
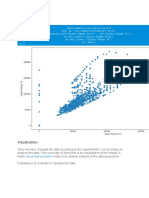
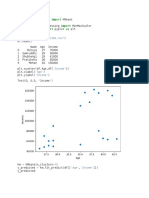
Chapter 3 - Basic Statistical Analysis
Chapter 3 - Basic Statistical Analysis
You might also like
- 035 Assignment PDFDocument14 pages035 Assignment PDFTman LetswaloNo ratings yet
- Advanced Statistics - Project ReportDocument14 pagesAdvanced Statistics - Project ReportRohan Kanungo100% (5)
- Par Inc Written ReportDocument1 pagePar Inc Written ReportJo-Anne VitobinaNo ratings yet
- Bootstrap PowerpointDocument20 pagesBootstrap Powerpointfrancisco1591100% (1)
- Designing Machine Learning Workflows in Python Chapter2Document39 pagesDesigning Machine Learning Workflows in Python Chapter2FgpeqwNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Algo TradingDocument64 pagesAlgo TradingJohn ReedNo ratings yet
- Clustering Documentation Python CodeDocument8 pagesClustering Documentation Python Codenehal gundrapallyNo ratings yet
- Pratik Zanke Source CodesDocument20 pagesPratik Zanke Source Codespratik zankeNo ratings yet
- In in in In: '/kaggle/input/data-19-1/data'Document6 pagesIn in in In: '/kaggle/input/data-19-1/data'sambitsoftNo ratings yet
- Spark Walmart Data Analysis ProjectDocument17 pagesSpark Walmart Data Analysis ProjectAnkit SharmaNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Lecture 22Document64 pagesLecture 22Tev WallaceNo ratings yet
- Chapter 4 - Linear RegressionDocument25 pagesChapter 4 - Linear Regressionanshita100% (2)
- ARIMADocument8 pagesARIMAQuinn AvrilNo ratings yet
- IoT Final JournalDocument31 pagesIoT Final JournalDivya RajputNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (2)
- 2020BIT007 Assignment No7.Ipynb - ColaboratoryDocument2 pages2020BIT007 Assignment No7.Ipynb - Colaboratoryaqonline906No ratings yet
- PPP Models - GARCH & NARNN - Ipynb - ColaboratoryDocument13 pagesPPP Models - GARCH & NARNN - Ipynb - ColaboratorysethantanahNo ratings yet
- Correlation and Regression (TP)Document4 pagesCorrelation and Regression (TP)Hiimay ChannelNo ratings yet
- Designing Machine Learning Workflows in Python Chapter3Document42 pagesDesigning Machine Learning Workflows in Python Chapter3FgpeqwNo ratings yet
- Deep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - CookbookDocument27 pagesDeep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - Cookbookmahmoudahmed.rtaNo ratings yet
- Lecture 02-Amdahl's Law, Modern Hardware: ECE 459: Programming For PerformanceDocument13 pagesLecture 02-Amdahl's Law, Modern Hardware: ECE 459: Programming For PerformancemirionNo ratings yet
- Random Forest: Implementaciones de Scikit-Learn Sobre QSARDocument11 pagesRandom Forest: Implementaciones de Scikit-Learn Sobre QSARRichard Jimenez100% (1)
- Simple Linear RegressionDocument4 pagesSimple Linear Regressionjaymehta1444No ratings yet
- How To StatspackDocument7 pagesHow To StatspackWeiChrNo ratings yet
- Scatterplot: VisualizationDocument6 pagesScatterplot: VisualizationrockineverNo ratings yet
- Rolling Window Functions With PandasDocument37 pagesRolling Window Functions With PandasVadim YermolenkoNo ratings yet
- Stock Prediction Web App - Jupyter NotebookDocument12 pagesStock Prediction Web App - Jupyter Notebookashutosh312004No ratings yet
- KmeansDocument7 pagesKmeanspatil samrudhiNo ratings yet
- PPP Models - ARIMA & NARNN - Ipynb - ColaboratoryDocument8 pagesPPP Models - ARIMA & NARNN - Ipynb - ColaboratorysethantanahNo ratings yet
