
05 High Level Synthesis
05 High Level Synthesis
You might also like
- Logic Programming in Scheme PDFDocument41 pagesLogic Programming in Scheme PDFbwbuizNo ratings yet
- Mobo TsimDocument5 pagesMobo Tsimمہندس احسنNo ratings yet
- VLSI CAD Flow: Logic Synthesis, Placement and Routing: Guest Lecture by Srini DevadasDocument70 pagesVLSI CAD Flow: Logic Synthesis, Placement and Routing: Guest Lecture by Srini DevadasxperiaashNo ratings yet
- High LevelDocument29 pagesHigh LevelHemant SaraswatNo ratings yet
- High Level Synthesis - 02 - Basic ConceptsDocument27 pagesHigh Level Synthesis - 02 - Basic Conceptsa bNo ratings yet
- ECE545 Lecture 7 DataflowDocument59 pagesECE545 Lecture 7 Dataflowjoshiprashant14No ratings yet
- F9 FM FormulasDocument8 pagesF9 FM Formulas5561 ROSHAN K PATELNo ratings yet
- DS in C++ Tim BuddDocument24 pagesDS in C++ Tim BuddQuânNo ratings yet
- Unit II: Instruction Set and Addressing ModesDocument53 pagesUnit II: Instruction Set and Addressing ModesriyasekaranNo ratings yet
- Lecture 20Document11 pagesLecture 20Aviral UpadhyayNo ratings yet
- CMOS Transistor Theory: Thanks To Prof. David HarrisDocument29 pagesCMOS Transistor Theory: Thanks To Prof. David HarrisHarshdeep BhatiaNo ratings yet
- Chapter # 3: Multi-Level Combinational Logic: Contemporary Logic Design Contemporary Logic DesignDocument13 pagesChapter # 3: Multi-Level Combinational Logic: Contemporary Logic Design Contemporary Logic Designrtavares_980738No ratings yet
- A Goal Programming Model For Working Capital ManagementDocument4 pagesA Goal Programming Model For Working Capital ManagementBharatKathuriaNo ratings yet
- CSE304 - Design & Analysis of Algorithms: Articulation Points, Bridges & Biconnected ComponentsDocument19 pagesCSE304 - Design & Analysis of Algorithms: Articulation Points, Bridges & Biconnected ComponentsMonjurur shipuNo ratings yet
- Lecture 7Document80 pagesLecture 7Rüstem EleçNo ratings yet
- F9 ACCA Summary - Revision Notes 2017Document96 pagesF9 ACCA Summary - Revision Notes 2017alihihai113No ratings yet
- N098 - MM - Exp 2Document6 pagesN098 - MM - Exp 2Vedashree ShetyeNo ratings yet
- Solving Multiobjective Models With GAMSDocument19 pagesSolving Multiobjective Models With GAMSoida_adNo ratings yet
- Cse 323 Cse 42Document2 pagesCse 323 Cse 42rarafat4057No ratings yet
- Cubic Functions: Any Function of The FormDocument5 pagesCubic Functions: Any Function of The FormDave ToddNo ratings yet
- High-Level Synthesis: Hao Zheng Comp Sci & Eng University of South FloridaDocument26 pagesHigh-Level Synthesis: Hao Zheng Comp Sci & Eng University of South Floridamdumar umarNo ratings yet
- Kal 02Document17 pagesKal 02IisacGNo ratings yet
- Lecture 4 - Implementing Logic in CMOSDocument32 pagesLecture 4 - Implementing Logic in CMOSsadia santaNo ratings yet
- Tutorial 9 Defining Relation Resolution Design GeneratorDocument1 pageTutorial 9 Defining Relation Resolution Design GeneratorigeNo ratings yet
- 22sp-041-cs Lab3 CO&ALDocument8 pages22sp-041-cs Lab3 CO&ALSubul RazaNo ratings yet
- csc2001f 2024 7 Avl TreesDocument30 pagescsc2001f 2024 7 Avl TreeshmdprkrNo ratings yet
- B.Tech / It /3 SEM/ INFO 2101/2017 B.Tech / It /3 SEM/ INFO 2101/2017Document2 pagesB.Tech / It /3 SEM/ INFO 2101/2017 B.Tech / It /3 SEM/ INFO 2101/2017Vikash KumarNo ratings yet
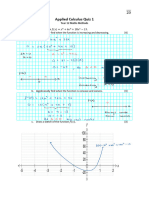
