
Theory of Computation Solutions
Theory of Computation Solutions
You might also like
- Automata Computability and Complexity Theory and Applications 1st Edition Rich Solution ManualDocument20 pagesAutomata Computability and Complexity Theory and Applications 1st Edition Rich Solution ManualBasaprabhu Halakarnimath0% (5)
- HW2 Solutions 2017 SpringDocument10 pagesHW2 Solutions 2017 Springstephengogo1991No ratings yet
- Linz - Chapter 2 & 3 - Exer PDFDocument25 pagesLinz - Chapter 2 & 3 - Exer PDFنغم حمدونةNo ratings yet
- Practice Questions Set 7Document3 pagesPractice Questions Set 7ramNo ratings yet
- Solutions To Set 6Document8 pagesSolutions To Set 6jigneshsonkusare18No ratings yet
- Solutions To Set 17 - (Telegram @myhackersworld2)Document18 pagesSolutions To Set 17 - (Telegram @myhackersworld2)jigneshsonkusare18No ratings yet
- Solutions To Set 16 PDFDocument6 pagesSolutions To Set 16 PDFParth Ranjan JhaNo ratings yet
- Practice Question Set 3 PDFDocument4 pagesPractice Question Set 3 PDFParth Ranjan JhaNo ratings yet
- Practice Questions Set 6Document5 pagesPractice Questions Set 6Parth Ranjan JhaNo ratings yet
- TOC Imp QuestionsDocument8 pagesTOC Imp QuestionsAnudeep ronaldoNo ratings yet
- Theory of Computation SET-8: 1. Regular Expression For This DFADocument4 pagesTheory of Computation SET-8: 1. Regular Expression For This DFAekaansh sahniNo ratings yet
- Practice Questions Set 8Document4 pagesPractice Questions Set 8Parth Ranjan JhaNo ratings yet
- Practice Questions Set 2Document4 pagesPractice Questions Set 2Parth Ranjan JhaNo ratings yet
- Gate Objective Question Unit 1& 2Document10 pagesGate Objective Question Unit 1& 2helloNo ratings yet
- Practice Questions Set 4Document4 pagesPractice Questions Set 4Parth Ranjan JhaNo ratings yet
- Solutions To Set 13Document12 pagesSolutions To Set 13jigneshsonkusare18No ratings yet
- 18.solutions Set-1Document12 pages18.solutions Set-1Deepak SwamiNo ratings yet
- FinalDocument7 pagesFinalSujal SinghNo ratings yet
- Cs170 Sp2020 Mt2 Chiesa Nelson SolnDocument19 pagesCs170 Sp2020 Mt2 Chiesa Nelson SolnJohn PepeNo ratings yet
- Solutions To Set 10Document5 pagesSolutions To Set 10Parth Ranjan JhaNo ratings yet
- Sol 10Document2 pagesSol 10Rishab JainNo ratings yet
- Automata: Answer: CDocument22 pagesAutomata: Answer: CDevjeet RoyNo ratings yet
- cs170 Fa2018 mt1 Rao SolnDocument8 pagescs170 Fa2018 mt1 Rao SolnimsNo ratings yet
- CS-GATE - Solved PYQDocument38 pagesCS-GATE - Solved PYQsharavananNo ratings yet
- Theory of Computation GateDocument21 pagesTheory of Computation GateSushant BhargavNo ratings yet
- Automata Theory Problems and ExercisesDocument11 pagesAutomata Theory Problems and ExercisesKate Bayona50% (2)
- Catalan NumberDocument8 pagesCatalan Numberrajput0302No ratings yet
- Part I: Introduction 1 Why Study Automata Theory? 2 Languages and StringsDocument22 pagesPart I: Introduction 1 Why Study Automata Theory? 2 Languages and StringsMunirul FSNo ratings yet
- This Study Resource Was: CSE396 Final Exam Answer Key Spring 2016Document8 pagesThis Study Resource Was: CSE396 Final Exam Answer Key Spring 2016Zhihao LinNo ratings yet
- Context-Free and Noncontext-Free LanguagesDocument36 pagesContext-Free and Noncontext-Free LanguagesRaj SharmaNo ratings yet
- Theory of Computation MCQsDocument40 pagesTheory of Computation MCQsJitender Sharma85% (27)
- 543374692csen 3102Document4 pages543374692csen 3102shashank kumarNo ratings yet
