markov Chains - II: 1 Conditional Probability ResultsDocument5 pagesStochastic Processes and Time Series Markov Chains - II: 1 Conditional Probability ResultsBiju AngaleesNo ratings yet
- 1 What Is A Random Variable (R.V.) ?Document6 pages1 What Is A Random Variable (R.V.) ?Eric VonFreemanNo ratings yet
- Zhang ManifoldDocument16 pagesZhang ManifoldVasi UtaNo ratings yet
- ClassificationDocument19 pagesClassificationstatyoungNo ratings yet
- I and II Order Le PssDocument48 pagesI and II Order Le PssAyanangshu ChakrabartyNo ratings yet
- Lecture 2: Entropy and Mutual Information: 2.1 ExampleDocument8 pagesLecture 2: Entropy and Mutual Information: 2.1 Exampless_18No ratings yet
- 11 Hidden Markov Models (HMMS) Model and Problem DescriptionDocument15 pages11 Hidden Markov Models (HMMS) Model and Problem DescriptionPrashant YadavNo ratings yet
- My Notes For Discrete and Continuous Distributions 987654Document28 pagesMy Notes For Discrete and Continuous Distributions 987654Shah FahadNo ratings yet
- N D IX: The E-M AlgorithmDocument12 pagesN D IX: The E-M Algorithm정하윤No ratings yet
- Dinestaer Ch6 InmanDocument88 pagesDinestaer Ch6 InmanTiago SantosNo ratings yet
- DistributionsDocument4 pagesDistributionsNarendra KNo ratings yet
- Lecture 1: Entropy and Mutual Information: 2.1 ExampleDocument8 pagesLecture 1: Entropy and Mutual Information: 2.1 ExampleLokesh SinghNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64From EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64No ratings yet
- Convolutional Neural Networks: CS 535 Deep Learning, Winter 2020 Fuxin LiDocument44 pagesConvolutional Neural Networks: CS 535 Deep Learning, Winter 2020 Fuxin LisandhyaNo ratings yet
- MATH Grade-10 Quarter-1 Module-6 Week-6 PDFDocument9 pagesMATH Grade-10 Quarter-1 Module-6 Week-6 PDFxander ison100% (9)
- Stat Scores PDFDocument8 pagesStat Scores PDFdaniel alcibiadestorrejon maldonadoNo ratings yet
- Btech Cs 7 Sem Application of Soft Computing rcs071 2020Document2 pagesBtech Cs 7 Sem Application of Soft Computing rcs071 2020Lalit SaraswatNo ratings yet
- Deep Learning PDFDocument87 pagesDeep Learning PDFArnaldo Preso De LigaNo ratings yet
- Lecture 17 - Hyperplane Classifiers - SVM - PlainDocument16 pagesLecture 17 - Hyperplane Classifiers - SVM - PlainRajachandra VoodigaNo ratings yet
- Dense Extreme Inception NetworkDocument10 pagesDense Extreme Inception NetworkMursal RehmanNo ratings yet
- IT257 DAA Linear ProgrammingDocument42 pagesIT257 DAA Linear ProgrammingSimhadri SevithaNo ratings yet
- Discretization of Convection - Diffusion Type Equation: 10 Indo - German Winter Academy 2011Document50 pagesDiscretization of Convection - Diffusion Type Equation: 10 Indo - German Winter Academy 2011Gaurav KulkarniNo ratings yet
- Artificial Neural Networks: Classification Using Multilayer Perceptron ModelDocument15 pagesArtificial Neural Networks: Classification Using Multilayer Perceptron ModelVeronica DumitrescuNo ratings yet
- UNIT 3.1 (Greedy Method - Knapsack Problem)Document24 pagesUNIT 3.1 (Greedy Method - Knapsack Problem)sejalNo ratings yet
- Variations On BackpropagationDocument46 pagesVariations On BackpropagationMahyar MohammadyNo ratings yet
- 2D Cutting Stock Optimization Software SurveyDocument29 pages2D Cutting Stock Optimization Software SurveytheliminalguyNo ratings yet
- Artificial Variable Technique-Big M MethodDocument48 pagesArtificial Variable Technique-Big M Methodavinash11987No ratings yet
- 05 - EN Sbirka Matematika 3 57 113 PDFDocument57 pages05 - EN Sbirka Matematika 3 57 113 PDFXDSerAngel BejarMNo ratings yet
- Mathematics 7 Module 1 Lesson 2 Polynomials Pre-Requisite Concepts: Constants, Variables, Algebraic ExpressionsDocument3 pagesMathematics 7 Module 1 Lesson 2 Polynomials Pre-Requisite Concepts: Constants, Variables, Algebraic Expressionsdorris09No ratings yet
