Download as pdf or txt
You might also like
- Forecasting Assignment 1Document3 pagesForecasting Assignment 1Sumit Kumar0% (1)
- Correlation and RegressionDocument16 pagesCorrelation and RegressionBonane AgnesNo ratings yet
- Correlation and RegressionDocument63 pagesCorrelation and RegressionFather JiggyNo ratings yet
- Simple Resgression SimpleDocument6 pagesSimple Resgression SimplebiggykhairNo ratings yet
- Corr and RegressDocument42 pagesCorr and Regresspasan lahiruNo ratings yet
- 12 Bivariate Data Analysis: Regression and Correlation MethodsDocument22 pages12 Bivariate Data Analysis: Regression and Correlation MethodsYash TripathiNo ratings yet
- Numerical RegressionDocument60 pagesNumerical RegressionJa HidNo ratings yet
- CH 9Document12 pagesCH 9Hayna tineNo ratings yet
- Correlation: We Take Two Measurements, of Two Different Physical Properties Are They Related?Document27 pagesCorrelation: We Take Two Measurements, of Two Different Physical Properties Are They Related?Jean RangelNo ratings yet
- 7 PearsonDocument9 pages7 PearsonAhmed GalalNo ratings yet
- FN 211 Self Test 4: Data Summary, Confidence Intervals, and Hypothesis TestingDocument10 pagesFN 211 Self Test 4: Data Summary, Confidence Intervals, and Hypothesis TestingRaiNz SeasonNo ratings yet
- Chapter Simple Linear Regression 1Document77 pagesChapter Simple Linear Regression 1Mobasher Messi100% (1)
- Correlation and RegressionDocument45 pagesCorrelation and RegressionPreethamgowda PreciousNo ratings yet
- Da 1Document2 pagesDa 1Shivani KulkarniNo ratings yet
- Corr and RegressDocument61 pagesCorr and Regresskamendra chauhanNo ratings yet
- CorrelationDocument52 pagesCorrelationasadNo ratings yet
- Business Statistics IIDocument100 pagesBusiness Statistics IIashishmanish100% (2)
- 1 - Linear RegressionDocument28 pages1 - Linear RegressionEmdad HossainNo ratings yet
- Regression ModelDocument26 pagesRegression ModelkhadarcabdiNo ratings yet
- Chapter 4 RegressionDocument38 pagesChapter 4 RegressionIvan NgNo ratings yet
- EconometricsDocument37 pagesEconometricslia hibiscusNo ratings yet
- Digital Assignment - IDocument2 pagesDigital Assignment - IR B SHARANNo ratings yet
- DISC 212 Session 13Document29 pagesDISC 212 Session 13Sneha KumariNo ratings yet
- Lecture 6 Simple Linear RegressionDocument36 pagesLecture 6 Simple Linear RegressionAshley Sophia GarciaNo ratings yet
- CH 2Document31 pagesCH 2Hama arasNo ratings yet
- CH 1Document7 pagesCH 1kenenisa AbdisaNo ratings yet
- BEC 440 Assignmnt 1Document4 pagesBEC 440 Assignmnt 1innocent mwansaNo ratings yet
- Regression: Dr. Agustinus Suryantoro, M.SDocument31 pagesRegression: Dr. Agustinus Suryantoro, M.SVikha Suryo KharismawanNo ratings yet
- Chapter Five: Regression and CorrelationDocument12 pagesChapter Five: Regression and Correlationጌታ እኮ ነውNo ratings yet
- Scatter Plot/Diagram Simple Linear Regression ModelDocument43 pagesScatter Plot/Diagram Simple Linear Regression ModelnooraNo ratings yet
- BC06-1 Bmas Topic-5 Linear Correlation and RegresssionDocument13 pagesBC06-1 Bmas Topic-5 Linear Correlation and Regresssionafatima paintingNo ratings yet
- Regression Analysis: Advanced Research MethadologyDocument44 pagesRegression Analysis: Advanced Research MethadologysohailNo ratings yet
- Regression: Building Experimental ModelsDocument47 pagesRegression: Building Experimental ModelsOnur KirpiciNo ratings yet
- Linear Regression: Major: All Engineering Majors Authors: Autar Kaw, Luke SnyderDocument33 pagesLinear Regression: Major: All Engineering Majors Authors: Autar Kaw, Luke SnyderPhoenix RizkyNo ratings yet
- CE304-Unit 5-Lect1-Jumah2018Document10 pagesCE304-Unit 5-Lect1-Jumah2018محمد بركاتNo ratings yet