- Functional Analysis - Manfred Einsiedler - Exercises Sheets - 2014 - Zurih - ETH PDFDocument55 pagesFunctional Analysis - Manfred Einsiedler - Exercises Sheets - 2014 - Zurih - ETH PDFaqszaqszNo ratings yet
- AutomataqueationDocument115 pagesAutomataqueationGetachew EnyewNo ratings yet
- Question Bank: Unit 1: Introduction To Finite AutomataDocument8 pagesQuestion Bank: Unit 1: Introduction To Finite AutomataBhavani PaturiNo ratings yet
- Cat1 Model1Document2 pagesCat1 Model1saiNo ratings yet
- CS 341 Homework 16 Languages That Are and Are Not Context-FreeDocument5 pagesCS 341 Homework 16 Languages That Are and Are Not Context-FreeVivek GudeNo ratings yet
- Answers: The University of NottinghamDocument20 pagesAnswers: The University of NottinghamGoldFactsNo ratings yet
- 15 1Document3 pages15 1Aditya MishraNo ratings yet
- Btech Cs 4 Sem Theory of Automata and Formal Languages ncs402 2018Document2 pagesBtech Cs 4 Sem Theory of Automata and Formal Languages ncs402 2018ATUL KUMAR YADAVNo ratings yet
- Pgcs2020 SolutionsDocument13 pagesPgcs2020 Solutionsfocusonaims11tNo ratings yet
- Hw2sol PDFDocument7 pagesHw2sol PDFSaa-dia BatoolNo ratings yet
- Isi 2012-15Document10 pagesIsi 2012-15Stephan ReynoldsNo ratings yet
- Practice Questions Set 13 PDFDocument4 pagesPractice Questions Set 13 PDFParth Ranjan JhaNo ratings yet
- CS6503 Theory of Computations Unit 2Document47 pagesCS6503 Theory of Computations Unit 2dgk84_id67% (3)
- B.Stat. (Hons.) & B.Math. (Hons.) Admission Test: 2012Document9 pagesB.Stat. (Hons.) & B.Math. (Hons.) Admission Test: 2012kishoreNo ratings yet
- SOLUTIONS: Homework Assignment 2: CSCI 2670 Introduction To Theory of Computing, Fall 2018 September 18, 2018Document8 pagesSOLUTIONS: Homework Assignment 2: CSCI 2670 Introduction To Theory of Computing, Fall 2018 September 18, 2018Orijit NandyNo ratings yet
- Combinatorics Course Week 4: 1 In-Class ProblemsDocument4 pagesCombinatorics Course Week 4: 1 In-Class ProblemsLouis JamesNo ratings yet
- Rich Automata SolnsDocument196 pagesRich Automata SolnsAshaNo ratings yet
- Toc MCQDocument1,103 pagesToc MCQAshutosh DeshmukhNo ratings yet
- Types of Algorithms Solutions: 1. Which of The Following Algorithms Is NOT A Divide & Conquer Algorithm by Nature?Document8 pagesTypes of Algorithms Solutions: 1. Which of The Following Algorithms Is NOT A Divide & Conquer Algorithm by Nature?ergrehgeNo ratings yet
- Rich Automata SolnsDocument187 pagesRich Automata SolnsEdmundLuong100% (6)
- Analysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For NDocument6 pagesAnalysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For Nsweta sharmaNo ratings yet
- Analysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For NDocument6 pagesAnalysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For NergrehgeNo ratings yet
- Functional Operators (AM-22), Volume 2: The Geometry of Orthogonal Spaces. (AM-22)From EverandFunctional Operators (AM-22), Volume 2: The Geometry of Orthogonal Spaces. (AM-22)No ratings yet
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)From EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)No ratings yet
- Ekaansh ResumeDocument1 pageEkaansh Resumeekaansh sahniNo ratings yet
- What Is The Problem?Document3 pagesWhat Is The Problem?ekaansh sahni100% (1)
- Theory of Computation SET-8: 1. Regular Expression For This DFADocument4 pagesTheory of Computation SET-8: 1. Regular Expression For This DFAekaansh sahniNo ratings yet
- Beam-TheoryDocument12 pagesBeam-Theoryekaansh sahniNo ratings yet