- Advanced Optimization Using MATLAB by EndalewDocument22 pagesAdvanced Optimization Using MATLAB by EndalewMerera TaresaNo ratings yet
- Class Notes 02feb2023Document70 pagesClass Notes 02feb2023arindamsinharayNo ratings yet
- Gamultiobj AlgorithmDocument6 pagesGamultiobj AlgorithmPaolo FlorentinNo ratings yet
- Shooting Method PDFDocument11 pagesShooting Method PDFNeha MiracleNo ratings yet
- Patching Catmull-Clark MeshesDocument72 pagesPatching Catmull-Clark MeshesAndrey BeskrovnykhNo ratings yet
- Nahp1 2020 PDFDocument4 pagesNahp1 2020 PDFVangheli TVNo ratings yet
- Cauvery Institute of Technology, Mandya: Divide and ConquerDocument11 pagesCauvery Institute of Technology, Mandya: Divide and ConquerHema Chander NNo ratings yet
- 03 - AutoMLDocument14 pages03 - AutoMLasim zamanNo ratings yet
- Greek Anal Fissures: ARA ResearchDocument8 pagesGreek Anal Fissures: ARA Researchmandingomonstercok100% (1)
- 20MIS1025 - Regression - Ipynb - ColaboratoryDocument5 pages20MIS1025 - Regression - Ipynb - ColaboratorySandip DasNo ratings yet
- Lecture 24 (Matrix Chain Multiplication)Document17 pagesLecture 24 (Matrix Chain Multiplication)Almaz RizviNo ratings yet
- Automata Sanjay Sir MCQDocument8 pagesAutomata Sanjay Sir MCQ69Sutanu MukherjeeNo ratings yet
- Fem Assignment Question Bank Unit 1&2 PDFDocument1 pageFem Assignment Question Bank Unit 1&2 PDFSudhakar UppalapatiNo ratings yet























































































Download as pdf or txt
You might also like
- HW1 SolutionDocument7 pagesHW1 SolutionLê QuânNo ratings yet
- 4537 May 10 SDocument4 pages4537 May 10 STev WallaceNo ratings yet
- Generalized Linear Models: FX Axb C DX Axb C DXDocument11 pagesGeneralized Linear Models: FX Axb C DX Axb C DXAishat OmotolaNo ratings yet
- Qm Summary Final: h μ x σ σ s s σ s ρ δ dDocument13 pagesQm Summary Final: h μ x σ σ s s σ s ρ δ dJan BorowskiNo ratings yet
- X-Ray Notes Part2 of 3Document24 pagesX-Ray Notes Part2 of 3LillyOpenMindNo ratings yet
- DSP MidtermDocument4 pagesDSP MidtermRen Aldrin BobadillaNo ratings yet
- FIT5197 2021 S1 Formula SheetDocument20 pagesFIT5197 2021 S1 Formula Sheetrenu.tamsekarNo ratings yet
- Section06 SolutionsDocument15 pagesSection06 SolutionsMuhammad asafNo ratings yet
- Z TransformDocument21 pagesZ Transformadil1122100% (3)
- Imaging SummaryDocument39 pagesImaging SummarylepenguinNo ratings yet
- Worksheet Fourier SeriesDocument6 pagesWorksheet Fourier SeriesInnocent MbeleNo ratings yet
- TaleextraDocument15 pagesTaleextraIlja MeijerNo ratings yet
- Particle in A Box (Text 5.8) : Boundary ConditionsDocument7 pagesParticle in A Box (Text 5.8) : Boundary ConditionsRakib AhsanNo ratings yet
- Topics in Combinatorics 001 (BookFi)Document42 pagesTopics in Combinatorics 001 (BookFi)zainab hamedNo ratings yet
- Linear Regression: Volker Tresp 2017Document25 pagesLinear Regression: Volker Tresp 2017Sophie StroblNo ratings yet
- Rarefied Gas Dynamics - DSMC CourseDocument50 pagesRarefied Gas Dynamics - DSMC CourseyicdooNo ratings yet
- Modern Crypto 18 Homework 2 SolutionDocument5 pagesModern Crypto 18 Homework 2 Solutionعبدالله بحراويNo ratings yet
- Good McqsDocument4 pagesGood McqsJason DrakeNo ratings yet
- 2 Gaussian Process PDFDocument55 pages2 Gaussian Process PDFนนฐ์ทกร บุญรักชาติNo ratings yet
- 2022 Week 4 Ch.3 StochasticProcessDocument15 pages2022 Week 4 Ch.3 StochasticProcessseungnam kimNo ratings yet
- Fundamental Approximation Theorems: Kunal Narayan ChaudhuryDocument4 pagesFundamental Approximation Theorems: Kunal Narayan Chaudhuryabd 01No ratings yet
- Symmetry Analysis of Differential EquationsDocument88 pagesSymmetry Analysis of Differential EquationsShabbir ChaudharyNo ratings yet
- Choice PHD Consumer Proofs 1 18Document22 pagesChoice PHD Consumer Proofs 1 18bhaskkarNo ratings yet
