
Database Management System Week 5 - Second Quarter
Database Management System Week 5 - Second Quarter
You might also like
- 155 เครน32ตันDocument95 pages155 เครน32ตันOos Tk100% (2)
- Sarajevo S Landscape First Look 20140417Document46 pagesSarajevo S Landscape First Look 20140417ado080992aodNo ratings yet
- SQL CREATE TABLE StatementDocument11 pagesSQL CREATE TABLE Statementkerya ibrahimNo ratings yet
- SQL Server Interview QuestionsDocument28 pagesSQL Server Interview QuestionshardhikasreeNo ratings yet
- Data Processing (hsd1)Document25 pagesData Processing (hsd1)jonahorjiNo ratings yet
- SS2 Data Processing Lesson Note Second TermDocument20 pagesSS2 Data Processing Lesson Note Second TermOLUWATAYO OLUWASEUNNo ratings yet
- Taking Advantage of Indexes: How It WorksDocument7 pagesTaking Advantage of Indexes: How It WorksMonika GuptaNo ratings yet
- ImplementingDocument8 pagesImplementingJaweriya AlamNo ratings yet
- Mysql: Eecs 448 Software Engineering Lab Lab #10: Mysql Due TimeDocument9 pagesMysql: Eecs 448 Software Engineering Lab Lab #10: Mysql Due TimeJeren ChenNo ratings yet
- Chapter 5 (SQL)Document19 pagesChapter 5 (SQL)rtyiookNo ratings yet
- Ignition DatabasesDocument38 pagesIgnition DatabasesMiguel100% (1)
- Structured Query Language (SQL)Document9 pagesStructured Query Language (SQL)James AndersonNo ratings yet
- 2A AssigmentDocument8 pages2A AssigmentrajNo ratings yet
- Define Candidate Key, Alternate Key, Composite Key.: AtomicityDocument4 pagesDefine Candidate Key, Alternate Key, Composite Key.: AtomicityrajeshlivetechNo ratings yet
- Automation Testing Using QTP, Visual Studio, Coded Ui Test, Manual Testing, Excel Database TestingDocument4 pagesAutomation Testing Using QTP, Visual Studio, Coded Ui Test, Manual Testing, Excel Database Testingshailesh_shekharNo ratings yet
- 3 - Describe Concepts of Relational DataDocument6 pages3 - Describe Concepts of Relational DataGustavoLadinoNo ratings yet
- SQL Interview QuestionsDocument14 pagesSQL Interview QuestionsRamu Yadav M100% (1)
- SQL ConstraintsDocument18 pagesSQL ConstraintsKristine CapaoNo ratings yet
- Chapter 2 & 3Document9 pagesChapter 2 & 3Marinette MedranoNo ratings yet
- ConstrangeriDocument17 pagesConstrangerigefinnaNo ratings yet
- Handout 5 - Working With Tables in SQLDocument10 pagesHandout 5 - Working With Tables in SQLabdiNo ratings yet
- SQL For Beginners Tutorial (Learn SQL in 2020) - DatagyDocument27 pagesSQL For Beginners Tutorial (Learn SQL in 2020) - DatagyVincent John RigorNo ratings yet
- SQL QueryDocument9 pagesSQL QuerynnandhaNo ratings yet
- ConstraintDocument30 pagesConstraintArbabNo ratings yet
- Data Processing SS2Document29 pagesData Processing SS2Ideji EkemenaNo ratings yet
- Data Types in SQLDocument12 pagesData Types in SQLharbolanle16No ratings yet
- Handout 5 - Working With Tables in SQLDocument11 pagesHandout 5 - Working With Tables in SQLRoha CbcNo ratings yet
- 105 SQL Interview Questions (2023 Prep Guide)Document24 pages105 SQL Interview Questions (2023 Prep Guide)Christine CaoNo ratings yet
- Rpl2020 SQL DDL DML 29thsep2020Document11 pagesRpl2020 SQL DDL DML 29thsep2020Vedasree TadukaNo ratings yet
- SQL QuestionsDocument28 pagesSQL Questionssanket@iiit100% (1)
- Database Management System MySQLDocument71 pagesDatabase Management System MySQLhazelyildiz18No ratings yet
- Unit 3 Relational ModelDocument32 pagesUnit 3 Relational ModelAshish bhandariNo ratings yet
- Coding RulesDocument8 pagesCoding Rulesapi-3747051No ratings yet
- Sample Paper For PreparationDocument11 pagesSample Paper For Preparationashish.s.sagamNo ratings yet
- Baker Construction....................... SQL ScreeningDocument8 pagesBaker Construction....................... SQL Screeningjiahui.jianggNo ratings yet