- Arabic MS PDFDocument3 pagesArabic MS PDFJayesh ChandNo ratings yet
- Gerubd Vs InfinitveDocument3 pagesGerubd Vs InfinitvejanetNo ratings yet
- 116 Present-Perfect US StudentDocument13 pages116 Present-Perfect US StudentFiorella DininiNo ratings yet
- Technical Writing and English ReinforcementDocument13 pagesTechnical Writing and English ReinforcementBianca36W478435No ratings yet
- Homework Reported QuestionsDocument4 pagesHomework Reported Questionsbettermexoxo4No ratings yet
- Mini-Mental State Examination (MMSE) : K PSTDocument2 pagesMini-Mental State Examination (MMSE) : K PSTMajesty ParkerNo ratings yet
- First Term Exam 2ASDocument5 pagesFirst Term Exam 2ASአቸጸ ለከጀNo ratings yet
- Thesis On Error Analysis by Rebat DhakalDocument78 pagesThesis On Error Analysis by Rebat Dhakalrebat85% (20)
- What's The Secret To A Good ConversationDocument4 pagesWhat's The Secret To A Good ConversationmaloNo ratings yet
- Word Power Made Easy Capsule 69 PDFDocument4 pagesWord Power Made Easy Capsule 69 PDFviraajNo ratings yet
- Past Simple (I Worked)Document4 pagesPast Simple (I Worked)irmathesweetNo ratings yet
- UNIT 6 - That's EntertainmentDocument24 pagesUNIT 6 - That's EntertainmentCarlos Arturo Ortiz BalagueraNo ratings yet
- Features of Academic TextsDocument48 pagesFeatures of Academic TextsQueen BalduezaNo ratings yet
- French Secrets RevealedDocument4 pagesFrench Secrets RevealedChandaKundaNo ratings yet
- Grammar 2.Class3.Group9.Topic - Five Syntactic Functions of Subordinate Clauses in Charles Dickens' Short Stories - Leader - Phùng Thanh VânDocument16 pagesGrammar 2.Class3.Group9.Topic - Five Syntactic Functions of Subordinate Clauses in Charles Dickens' Short Stories - Leader - Phùng Thanh VânVân ThanhNo ratings yet
- Form 1 Assignment 1 26.6.2020Document3 pagesForm 1 Assignment 1 26.6.2020Qhairunisa HinsanNo ratings yet
- Punctuation Pattern SheetDocument2 pagesPunctuation Pattern SheetFuller Writing Center0% (1)
- Entry Checker BookletDocument24 pagesEntry Checker BookletEulalia Alvarez Gallardo0% (1)
- English GrammarDocument44 pagesEnglish GrammarAnonymous 5JP7Gjd41pNo ratings yet
- Academic Style  Exercise With Tips KopyasıDocument4 pagesAcademic Style  Exercise With Tips KopyasıSELIN AKAYNo ratings yet
- Reflexive Pronouns Lesson PlanDocument2 pagesReflexive Pronouns Lesson PlanLamia AmmedlousNo ratings yet
- 4th 5th Grade ClassroomDocument2 pages4th 5th Grade ClassroomValley Christian SchoolNo ratings yet
- Dooge - Easy Latin For SightreadingDocument170 pagesDooge - Easy Latin For SightreadingLucius AnneusNo ratings yet
- Equivalence in TranslationDocument10 pagesEquivalence in TranslationNalin HettiarachchiNo ratings yet
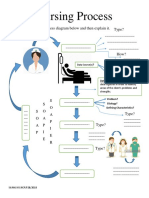
- Nursing Process: Complete The Nursing Process Diagram Below and Then Explain It. Type?Document2 pagesNursing Process: Complete The Nursing Process Diagram Below and Then Explain It. Type?Naufal AlbabNo ratings yet
- With Time ExpressionsDocument7 pagesWith Time ExpressionsMartaNo ratings yet
- Position PrepositionsDocument9 pagesPosition PrepositionsNarasinga Rao BarnikanaNo ratings yet
- Lyra Chapter 5-7Document81 pagesLyra Chapter 5-7Feed Back ParNo ratings yet
- Top-Down ParsingDocument10 pagesTop-Down Parsing319126510033 LAKAREDDY MADHU VANINo ratings yet
- Daftar Lengkap Irregular Verb Beserta ArtinyaDocument32 pagesDaftar Lengkap Irregular Verb Beserta ArtinyaAri WijayantiNo ratings yet