- Formula PDFDocument3 pagesFormula PDFWong Kai YiNo ratings yet
- 03Document34 pages03Gagan JainNo ratings yet
- Assignment 1: Probability : Partial SolutionDocument7 pagesAssignment 1: Probability : Partial SolutionVirda SetyaniNo ratings yet
- All TasksDocument7 pagesAll TasksKrzysztof ToNo ratings yet
- Math Cheat SheetDocument2 pagesMath Cheat SheetQuito NituraNo ratings yet
- 專題二Document14 pages專題二Liang chun WuNo ratings yet
- Week 3 Lecture NotesDocument12 pagesWeek 3 Lecture NotesLilach NNo ratings yet
- 3 Random ProcessesDocument24 pages3 Random ProcessesSamson ImmanuelNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialIrmak ErkolNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialCajun SefNo ratings yet
- 1 More Dispersion: Weston Barger June 30, 2016Document6 pages1 More Dispersion: Weston Barger June 30, 2016ranvNo ratings yet
- Section06 SolutionsDocument11 pagesSection06 SolutionsKarimaNo ratings yet
- Chapter 5 Functions of Random VariablesDocument29 pagesChapter 5 Functions of Random VariablesAssimi DembéléNo ratings yet
- LinearDocument31 pagesLinearHiGrill25No ratings yet
- Machine Learning: Probabilistic View of Linear Regression Logistic Regression Hyperplane Based Classifiers and PerceptronDocument67 pagesMachine Learning: Probabilistic View of Linear Regression Logistic Regression Hyperplane Based Classifiers and PerceptronBoul chandra GaraiNo ratings yet
- Papers Dithered Noise Shapers: 1 1, Y,, X - Y,, X, X, XDocument10 pagesPapers Dithered Noise Shapers: 1 1, Y,, X - Y,, X, X, XTimos PapadopoulosNo ratings yet
- Mathematical Economics: 1 What To StudyDocument23 pagesMathematical Economics: 1 What To Studyjrvv2013gmailNo ratings yet
- Almost Everywhere Strong Summability of Fejer MeanDocument20 pagesAlmost Everywhere Strong Summability of Fejer Meangovindaraju annamalaiNo ratings yet
- Expected Values Expected Values: Alberto SuárezDocument6 pagesExpected Values Expected Values: Alberto SuárezVladimiro Ibañez QuispeNo ratings yet
- Random Variables: Presented by in Stochastic Analysis and Inverse ModellingDocument21 pagesRandom Variables: Presented by in Stochastic Analysis and Inverse ModellingAndres Pino100% (1)
- M401 Worksheet For Ch. 4Document2 pagesM401 Worksheet For Ch. 4Daily VideosNo ratings yet
- LectNotes 2013-02-26Document5 pagesLectNotes 2013-02-26Israel Rom Olguín GuzmanNo ratings yet
- Stochastic Processes and Time Series Markov Chains - II: 1 Conditional Probability ResultsDocument5 pagesStochastic Processes and Time Series Markov Chains - II: 1 Conditional Probability ResultsBiju AngaleesNo ratings yet
- 1 What Is A Random Variable (R.V.) ?Document6 pages1 What Is A Random Variable (R.V.) ?Eric VonFreemanNo ratings yet
- Zhang ManifoldDocument16 pagesZhang ManifoldVasi UtaNo ratings yet
- ClassificationDocument19 pagesClassificationstatyoungNo ratings yet
- I and II Order Le PssDocument48 pagesI and II Order Le PssAyanangshu ChakrabartyNo ratings yet
- Lecture 2: Entropy and Mutual Information: 2.1 ExampleDocument8 pagesLecture 2: Entropy and Mutual Information: 2.1 Exampless_18No ratings yet
- 11 Hidden Markov Models (HMMS) Model and Problem DescriptionDocument15 pages11 Hidden Markov Models (HMMS) Model and Problem DescriptionPrashant YadavNo ratings yet
- My Notes For Discrete and Continuous Distributions 987654Document28 pagesMy Notes For Discrete and Continuous Distributions 987654Shah FahadNo ratings yet
- N D IX: The E-M AlgorithmDocument12 pagesN D IX: The E-M Algorithm정하윤No ratings yet
- Dinestaer Ch6 InmanDocument88 pagesDinestaer Ch6 InmanTiago SantosNo ratings yet
- DistributionsDocument4 pagesDistributionsNarendra KNo ratings yet
- Lecture 1: Entropy and Mutual Information: 2.1 ExampleDocument8 pagesLecture 1: Entropy and Mutual Information: 2.1 ExampleLokesh SinghNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64From EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64No ratings yet