- Attention Intensity As Contrarian Factor Tilt: HangukquantDocument20 pagesAttention Intensity As Contrarian Factor Tilt: HangukquantKiran RNo ratings yet
- Lab - 8 - 21130568 - NguyenNhuToan - Ipynb - ColabDocument4 pagesLab - 8 - 21130568 - NguyenNhuToan - Ipynb - Colabnguyennhutoan722003No ratings yet
- Chapter 4Document31 pagesChapter 4david AbotsitseNo ratings yet
- Stock AnalysisDocument16 pagesStock AnalysisAbhisek KeshariNo ratings yet
- Chapter 1Document36 pagesChapter 1david AbotsitseNo ratings yet
- BDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Document10 pagesBDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Saleh ZulNo ratings yet
- Final CodingDocument6 pagesFinal CodingSasikala RajendranNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- 3 Creating Features - KaggleDocument14 pages3 Creating Features - KagglePrujith Muthu RamNo ratings yet
- Importing Packages: Id Label Tweet 0 1 2 3 4Document8 pagesImporting Packages: Id Label Tweet 0 1 2 3 4rajat rainaNo ratings yet
- DA Lab 1-7Document26 pagesDA Lab 1-7vishwas guptaNo ratings yet
- Part 1Document13 pagesPart 1Tik TokNo ratings yet
- Forecast MLDocument24 pagesForecast MLMonica Ionita-Scholz100% (1)
- Fds MannualDocument39 pagesFds MannualsudhaNo ratings yet
- ML LAB Mannual - IndexDocument29 pagesML LAB Mannual - IndexNisahd hiteshNo ratings yet
- Bootstrap PowerpointDocument10 pagesBootstrap PowerpointJose C Beraun Tapia100% (1)
- 178 DLDocument31 pages178 DLNidhiNo ratings yet
- Back Testing For Algorithmic Trading StrategiesDocument24 pagesBack Testing For Algorithmic Trading Strategiesandy paulNo ratings yet
- LSTM Stock PredictionDocument38 pagesLSTM Stock PredictionKetan Ingale100% (1)
- Assignment 4Document5 pagesAssignment 4shellieratheeNo ratings yet
- Deep Learning CH3Document22 pagesDeep Learning CH3Mikistli YowaltekutliNo ratings yet
- Oil Export IndonesiaDocument12 pagesOil Export IndonesiaRifky Kurniawan100% (1)
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- Statistical Data Analysis - Ipynb - ColaboratoryDocument6 pagesStatistical Data Analysis - Ipynb - ColaboratoryVarad KulkarniNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- ML File FinalDocument11 pagesML File FinalGautam SharmaNo ratings yet
- Chapter 3Document58 pagesChapter 3david AbotsitseNo ratings yet
- Final Cyber Security Book (2014-15)Document188 pagesFinal Cyber Security Book (2014-15)Kartik GulatiNo ratings yet
- Deep Security 95 Admin Guide ENDocument272 pagesDeep Security 95 Admin Guide ENKartik GulatiNo ratings yet
- Server Hardware Guide To Architecture, Products and ManagementDocument26 pagesServer Hardware Guide To Architecture, Products and ManagementKartik GulatiNo ratings yet
- Pay After Placement: Pay Nothing Till You Get ADocument4 pagesPay After Placement: Pay Nothing Till You Get AKartik GulatiNo ratings yet
- Data Networks by Dimitri Bertsekas Robert Gallager PDFDocument500 pagesData Networks by Dimitri Bertsekas Robert Gallager PDFKartik GulatiNo ratings yet
- Inferno: Guidelines & RulebookDocument15 pagesInferno: Guidelines & RulebookKartik GulatiNo ratings yet
- O5 ReliabilityDocument68 pagesO5 ReliabilityArin NimtrakulNo ratings yet
- An Open Source Python Library For Environmental Isotopic ModellingDocument19 pagesAn Open Source Python Library For Environmental Isotopic ModellingAndres Felipe Porras RiosNo ratings yet