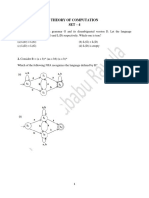













































































Download as pdf or txt
You might also like
- Automata Computability and Complexity Theory and Applications 1st Edition Rich Solution ManualDocument20 pagesAutomata Computability and Complexity Theory and Applications 1st Edition Rich Solution ManualBasaprabhu Halakarnimath0% (5)
- HW2 Solutions 2017 SpringDocument10 pagesHW2 Solutions 2017 Springstephengogo1991No ratings yet
- Linz - Chapter 2 & 3 - Exer PDFDocument25 pagesLinz - Chapter 2 & 3 - Exer PDFنغم حمدونةNo ratings yet
- Practice Questions Set 7Document3 pagesPractice Questions Set 7ramNo ratings yet
- Solutions To Set 6Document8 pagesSolutions To Set 6jigneshsonkusare18No ratings yet
- Solutions To Set 17 - (Telegram @myhackersworld2)Document18 pagesSolutions To Set 17 - (Telegram @myhackersworld2)jigneshsonkusare18No ratings yet
- Solutions To Set 16 PDFDocument6 pagesSolutions To Set 16 PDFParth Ranjan JhaNo ratings yet
- Practice Question Set 3 PDFDocument4 pagesPractice Question Set 3 PDFParth Ranjan JhaNo ratings yet
- Practice Questions Set 6Document5 pagesPractice Questions Set 6Parth Ranjan JhaNo ratings yet
- TOC Imp QuestionsDocument8 pagesTOC Imp QuestionsAnudeep ronaldoNo ratings yet
- Theory of Computation SET-8: 1. Regular Expression For This DFADocument4 pagesTheory of Computation SET-8: 1. Regular Expression For This DFAekaansh sahniNo ratings yet
- Practice Questions Set 8Document4 pagesPractice Questions Set 8Parth Ranjan JhaNo ratings yet
- Practice Questions Set 2Document4 pagesPractice Questions Set 2Parth Ranjan JhaNo ratings yet
- Gate Objective Question Unit 1& 2Document10 pagesGate Objective Question Unit 1& 2helloNo ratings yet
- Practice Questions Set 4Document4 pagesPractice Questions Set 4Parth Ranjan JhaNo ratings yet
- Solutions To Set 13Document12 pagesSolutions To Set 13jigneshsonkusare18No ratings yet
- 18.solutions Set-1Document12 pages18.solutions Set-1Deepak SwamiNo ratings yet
- FinalDocument7 pagesFinalSujal SinghNo ratings yet
- Cs170 Sp2020 Mt2 Chiesa Nelson SolnDocument19 pagesCs170 Sp2020 Mt2 Chiesa Nelson SolnJohn PepeNo ratings yet
- Solutions To Set 10Document5 pagesSolutions To Set 10Parth Ranjan JhaNo ratings yet
- Sol 10Document2 pagesSol 10Rishab JainNo ratings yet
- Automata: Answer: CDocument22 pagesAutomata: Answer: CDevjeet RoyNo ratings yet
- cs170 Fa2018 mt1 Rao SolnDocument8 pagescs170 Fa2018 mt1 Rao SolnimsNo ratings yet
- CS-GATE - Solved PYQDocument38 pagesCS-GATE - Solved PYQsharavananNo ratings yet
- Theory of Computation GateDocument21 pagesTheory of Computation GateSushant BhargavNo ratings yet
- Automata Theory Problems and ExercisesDocument11 pagesAutomata Theory Problems and ExercisesKate Bayona50% (2)
- Catalan NumberDocument8 pagesCatalan Numberrajput0302No ratings yet
- Part I: Introduction 1 Why Study Automata Theory? 2 Languages and StringsDocument22 pagesPart I: Introduction 1 Why Study Automata Theory? 2 Languages and StringsMunirul FSNo ratings yet
- This Study Resource Was: CSE396 Final Exam Answer Key Spring 2016Document8 pagesThis Study Resource Was: CSE396 Final Exam Answer Key Spring 2016Zhihao LinNo ratings yet
- Context-Free and Noncontext-Free LanguagesDocument36 pagesContext-Free and Noncontext-Free LanguagesRaj SharmaNo ratings yet
- Theory of Computation MCQsDocument40 pagesTheory of Computation MCQsJitender Sharma85% (27)
- 543374692csen 3102Document4 pages543374692csen 3102shashank kumarNo ratings yet
