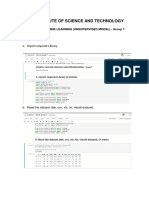
Download as docx, pdf, or txt
You might also like
- DownloadDocument5 pagesDownloadanurag_jay12464No ratings yet
- Ashwani Singh 117BM0731Document28 pagesAshwani Singh 117BM0731Ashwani SinghNo ratings yet
- An Introduction To Microarray AnalysisDocument25 pagesAn Introduction To Microarray AnalysisSaurav Sarkar100% (1)
- Aviris Hyperspectral Images Compression Using 3d Spiht AlgorithmDocument6 pagesAviris Hyperspectral Images Compression Using 3d Spiht AlgorithmIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- Detection of Period-3 Behavior Genomic Sequences Using Singular DecompositionDocument5 pagesDetection of Period-3 Behavior Genomic Sequences Using Singular DecompositionChandrasekaran SaravanakumarNo ratings yet
- Detect Key Genes in Classification of Microarray DataDocument13 pagesDetect Key Genes in Classification of Microarray DataLeo trinhNo ratings yet
- IDS Project Group 11Document35 pagesIDS Project Group 11Faheem AkramNo ratings yet
- Synthesis of Thinned Linear Antenna Arrays With Fixed Sidelobe Level Using Real-Coded Genetic Algorithm G. K. MahantiDocument10 pagesSynthesis of Thinned Linear Antenna Arrays With Fixed Sidelobe Level Using Real-Coded Genetic Algorithm G. K. MahantiNaren PathakNo ratings yet
- Study of Statistical Correlations in DNA Sequences: P. Bernaola-Galva N, P. Carpena, R. Roma N-Rolda N, J.L. OliverDocument11 pagesStudy of Statistical Correlations in DNA Sequences: P. Bernaola-Galva N, P. Carpena, R. Roma N-Rolda N, J.L. OlivertavpriteshNo ratings yet
- Paper 1Document7 pagesPaper 1RakeshconclaveNo ratings yet
- Dot Plot InterpretationDocument18 pagesDot Plot InterpretationJoão AlvesNo ratings yet
- Dchip, MAS e RMADocument8 pagesDchip, MAS e RMAYuri Nagamine UrataNo ratings yet
- Chapter 5 Analysis of Several Groups Canonical Variate Analysis - 1999 - Aspects of Multivariate Statistical Analysis in GeologyDocument37 pagesChapter 5 Analysis of Several Groups Canonical Variate Analysis - 1999 - Aspects of Multivariate Statistical Analysis in GeologyAnderson CarvalhoNo ratings yet
- Microarrays I: Introduction To The Concept & BackgroundDocument59 pagesMicroarrays I: Introduction To The Concept & Backgroundsonam behlkambojNo ratings yet
- Sequence Similarity Between Genetic Codes Using Improved Longest Common Subsequence AlgorithmDocument4 pagesSequence Similarity Between Genetic Codes Using Improved Longest Common Subsequence AlgorithmEditor IJRITCCNo ratings yet
- Soft Des CPTDocument3 pagesSoft Des CPTfcordNo ratings yet
- Publication 2Document8 pagesPublication 2MariaNo ratings yet
- Prediction of Two Phase Flow PDFDocument5 pagesPrediction of Two Phase Flow PDFPujara ManishNo ratings yet
- Support Vector Machines and Kernels For Computational BiologyDocument26 pagesSupport Vector Machines and Kernels For Computational BiologydianNo ratings yet
- Csit 64802Document10 pagesCsit 64802CS & ITNo ratings yet
- Research Paper 4Document4 pagesResearch Paper 4SAMPATH ANo ratings yet
- An Introduction To Genetic...Document9 pagesAn Introduction To Genetic...Manohar KoduriNo ratings yet
- SC SMDocument26 pagesSC SMJavi ErNo ratings yet
- JETIR2405449 PublishedDocument6 pagesJETIR2405449 PublishedshreedharhksNo ratings yet
- 02 Phenotyping For QTL MappingDocument9 pages02 Phenotyping For QTL MappingAditya WirawanNo ratings yet
- Matlab Analysis of Eeg Signals For Diagnosis of Epileptic Seizures by Ashwani Singh 117BM0731 Under The Guidance of Prof. Bibhukalyan Prasad NayakDocument29 pagesMatlab Analysis of Eeg Signals For Diagnosis of Epileptic Seizures by Ashwani Singh 117BM0731 Under The Guidance of Prof. Bibhukalyan Prasad NayakAshwani SinghNo ratings yet
- Correspondance AnalysisDocument16 pagesCorrespondance AnalysisSooraj MuraleeNo ratings yet
- Icassp 2017 7952519Document5 pagesIcassp 2017 7952519Anirudh KamarajNo ratings yet
