Download as pdf or txt
You might also like
- Cromwell Center Replacement Feasibility StudyDocument18 pagesCromwell Center Replacement Feasibility StudyDNAinfoNewYork100% (1)
- LargeGANS PDFDocument29 pagesLargeGANS PDFdhiraj madanNo ratings yet
- From Adversarial Training To Geenerative Adversarial NetworksDocument12 pagesFrom Adversarial Training To Geenerative Adversarial NetworksBhbjnnNo ratings yet
- L S Gan T H F N I S: Arge Cale Raining For IGH Idelity Atural Mage YnthesisDocument35 pagesL S Gan T H F N I S: Arge Cale Raining For IGH Idelity Atural Mage YnthesisNguyễn ViệtNo ratings yet
- GANModeCollapse Metz PDFDocument25 pagesGANModeCollapse Metz PDFJean-Pierre CoffeNo ratings yet
- Improved Techniques For Training Gans: (G) Data (G)Document10 pagesImproved Techniques For Training Gans: (G) Data (G)Raghavendra ShettyNo ratings yet
- Spectral Normalization For GANsDocument26 pagesSpectral Normalization For GANsYasuru ThiwankaNo ratings yet
- cGAN For Convolutional Face GenerationDocument9 pagescGAN For Convolutional Face GenerationThuan NguyenNo ratings yet
- 481 Generative Latent FlowDocument20 pages481 Generative Latent FlowOussama YousreNo ratings yet
- SeqGAN: Sequence Generative Adversarial Nets With Policy GradientDocument10 pagesSeqGAN: Sequence Generative Adversarial Nets With Policy GradientwwfwpifpiefNo ratings yet
- Generative Adversarial Nets:Optimizations and Functioning: MotivationDocument5 pagesGenerative Adversarial Nets:Optimizations and Functioning: MotivationShiv SJNo ratings yet
- GAN Project ReportDocument13 pagesGAN Project Reportfatima ait oubereNo ratings yet
- Evolutionary Generative Adversarial NetworksDocument14 pagesEvolutionary Generative Adversarial NetworksSahilKumarNo ratings yet
- 4385-Article Text-7424-1-10-20190706Document8 pages4385-Article Text-7424-1-10-20190706idrisscarlosid1No ratings yet
- Realistic Face Image Generation Based On Generative Adversarial NetworkDocument4 pagesRealistic Face Image Generation Based On Generative Adversarial NetworkRaghavendra ShettyNo ratings yet
- Seqgan: Sequence Generative Adversarial Nets With Policy GradientDocument10 pagesSeqgan: Sequence Generative Adversarial Nets With Policy GradientJustin San JuanNo ratings yet
- Generalized Regression With Conditional GansDocument9 pagesGeneralized Regression With Conditional Gans664682899No ratings yet
- Regularization Methods For Generative Adversarial Networks: An Overview of Recent StudiesDocument18 pagesRegularization Methods For Generative Adversarial Networks: An Overview of Recent StudiesSasan KNo ratings yet
- L19 GANsDocument9 pagesL19 GANsziliang.miao26No ratings yet
- Text Generation With Gan Networks Using Feedback ScoreDocument14 pagesText Generation With Gan Networks Using Feedback ScoreJames MorenoNo ratings yet
- Paper 14Document3 pagesPaper 14RimNo ratings yet
- On Convergence and Stability of GansDocument18 pagesOn Convergence and Stability of GansThuan NguyenNo ratings yet
- GNN グラフの構造推定問題Document10 pagesGNN グラフの構造推定問題TelockNo ratings yet
- B - S G A N: Oundary Eeking Enerative Dversarial EtworksDocument17 pagesB - S G A N: Oundary Eeking Enerative Dversarial EtworksHuWalterNo ratings yet
- 4823-Article Text-7889-1-10-20190709Document9 pages4823-Article Text-7889-1-10-20190709Binay AdhikariNo ratings yet
- Reviewon Generative Adversarial NetworksDocument6 pagesReviewon Generative Adversarial Networkskepemaf305No ratings yet
- Child Face Generation With Deep Conditional Generative Adversarial NetworksDocument7 pagesChild Face Generation With Deep Conditional Generative Adversarial NetworksHlophe Nathoe NkosinathiNo ratings yet
- Attributing and Detecting Fake Images Generated by Known GANsDocument7 pagesAttributing and Detecting Fake Images Generated by Known GANsTín Hào KhổngNo ratings yet
- Bayesian GAN: 31st Conference On Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USADocument16 pagesBayesian GAN: 31st Conference On Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USAJakub Wojciech WisniewskiNo ratings yet
- Data Augmentation GanDocument14 pagesData Augmentation GanSanjeev KumarNo ratings yet
- Generative Adversarial Networks For Text Using Word2vec IntermediariesDocument12 pagesGenerative Adversarial Networks For Text Using Word2vec IntermediariesJaspreetSinghNo ratings yet
