Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5823)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- CERT-In Empanel OrgDocument141 pagesCERT-In Empanel OrgavinashrajsumanNo ratings yet
- Termpaper Grpup DDocument22 pagesTermpaper Grpup DSafiqul IslamNo ratings yet
- Course Title: Course Code: 503: Term Paper On "Chapter-3 (Phase Manner For Research) (I, Ii, Iv)Document41 pagesCourse Title: Course Code: 503: Term Paper On "Chapter-3 (Phase Manner For Research) (I, Ii, Iv)Safiqul IslamNo ratings yet
- Term Paper On "Regression Methodologies & Review of LiteratureDocument25 pagesTerm Paper On "Regression Methodologies & Review of LiteratureSafiqul IslamNo ratings yet
- Md. Saiful Islam: Career ObjectivesDocument2 pagesMd. Saiful Islam: Career ObjectivesSafiqul IslamNo ratings yet
- Rayhan MahmudDocument1 pageRayhan MahmudSafiqul IslamNo ratings yet
- Monomukdha: Address:Tikatoli, K M Des Lane, Dhaka Tel: +880 01703820742 Career ObjectiveDocument2 pagesMonomukdha: Address:Tikatoli, K M Des Lane, Dhaka Tel: +880 01703820742 Career ObjectiveSafiqul IslamNo ratings yet
- CIB Letter of AuthorityDocument3 pagesCIB Letter of AuthoritykoperasiNo ratings yet
- RE, EE PROJECT - Docx (Pas Jamal)Document27 pagesRE, EE PROJECT - Docx (Pas Jamal)Sabrina Abdurahman100% (2)
- SMS Internet Banking FormDocument4 pagesSMS Internet Banking FormSayed InsanNo ratings yet
- Issues and Challenges Faced in The Implementation of Basel III in Indian BanksDocument24 pagesIssues and Challenges Faced in The Implementation of Basel III in Indian Banksassignment helperNo ratings yet
- Investment and Banking LawDocument357 pagesInvestment and Banking LawNineteenNo ratings yet
- Determinants of Efficiency of Fiji's Commercial Banks: An Empirical Study: 2002-16Document20 pagesDeterminants of Efficiency of Fiji's Commercial Banks: An Empirical Study: 2002-16Rahul ChandNo ratings yet
- Office Memorandum No - DGW/MAN/221 Issued by Authority of Director General of WorksDocument14 pagesOffice Memorandum No - DGW/MAN/221 Issued by Authority of Director General of WorksreddytlnNo ratings yet
- Unit 13 Credit Risk Management: ObjectivesDocument41 pagesUnit 13 Credit Risk Management: ObjectivesSiva Venkata RamanaNo ratings yet
- STUDY PLAN Commercial Bank OperationsDocument4 pagesSTUDY PLAN Commercial Bank OperationshuzailinsyawanaNo ratings yet
- Introduction of Reserve Bank of IndiaDocument14 pagesIntroduction of Reserve Bank of IndiaGirish Lundwani88% (43)
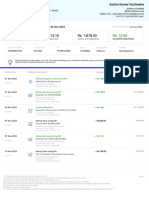
- Statement Nov 23 XXXXXXXX4196Document3 pagesStatement Nov 23 XXXXXXXX4196Sachin Kumar KushwahaNo ratings yet
- PE in China EY May2011Document20 pagesPE in China EY May2011pareshsharmaNo ratings yet
- Planning of Bank Branch AuditDocument9 pagesPlanning of Bank Branch AuditAshutosh PathakNo ratings yet
- 213F Principles of Banking LawsDocument81 pages213F Principles of Banking Lawsbhatt.net.in100% (1)
- Indonesia Payment Systems Blueprint 2025 PDFDocument72 pagesIndonesia Payment Systems Blueprint 2025 PDFShafira AmandaNo ratings yet
- Chapter - Xii Society, Religion and Temple: /j-U-V-/J-U-V-/J-u-u-u-u-u-u-u-U-U-U-u-U-U-VJ-VJ-U-U-U-U-U-U-U-VJDocument35 pagesChapter - Xii Society, Religion and Temple: /j-U-V-/J-U-V-/J-u-u-u-u-u-u-u-U-U-U-u-U-U-VJ-VJ-U-U-U-U-U-U-U-VJZarbEChishtiNo ratings yet
- The Intellectual Capital Performance of Banking Sector in PakistanDocument16 pagesThe Intellectual Capital Performance of Banking Sector in PakistanAbdul SamiNo ratings yet
- Banker Customer RelationshipDocument57 pagesBanker Customer RelationshipWillyken omariNo ratings yet
- Monirul, BangladeshDocument27 pagesMonirul, Bangladeshmoney_shallNo ratings yet
- Ecgc Schemes of Export: 1.maturity FactoringDocument5 pagesEcgc Schemes of Export: 1.maturity FactoringRizwan Kondkari0% (1)
- Application Form: ConfidentialDocument5 pagesApplication Form: Confidentialsk91222No ratings yet
- Financing Shipping Companies and Shipping OperationsDocument15 pagesFinancing Shipping Companies and Shipping OperationsIro Gidakou Georgiou100% (4)
- Role of MarketingDocument3 pagesRole of MarketingYogesh GodgeNo ratings yet
- Swift Connectivity Presentation Intro PDFDocument18 pagesSwift Connectivity Presentation Intro PDFveldanezNo ratings yet
- Credit Risk ModelingDocument213 pagesCredit Risk Modelinghsk1No ratings yet
- CT PT Marshalling BoxesDocument19 pagesCT PT Marshalling BoxesBoddu ThirupathiNo ratings yet
- Treasury Cash ManagementDocument9 pagesTreasury Cash ManagementEVERJOY MAPIRANo ratings yet
- Chapter 3 Financial Market StructuteDocument54 pagesChapter 3 Financial Market StructuteyebegashetNo ratings yet
- Study Guide No. 4 Chapter 4 - Extinguishment of ObligationsDocument11 pagesStudy Guide No. 4 Chapter 4 - Extinguishment of ObligationsHannah Marie Aliño100% (1)