- Convolutional Neural Networks: CS 535 Deep Learning, Winter 2020 Fuxin LiDocument44 pagesConvolutional Neural Networks: CS 535 Deep Learning, Winter 2020 Fuxin LisandhyaNo ratings yet
- MATH Grade-10 Quarter-1 Module-6 Week-6 PDFDocument9 pagesMATH Grade-10 Quarter-1 Module-6 Week-6 PDFxander ison100% (9)
- Stat Scores PDFDocument8 pagesStat Scores PDFdaniel alcibiadestorrejon maldonadoNo ratings yet
- Btech Cs 7 Sem Application of Soft Computing rcs071 2020Document2 pagesBtech Cs 7 Sem Application of Soft Computing rcs071 2020Lalit SaraswatNo ratings yet
- Deep Learning PDFDocument87 pagesDeep Learning PDFArnaldo Preso De LigaNo ratings yet
- Lecture 17 - Hyperplane Classifiers - SVM - PlainDocument16 pagesLecture 17 - Hyperplane Classifiers - SVM - PlainRajachandra VoodigaNo ratings yet
- Dense Extreme Inception NetworkDocument10 pagesDense Extreme Inception NetworkMursal RehmanNo ratings yet
- IT257 DAA Linear ProgrammingDocument42 pagesIT257 DAA Linear ProgrammingSimhadri SevithaNo ratings yet
- Discretization of Convection - Diffusion Type Equation: 10 Indo - German Winter Academy 2011Document50 pagesDiscretization of Convection - Diffusion Type Equation: 10 Indo - German Winter Academy 2011Gaurav KulkarniNo ratings yet
- Artificial Neural Networks: Classification Using Multilayer Perceptron ModelDocument15 pagesArtificial Neural Networks: Classification Using Multilayer Perceptron ModelVeronica DumitrescuNo ratings yet
- UNIT 3.1 (Greedy Method - Knapsack Problem)Document24 pagesUNIT 3.1 (Greedy Method - Knapsack Problem)sejalNo ratings yet
- Variations On BackpropagationDocument46 pagesVariations On BackpropagationMahyar MohammadyNo ratings yet
- 2D Cutting Stock Optimization Software SurveyDocument29 pages2D Cutting Stock Optimization Software SurveytheliminalguyNo ratings yet
- Artificial Variable Technique-Big M MethodDocument48 pagesArtificial Variable Technique-Big M Methodavinash11987No ratings yet
- 05 - EN Sbirka Matematika 3 57 113 PDFDocument57 pages05 - EN Sbirka Matematika 3 57 113 PDFXDSerAngel BejarMNo ratings yet
- Mathematics 7 Module 1 Lesson 2 Polynomials Pre-Requisite Concepts: Constants, Variables, Algebraic ExpressionsDocument3 pagesMathematics 7 Module 1 Lesson 2 Polynomials Pre-Requisite Concepts: Constants, Variables, Algebraic Expressionsdorris09No ratings yet
- Advanced Optimization Using MATLAB by EndalewDocument22 pagesAdvanced Optimization Using MATLAB by EndalewMerera TaresaNo ratings yet
- Class Notes 02feb2023Document70 pagesClass Notes 02feb2023arindamsinharayNo ratings yet
- Gamultiobj AlgorithmDocument6 pagesGamultiobj AlgorithmPaolo FlorentinNo ratings yet
- Shooting Method PDFDocument11 pagesShooting Method PDFNeha MiracleNo ratings yet
- Patching Catmull-Clark MeshesDocument72 pagesPatching Catmull-Clark MeshesAndrey BeskrovnykhNo ratings yet
- Nahp1 2020 PDFDocument4 pagesNahp1 2020 PDFVangheli TVNo ratings yet
- Cauvery Institute of Technology, Mandya: Divide and ConquerDocument11 pagesCauvery Institute of Technology, Mandya: Divide and ConquerHema Chander NNo ratings yet
- 03 - AutoMLDocument14 pages03 - AutoMLasim zamanNo ratings yet
- Greek Anal Fissures: ARA ResearchDocument8 pagesGreek Anal Fissures: ARA Researchmandingomonstercok100% (1)
- 20MIS1025 - Regression - Ipynb - ColaboratoryDocument5 pages20MIS1025 - Regression - Ipynb - ColaboratorySandip DasNo ratings yet
- Lecture 24 (Matrix Chain Multiplication)Document17 pagesLecture 24 (Matrix Chain Multiplication)Almaz RizviNo ratings yet
- Automata Sanjay Sir MCQDocument8 pagesAutomata Sanjay Sir MCQ69Sutanu MukherjeeNo ratings yet
- Fem Assignment Question Bank Unit 1&2 PDFDocument1 pageFem Assignment Question Bank Unit 1&2 PDFSudhakar UppalapatiNo ratings yet