Download as pdf or txt
You might also like
- Minor Project PresentationDocument15 pagesMinor Project Presentationtradersindian4100% (1)
- Controllable Sentence Simplification with a Unified Text-to-Text Transfer TransformerDocument12 pagesControllable Sentence Simplification with a Unified Text-to-Text Transfer Transformernbw754jtw7No ratings yet
- No Training Required Exploring Random Encoders For Sentence ClassificationDocument16 pagesNo Training Required Exploring Random Encoders For Sentence ClassificationMoonlight DancerNo ratings yet
- Language Models Are Unsupervised Multitask LearnersDocument24 pagesLanguage Models Are Unsupervised Multitask LearnersGabrielNo ratings yet
- Semantics-Aware BERT For Language Understanding: Zhuosheng Zhang, Yuwei Wu, Hai Zhao, Zuchao LiDocument8 pagesSemantics-Aware BERT For Language Understanding: Zhuosheng Zhang, Yuwei Wu, Hai Zhao, Zuchao Li刘中坤No ratings yet
- Revisiting Character-Based Neural Machine Translation With Capacity and CompressionDocument11 pagesRevisiting Character-Based Neural Machine Translation With Capacity and CompressionWalterHuNo ratings yet
- Improving BERT-Based Text Classification With Auxiliary Sentence and Domain KnowledgeDocument16 pagesImproving BERT-Based Text Classification With Auxiliary Sentence and Domain KnowledgenimaNo ratings yet
- 855 Roberta A Robustly Optimized BDocument15 pages855 Roberta A Robustly Optimized BVo Nhu YNo ratings yet
- 2021 emnlp-main 92论文Document14 pages2021 emnlp-main 92论文aslina akwaNo ratings yet
- Conneau, A., Et Al. (2017) - Supervised Learning of Universal Sentence Representations From Natural Language Inference Data. EMNLPDocument12 pagesConneau, A., Et Al. (2017) - Supervised Learning of Universal Sentence Representations From Natural Language Inference Data. EMNLPAhmed IsmailNo ratings yet
- 2023.ijcnlp Short.10Document10 pages2023.ijcnlp Short.10Dũng NguyễnNo ratings yet
- BERT Explained - State of The Art Language Model For NLP - by Rani Horev - Towards Data ScienceDocument8 pagesBERT Explained - State of The Art Language Model For NLP - by Rani Horev - Towards Data ScienceOnlyBy Myself100% (1)
- Linguistically-Informed Self-Attention For Semantic Role LabelingDocument10 pagesLinguistically-Informed Self-Attention For Semantic Role LabelingMayukh MaityNo ratings yet
- Innovatively Fused Deep Learning For Evaluating Translations From Poor Into Rich Morphology-Coling2020Document11 pagesInnovatively Fused Deep Learning For Evaluating Translations From Poor Into Rich Morphology-Coling2020Vilelmini SosoniNo ratings yet
- ThirdpaperDocument10 pagesThirdpaperjohnjoeNo ratings yet
- Improving BERT-Based Text Classification With Auxiliary Sentence and Domain KnowledgeDocument13 pagesImproving BERT-Based Text Classification With Auxiliary Sentence and Domain KnowledgeLarissa FelicianaNo ratings yet
- Word Alignment Modeling With Context Dependent Deep Neural NetworkDocument10 pagesWord Alignment Modeling With Context Dependent Deep Neural NetworkUriel OuakeNo ratings yet
- End-To-End Graph-Based TAG Parsing With Neural NetworksDocument14 pagesEnd-To-End Graph-Based TAG Parsing With Neural NetworksDavid Riquelme ReynaNo ratings yet
- Pre-Training and Fine-Tuning Electra Models For Various Vietnamese Natural Language Processing TasksDocument7 pagesPre-Training and Fine-Tuning Electra Models For Various Vietnamese Natural Language Processing TasksKhánh LêNo ratings yet