- Applied Calculus Quiz 1 SolutionsDocument2 pagesApplied Calculus Quiz 1 SolutionsAndrew EwersNo ratings yet
- Drawing PDFDocument1 pageDrawing PDFSaraMuzaffarNo ratings yet
- Classification: Linear SVMDocument26 pagesClassification: Linear SVMLiamNo ratings yet
- Lecture10 Nosql PDFDocument80 pagesLecture10 Nosql PDFManisha_tNo ratings yet
- Stick DiagDocument6 pagesStick DiagSrinu BoddulaNo ratings yet
- L06 RISCV FunctionsDocument49 pagesL06 RISCV FunctionsTuấn LêNo ratings yet
- Introml 02 Regression Annotated PDFDocument26 pagesIntroml 02 Regression Annotated PDFMark NamNo ratings yet
- Conformal and BilinearDocument8 pagesConformal and BilinearSaddam HusainNo ratings yet
- Ap Calc Ab NotesDocument3 pagesAp Calc Ab NotesMiaNo ratings yet
- Mid Term 15,16 AnswerDocument13 pagesMid Term 15,16 AnswerSofwan JuewekNo ratings yet
- 2019 - Csen 4101Document2 pages2019 - Csen 4101poxemik697covbasecomNo ratings yet
- 2016 IT601 DBMS OldDocument3 pages2016 IT601 DBMS OldSUCHHANDA CHAKRABORTYNo ratings yet
- Indefinite & Definite Integration (XII)Document31 pagesIndefinite & Definite Integration (XII)prathmesh guptaNo ratings yet
- Discrete Structures: Wonsook Lee Wslee@Uottawa - Ca Eecs, Univ. of OttawaDocument34 pagesDiscrete Structures: Wonsook Lee Wslee@Uottawa - Ca Eecs, Univ. of OttawaIbrahim KanoucheNo ratings yet
- 05 Brute ForceDocument56 pages05 Brute ForcejojoNo ratings yet
- 99 09H Cal1-212 S09 E Improper ApplyDefP1Document20 pages99 09H Cal1-212 S09 E Improper ApplyDefP1Hoài Nguyễn Phan VũNo ratings yet
- 37 (COM 2) 2.3 2017 Operations Research and Computer in BusinessDocument7 pages37 (COM 2) 2.3 2017 Operations Research and Computer in BusinessSahu PraveenNo ratings yet
- Foundations of C++: Bjarne StroustrupDocument22 pagesFoundations of C++: Bjarne StroustrupcarluxNo ratings yet
- Cubic Functions - IBDP Mathematics - Applications and Interpretation SL FE2021 - KognityDocument6 pagesCubic Functions - IBDP Mathematics - Applications and Interpretation SL FE2021 - KognityMirjeta ZymeriNo ratings yet
- D/A Converters Continued:: - Component Matching - Systematic & Random ErrorsDocument31 pagesD/A Converters Continued:: - Component Matching - Systematic & Random ErrorsAvinash BadanikaiNo ratings yet
- 21529sm Finalnew Vol2 Cp10Document85 pages21529sm Finalnew Vol2 Cp10Ravi ReddyNo ratings yet
- Computational Techniques in Civil Engineering: 6. Method of Characteristics (MOC)Document5 pagesComputational Techniques in Civil Engineering: 6. Method of Characteristics (MOC)yeee boiiiNo ratings yet
- 9 - GraphsDocument61 pages9 - GraphsMai Cao Thị ThanhNo ratings yet
- Embedded Systems - 16CS402: Department of Computer Science and Engineering, Dayananda Sagar University, BengaluruDocument137 pagesEmbedded Systems - 16CS402: Department of Computer Science and Engineering, Dayananda Sagar University, BengaluruKiran KiruNo ratings yet
- Free Sample Test: Function Int N (For I 1 I N I++ For J 1 J N J J 2 PR Int F " GATE " )Document14 pagesFree Sample Test: Function Int N (For I 1 I N I++ For J 1 J N J J 2 PR Int F " GATE " )Kanchan jainNo ratings yet
- Omogen Heap: KTH Royal Institute of TechnologyDocument26 pagesOmogen Heap: KTH Royal Institute of TechnologyMuhammad NaufalNo ratings yet
- Formula Iitjee Integral-CalculusDocument17 pagesFormula Iitjee Integral-CalculusKshitij BahukhandiNo ratings yet
- Omogen Heap: KTH Royal Institute of TechnologyDocument25 pagesOmogen Heap: KTH Royal Institute of TechnologyArthom ZMinecraftNo ratings yet