- C R Assgt Solns v5Document6 pagesC R Assgt Solns v5Xin XinNo ratings yet
- SimpleLinearRegression PDFDocument86 pagesSimpleLinearRegression PDFkappi4uNo ratings yet
- Stat276 Chapter 7Document23 pagesStat276 Chapter 7Onetwothree TubeNo ratings yet
- VL2023240103477 DaDocument3 pagesVL2023240103477 Dadeanambrose5004No ratings yet
- Lecture - Correlation and Regression GEG 222Document67 pagesLecture - Correlation and Regression GEG 222Odunayo AjiboyeNo ratings yet
- Simple Regression Model: Conference PaperDocument10 pagesSimple Regression Model: Conference PaperVigneshwari MahamuniNo ratings yet
- Chapter Eight 8 Simple Linear Regression and Correlation: N XY X Y N X XDocument5 pagesChapter Eight 8 Simple Linear Regression and Correlation: N XY X Y N X XtaysirbestNo ratings yet
- pc11 Sol c04 4-1Document5 pagespc11 Sol c04 4-1cxzczxNo ratings yet
- Fai Module 3 PptDocument67 pagesFai Module 3 Pptsrakshitha936No ratings yet
- 03 Revisions L RegressionDocument25 pages03 Revisions L RegressionmehdiNo ratings yet
- Estad Istica II Chapter 4: Simple Linear RegressionDocument46 pagesEstad Istica II Chapter 4: Simple Linear RegressionJuanNo ratings yet
- Cha 6Document8 pagesCha 6Senay HaftuNo ratings yet
- Statistics QBDocument15 pagesStatistics QBKushbooNo ratings yet
- MathsDocument33 pagesMathsHoudaNo ratings yet
- DSJ BMS Unit3 16102020Document21 pagesDSJ BMS Unit3 16102020Parmeet KumarNo ratings yet
- Heteroscedasticity WorkshopDocument72 pagesHeteroscedasticity WorkshopHarishNo ratings yet
- NA-11Document15 pagesNA-11Ezgi GeyikNo ratings yet
- Unit 2-Part 3-Linear RegressionDocument38 pagesUnit 2-Part 3-Linear Regressionsasuke UchihaNo ratings yet
- Econ452: Problem Set 2: University of Michigan - Department of EconomicsDocument4 pagesEcon452: Problem Set 2: University of Michigan - Department of EconomicsWill MillerNo ratings yet
- 4-Linear Correlation & Regression LineDocument24 pages4-Linear Correlation & Regression LineZoya AhmadNo ratings yet
- Regression and FactorDocument95 pagesRegression and FactorSura C. JirNo ratings yet
- Stat 1Document6 pagesStat 1Reevu ThapaNo ratings yet
- Introduction To Management Science: Post Mid Sessions 2 & 3 November 4 and 6 2019Document26 pagesIntroduction To Management Science: Post Mid Sessions 2 & 3 November 4 and 6 2019Syed Zaki Ali AsgharNo ratings yet
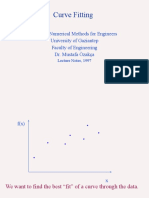
- Curve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaDocument171 pagesCurve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaAbdullah Emirhan AydınNo ratings yet
- Factoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)From EverandFactoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)No ratings yet
- Case Questions - Module 3Document4 pagesCase Questions - Module 3Lucas AalbersNo ratings yet
- Appendix A1 - Excel20101Document40 pagesAppendix A1 - Excel20101Lucas AalbersNo ratings yet
- TN - Topic 1 VBCDocument5 pagesTN - Topic 1 VBCLucas AalbersNo ratings yet
- Example 2 - No NameDocument8 pagesExample 2 - No NameLucas AalbersNo ratings yet
- Banker Et Al. (2000)Document29 pagesBanker Et Al. (2000)Lucas AalbersNo ratings yet
- RegionFly - Case DataDocument4 pagesRegionFly - Case DataLucas AalbersNo ratings yet
- Accounting, Organizations and Society: Sudipta Basu, Marcus Kirk, Greg WaymireDocument23 pagesAccounting, Organizations and Society: Sudipta Basu, Marcus Kirk, Greg WaymireLucas AalbersNo ratings yet
- Fuyao Glass - SummarizationDocument2 pagesFuyao Glass - SummarizationLucas AalbersNo ratings yet
- MBA - Full Time (Regular) - Regulation & Syllabus: Bharathiar University: Coimbatore-46Document59 pagesMBA - Full Time (Regular) - Regulation & Syllabus: Bharathiar University: Coimbatore-46RamkumarNo ratings yet
