Download as pdf or txt
You might also like
- Probabilistyka - A. Plucińska, E. PlucińskiDocument230 pagesProbabilistyka - A. Plucińska, E. Plucińskitemp3579No ratings yet
- CAIE AS Level Computer Science 9618 Theory v1 Z-NotesDocument20 pagesCAIE AS Level Computer Science 9618 Theory v1 Z-NotesAnar NyambayarNo ratings yet
- UntitledDocument59 pagesUntitledSylvin GopayNo ratings yet
- Anatomy Coloring BookDocument171 pagesAnatomy Coloring BookIoana Pasca100% (1)
- 2nd Year Full Book Objectives MCQs NotesDocument45 pages2nd Year Full Book Objectives MCQs NotesnidaNo ratings yet
- Muthulakshmi M: Software Technical Trainer IBMDocument81 pagesMuthulakshmi M: Software Technical Trainer IBMNarenkumar. NNo ratings yet
- R InterviewDocument20 pagesR InterviewVishal ShahNo ratings yet
- STATS LAB Basics of R PDFDocument77 pagesSTATS LAB Basics of R PDFAnanthu SajithNo ratings yet
- Understanding Basic Data Types and Data Structures in RDocument10 pagesUnderstanding Basic Data Types and Data Structures in RNico MallNo ratings yet
- R Programming For NGS Data AnalysisDocument5 pagesR Programming For NGS Data AnalysisAbcdNo ratings yet
- Introduction To R: Nihan Acar-Denizli, Pau FonsecaDocument50 pagesIntroduction To R: Nihan Acar-Denizli, Pau FonsecaasaksjaksNo ratings yet
- R - Interview QuestionsDocument7 pagesR - Interview QuestionsRakshit VajaNo ratings yet
- 1 - Introduction To Programming With RDocument13 pages1 - Introduction To Programming With Rpaseg78960No ratings yet
- Introduction To R Installation: Data Types Value ExamplesDocument9 pagesIntroduction To R Installation: Data Types Value ExamplesDenis ShpekaNo ratings yet
- Presentation of RDocument109 pagesPresentation of RTomasBelenNo ratings yet
- An Introduction To R: Alessio FarcomeniDocument38 pagesAn Introduction To R: Alessio FarcomeniValerio ZarrelliNo ratings yet
- ALL-FAQ-R LanguageDocument161 pagesALL-FAQ-R LanguageUmamaheswaraRao PutrevuNo ratings yet
- Getting Started With RDocument155 pagesGetting Started With RsonucostaNo ratings yet
- DWDM - Lab Manual1Document40 pagesDWDM - Lab Manual1aathyukthas.ai20001No ratings yet
- Data Structures in R ProgrammingDocument8 pagesData Structures in R ProgrammingDivya PNo ratings yet
- A Report On R Name-Kaveena ROLL NO-12EE46Document10 pagesA Report On R Name-Kaveena ROLL NO-12EE46Rishabh JindalNo ratings yet
- What Is A Data Structure?: Data Structures in Data ScienceDocument24 pagesWhat Is A Data Structure?: Data Structures in Data ScienceMeghna ChoudharyNo ratings yet
- Data Anylysis UNIT 1Document25 pagesData Anylysis UNIT 1Shivaditya singhNo ratings yet
- Data Analytics Using RDocument27 pagesData Analytics Using Rviju001100% (1)
- Introduction To RDocument20 pagesIntroduction To Rseptian_bbyNo ratings yet
- Ba 340: Data Analytics: Understand How R Stores and Works With DataDocument62 pagesBa 340: Data Analytics: Understand How R Stores and Works With DataRania GoujaNo ratings yet
- Data in RDocument7 pagesData in RDhruv BhallaNo ratings yet
- An Introduction To R: 1 BackgroundDocument17 pagesAn Introduction To R: 1 BackgroundDeepak GuptaNo ratings yet