- Ratio and Proportion Question With Solution Free PDF@WWW - Letsstudytogether.coDocument36 pagesRatio and Proportion Question With Solution Free PDF@WWW - Letsstudytogether.corahulrp3031No ratings yet
- Inside The Digital Gate: Circuits ElectronicsDocument20 pagesInside The Digital Gate: Circuits ElectronicsMitpdfNo ratings yet
- DigSysDes Fall2021 Lec18Document23 pagesDigSysDes Fall2021 Lec18Best of BestNo ratings yet
- 1 PBDocument9 pages1 PBAbdiel Perez RamosNo ratings yet
- Long (Buy) Positions Short (Sell) PositionsDocument8 pagesLong (Buy) Positions Short (Sell) PositionsTuan Nguyen MinhNo ratings yet
- Very Large Scale IntegrationDocument35 pagesVery Large Scale IntegrationShakeel EngyNo ratings yet
- Scheduling Algorithms For High-Level SynthesisDocument10 pagesScheduling Algorithms For High-Level SynthesisShakeel EngyNo ratings yet
- Guidelines For Report WritingDocument4 pagesGuidelines For Report WritingShakeel EngyNo ratings yet
- Mohammad Shakeel Ahmed: Carrier ObjectiveDocument3 pagesMohammad Shakeel Ahmed: Carrier ObjectiveShakeel EngyNo ratings yet
- Nr-r09 Modern Control TheoryDocument2 pagesNr-r09 Modern Control TheoryShakeel EngyNo ratings yet
- Nr-r09 Analysis of Power Electronic ConvertersDocument2 pagesNr-r09 Analysis of Power Electronic ConvertersShakeel EngyNo ratings yet
- Analysis and Design of Multi Storied Building by Using Etabs SoftwareDocument2 pagesAnalysis and Design of Multi Storied Building by Using Etabs SoftwareShakeel EngyNo ratings yet
- MicroDocument17 pagesMicroShakeel EngyNo ratings yet
- Project Guidelines Project Diary Project Report Format MeDocument20 pagesProject Guidelines Project Diary Project Report Format MeShakeel EngyNo ratings yet
- Project Guidelines Project Diary Project Report Format MeDocument20 pagesProject Guidelines Project Diary Project Report Format MeShakeel EngyNo ratings yet
- Message Control For InvoiceDocument7 pagesMessage Control For InvoiceJesse Townsend100% (1)
- 91 Computer ScienceDocument23 pages91 Computer ScienceAnkit ShawNo ratings yet
- Hi Tech c18 ManualDocument334 pagesHi Tech c18 ManualwizardgrtNo ratings yet
- EEX4465 - Data Structures and Algorithms 2020/2021: Tutor Marked Assignment - #2 Deadline OnDocument2 pagesEEX4465 - Data Structures and Algorithms 2020/2021: Tutor Marked Assignment - #2 Deadline OnNawam UdayangaNo ratings yet
- AISCIENCES - Data Science Cookbook - V0Document244 pagesAISCIENCES - Data Science Cookbook - V0KayNo ratings yet
- Constraint Satisfaction Problems: AIMA: Chapter 6Document64 pagesConstraint Satisfaction Problems: AIMA: Chapter 6Sunilkumar ReddyNo ratings yet
- Mainframe Refresher MuthuDocument47 pagesMainframe Refresher MuthumohanakrisnakNo ratings yet
- Synapseindia Dot Net Development - Programming OverviewDocument27 pagesSynapseindia Dot Net Development - Programming OverviewsynapseindiaappsdevelopmentNo ratings yet
- Systolic ArchitectureDocument2 pagesSystolic Architecturepoulomi santraNo ratings yet
- Installation: of SAP PI 7.5 and HigherDocument17 pagesInstallation: of SAP PI 7.5 and Higherhunter.correaNo ratings yet
- Zip Trees (Robert E. Tarjany Caleb C. Levyz)Document16 pagesZip Trees (Robert E. Tarjany Caleb C. Levyz)MEGUELLATI Fahd MustaphaNo ratings yet
- Java AssignmentDocument4 pagesJava AssignmentAndrew LassiaNo ratings yet