- 2020 Lrec-1 259Document10 pages2020 Lrec-1 259Caio CruzNo ratings yet
- Image Captioning: Department of Computer Science University of Engineering & Technology TaxilaDocument10 pagesImage Captioning: Department of Computer Science University of Engineering & Technology TaxilaaliNo ratings yet
- A Multilayer Convolutional Encoder-Decoder Neural Network For Grammatical Error CorrectionDocument8 pagesA Multilayer Convolutional Encoder-Decoder Neural Network For Grammatical Error CorrectionJadir Ibna HasanNo ratings yet
- Preprint JesusDocument2 pagesPreprint JesusJesus UrbanejaNo ratings yet
- HKBK College of Engineering Department of Computer Science and EngineeringDocument24 pagesHKBK College of Engineering Department of Computer Science and Engineering1HK16CS104 Muntazir Hussain BhatNo ratings yet
- Interpreting Language Models Through Knowledge Graph ExtractionDocument13 pagesInterpreting Language Models Through Knowledge Graph ExtractionProtsenko IgorNo ratings yet
- Zero-Shot Sequence Labeling For Transformer-Based Sentence ClassifiersDocument11 pagesZero-Shot Sequence Labeling For Transformer-Based Sentence ClassifiersmarekreiNo ratings yet
- Tacl A 00300Document14 pagesTacl A 00300Mandar JoshiNo ratings yet
- How To Unleash The Power of Large Language Models For Few-Shot Relation ExtractionDocument11 pagesHow To Unleash The Power of Large Language Models For Few-Shot Relation Extractionxzj294197164No ratings yet
- Effect of Scale On CatastrophiDocument33 pagesEffect of Scale On CatastrophiUmar TsaniNo ratings yet
- 2022 Naacl-Srw 18Document7 pages2022 Naacl-Srw 18Vo Nhu YNo ratings yet
- Connecting DOTSDocument7 pagesConnecting DOTSHemanth lepchaNo ratings yet
- Combining Pre-Trained Language Models and Structured KnowledgeDocument19 pagesCombining Pre-Trained Language Models and Structured KnowledgeSRNo ratings yet
- Garbacea 22 ADocument17 pagesGarbacea 22 ANaoual NassiriNo ratings yet
- 1 s2.0 S2095809922006324 MainDocument20 pages1 s2.0 S2095809922006324 MainJuan ZarateNo ratings yet
- Max-Margin Tensor Neural Network For Chinese Word SegmentationDocument11 pagesMax-Margin Tensor Neural Network For Chinese Word SegmentationafnanmajidNo ratings yet
- Multi-Task Sequence To Sequence LearningDocument10 pagesMulti-Task Sequence To Sequence LearningShri KrishnaNo ratings yet
- Character Level Text Classification Via Convolutional Neural Network and Gated Recurrent UnitDocument11 pagesCharacter Level Text Classification Via Convolutional Neural Network and Gated Recurrent UnitmainakroniNo ratings yet
- 2021 Mirror-Bert EmnlpDocument18 pages2021 Mirror-Bert Emnlprajesh716No ratings yet
- Token-Level Metaphor Detection Using Neural NetworksDocument6 pagesToken-Level Metaphor Detection Using Neural NetworksAli Asghar Pourhaji KazemNo ratings yet
- Baselines and AnalysisDocument6 pagesBaselines and Analysisbelay beyenaNo ratings yet
- Compound Feature Engg For Compound Type IdentificationDocument17 pagesCompound Feature Engg For Compound Type IdentificationhiraNo ratings yet
- A Unified Architecture For Natural Language Processing: Deep Neural Networks With Multitask LearningDocument9 pagesA Unified Architecture For Natural Language Processing: Deep Neural Networks With Multitask LearningnghiaNo ratings yet