- R TutorialDocument25 pagesR Tutoriallamaram32No ratings yet
- Pfa QTN BankDocument74 pagesPfa QTN BankVignesh ShettyNo ratings yet
- Introduction To Data Science With R ProgrammingDocument91 pagesIntroduction To Data Science With R ProgrammingVimal KumarNo ratings yet
- R-Programming: To See The Working Directory in R StudioDocument17 pagesR-Programming: To See The Working Directory in R StudioNonameforeverNo ratings yet
- RIntroIntroduction To RDocument128 pagesRIntroIntroduction To RloxodromenNo ratings yet
- Data Analysis Using R and VectorsDocument35 pagesData Analysis Using R and VectorsRajat sainiNo ratings yet
- N2 Data in RDocument7 pagesN2 Data in RCooper BurrillNo ratings yet
- Statistics With R Programming For Bigdata (Autosaved)Document41 pagesStatistics With R Programming For Bigdata (Autosaved)rohithmahendran1305No ratings yet
- RBigData NTLDocument24 pagesRBigData NTLFRANK ALPHANo ratings yet
- Statistical Models Using RDocument6 pagesStatistical Models Using Rprimevideo09871234No ratings yet
- #Create Vector of Numeric Values #Display Class of VectorDocument10 pages#Create Vector of Numeric Values #Display Class of VectorAnooj SrivastavaNo ratings yet
- R Training Deck - v1Document35 pagesR Training Deck - v1Mrigendranath DebsarmaNo ratings yet
- Teaching Notes of RDocument78 pagesTeaching Notes of RamritaNo ratings yet
- Introduction To R: Pavan Kumar ADocument55 pagesIntroduction To R: Pavan Kumar Anaresh darapuNo ratings yet
- Basics of R Programming and Data Structures PDFDocument80 pagesBasics of R Programming and Data Structures PDFAsmatullah KhanNo ratings yet
- SM 38Document50 pagesSM 38ayushNo ratings yet
- Ahmed Rebai R-BasicsDocument33 pagesAhmed Rebai R-Basicsbejjanki.kumaraswamyNo ratings yet
- PW1 2Document20 pagesPW1 2Наталья ДолговаNo ratings yet
- R Programming Variables Datatypes Vectors Lists NotesDocument18 pagesR Programming Variables Datatypes Vectors Lists NotesRohini AravindanNo ratings yet
- Exploratory Data Analysis and Graphics: Lab 2Document19 pagesExploratory Data Analysis and Graphics: Lab 2juntujuntuNo ratings yet
- R ProgrammingDocument35 pagesR Programmingharshit rajNo ratings yet
- Bdo Co1 Session 4Document43 pagesBdo Co1 Session 4s.m.pasha0709No ratings yet
- R StudioDocument8 pagesR StudioBhargavaNandaNo ratings yet
- ECON 1100 R04 - R.Commands PDFDocument15 pagesECON 1100 R04 - R.Commands PDFAnthony MichaelNo ratings yet
- Lab Manual DARDocument81 pagesLab Manual DARHarry KunarNo ratings yet
- Lecture 7 - Integrated Analysis With RDocument79 pagesLecture 7 - Integrated Analysis With RAnurag LaddhaNo ratings yet
- LAB1Document12 pagesLAB1Mohan KishoreNo ratings yet
- 2 UndefinedDocument86 pages2 Undefinedjefoli1651No ratings yet
- 4 - DataTypes Vector Matrices OperatorsDocument33 pages4 - DataTypes Vector Matrices OperatorsAnurag SharmaNo ratings yet
- 1) Open Source: R AdvantagesDocument39 pages1) Open Source: R AdvantagesvineetkushwahNo ratings yet
- ATA Tructures In: Pavan Kumar ADocument35 pagesATA Tructures In: Pavan Kumar Anaresh darapuNo ratings yet
- R IntroductionDocument40 pagesR IntroductionSEbastian CardozoNo ratings yet