- Midterm 2011 SolutionDocument5 pagesMidterm 2011 Solutionisraa_melacaNo ratings yet
- FCP University Question PaperDocument11 pagesFCP University Question PaperjananiseNo ratings yet
- Overview of C++ Memory ManagementDocument19 pagesOverview of C++ Memory ManagementChamara JayalathNo ratings yet
- Design Facility Reference 4.1Document642 pagesDesign Facility Reference 4.1propmohamedNo ratings yet
- Term 1 CS Practical File 2021-22Document18 pagesTerm 1 CS Practical File 2021-22ranaNo ratings yet
- Slivers DemystifiedDocument14 pagesSlivers DemystifiedSanti LopezNo ratings yet
- Cembrano, Stephanie Rei Allana S. DICT 2-1 Quiz 1Document4 pagesCembrano, Stephanie Rei Allana S. DICT 2-1 Quiz 1Rei CembranoNo ratings yet
- OutputDocument86 pagesOutputSkydiver DortmundNo ratings yet
- Can't Follow Non-Constant Source. Use A Directive To Specify LocationDocument2 pagesCan't Follow Non-Constant Source. Use A Directive To Specify LocationPilar Rodriguez HijasNo ratings yet
- Delphi XE2 Foundations Part 2 Rolliston Chris PDFDocument174 pagesDelphi XE2 Foundations Part 2 Rolliston Chris PDFRadovan JaicNo ratings yet
- Unit IvDocument78 pagesUnit IvSudhakar SelvamNo ratings yet
- Operating System Concepts (Exercises and Answers) Part IIDocument7 pagesOperating System Concepts (Exercises and Answers) Part IIAlfred Fred100% (1)
- Worksheet 3.1Document20 pagesWorksheet 3.1Vatsal SharmaNo ratings yet
- TAW10 ABAP Workbench Fundamentals: Course GoalsDocument2 pagesTAW10 ABAP Workbench Fundamentals: Course GoalsUmeshNo ratings yet
- LogDocument84 pagesLoghi manNo ratings yet
- Antlr 4 Guide To Help U LearnDocument37 pagesAntlr 4 Guide To Help U LearnNaveen Kothapally KumarNo ratings yet































































































Download as pdf or txt
You might also like
- Logic Programming in Scheme PDFDocument41 pagesLogic Programming in Scheme PDFbwbuizNo ratings yet
- Mobo TsimDocument5 pagesMobo Tsimمہندس احسنNo ratings yet
- VLSI CAD Flow: Logic Synthesis, Placement and Routing: Guest Lecture by Srini DevadasDocument70 pagesVLSI CAD Flow: Logic Synthesis, Placement and Routing: Guest Lecture by Srini DevadasxperiaashNo ratings yet
- High LevelDocument29 pagesHigh LevelHemant SaraswatNo ratings yet
- High Level Synthesis - 02 - Basic ConceptsDocument27 pagesHigh Level Synthesis - 02 - Basic Conceptsa bNo ratings yet
- ECE545 Lecture 7 DataflowDocument59 pagesECE545 Lecture 7 Dataflowjoshiprashant14No ratings yet
- F9 FM FormulasDocument8 pagesF9 FM Formulas5561 ROSHAN K PATELNo ratings yet
- DS in C++ Tim BuddDocument24 pagesDS in C++ Tim BuddQuânNo ratings yet
- Unit II: Instruction Set and Addressing ModesDocument53 pagesUnit II: Instruction Set and Addressing ModesriyasekaranNo ratings yet
- Lecture 20Document11 pagesLecture 20Aviral UpadhyayNo ratings yet
- CMOS Transistor Theory: Thanks To Prof. David HarrisDocument29 pagesCMOS Transistor Theory: Thanks To Prof. David HarrisHarshdeep BhatiaNo ratings yet
- Chapter # 3: Multi-Level Combinational Logic: Contemporary Logic Design Contemporary Logic DesignDocument13 pagesChapter # 3: Multi-Level Combinational Logic: Contemporary Logic Design Contemporary Logic Designrtavares_980738No ratings yet
- A Goal Programming Model For Working Capital ManagementDocument4 pagesA Goal Programming Model For Working Capital ManagementBharatKathuriaNo ratings yet