- QuestionsDocument5 pagesQuestionshuzaifa mirzaNo ratings yet
- Ml2 MergedDocument15 pagesMl2 Mergedharshbafna.ei20No ratings yet
- AP Statistics Semester Exam ReviewDocument9 pagesAP Statistics Semester Exam Reviewkiraayumi6789100% (1)
- Exact LogisticDocument10 pagesExact LogisticrahulsukhijaNo ratings yet
- Education and Economic Growth A Meta Regression AnalysisDocument21 pagesEducation and Economic Growth A Meta Regression AnalysisssrassrNo ratings yet
- Choosing A Statistical Test PDFDocument5 pagesChoosing A Statistical Test PDFmpc.9315970No ratings yet
- Chapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian ThinkingDocument17 pagesChapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian Thinkingmrs dosadoNo ratings yet
- Z ScoreDocument10 pagesZ Scorefeva55No ratings yet
- Session 6-15 - Unit II & III: Probability and Distribution, Classical TestsDocument34 pagesSession 6-15 - Unit II & III: Probability and Distribution, Classical TestsRahul B 2B.ComSec 2No ratings yet
- CF Chapter 12 Excel Master StudentDocument25 pagesCF Chapter 12 Excel Master Studentsambi619No ratings yet
- Bank RpubsDocument24 pagesBank RpubsAnil Kumar NayakNo ratings yet
- AP Statistics Review 2013Document79 pagesAP Statistics Review 2013Jonathan TranNo ratings yet
- Sessions 21-24 Factor Analysis - Ppt-RevDocument61 pagesSessions 21-24 Factor Analysis - Ppt-Revnandini swamiNo ratings yet
- Chapter 6 - 2020Document62 pagesChapter 6 - 2020Nga Ying WuNo ratings yet
- R-Cheatsheet: Help Numerical Summaries Linear RegressionDocument2 pagesR-Cheatsheet: Help Numerical Summaries Linear RegressionSieben DoppeltNo ratings yet
- Sciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovalDocument7 pagesSciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovallaylaNo ratings yet
- SWAYAM Syllabus - Predictive - AnalyticsnewDocument3 pagesSWAYAM Syllabus - Predictive - AnalyticsnewUNikz (Official)No ratings yet
- Anindita Kusuma Ardiani G2A009148 BabVIIIKTIDocument15 pagesAnindita Kusuma Ardiani G2A009148 BabVIIIKTIAulia Rohmawati FitrianingsihNo ratings yet
- HeteroskedasticityDocument12 pagesHeteroskedasticityMNo ratings yet
- Predicting Wins in BaseballDocument7 pagesPredicting Wins in BaseballgarrettherrNo ratings yet
- BA4101 STATISTICS FOR MANAGEMENT Reg 21 Question BankDocument11 pagesBA4101 STATISTICS FOR MANAGEMENT Reg 21 Question BankRishi vardhiniNo ratings yet
- Cronch Bach Alpha Test RealiabilityDocument6 pagesCronch Bach Alpha Test Realiabilityzaka4decNo ratings yet
- StatProb11 Q4 Mod3 RegressionAnalysis v4Document21 pagesStatProb11 Q4 Mod3 RegressionAnalysis v4ALEX SARAOSOS100% (4)
- Testing Hypothesis - One Sample Test: Chapter - 8Document52 pagesTesting Hypothesis - One Sample Test: Chapter - 8Sumit AcharyaNo ratings yet
- (Bruderl) Applied Regression Analysis Using StataDocument73 pages(Bruderl) Applied Regression Analysis Using StataSanjiv DesaiNo ratings yet
- Jahangirnagar University: An Assignment OnDocument16 pagesJahangirnagar University: An Assignment Onsadia suhiNo ratings yet
- Dimensionality - Reduction - Principal - Component - Analysis - Ipynb at Master Llsourcell - Dimensionality - Reduction GitHubDocument14 pagesDimensionality - Reduction - Principal - Component - Analysis - Ipynb at Master Llsourcell - Dimensionality - Reduction GitHubsid raiNo ratings yet






























































