- Functional Analysis - Manfred Einsiedler - Exercises Sheets - 2014 - Zurih - ETH PDFDocument55 pagesFunctional Analysis - Manfred Einsiedler - Exercises Sheets - 2014 - Zurih - ETH PDFaqszaqszNo ratings yet
- AutomataqueationDocument115 pagesAutomataqueationGetachew EnyewNo ratings yet
- Question Bank: Unit 1: Introduction To Finite AutomataDocument8 pagesQuestion Bank: Unit 1: Introduction To Finite AutomataBhavani PaturiNo ratings yet
- Cat1 Model1Document2 pagesCat1 Model1saiNo ratings yet
- CS 341 Homework 16 Languages That Are and Are Not Context-FreeDocument5 pagesCS 341 Homework 16 Languages That Are and Are Not Context-FreeVivek GudeNo ratings yet
- Answers: The University of NottinghamDocument20 pagesAnswers: The University of NottinghamGoldFactsNo ratings yet
- 15 1Document3 pages15 1Aditya MishraNo ratings yet
- Btech Cs 4 Sem Theory of Automata and Formal Languages ncs402 2018Document2 pagesBtech Cs 4 Sem Theory of Automata and Formal Languages ncs402 2018ATUL KUMAR YADAVNo ratings yet
- Pgcs2020 SolutionsDocument13 pagesPgcs2020 Solutionsfocusonaims11tNo ratings yet
- Hw2sol PDFDocument7 pagesHw2sol PDFSaa-dia BatoolNo ratings yet
- Isi 2012-15Document10 pagesIsi 2012-15Stephan ReynoldsNo ratings yet
- Practice Questions Set 13 PDFDocument4 pagesPractice Questions Set 13 PDFParth Ranjan JhaNo ratings yet
- CS6503 Theory of Computations Unit 2Document47 pagesCS6503 Theory of Computations Unit 2dgk84_id67% (3)
- B.Stat. (Hons.) & B.Math. (Hons.) Admission Test: 2012Document9 pagesB.Stat. (Hons.) & B.Math. (Hons.) Admission Test: 2012kishoreNo ratings yet
- SOLUTIONS: Homework Assignment 2: CSCI 2670 Introduction To Theory of Computing, Fall 2018 September 18, 2018Document8 pagesSOLUTIONS: Homework Assignment 2: CSCI 2670 Introduction To Theory of Computing, Fall 2018 September 18, 2018Orijit NandyNo ratings yet
- Combinatorics Course Week 4: 1 In-Class ProblemsDocument4 pagesCombinatorics Course Week 4: 1 In-Class ProblemsLouis JamesNo ratings yet
- Rich Automata SolnsDocument196 pagesRich Automata SolnsAshaNo ratings yet
- Toc MCQDocument1,103 pagesToc MCQAshutosh DeshmukhNo ratings yet
- Types of Algorithms Solutions: 1. Which of The Following Algorithms Is NOT A Divide & Conquer Algorithm by Nature?Document8 pagesTypes of Algorithms Solutions: 1. Which of The Following Algorithms Is NOT A Divide & Conquer Algorithm by Nature?ergrehgeNo ratings yet
- Rich Automata SolnsDocument187 pagesRich Automata SolnsEdmundLuong100% (6)
- Analysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For NDocument6 pagesAnalysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For Nsweta sharmaNo ratings yet
- Analysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For NDocument6 pagesAnalysis of Algorithm Types of Algorithm Solutions: 1. If T (N) 2T (n/2) + Log N, For NergrehgeNo ratings yet
- Functional Operators (AM-22), Volume 2: The Geometry of Orthogonal Spaces. (AM-22)From EverandFunctional Operators (AM-22), Volume 2: The Geometry of Orthogonal Spaces. (AM-22)No ratings yet
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)From EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)No ratings yet
- Ekaansh ResumeDocument1 pageEkaansh Resumeekaansh sahniNo ratings yet
- What Is The Problem?Document3 pagesWhat Is The Problem?ekaansh sahni100% (1)
- Theory of Computation SET-8: 1. Regular Expression For This DFADocument4 pagesTheory of Computation SET-8: 1. Regular Expression For This DFAekaansh sahniNo ratings yet