- Analysis For Power System State EstimationDocument9 pagesAnalysis For Power System State EstimationAnonymous TJRX7CNo ratings yet
- Best Basis Intelligent MonitoringDocument14 pagesBest Basis Intelligent Monitoringinsync_001No ratings yet
- Lecture Notes Algorithms in Bioinformatics I - Prof. Daniel HusonDocument28 pagesLecture Notes Algorithms in Bioinformatics I - Prof. Daniel HusonmsNo ratings yet
- Sdimfeisas PDFDocument20 pagesSdimfeisas PDF游俊彥No ratings yet
- On Learning To Identify Genders From Raw Speech Signal Using CnnsDocument5 pagesOn Learning To Identify Genders From Raw Speech Signal Using CnnsharisbinziaNo ratings yet
- (IJCST-V1I2P7) : T.Shanmugavadivu, T.RavichandranDocument3 pages(IJCST-V1I2P7) : T.Shanmugavadivu, T.RavichandranIJETA - EighthSenseGroupNo ratings yet
- Image Quality Assessment and Statistical Evaluation: February 4, 2005Document25 pagesImage Quality Assessment and Statistical Evaluation: February 4, 2005karedokNo ratings yet
- TMP 6 EEEDocument3 pagesTMP 6 EEEFrontiersNo ratings yet
- Gene Sequence AnalysisDocument10 pagesGene Sequence AnalysisÃyûsh KumarNo ratings yet
- A Comparative Study of Different Entropies For Spectrum Sensing TechniquesDocument15 pagesA Comparative Study of Different Entropies For Spectrum Sensing Techniquessuchi87No ratings yet
- New04 Thefuture Sequence To Expression ModellsDocument12 pagesNew04 Thefuture Sequence To Expression ModellssznistvanNo ratings yet
- MATH105 Worksheet 4 1Document10 pagesMATH105 Worksheet 4 1Gia Huong HoangNo ratings yet
- Sizer Analysis For The Comparison of Regression Curves: Cheolwoo Park and Kee-Hoon KangDocument27 pagesSizer Analysis For The Comparison of Regression Curves: Cheolwoo Park and Kee-Hoon KangjofrajodiNo ratings yet
- Chaos Game RrepresentstionDocument14 pagesChaos Game RrepresentstionlenomagnusNo ratings yet
- Nasa - Fully-Coupled Fluid-Structure Vibration Analysis Using NastranDocument84 pagesNasa - Fully-Coupled Fluid-Structure Vibration Analysis Using NastranMinseong KimNo ratings yet
- Report Batch 7Document9 pagesReport Batch 7NandhakumarNo ratings yet
- GRNN For Forecasting Resonance Frequency of Circular Patch AntennaDocument4 pagesGRNN For Forecasting Resonance Frequency of Circular Patch AntennaShruthy ReddyNo ratings yet
- Ozdamar (2014) - Bootstrapping Correspondence AnalysisDocument11 pagesOzdamar (2014) - Bootstrapping Correspondence AnalysisAhmad HassanNo ratings yet
- REMonge JLCrespo DNA Complexity Measures LatexDocument6 pagesREMonge JLCrespo DNA Complexity Measures LatexgokhancantasNo ratings yet
- Gene Expression Data Analysis: MinireviewDocument8 pagesGene Expression Data Analysis: MinireviewAsma MushtaqNo ratings yet
- An Assessment of Prediction Algorithms For Nucleosome PositioningDocument10 pagesAn Assessment of Prediction Algorithms For Nucleosome PositioningSanthaVenkataramanaraoNo ratings yet
- Res NetDocument14 pagesRes NetsamiaikhlefNo ratings yet
- Transient Stability Assessment of Power Systems Using Probabilistic Neural Network With Enhanced Feature Selection and ExtractionDocument12 pagesTransient Stability Assessment of Power Systems Using Probabilistic Neural Network With Enhanced Feature Selection and Extractionrasim_m1146No ratings yet
- Microarray ReviewDocument5 pagesMicroarray ReviewhimaNo ratings yet
- Radiomic Prediction of Tumor Grade and Overall Survival From The BraTS Glioma Dataset SI PDFDocument28 pagesRadiomic Prediction of Tumor Grade and Overall Survival From The BraTS Glioma Dataset SI PDFpradeepNo ratings yet
- International Journal of Computer Science: Theory and ApplicationDocument6 pagesInternational Journal of Computer Science: Theory and ApplicationijcstaNo ratings yet
- Local - PCA - It Is Against PCADocument24 pagesLocal - PCA - It Is Against PCAdr musafirNo ratings yet
- Evolutionary Algorithms Based RBF Neural Networks For Parkinson S Disease DiagnosisDocument5 pagesEvolutionary Algorithms Based RBF Neural Networks For Parkinson S Disease DiagnosisMuhammad Ayaz MirzaNo ratings yet