Download as pdf or txt
You might also like
- 035 Assignment PDFDocument14 pages035 Assignment PDFTman LetswaloNo ratings yet
- Advanced Statistics - Project ReportDocument14 pagesAdvanced Statistics - Project ReportRohan Kanungo100% (5)
- Par Inc Written ReportDocument1 pagePar Inc Written ReportJo-Anne VitobinaNo ratings yet
- Bootstrap PowerpointDocument20 pagesBootstrap Powerpointfrancisco1591100% (1)
- Designing Machine Learning Workflows in Python Chapter2Document39 pagesDesigning Machine Learning Workflows in Python Chapter2FgpeqwNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Algo TradingDocument64 pagesAlgo TradingJohn ReedNo ratings yet
- Clustering Documentation Python CodeDocument8 pagesClustering Documentation Python Codenehal gundrapallyNo ratings yet
- Pratik Zanke Source CodesDocument20 pagesPratik Zanke Source Codespratik zankeNo ratings yet
- In in in In: '/kaggle/input/data-19-1/data'Document6 pagesIn in in In: '/kaggle/input/data-19-1/data'sambitsoftNo ratings yet
- Spark Walmart Data Analysis ProjectDocument17 pagesSpark Walmart Data Analysis ProjectAnkit SharmaNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Lecture 22Document64 pagesLecture 22Tev WallaceNo ratings yet
- Chapter 4 - Linear RegressionDocument25 pagesChapter 4 - Linear Regressionanshita100% (2)
- ARIMADocument8 pagesARIMAQuinn AvrilNo ratings yet
- IoT Final JournalDocument31 pagesIoT Final JournalDivya RajputNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (2)
- 2020BIT007 Assignment No7.Ipynb - ColaboratoryDocument2 pages2020BIT007 Assignment No7.Ipynb - Colaboratoryaqonline906No ratings yet
- PPP Models - GARCH & NARNN - Ipynb - ColaboratoryDocument13 pagesPPP Models - GARCH & NARNN - Ipynb - ColaboratorysethantanahNo ratings yet
- Correlation and Regression (TP)Document4 pagesCorrelation and Regression (TP)Hiimay ChannelNo ratings yet
- Designing Machine Learning Workflows in Python Chapter3Document42 pagesDesigning Machine Learning Workflows in Python Chapter3FgpeqwNo ratings yet
- Deep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - CookbookDocument27 pagesDeep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - Cookbookmahmoudahmed.rtaNo ratings yet
- Lecture 02-Amdahl's Law, Modern Hardware: ECE 459: Programming For PerformanceDocument13 pagesLecture 02-Amdahl's Law, Modern Hardware: ECE 459: Programming For PerformancemirionNo ratings yet
- Random Forest: Implementaciones de Scikit-Learn Sobre QSARDocument11 pagesRandom Forest: Implementaciones de Scikit-Learn Sobre QSARRichard Jimenez100% (1)
- Simple Linear RegressionDocument4 pagesSimple Linear Regressionjaymehta1444No ratings yet
- How To StatspackDocument7 pagesHow To StatspackWeiChrNo ratings yet
- Scatterplot: VisualizationDocument6 pagesScatterplot: VisualizationrockineverNo ratings yet
- Rolling Window Functions With PandasDocument37 pagesRolling Window Functions With PandasVadim YermolenkoNo ratings yet
- Stock Prediction Web App - Jupyter NotebookDocument12 pagesStock Prediction Web App - Jupyter Notebookashutosh312004No ratings yet
- KmeansDocument7 pagesKmeanspatil samrudhiNo ratings yet
- PPP Models - ARIMA & NARNN - Ipynb - ColaboratoryDocument8 pagesPPP Models - ARIMA & NARNN - Ipynb - ColaboratorysethantanahNo ratings yet