- CSE304 - Design & Analysis of Algorithms: Articulation Points, Bridges & Biconnected ComponentsDocument19 pagesCSE304 - Design & Analysis of Algorithms: Articulation Points, Bridges & Biconnected ComponentsMonjurur shipuNo ratings yet
- Lecture 7Document80 pagesLecture 7Rüstem EleçNo ratings yet
- F9 ACCA Summary - Revision Notes 2017Document96 pagesF9 ACCA Summary - Revision Notes 2017alihihai113No ratings yet
- N098 - MM - Exp 2Document6 pagesN098 - MM - Exp 2Vedashree ShetyeNo ratings yet
- Solving Multiobjective Models With GAMSDocument19 pagesSolving Multiobjective Models With GAMSoida_adNo ratings yet
- Cse 323 Cse 42Document2 pagesCse 323 Cse 42rarafat4057No ratings yet
- Cubic Functions: Any Function of The FormDocument5 pagesCubic Functions: Any Function of The FormDave ToddNo ratings yet
- High-Level Synthesis: Hao Zheng Comp Sci & Eng University of South FloridaDocument26 pagesHigh-Level Synthesis: Hao Zheng Comp Sci & Eng University of South Floridamdumar umarNo ratings yet
- Kal 02Document17 pagesKal 02IisacGNo ratings yet
- Lecture 4 - Implementing Logic in CMOSDocument32 pagesLecture 4 - Implementing Logic in CMOSsadia santaNo ratings yet
- Tutorial 9 Defining Relation Resolution Design GeneratorDocument1 pageTutorial 9 Defining Relation Resolution Design GeneratorigeNo ratings yet
- 22sp-041-cs Lab3 CO&ALDocument8 pages22sp-041-cs Lab3 CO&ALSubul RazaNo ratings yet
- csc2001f 2024 7 Avl TreesDocument30 pagescsc2001f 2024 7 Avl TreeshmdprkrNo ratings yet
- B.Tech / It /3 SEM/ INFO 2101/2017 B.Tech / It /3 SEM/ INFO 2101/2017Document2 pagesB.Tech / It /3 SEM/ INFO 2101/2017 B.Tech / It /3 SEM/ INFO 2101/2017Vikash KumarNo ratings yet
- Applied Calculus Quiz 1 SolutionsDocument2 pagesApplied Calculus Quiz 1 SolutionsAndrew EwersNo ratings yet
- Drawing PDFDocument1 pageDrawing PDFSaraMuzaffarNo ratings yet
- Classification: Linear SVMDocument26 pagesClassification: Linear SVMLiamNo ratings yet
- Lecture10 Nosql PDFDocument80 pagesLecture10 Nosql PDFManisha_tNo ratings yet
- Stick DiagDocument6 pagesStick DiagSrinu BoddulaNo ratings yet
- L06 RISCV FunctionsDocument49 pagesL06 RISCV FunctionsTuấn LêNo ratings yet
- Introml 02 Regression Annotated PDFDocument26 pagesIntroml 02 Regression Annotated PDFMark NamNo ratings yet
- Conformal and BilinearDocument8 pagesConformal and BilinearSaddam HusainNo ratings yet
- Ap Calc Ab NotesDocument3 pagesAp Calc Ab NotesMiaNo ratings yet
- Mid Term 15,16 AnswerDocument13 pagesMid Term 15,16 AnswerSofwan JuewekNo ratings yet
- 2019 - Csen 4101Document2 pages2019 - Csen 4101poxemik697covbasecomNo ratings yet
- 2016 IT601 DBMS OldDocument3 pages2016 IT601 DBMS OldSUCHHANDA CHAKRABORTYNo ratings yet
- Indefinite & Definite Integration (XII)Document31 pagesIndefinite & Definite Integration (XII)prathmesh guptaNo ratings yet
- Discrete Structures: Wonsook Lee Wslee@Uottawa - Ca Eecs, Univ. of OttawaDocument34 pagesDiscrete Structures: Wonsook Lee Wslee@Uottawa - Ca Eecs, Univ. of OttawaIbrahim KanoucheNo ratings yet
- 05 Brute ForceDocument56 pages05 Brute ForcejojoNo ratings yet
- 99 09H Cal1-212 S09 E Improper ApplyDefP1Document20 pages99 09H Cal1-212 S09 E Improper ApplyDefP1Hoài Nguyễn Phan VũNo ratings yet
- 37 (COM 2) 2.3 2017 Operations Research and Computer in BusinessDocument7 pages37 (COM 2) 2.3 2017 Operations Research and Computer in BusinessSahu PraveenNo ratings yet