- Data Augmentation With Transformers For Text ClassificationDocument13 pagesData Augmentation With Transformers For Text ClassificationMax SarmentoNo ratings yet
- Unsupervised Style TransferDocument5 pagesUnsupervised Style TransferAnonymous FZeZr4No ratings yet
- The Diverse Landscape of Large Language Models Deepsense AiDocument16 pagesThe Diverse Landscape of Large Language Models Deepsense AiYoussef OuyhyaNo ratings yet
- Fast Gen of KgeDocument14 pagesFast Gen of KgeDương Vũ MinhNo ratings yet
- DATE: Detecting Anomalies in Text Via Self-Supervision of TransformersDocument11 pagesDATE: Detecting Anomalies in Text Via Self-Supervision of TransformersAyman TaniraNo ratings yet
- R E N A: Easoning About Ntailment With Eural TtentionDocument9 pagesR E N A: Easoning About Ntailment With Eural TtentionDi BFranNo ratings yet
- Language Models With Transformers: Chenguang Wang Mu Li Alexander J. Smola Amazon Web ServicesDocument12 pagesLanguage Models With Transformers: Chenguang Wang Mu Li Alexander J. Smola Amazon Web ServicesSandi HermawanNo ratings yet
- Unsupervised Word Translation With Adversarial Autoencoder: Tasnim MohiuddinDocument32 pagesUnsupervised Word Translation With Adversarial Autoencoder: Tasnim Mohiuddinastkr5No ratings yet
- Effect of Model and Pretraining Scale On Catastrophic Forgetting in Neural NetworksDocument33 pagesEffect of Model and Pretraining Scale On Catastrophic Forgetting in Neural Networkskai luNo ratings yet
- Towards The Use of Pretrained Language Models For Task-Oriented Dialogue SystemsDocument8 pagesTowards The Use of Pretrained Language Models For Task-Oriented Dialogue SystemsyadavrajeNo ratings yet
- SUBMITTED ACL 2019 Unified Parsing FrameworkDocument10 pagesSUBMITTED ACL 2019 Unified Parsing FrameworkAbhishek BansalNo ratings yet
- SocherBauerManningNg ACL2013 PDFDocument11 pagesSocherBauerManningNg ACL2013 PDFSr. RZNo ratings yet
- WordgcnDocument11 pagesWordgcnPrateek YadavNo ratings yet
- Seq2Edits: Sequence Transduction Using Span-Level Edit OperationsDocument17 pagesSeq2Edits: Sequence Transduction Using Span-Level Edit OperationsSunny DuttaNo ratings yet
- 4823-Article Text-7889-1-10-20190709Document9 pages4823-Article Text-7889-1-10-20190709Binay AdhikariNo ratings yet
- Boosting The Performance of Transformer ArchitectuDocument6 pagesBoosting The Performance of Transformer ArchitectuGetnete degemuNo ratings yet
- Tagged Back-Translation: Isaac Caswell, Ciprian Chelba, David Grangier Google ResearchDocument11 pagesTagged Back-Translation: Isaac Caswell, Ciprian Chelba, David Grangier Google ResearchYgana AnyNo ratings yet
- Control Prefixes For Parameter-Efficient Text GenerationDocument20 pagesControl Prefixes For Parameter-Efficient Text GenerationmarekreiNo ratings yet
- Ensemble Averaging (Machine Learning)Document3 pagesEnsemble Averaging (Machine Learning)emma698No ratings yet
- Didroid: Android Malware Classification and Characterization Using Deep Image LearningDocument13 pagesDidroid: Android Malware Classification and Characterization Using Deep Image LearningThanaa OdatNo ratings yet
- Applied Machine LearningDocument49 pagesApplied Machine LearningWanida KrataeNo ratings yet
- Lecture 1 Disruptive Technologies AIDocument12 pagesLecture 1 Disruptive Technologies AItamal3110No ratings yet