- Attention Intensity As Contrarian Factor Tilt: HangukquantDocument20 pagesAttention Intensity As Contrarian Factor Tilt: HangukquantKiran RNo ratings yet
- Lab - 8 - 21130568 - NguyenNhuToan - Ipynb - ColabDocument4 pagesLab - 8 - 21130568 - NguyenNhuToan - Ipynb - Colabnguyennhutoan722003No ratings yet
- Chapter 4Document31 pagesChapter 4david AbotsitseNo ratings yet
- Stock AnalysisDocument16 pagesStock AnalysisAbhisek KeshariNo ratings yet
- Chapter 1Document36 pagesChapter 1david AbotsitseNo ratings yet
- BDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Document10 pagesBDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Saleh ZulNo ratings yet
- Final CodingDocument6 pagesFinal CodingSasikala RajendranNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- 3 Creating Features - KaggleDocument14 pages3 Creating Features - KagglePrujith Muthu RamNo ratings yet
- Importing Packages: Id Label Tweet 0 1 2 3 4Document8 pagesImporting Packages: Id Label Tweet 0 1 2 3 4rajat rainaNo ratings yet
- DA Lab 1-7Document26 pagesDA Lab 1-7vishwas guptaNo ratings yet
- Part 1Document13 pagesPart 1Tik TokNo ratings yet
- Forecast MLDocument24 pagesForecast MLMonica Ionita-Scholz100% (1)
- Fds MannualDocument39 pagesFds MannualsudhaNo ratings yet
- ML LAB Mannual - IndexDocument29 pagesML LAB Mannual - IndexNisahd hiteshNo ratings yet
- Bootstrap PowerpointDocument10 pagesBootstrap PowerpointJose C Beraun Tapia100% (1)
- 178 DLDocument31 pages178 DLNidhiNo ratings yet
- Back Testing For Algorithmic Trading StrategiesDocument24 pagesBack Testing For Algorithmic Trading Strategiesandy paulNo ratings yet
- LSTM Stock PredictionDocument38 pagesLSTM Stock PredictionKetan Ingale100% (1)
- Assignment 4Document5 pagesAssignment 4shellieratheeNo ratings yet
- Deep Learning CH3Document22 pagesDeep Learning CH3Mikistli YowaltekutliNo ratings yet
- Oil Export IndonesiaDocument12 pagesOil Export IndonesiaRifky Kurniawan100% (1)
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- Statistical Data Analysis - Ipynb - ColaboratoryDocument6 pagesStatistical Data Analysis - Ipynb - ColaboratoryVarad KulkarniNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- ML File FinalDocument11 pagesML File FinalGautam SharmaNo ratings yet
- Chapter 3Document58 pagesChapter 3david AbotsitseNo ratings yet
- Final Cyber Security Book (2014-15)Document188 pagesFinal Cyber Security Book (2014-15)Kartik GulatiNo ratings yet
- Deep Security 95 Admin Guide ENDocument272 pagesDeep Security 95 Admin Guide ENKartik GulatiNo ratings yet
- Server Hardware Guide To Architecture, Products and ManagementDocument26 pagesServer Hardware Guide To Architecture, Products and ManagementKartik GulatiNo ratings yet
- Pay After Placement: Pay Nothing Till You Get ADocument4 pagesPay After Placement: Pay Nothing Till You Get AKartik GulatiNo ratings yet
- Data Networks by Dimitri Bertsekas Robert Gallager PDFDocument500 pagesData Networks by Dimitri Bertsekas Robert Gallager PDFKartik GulatiNo ratings yet
- Inferno: Guidelines & RulebookDocument15 pagesInferno: Guidelines & RulebookKartik GulatiNo ratings yet
- O5 ReliabilityDocument68 pagesO5 ReliabilityArin NimtrakulNo ratings yet
- An Open Source Python Library For Environmental Isotopic ModellingDocument19 pagesAn Open Source Python Library For Environmental Isotopic ModellingAndres Felipe Porras RiosNo ratings yet