- Foundations of C++: Bjarne StroustrupDocument22 pagesFoundations of C++: Bjarne StroustrupcarluxNo ratings yet
- Cubic Functions - IBDP Mathematics - Applications and Interpretation SL FE2021 - KognityDocument6 pagesCubic Functions - IBDP Mathematics - Applications and Interpretation SL FE2021 - KognityMirjeta ZymeriNo ratings yet
- D/A Converters Continued:: - Component Matching - Systematic & Random ErrorsDocument31 pagesD/A Converters Continued:: - Component Matching - Systematic & Random ErrorsAvinash BadanikaiNo ratings yet
- 21529sm Finalnew Vol2 Cp10Document85 pages21529sm Finalnew Vol2 Cp10Ravi ReddyNo ratings yet
- Computational Techniques in Civil Engineering: 6. Method of Characteristics (MOC)Document5 pagesComputational Techniques in Civil Engineering: 6. Method of Characteristics (MOC)yeee boiiiNo ratings yet
- 9 - GraphsDocument61 pages9 - GraphsMai Cao Thị ThanhNo ratings yet
- Embedded Systems - 16CS402: Department of Computer Science and Engineering, Dayananda Sagar University, BengaluruDocument137 pagesEmbedded Systems - 16CS402: Department of Computer Science and Engineering, Dayananda Sagar University, BengaluruKiran KiruNo ratings yet
- Free Sample Test: Function Int N (For I 1 I N I++ For J 1 J N J J 2 PR Int F " GATE " )Document14 pagesFree Sample Test: Function Int N (For I 1 I N I++ For J 1 J N J J 2 PR Int F " GATE " )Kanchan jainNo ratings yet
- Omogen Heap: KTH Royal Institute of TechnologyDocument26 pagesOmogen Heap: KTH Royal Institute of TechnologyMuhammad NaufalNo ratings yet
- Formula Iitjee Integral-CalculusDocument17 pagesFormula Iitjee Integral-CalculusKshitij BahukhandiNo ratings yet
- Omogen Heap: KTH Royal Institute of TechnologyDocument25 pagesOmogen Heap: KTH Royal Institute of TechnologyArthom ZMinecraftNo ratings yet
- Ratio and Proportion Question With Solution Free PDF@WWW - Letsstudytogether.coDocument36 pagesRatio and Proportion Question With Solution Free PDF@WWW - Letsstudytogether.corahulrp3031No ratings yet
- Inside The Digital Gate: Circuits ElectronicsDocument20 pagesInside The Digital Gate: Circuits ElectronicsMitpdfNo ratings yet
- DigSysDes Fall2021 Lec18Document23 pagesDigSysDes Fall2021 Lec18Best of BestNo ratings yet
- 1 PBDocument9 pages1 PBAbdiel Perez RamosNo ratings yet
- Long (Buy) Positions Short (Sell) PositionsDocument8 pagesLong (Buy) Positions Short (Sell) PositionsTuan Nguyen MinhNo ratings yet
- Very Large Scale IntegrationDocument35 pagesVery Large Scale IntegrationShakeel EngyNo ratings yet
- Scheduling Algorithms For High-Level SynthesisDocument10 pagesScheduling Algorithms For High-Level SynthesisShakeel EngyNo ratings yet
- Guidelines For Report WritingDocument4 pagesGuidelines For Report WritingShakeel EngyNo ratings yet
- Mohammad Shakeel Ahmed: Carrier ObjectiveDocument3 pagesMohammad Shakeel Ahmed: Carrier ObjectiveShakeel EngyNo ratings yet
- Nr-r09 Modern Control TheoryDocument2 pagesNr-r09 Modern Control TheoryShakeel EngyNo ratings yet
- Nr-r09 Analysis of Power Electronic ConvertersDocument2 pagesNr-r09 Analysis of Power Electronic ConvertersShakeel EngyNo ratings yet
- Analysis and Design of Multi Storied Building by Using Etabs SoftwareDocument2 pagesAnalysis and Design of Multi Storied Building by Using Etabs SoftwareShakeel EngyNo ratings yet
- MicroDocument17 pagesMicroShakeel EngyNo ratings yet