- (Graded) : Assignment No. 3Document3 pages(Graded) : Assignment No. 3Nazim AliNo ratings yet
- Proposal Defense Schedule 1st Round 2019-20AY - For StudnetsDocument2 pagesProposal Defense Schedule 1st Round 2019-20AY - For StudnetsyekoyesewNo ratings yet
- List of Artificial Intelligence ProjectsDocument5 pagesList of Artificial Intelligence Projectsnigel989No ratings yet
- 3 - DeepLearning - and - CNN v3Document50 pages3 - DeepLearning - and - CNN v3Dumidu GhanasekaraNo ratings yet
- Machine Learning (Open Elective) B.Tech. ECE LTPC 3 0 0 3 ObjectivesDocument2 pagesMachine Learning (Open Elective) B.Tech. ECE LTPC 3 0 0 3 ObjectivesDevadas M ECENo ratings yet
- AiDocument4 pagesAiramji99No ratings yet
- ChatGPT Is Not All You Need. A State of The Art Review of Large Generative AI ModelsDocument22 pagesChatGPT Is Not All You Need. A State of The Art Review of Large Generative AI Modelsjasperchua91No ratings yet
- Machine Learning 2nd AssignmentDocument3 pagesMachine Learning 2nd AssignmentlalaNo ratings yet
- CPCS335 1 IntroductionDocument34 pagesCPCS335 1 IntroductionKing Abdi HajjiNo ratings yet
- Thesis Report On Image Classification Using ConvDocument9 pagesThesis Report On Image Classification Using ConvRashedul IslamNo ratings yet
- ms160400843 - Synopsis v2Document11 pagesms160400843 - Synopsis v2Shahid AzeemNo ratings yet
- EthemKaral Resume PDFDocument4 pagesEthemKaral Resume PDFŞebnem Bingöl KaralNo ratings yet
- Neural NetworksDocument3 pagesNeural NetworksMahesh MalkaniNo ratings yet
- QuizDocument5 pagesQuizFatma Zohra OUIRNo ratings yet
- NeurIPS 2021 Deeply Shared Filter Bases For Parameter Efficient Convolutional Neural Networks PaperDocument12 pagesNeurIPS 2021 Deeply Shared Filter Bases For Parameter Efficient Convolutional Neural Networks PapercthfmzNo ratings yet
- Chapter 7Document31 pagesChapter 7Fairooz TorosheNo ratings yet
- Iceca 2023 - PaperDocument5 pagesIceca 2023 - Paperslalitha.613No ratings yet
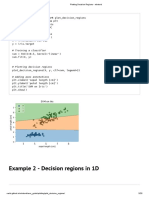
- Plotting Decision Regions - MlxtendDocument5 pagesPlotting Decision Regions - Mlxtendakhi016733No ratings yet
- Implementation of Handwritten Digit Recognizer Using CNN: Vinjit, Bhojak, Kumar and NikamDocument9 pagesImplementation of Handwritten Digit Recognizer Using CNN: Vinjit, Bhojak, Kumar and NikamfdknkndfNo ratings yet
- Racism Detection by Analyzing Differential Opinions Through Sentiment Analysis of Tweets Using Stacked Ensemble GCR-NN ModelDocument12 pagesRacism Detection by Analyzing Differential Opinions Through Sentiment Analysis of Tweets Using Stacked Ensemble GCR-NN ModelMessalti Ahmed zoubirNo ratings yet
- Combining Pattern Classifiers Methods and Algorithms PDFDocument2 pagesCombining Pattern Classifiers Methods and Algorithms PDFJustinNo ratings yet
- What Is Artificial Intelligence.?Document3 pagesWhat Is Artificial Intelligence.?Sri SriNo ratings yet
- Deep Interpretable Architecture For Plant Diseases ClassificationDocument11 pagesDeep Interpretable Architecture For Plant Diseases ClassificationaamusNo ratings yet
- VIT Online Learning (VITOL) Institute Summer Online Courses Internal Assessment ScheduleDocument1 pageVIT Online Learning (VITOL) Institute Summer Online Courses Internal Assessment ScheduleBadhan PaulNo ratings yet