- Lesson 2 Discrete Probability DistributionsDocument11 pagesLesson 2 Discrete Probability DistributionsReign SaplacoNo ratings yet
- Efficient Epileptic Seizure Prediction Based On Deep LearningDocument10 pagesEfficient Epileptic Seizure Prediction Based On Deep LearningJoan Sebastian Betancourt AriasNo ratings yet
- Tutsheet 5Document2 pagesTutsheet 5vishnuNo ratings yet
- TA Hypothesis TestingDocument8 pagesTA Hypothesis TestingstudentofstudentNo ratings yet
- QB MAT311 Unit2 PDFDocument7 pagesQB MAT311 Unit2 PDFGroup 5 Product Launch100% (1)
- Two-Way Analysis of VarianceDocument25 pagesTwo-Way Analysis of Variancetarek moahmoud khalifaNo ratings yet
- Nonlinearity Between Ownership Concentration and Firm ValueDocument12 pagesNonlinearity Between Ownership Concentration and Firm ValueHanan RadityaNo ratings yet
- Problem SetDocument10 pagesProblem SetNissie AscoNo ratings yet
- Bba FT Business StatisticsDocument8 pagesBba FT Business StatisticsParashan CkNo ratings yet
- GPL Reference Guide For IBM SPSS StatisticsDocument363 pagesGPL Reference Guide For IBM SPSS Statisticspm_barnesNo ratings yet
- Sampling CLT CIDocument81 pagesSampling CLT CIariba shoukatNo ratings yet
- Table V Percentage Points T: Appendix ADocument1 pageTable V Percentage Points T: Appendix AAubrey LastimosaNo ratings yet
- Chapter 6: How To Do Forecasting by Regression AnalysisDocument7 pagesChapter 6: How To Do Forecasting by Regression AnalysisSarah Sally SarahNo ratings yet
- PDF Foundations and Applications of Statistics An Introduction Using R 2Nd Edition Randall Pruim Ebook Full ChapterDocument53 pagesPDF Foundations and Applications of Statistics An Introduction Using R 2Nd Edition Randall Pruim Ebook Full Chapterken.carone995100% (2)
- Geographic Information Systems and ScienceDocument18 pagesGeographic Information Systems and ScienceMirza CengicNo ratings yet
- Catalog10 11Document241 pagesCatalog10 11vsinisa1No ratings yet
- Engineering - Data - Quiz3 HandsonDocument3 pagesEngineering - Data - Quiz3 HandsonAce Heart Rosendo AmanteNo ratings yet
- Cloud Computing For CitiesDocument275 pagesCloud Computing For CitiesfaceruttiNo ratings yet
- A Study of Factors Affecting Purchase Intention of Young People Towards Smartphone BrandDocument49 pagesA Study of Factors Affecting Purchase Intention of Young People Towards Smartphone BrandNimasha100% (1)
- Cbse - Department of Skill Education: Artificial Intelligence (Subject Code 843)Document2 pagesCbse - Department of Skill Education: Artificial Intelligence (Subject Code 843)harshNo ratings yet
- Customer Relationship Management and Hospital ServiceDocument17 pagesCustomer Relationship Management and Hospital ServiceRina AnnisaNo ratings yet
- A Biomecânica e As Aplicações Dos Exercícios Do Strongman - Uma Revisão SistemáticaDocument19 pagesA Biomecânica e As Aplicações Dos Exercícios Do Strongman - Uma Revisão SistemáticaSheilani MartinsNo ratings yet
- Chapter 5Document37 pagesChapter 5Muhammd AzeemNo ratings yet
- Machine Learning Interview QuestionsDocument4 pagesMachine Learning Interview QuestionsAmandeep100% (1)
- 0syllabus Sep 2017 PDFDocument100 pages0syllabus Sep 2017 PDFMilan GoyalNo ratings yet
- Read Online Here: Resonance DPP SolutionsDocument3 pagesRead Online Here: Resonance DPP SolutionsRabi Kumar PatraNo ratings yet
- BL RSCH 2122 LEC 1922S Inquiries, Investigations and Immersion (VICTOR)Document11 pagesBL RSCH 2122 LEC 1922S Inquiries, Investigations and Immersion (VICTOR)reynaldNo ratings yet
- Dendro StatisticsDocument17 pagesDendro Statisticsapi-3825778No ratings yet