- Computer Processing of Remotely-Sensed Images: An IntroductionFrom EverandComputer Processing of Remotely-Sensed Images: An IntroductionNo ratings yet
- The Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessFrom EverandThe Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessNo ratings yet
- Classification of Cardiovascular Disease Using Feature Extraction and Artificial Neural NetworksDocument16 pagesClassification of Cardiovascular Disease Using Feature Extraction and Artificial Neural NetworksmuraliNo ratings yet
- ECG-based Human Authentication: A Review: Abstract-The Electrocardiogram (ECG) Is An EmergingDocument6 pagesECG-based Human Authentication: A Review: Abstract-The Electrocardiogram (ECG) Is An EmergingmuraliNo ratings yet
- Communication: Elimination of AC Interference in Electmcardiogram UsingDocument5 pagesCommunication: Elimination of AC Interference in Electmcardiogram UsingmuraliNo ratings yet
- G. H. Patel College of Engineering and Technology: Dhiraj Ramnani - Shail Patil - Darpen PatelDocument1 pageG. H. Patel College of Engineering and Technology: Dhiraj Ramnani - Shail Patil - Darpen PatelmuraliNo ratings yet
- Biomedical Signal Processing and Control: V. Mondéjar-Guerra, J. Novo, J. Rouco, M.G. Penedo, M. OrtegaDocument8 pagesBiomedical Signal Processing and Control: V. Mondéjar-Guerra, J. Novo, J. Rouco, M.G. Penedo, M. OrtegamuraliNo ratings yet
- Sun TR2642Document16 pagesSun TR2642muraliNo ratings yet
- 6.identification of Protein-Coding Regions in DNA SequencesDocument11 pages6.identification of Protein-Coding Regions in DNA SequencesmuraliNo ratings yet
- Applied Sciences: A Novel Heart Rate Robust Method For Short-Term Electrocardiogram Biometric IdentificationDocument20 pagesApplied Sciences: A Novel Heart Rate Robust Method For Short-Term Electrocardiogram Biometric IdentificationmuraliNo ratings yet
- Automatic Detection of The End-Diastolic and End-Systolic From 4D Echocardiographic ImagesDocument11 pagesAutomatic Detection of The End-Diastolic and End-Systolic From 4D Echocardiographic ImagesmuraliNo ratings yet
- Time-Frequency Domain Deep Convolutional Neural Network For The Classification of Focal and Non-Focal EEG SignalsDocument9 pagesTime-Frequency Domain Deep Convolutional Neural Network For The Classification of Focal and Non-Focal EEG SignalsmuraliNo ratings yet
- Brain Sciences: Improved EOG Artifact Removal Using Wavelet Enhanced Independent Component AnalysisDocument22 pagesBrain Sciences: Improved EOG Artifact Removal Using Wavelet Enhanced Independent Component AnalysismuraliNo ratings yet
- A Multi-Channel Approach For Cortical Stimulation Artefact Suppression in Depth EEG Signals Using Time-Frequency and Spatial FilteringDocument12 pagesA Multi-Channel Approach For Cortical Stimulation Artefact Suppression in Depth EEG Signals Using Time-Frequency and Spatial FilteringmuraliNo ratings yet
- Noise Rejection For Wearable Ecgs Using Modified Frequency Slice Wavelet Transform and Convolutional Neural NetworksDocument8 pagesNoise Rejection For Wearable Ecgs Using Modified Frequency Slice Wavelet Transform and Convolutional Neural NetworksmuraliNo ratings yet
- Automatic ECG-Based Emotion Recognition in Music ListeningDocument16 pagesAutomatic ECG-Based Emotion Recognition in Music ListeningmuraliNo ratings yet
- Venkat Es An 2018Document8 pagesVenkat Es An 2018muraliNo ratings yet
- Automated System For Epileptic EEG Detection Using Iterative FilteringDocument4 pagesAutomated System For Epileptic EEG Detection Using Iterative FilteringmuraliNo ratings yet
- Deep Neural Network Based Approach For ECG Classification Using Hybrid Differential Features and Active LearningDocument11 pagesDeep Neural Network Based Approach For ECG Classification Using Hybrid Differential Features and Active LearningmuraliNo ratings yet