- QuestionsDocument5 pagesQuestionshuzaifa mirzaNo ratings yet
- Ml2 MergedDocument15 pagesMl2 Mergedharshbafna.ei20No ratings yet
- AP Statistics Semester Exam ReviewDocument9 pagesAP Statistics Semester Exam Reviewkiraayumi6789100% (1)
- Exact LogisticDocument10 pagesExact LogisticrahulsukhijaNo ratings yet
- Education and Economic Growth A Meta Regression AnalysisDocument21 pagesEducation and Economic Growth A Meta Regression AnalysisssrassrNo ratings yet
- Choosing A Statistical Test PDFDocument5 pagesChoosing A Statistical Test PDFmpc.9315970No ratings yet
- Chapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian ThinkingDocument17 pagesChapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian Thinkingmrs dosadoNo ratings yet
- Z ScoreDocument10 pagesZ Scorefeva55No ratings yet
- Session 6-15 - Unit II & III: Probability and Distribution, Classical TestsDocument34 pagesSession 6-15 - Unit II & III: Probability and Distribution, Classical TestsRahul B 2B.ComSec 2No ratings yet
- CF Chapter 12 Excel Master StudentDocument25 pagesCF Chapter 12 Excel Master Studentsambi619No ratings yet
- Bank RpubsDocument24 pagesBank RpubsAnil Kumar NayakNo ratings yet
- AP Statistics Review 2013Document79 pagesAP Statistics Review 2013Jonathan TranNo ratings yet
- Sessions 21-24 Factor Analysis - Ppt-RevDocument61 pagesSessions 21-24 Factor Analysis - Ppt-Revnandini swamiNo ratings yet
- Chapter 6 - 2020Document62 pagesChapter 6 - 2020Nga Ying WuNo ratings yet
- R-Cheatsheet: Help Numerical Summaries Linear RegressionDocument2 pagesR-Cheatsheet: Help Numerical Summaries Linear RegressionSieben DoppeltNo ratings yet
- Sciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovalDocument7 pagesSciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovallaylaNo ratings yet
- SWAYAM Syllabus - Predictive - AnalyticsnewDocument3 pagesSWAYAM Syllabus - Predictive - AnalyticsnewUNikz (Official)No ratings yet
- Anindita Kusuma Ardiani G2A009148 BabVIIIKTIDocument15 pagesAnindita Kusuma Ardiani G2A009148 BabVIIIKTIAulia Rohmawati FitrianingsihNo ratings yet
- HeteroskedasticityDocument12 pagesHeteroskedasticityMNo ratings yet
- Predicting Wins in BaseballDocument7 pagesPredicting Wins in BaseballgarrettherrNo ratings yet
- BA4101 STATISTICS FOR MANAGEMENT Reg 21 Question BankDocument11 pagesBA4101 STATISTICS FOR MANAGEMENT Reg 21 Question BankRishi vardhiniNo ratings yet
- Cronch Bach Alpha Test RealiabilityDocument6 pagesCronch Bach Alpha Test Realiabilityzaka4decNo ratings yet
- StatProb11 Q4 Mod3 RegressionAnalysis v4Document21 pagesStatProb11 Q4 Mod3 RegressionAnalysis v4ALEX SARAOSOS100% (4)
- Testing Hypothesis - One Sample Test: Chapter - 8Document52 pagesTesting Hypothesis - One Sample Test: Chapter - 8Sumit AcharyaNo ratings yet
- (Bruderl) Applied Regression Analysis Using StataDocument73 pages(Bruderl) Applied Regression Analysis Using StataSanjiv DesaiNo ratings yet
- Jahangirnagar University: An Assignment OnDocument16 pagesJahangirnagar University: An Assignment Onsadia suhiNo ratings yet
- Dimensionality - Reduction - Principal - Component - Analysis - Ipynb at Master Llsourcell - Dimensionality - Reduction GitHubDocument14 pagesDimensionality - Reduction - Principal - Component - Analysis - Ipynb at Master Llsourcell - Dimensionality - Reduction GitHubsid raiNo ratings yet