- Yinka-Banjo-Ugot2020 Article AReviewOfGenerativeAdversarialDocument16 pagesYinka-Banjo-Ugot2020 Article AReviewOfGenerativeAdversarialsoheilesm456No ratings yet
- GANVizDocument13 pagesGANVizDanish VasdevNo ratings yet
- Generative Adversarial Learning For Robust Text Classification With A Bunch of Labeled ExamplesDocument6 pagesGenerative Adversarial Learning For Robust Text Classification With A Bunch of Labeled ExamplesLarissa FelicianaNo ratings yet
- D GAN ? S T E: O S Learn The Distribution OME Heory AND MpiricsDocument16 pagesD GAN ? S T E: O S Learn The Distribution OME Heory AND MpiricsJean-Pierre CoffeNo ratings yet
- Evolutionary Generative Adversarial NetworksDocument14 pagesEvolutionary Generative Adversarial NetworksHannan GharadeNo ratings yet
- Analog Bits: Generating Discrete Data Using Diffusion Models With Self-ConditioningDocument23 pagesAnalog Bits: Generating Discrete Data Using Diffusion Models With Self-ConditioningDgjnNo ratings yet
- $isprs Annals IV 2 W7 167 2019Document7 pages$isprs Annals IV 2 W7 167 2019esmail ahmedNo ratings yet
- Stabilizing Training of Generative Adversarial Networks Through RegularizationDocument16 pagesStabilizing Training of Generative Adversarial Networks Through RegularizationArif BachtiarNo ratings yet
- Fitee 1700786 PDFDocument10 pagesFitee 1700786 PDFPeppeNo ratings yet
- Image Colorization Using Generative Adversarial NetworksDocument11 pagesImage Colorization Using Generative Adversarial Networksliun71743No ratings yet
- LeNgiCoaLahProNg11 PDFDocument8 pagesLeNgiCoaLahProNg11 PDFJorge LeandroNo ratings yet
- Generative Adversarial Networks For Data Generation and Damage Detection Using Resnet in Structural Health MonitoringDocument25 pagesGenerative Adversarial Networks For Data Generation and Damage Detection Using Resnet in Structural Health MonitoringBhavana BollarapuNo ratings yet
- 4158-Article Text-10648-5-10-20230225Document10 pages4158-Article Text-10648-5-10-20230225Rishi AstasachindraNo ratings yet
- Lessons Learned From The Training of Gans On Artificial DatasetsDocument12 pagesLessons Learned From The Training of Gans On Artificial DatasetsAakash DhakalNo ratings yet
- Learning Deep Embeddings With Histogram LossDocument9 pagesLearning Deep Embeddings With Histogram LossEmran SalehNo ratings yet
- 124 Diagnosing and Fixing ManifoldDocument48 pages124 Diagnosing and Fixing ManifoldMayssa SOUSSIANo ratings yet
- Gan ComplateDocument6 pagesGan ComplateDivakar KeshriNo ratings yet
- And The Bit Goes DownDocument11 pagesAnd The Bit Goes Downgireesh123123No ratings yet
- 1929 Causal Discovery With ReinforcDocument17 pages1929 Causal Discovery With ReinforcAditya KonnurNo ratings yet
- Variational Deep EmbeddingDocument8 pagesVariational Deep EmbeddingBatkhongor ChagnaaNo ratings yet
- S - S L C - C G A N: EMI Upervised Earning With Ontext Onditional Enerative Dversarial EtworksDocument10 pagesS - S L C - C G A N: EMI Upervised Earning With Ontext Onditional Enerative Dversarial EtworksHuWalterNo ratings yet
- Feng When Do GANs Replicate On The Choice of Dataset Size ICCV 2021 PaperDocument10 pagesFeng When Do GANs Replicate On The Choice of Dataset Size ICCV 2021 PaperfaridasabryNo ratings yet
- Generative Adversarial Networks in Time Series: A Systematic Literature ReviewDocument31 pagesGenerative Adversarial Networks in Time Series: A Systematic Literature Reviewklaus peterNo ratings yet
- Lecture 2.3.4GANDocument4 pagesLecture 2.3.4GANMohd YusufNo ratings yet
- Negative Data AugmentationDocument17 pagesNegative Data AugmentationKaykayNo ratings yet
- GAN PaperDocument9 pagesGAN Paperbhuvankr2002No ratings yet
- None - ADCGAN - Conditional GANs With Auxiliary Discriminative ClassifierDocument16 pagesNone - ADCGAN - Conditional GANs With Auxiliary Discriminative Classifieran nguyenNo ratings yet
- Twin Auxilary Classifier GANDocument28 pagesTwin Auxilary Classifier GANan nguyenNo ratings yet
- Ijigsp V14 N5 3Document16 pagesIjigsp V14 N5 3Kamal HajariNo ratings yet
- Computer Vision Graph Cuts: Exploring Graph Cuts in Computer VisionFrom EverandComputer Vision Graph Cuts: Exploring Graph Cuts in Computer VisionNo ratings yet