- Spatially Adaptive Image Denoising Using Inter-Scale Dependence in Directionlet DomainDocument11 pagesSpatially Adaptive Image Denoising Using Inter-Scale Dependence in Directionlet DomainmuraliNo ratings yet
- MBBS I Assignment Sanjay SirDocument2 pagesMBBS I Assignment Sanjay SirAbhishek PandeyNo ratings yet
- Lost Crops of The Incas: Origins of Domestication of The Andean Pulse Crop Tarwi, Lupinus MutabilisDocument15 pagesLost Crops of The Incas: Origins of Domestication of The Andean Pulse Crop Tarwi, Lupinus MutabilisJosep Dante Norabuena BreasNo ratings yet
- AP Catalase Enzyme LabDocument4 pagesAP Catalase Enzyme LabAesthetic LoverNo ratings yet
- General Biology Mod1Document104 pagesGeneral Biology Mod1mn KimNo ratings yet
- Category A Agents 11Document31 pagesCategory A Agents 11Us ShortaNo ratings yet
- 1503 KJSDLJFLSDF X10Document219 pages1503 KJSDLJFLSDF X10Aaron WallaceNo ratings yet
- HBRDocument26 pagesHBRKiran Rimal100% (1)
- Chapter 19Document61 pagesChapter 19Michelle Dela CruzNo ratings yet
- Aptasensors For Pesticide Detection: Mei Liu, Arshad Khan, Zhifei Wang, Yuan Liu, Gaojian Yang, Yan Deng andDocument49 pagesAptasensors For Pesticide Detection: Mei Liu, Arshad Khan, Zhifei Wang, Yuan Liu, Gaojian Yang, Yan Deng andSintayehu BerhanuNo ratings yet
- EJI and Bryan Stevenson Amicus Brief in Support of SB 1391Document68 pagesEJI and Bryan Stevenson Amicus Brief in Support of SB 1391Celeste FremonNo ratings yet
- Experiment LipidsDocument5 pagesExperiment LipidsSHAFIKANOR3661No ratings yet
- List of Fellows Selected Through Open Recruitment in JapanDocument1 pageList of Fellows Selected Through Open Recruitment in JapanZulfiqar Hussan KuthuNo ratings yet
- Bioplastic Using Coconut MeatDocument5 pagesBioplastic Using Coconut MeatJOSH MARIANO III P. BLANCONo ratings yet
- CV of Professor Henrik Hagberg, Centre For The Developing Brain, King's College LondonDocument2 pagesCV of Professor Henrik Hagberg, Centre For The Developing Brain, King's College LondonIsraelssonNo ratings yet
- Flik Silverpen's Guide ToDocument9 pagesFlik Silverpen's Guide ToSonny3091100% (1)
- Nervous System 2022Document41 pagesNervous System 2022zahra nabilaNo ratings yet
- Q1. Choose The Correct Answer. 1X50 50Document7 pagesQ1. Choose The Correct Answer. 1X50 50Muhammad RizwanNo ratings yet
- ICSE Class 10 Biology 2003Document6 pagesICSE Class 10 Biology 2003SACHIDANANDA SNo ratings yet
- Life Sciences Grade 10 Worksheet 1 Plant TissuesDocument5 pagesLife Sciences Grade 10 Worksheet 1 Plant TissuesEjay OlebogengNo ratings yet
- Syllabus AICE-JRF-SRF-PGS-2019 - 1 PDFDocument89 pagesSyllabus AICE-JRF-SRF-PGS-2019 - 1 PDFrajap02No ratings yet
- Cerebrum: By: Pedro E. Ampil, M.D.FPSA Department of Human Structural Biology Our Lady of Fatima UniversityDocument29 pagesCerebrum: By: Pedro E. Ampil, M.D.FPSA Department of Human Structural Biology Our Lady of Fatima UniversityPlaza Jeanine LouiseNo ratings yet
- Scientific Validation of Standardization of Narayana Chendrooram (Kannusamy Paramparai Vaithiyam) Through The Siddha and Modern TechniquesDocument12 pagesScientific Validation of Standardization of Narayana Chendrooram (Kannusamy Paramparai Vaithiyam) Through The Siddha and Modern TechniquesBala Kiran GaddamNo ratings yet
- Psychology HonsDocument58 pagesPsychology HonsHari kumarNo ratings yet
- Biology and BehaviorDocument7 pagesBiology and BehaviorDanyNo ratings yet
- EutrophicationDocument49 pagesEutrophicationBhe Bhe RanNo ratings yet
- Quiz Lipids and LipoproteinsDocument9 pagesQuiz Lipids and LipoproteinsAllyah Ross DuqueNo ratings yet
- TRANSES ANAPHY Male Reproductive SystemDocument6 pagesTRANSES ANAPHY Male Reproductive SystemPia LouiseNo ratings yet
- B05 QuestionsDocument5 pagesB05 QuestionsMauriya SenthilnathanNo ratings yet
- 3540660208Document223 pages3540660208Iswahyudi AlamsyahNo ratings yet
- SMART-R Based On AIATS - 02-RMDocument8 pagesSMART-R Based On AIATS - 02-RMlovecrimson19No ratings yet