- Unit 2Document29 pagesUnit 2alblooshinoura66No ratings yet
- Capital GainsDocument8 pagesCapital Gainshariprasanna951No ratings yet
- Nonlinear TaxonomyDocument5 pagesNonlinear Taxonomymichel mboueNo ratings yet
- Introduction To R and L TEX For Institutional Research: Excelsior CollegeDocument123 pagesIntroduction To R and L TEX For Institutional Research: Excelsior Collegemichel mboueNo ratings yet
- Ecological - Time SeriesDocument4 pagesEcological - Time Seriesmichel mboueNo ratings yet
- Brambor Et Al Multipolicative Interactions (2016!12!11 23-51-45 UTC)Document20 pagesBrambor Et Al Multipolicative Interactions (2016!12!11 23-51-45 UTC)michel mboueNo ratings yet
- World Stats Pocketbook 2009Document251 pagesWorld Stats Pocketbook 2009michel mboueNo ratings yet
- World Stats Pocketbook 2006Document257 pagesWorld Stats Pocketbook 2006michel mboueNo ratings yet
- April 2020 Coronavirus Reference Scenario: Charts & TablesDocument38 pagesApril 2020 Coronavirus Reference Scenario: Charts & Tablesmichel mboueNo ratings yet
- Statistical Modeling: The Two Cultures: Leo BreimanDocument17 pagesStatistical Modeling: The Two Cultures: Leo Breimanmichel mboueNo ratings yet
- OBR Coronavirus Reference Scenario: Commentary On TheDocument23 pagesOBR Coronavirus Reference Scenario: Commentary On Themichel mboueNo ratings yet
- Briefing Note COVAX AMC Cost-SharingDocument3 pagesBriefing Note COVAX AMC Cost-Sharingmichel mboueNo ratings yet
- COVAX Supply ForecastDocument17 pagesCOVAX Supply Forecastmichel mboueNo ratings yet
- Global Economic Prospects: Middle East and North Africa: June 2020Document2 pagesGlobal Economic Prospects: Middle East and North Africa: June 2020michel mboueNo ratings yet
- Atmospheric CO - Mauna Loa Observatory - NOAA: Dataset SummaryDocument32 pagesAtmospheric CO - Mauna Loa Observatory - NOAA: Dataset Summarymichel mboueNo ratings yet
- U.S. Farm Income Outlook For 2018: Randy SchnepfDocument36 pagesU.S. Farm Income Outlook For 2018: Randy Schnepfmichel mboueNo ratings yet
- Africa S Coffee Sector Status Challenges and Opportunities For Growth PDFDocument78 pagesAfrica S Coffee Sector Status Challenges and Opportunities For Growth PDFmichel mboueNo ratings yet
- Mellor Lectures LDE7Document129 pagesMellor Lectures LDE7michel mboueNo ratings yet
- Real GDP: World Advanced EconomiesDocument27 pagesReal GDP: World Advanced Economiesmichel mboueNo ratings yet
- Past Climate, The Last 10,000 Years: Video TranscriptDocument2 pagesPast Climate, The Last 10,000 Years: Video Transcriptmichel mboueNo ratings yet
- Past Climate, The Last 2,000 YearsDocument2 pagesPast Climate, The Last 2,000 Yearsmichel mboueNo ratings yet
- Global Economic Prospects: South Asia: June 2020Document2 pagesGlobal Economic Prospects: South Asia: June 2020michel mboueNo ratings yet
- Global Economic Prospects: Sub-Saharan Africa: June 2020Document4 pagesGlobal Economic Prospects: Sub-Saharan Africa: June 2020michel mboueNo ratings yet
- laserDESK Software ManualDocument435 pageslaserDESK Software Manualesbarton1No ratings yet