- Spectral Norm Regularization For Improving The Generalizability of Deep LearningDocument12 pagesSpectral Norm Regularization For Improving The Generalizability of Deep LearningyonasNo ratings yet
- High-Resolution Image Synthesis and Semantic Manipulation With Conditional GansDocument60 pagesHigh-Resolution Image Synthesis and Semantic Manipulation With Conditional GansyonasNo ratings yet
- Absum: Simple Regularization Method For Reducing Structural Sensitivity of Convolutional Neural NetworksDocument10 pagesAbsum: Simple Regularization Method For Reducing Structural Sensitivity of Convolutional Neural NetworksyonasNo ratings yet
- Xun Huang Multimodal Unsupervised Image-To-Image ECCV 2018 PaperDocument18 pagesXun Huang Multimodal Unsupervised Image-To-Image ECCV 2018 PaperyonasNo ratings yet
- Thesis Dissertation Guide 20211001Document29 pagesThesis Dissertation Guide 20211001yonasNo ratings yet
- Justin Kuchta Criminal Complaint and AffidavitDocument5 pagesJustin Kuchta Criminal Complaint and AffidavitReport Annapolis NewsNo ratings yet
- NC20B1NL 2 UsansiDocument7 pagesNC20B1NL 2 UsansiBERSE MAJU INDONESIANo ratings yet
- PALE No. 1Document14 pagesPALE No. 1Anonymous lXytcd5NWNo ratings yet
- Blockchain Unit 1Document13 pagesBlockchain Unit 1sharmanikki8381No ratings yet
- Padini Holdings BHDDocument9 pagesPadini Holdings BHDFeliNo ratings yet
- Curling v. Raffensperger Transcript, Volume 4Document184 pagesCurling v. Raffensperger Transcript, Volume 4The FederalistNo ratings yet
- 06 08 DCF Quiz Questions Basic PDFDocument22 pages06 08 DCF Quiz Questions Basic PDFVarun AgarwalNo ratings yet
- Demand Function and ElasticityDocument3 pagesDemand Function and ElasticityHarshita RajputNo ratings yet
- PWC Basics of Mining 4 Som Mine Waste ManagementDocument46 pagesPWC Basics of Mining 4 Som Mine Waste Managementakm249No ratings yet
- Advanced Financial Accounting: 2 Year ExaminationDocument32 pagesAdvanced Financial Accounting: 2 Year ExaminationRobertKimtaiNo ratings yet
- Book 1Document219 pagesBook 1Ardi AnsyahNo ratings yet
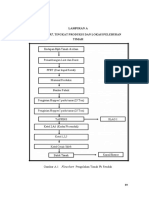
- Flowchart, Tingkat Produksi Dan Lokasi Peleburan: Lampiran ADocument11 pagesFlowchart, Tingkat Produksi Dan Lokasi Peleburan: Lampiran Aanton wibowoNo ratings yet
- 095-Everett vs. Asia Banking Corp 49 Phil 512Document8 pages095-Everett vs. Asia Banking Corp 49 Phil 512Jopan SJNo ratings yet
- CV May 2020 - Karen DavidgeDocument7 pagesCV May 2020 - Karen Davidgeapi-490357188No ratings yet
- Controller Xy wth1 Temperature and Humidity Manual OptimizedDocument6 pagesController Xy wth1 Temperature and Humidity Manual Optimizedsakemoto2No ratings yet
- ReflectionDocument1 pageReflectionThess Tecla Zerauc Azodnem100% (1)
- Shopping Cart - Regatta - Great OutdoorsDocument3 pagesShopping Cart - Regatta - Great OutdoorsMinchel MesquitaNo ratings yet
- OutlineDocument1 pageOutlineVictor ChanNo ratings yet
- Change of Owner Details C3A FormDocument2 pagesChange of Owner Details C3A FormcalebderneddeNo ratings yet
- A New Model For Predicting The Flight Activity of Lobesia BotranaDocument8 pagesA New Model For Predicting The Flight Activity of Lobesia BotranaClaudia SanchezNo ratings yet
- Manual de Puesta A Punto Motor K24 HondaDocument24 pagesManual de Puesta A Punto Motor K24 HondaAlvaro Mora100% (2)
- Instructor II: Instructor and Course EvaluationsDocument42 pagesInstructor II: Instructor and Course Evaluationsjesus floresNo ratings yet
- Workplace Software and Skills - WEB IlfJtcPDocument1,101 pagesWorkplace Software and Skills - WEB IlfJtcPlkeremoieltonNo ratings yet
- GeolineDocument15 pagesGeolineRepresentaciones y Distribuciones FALNo ratings yet
- BFR92/BFR92R: Silicon NPN Planar RF TransistorDocument6 pagesBFR92/BFR92R: Silicon NPN Planar RF TransistornudufoqiNo ratings yet
- Cost Benefit AnalysisDocument2 pagesCost Benefit AnalysisGarvitJainNo ratings yet
- Algorithms For Data Science: CSOR W4246Document44 pagesAlgorithms For Data Science: CSOR W4246EarthaNo ratings yet
- Dac11g PDFDocument326 pagesDac11g PDFDilip Kumar AluguNo ratings yet
- Design of Dynamic Balancing Machine 7a83bad5Document5 pagesDesign of Dynamic Balancing Machine 7a83bad5Wong Yong Jie100% (1)