- Beam-TheoryDocument12 pagesBeam-Theoryekaansh sahniNo ratings yet
- Arabic MS PDFDocument3 pagesArabic MS PDFJayesh ChandNo ratings yet
- Gerubd Vs InfinitveDocument3 pagesGerubd Vs InfinitvejanetNo ratings yet
- 116 Present-Perfect US StudentDocument13 pages116 Present-Perfect US StudentFiorella DininiNo ratings yet
- Technical Writing and English ReinforcementDocument13 pagesTechnical Writing and English ReinforcementBianca36W478435No ratings yet
- Homework Reported QuestionsDocument4 pagesHomework Reported Questionsbettermexoxo4No ratings yet
- Mini-Mental State Examination (MMSE) : K PSTDocument2 pagesMini-Mental State Examination (MMSE) : K PSTMajesty ParkerNo ratings yet
- First Term Exam 2ASDocument5 pagesFirst Term Exam 2ASአቸጸ ለከጀNo ratings yet
- Thesis On Error Analysis by Rebat DhakalDocument78 pagesThesis On Error Analysis by Rebat Dhakalrebat85% (20)
- What's The Secret To A Good ConversationDocument4 pagesWhat's The Secret To A Good ConversationmaloNo ratings yet
- Word Power Made Easy Capsule 69 PDFDocument4 pagesWord Power Made Easy Capsule 69 PDFviraajNo ratings yet
- Past Simple (I Worked)Document4 pagesPast Simple (I Worked)irmathesweetNo ratings yet
- UNIT 6 - That's EntertainmentDocument24 pagesUNIT 6 - That's EntertainmentCarlos Arturo Ortiz BalagueraNo ratings yet
- Features of Academic TextsDocument48 pagesFeatures of Academic TextsQueen BalduezaNo ratings yet
- French Secrets RevealedDocument4 pagesFrench Secrets RevealedChandaKundaNo ratings yet
- Grammar 2.Class3.Group9.Topic - Five Syntactic Functions of Subordinate Clauses in Charles Dickens' Short Stories - Leader - Phùng Thanh VânDocument16 pagesGrammar 2.Class3.Group9.Topic - Five Syntactic Functions of Subordinate Clauses in Charles Dickens' Short Stories - Leader - Phùng Thanh VânVân ThanhNo ratings yet
- Form 1 Assignment 1 26.6.2020Document3 pagesForm 1 Assignment 1 26.6.2020Qhairunisa HinsanNo ratings yet
- Punctuation Pattern SheetDocument2 pagesPunctuation Pattern SheetFuller Writing Center0% (1)
- Entry Checker BookletDocument24 pagesEntry Checker BookletEulalia Alvarez Gallardo0% (1)
- English GrammarDocument44 pagesEnglish GrammarAnonymous 5JP7Gjd41pNo ratings yet
- Academic Style  Exercise With Tips KopyasıDocument4 pagesAcademic Style  Exercise With Tips KopyasıSELIN AKAYNo ratings yet
- Reflexive Pronouns Lesson PlanDocument2 pagesReflexive Pronouns Lesson PlanLamia AmmedlousNo ratings yet
- 4th 5th Grade ClassroomDocument2 pages4th 5th Grade ClassroomValley Christian SchoolNo ratings yet
- Dooge - Easy Latin For SightreadingDocument170 pagesDooge - Easy Latin For SightreadingLucius AnneusNo ratings yet
- Equivalence in TranslationDocument10 pagesEquivalence in TranslationNalin HettiarachchiNo ratings yet
- Nursing Process: Complete The Nursing Process Diagram Below and Then Explain It. Type?Document2 pagesNursing Process: Complete The Nursing Process Diagram Below and Then Explain It. Type?Naufal AlbabNo ratings yet
- With Time ExpressionsDocument7 pagesWith Time ExpressionsMartaNo ratings yet
- Position PrepositionsDocument9 pagesPosition PrepositionsNarasinga Rao BarnikanaNo ratings yet
- Lyra Chapter 5-7Document81 pagesLyra Chapter 5-7Feed Back ParNo ratings yet
- Top-Down ParsingDocument10 pagesTop-Down Parsing319126510033 LAKAREDDY MADHU VANINo ratings yet
- Daftar Lengkap Irregular Verb Beserta ArtinyaDocument32 pagesDaftar Lengkap Irregular Verb Beserta ArtinyaAri WijayantiNo ratings yet