- CG Unit 1.9Document136 pagesCG Unit 1.9Ethi Sathish DevNo ratings yet
- Computer Graphics1Document140 pagesComputer Graphics1dishanshu jagtapNo ratings yet
- CorelDRAW Graphics Suite 2019 PDFDocument20 pagesCorelDRAW Graphics Suite 2019 PDFHammad HassanNo ratings yet
- Una Larga Edad Media. Jacques Le Goff (Fragmento)Document60 pagesUna Larga Edad Media. Jacques Le Goff (Fragmento)Facundo Alvarez ConstantinNo ratings yet
- Q4 - M4 Store Technical Drawings and Equipment - Instruments FinalDocument23 pagesQ4 - M4 Store Technical Drawings and Equipment - Instruments FinalcadamariahNo ratings yet
- Manual VOSviewer 1.6.13Document53 pagesManual VOSviewer 1.6.13cristian sanchezNo ratings yet
- Programming With Visual Studio MFC and OpenglDocument25 pagesProgramming With Visual Studio MFC and OpenglAndre PdNo ratings yet
- CommandcommandDocument2 pagesCommandcommandRoger Carlos AlvaradoNo ratings yet
- 10 Corel Draw 12Document62 pages10 Corel Draw 12Cell PhoneNo ratings yet
- Create PDF With GO2PDF For Free, If You Wish To Remove This Line, Click Here To Buy Virtual PDF PrinterDocument50 pagesCreate PDF With GO2PDF For Free, If You Wish To Remove This Line, Click Here To Buy Virtual PDF Printerkrishnavenis9051No ratings yet
- Prosa de Estado y Estados de La Prosa-Marcelo CohenDocument8 pagesProsa de Estado y Estados de La Prosa-Marcelo CohenLauraNo ratings yet
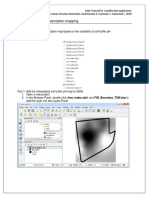
- Lime Prescription MappingDocument6 pagesLime Prescription MappingsostnivleNo ratings yet
- SFML ClasslistDocument3 pagesSFML ClasslistMeryll EssigNo ratings yet
- Design With Prints Laboratory Manual PraDocument26 pagesDesign With Prints Laboratory Manual PraTekWizard SRVNo ratings yet
- Precision AgricultureDocument245 pagesPrecision AgricultureMatheus Aragão100% (1)
- Help ScanNCutCanvas enDocument29 pagesHelp ScanNCutCanvas eng0youNo ratings yet
- Create Text Effects With Vectors: What You'll NeedDocument19 pagesCreate Text Effects With Vectors: What You'll NeedM Halvi SopianNo ratings yet
- IDRISI Selva Tutorial: January 2012 J. Ronald EastmanDocument354 pagesIDRISI Selva Tutorial: January 2012 J. Ronald EastmanAbimelet_Hern__1133No ratings yet
- Pencil2d Quick Guide PDFDocument2 pagesPencil2d Quick Guide PDFlilaNo ratings yet
- Estudio Exploratorio Sobre La Presencia de Sexismo en Una Universidad Colombiana - Vásquez-Puello PDFDocument9 pagesEstudio Exploratorio Sobre La Presencia de Sexismo en Una Universidad Colombiana - Vásquez-Puello PDFCielo Puello SarabiaNo ratings yet
- FocusDocument477 pagesFocusHades12 DotNo ratings yet
- Formulir Absen SilaseDocument3 pagesFormulir Absen SilaseJay Z100% (1)
- Fundamental Principles of Geographic Information Systems PDFDocument10 pagesFundamental Principles of Geographic Information Systems PDFAlina ManduNo ratings yet
- Cambridge International AS & A Level: Information Technology 9626/04Document8 pagesCambridge International AS & A Level: Information Technology 9626/04Kenneth Ekow InkumNo ratings yet
- Delcam - ArtCAM 2010 Insignia TrainingCourse EN - 2010Document134 pagesDelcam - ArtCAM 2010 Insignia TrainingCourse EN - 2010akaki leqvinadzeNo ratings yet