- Project Guidelines Project Diary Project Report Format MeDocument20 pagesProject Guidelines Project Diary Project Report Format MeShakeel EngyNo ratings yet
- Project Guidelines Project Diary Project Report Format MeDocument20 pagesProject Guidelines Project Diary Project Report Format MeShakeel EngyNo ratings yet
- Message Control For InvoiceDocument7 pagesMessage Control For InvoiceJesse Townsend100% (1)
- 91 Computer ScienceDocument23 pages91 Computer ScienceAnkit ShawNo ratings yet
- Hi Tech c18 ManualDocument334 pagesHi Tech c18 ManualwizardgrtNo ratings yet
- EEX4465 - Data Structures and Algorithms 2020/2021: Tutor Marked Assignment - #2 Deadline OnDocument2 pagesEEX4465 - Data Structures and Algorithms 2020/2021: Tutor Marked Assignment - #2 Deadline OnNawam UdayangaNo ratings yet
- AISCIENCES - Data Science Cookbook - V0Document244 pagesAISCIENCES - Data Science Cookbook - V0KayNo ratings yet
- Constraint Satisfaction Problems: AIMA: Chapter 6Document64 pagesConstraint Satisfaction Problems: AIMA: Chapter 6Sunilkumar ReddyNo ratings yet
- Mainframe Refresher MuthuDocument47 pagesMainframe Refresher MuthumohanakrisnakNo ratings yet
- Synapseindia Dot Net Development - Programming OverviewDocument27 pagesSynapseindia Dot Net Development - Programming OverviewsynapseindiaappsdevelopmentNo ratings yet
- Systolic ArchitectureDocument2 pagesSystolic Architecturepoulomi santraNo ratings yet
- Installation: of SAP PI 7.5 and HigherDocument17 pagesInstallation: of SAP PI 7.5 and Higherhunter.correaNo ratings yet
- Zip Trees (Robert E. Tarjany Caleb C. Levyz)Document16 pagesZip Trees (Robert E. Tarjany Caleb C. Levyz)MEGUELLATI Fahd MustaphaNo ratings yet
- Java AssignmentDocument4 pagesJava AssignmentAndrew LassiaNo ratings yet
- Midterm 2011 SolutionDocument5 pagesMidterm 2011 Solutionisraa_melacaNo ratings yet
- FCP University Question PaperDocument11 pagesFCP University Question PaperjananiseNo ratings yet
- Overview of C++ Memory ManagementDocument19 pagesOverview of C++ Memory ManagementChamara JayalathNo ratings yet
- Design Facility Reference 4.1Document642 pagesDesign Facility Reference 4.1propmohamedNo ratings yet
- Term 1 CS Practical File 2021-22Document18 pagesTerm 1 CS Practical File 2021-22ranaNo ratings yet
- Slivers DemystifiedDocument14 pagesSlivers DemystifiedSanti LopezNo ratings yet
- Cembrano, Stephanie Rei Allana S. DICT 2-1 Quiz 1Document4 pagesCembrano, Stephanie Rei Allana S. DICT 2-1 Quiz 1Rei CembranoNo ratings yet
- OutputDocument86 pagesOutputSkydiver DortmundNo ratings yet
- Can't Follow Non-Constant Source. Use A Directive To Specify LocationDocument2 pagesCan't Follow Non-Constant Source. Use A Directive To Specify LocationPilar Rodriguez HijasNo ratings yet
- Delphi XE2 Foundations Part 2 Rolliston Chris PDFDocument174 pagesDelphi XE2 Foundations Part 2 Rolliston Chris PDFRadovan JaicNo ratings yet
- Unit IvDocument78 pagesUnit IvSudhakar SelvamNo ratings yet
- Operating System Concepts (Exercises and Answers) Part IIDocument7 pagesOperating System Concepts (Exercises and Answers) Part IIAlfred Fred100% (1)
- Worksheet 3.1Document20 pagesWorksheet 3.1Vatsal SharmaNo ratings yet
- TAW10 ABAP Workbench Fundamentals: Course GoalsDocument2 pagesTAW10 ABAP Workbench Fundamentals: Course GoalsUmeshNo ratings yet
- LogDocument84 pagesLoghi manNo ratings yet
- Antlr 4 Guide To Help U LearnDocument37 pagesAntlr 4 Guide To Help U LearnNaveen Kothapally KumarNo ratings yet