- Index CreationDocument30 pagesIndex CreationSubir Kumar DeyNo ratings yet
- SQL - CH 12 - Creating A DatabaseDocument9 pagesSQL - CH 12 - Creating A DatabaseNavinYattiNo ratings yet
- SQL AllDocument122 pagesSQL AllApurvaNo ratings yet
- IndexesDocument7 pagesIndexesSaurabh GuptaNo ratings yet
- Structured Query Language (SQL)Document29 pagesStructured Query Language (SQL)Sameer KhanNo ratings yet
- MSBI (Microsoft Business Intelligence) DataDocument10 pagesMSBI (Microsoft Business Intelligence) DataammapalliNo ratings yet
- Beginners SQL PlusDocument14 pagesBeginners SQL Plussalamanda1969No ratings yet
- A Quick-Start Tutorial On Relational Database Design: Step 1: Define The Purpose of The Database (Requirement Analysis)Document5 pagesA Quick-Start Tutorial On Relational Database Design: Step 1: Define The Purpose of The Database (Requirement Analysis)Prisca Michele MichaelNo ratings yet
- Advanced Android Development: Lesson 6.01 - Working With SQL and SqliteDocument33 pagesAdvanced Android Development: Lesson 6.01 - Working With SQL and SqliteRob LimaNo ratings yet
- Perofrmance and Indexes Discussion Questions Solutions PDFDocument5 pagesPerofrmance and Indexes Discussion Questions Solutions PDFbmaksNo ratings yet
- SQL Server Index BasicsDocument5 pagesSQL Server Index BasicsshashankniecNo ratings yet
- Oracle ImpDocument35 pagesOracle ImpPankaj AsudaniNo ratings yet
- Business Object UniverseDocument6 pagesBusiness Object Universeashish10mca9394No ratings yet
- Context: Stored ProceduresDocument18 pagesContext: Stored ProceduresZilemuhammad123No ratings yet
- SQL Qtns/Ans What Are Two Methods of Retrieving SQL?Document5 pagesSQL Qtns/Ans What Are Two Methods of Retrieving SQL?saumitra ghogale100% (1)
- Chetan SQL LearnsDocument21 pagesChetan SQL LearnsChetan BelagaliNo ratings yet
- SELECT DISTINCT Empname FROM EmptableDocument10 pagesSELECT DISTINCT Empname FROM Emptableapi-3818400No ratings yet
- SQL Server Interview QuestionsDocument9 pagesSQL Server Interview Questionsamanblr12No ratings yet
- Let Us Take An Example of We Have A Customer Table, in Customer Table We Have Customer Name, Customer Id, Customer Address ColumnsDocument1 pageLet Us Take An Example of We Have A Customer Table, in Customer Table We Have Customer Name, Customer Id, Customer Address ColumnsMoiz MohammedNo ratings yet
- SQL Interview Questions PDFDocument57 pagesSQL Interview Questions PDFNehal patilNo ratings yet
- 5.3 SQLDocument29 pages5.3 SQLBLADE LEMONNo ratings yet
- SQL CheatshetDocument15 pagesSQL Cheatshetdavita100% (1)
- Querying with SQL T-SQL for Microsoft SQL ServerFrom EverandQuerying with SQL T-SQL for Microsoft SQL ServerRating: 2.5 out of 5 stars2.5/5 (4)
- Cant Hurt Me Master Your Mind and Defy The OddsDocument32 pagesCant Hurt Me Master Your Mind and Defy The Oddspatrick.knapp196100% (46)
- Makati City Ordinance 2002 090H32vmTZOSSbwHa2RYGq0OWjZL9U-2zXIPH3EigH7XcBdXhmx30NqUeYAf8XMmYADocument2 pagesMakati City Ordinance 2002 090H32vmTZOSSbwHa2RYGq0OWjZL9U-2zXIPH3EigH7XcBdXhmx30NqUeYAf8XMmYAMyrna Francisco CasabonNo ratings yet
- Ryanair Magazine August - September 2010Document168 pagesRyanair Magazine August - September 2010jman5000No ratings yet
- Birla AlokyaDocument18 pagesBirla AlokyaanjaligargisbNo ratings yet
- How To Install XAMPP For WindowsDocument35 pagesHow To Install XAMPP For Windowsmarlon marcaidaNo ratings yet
- Allison Weir - A Study of FulviaDocument168 pagesAllison Weir - A Study of Fulviadumezil3729No ratings yet
- Inpho GT Lom KMDocument11 pagesInpho GT Lom KMlash73752No ratings yet
- Sahali Vs COMELECDocument11 pagesSahali Vs COMELECDaley CatugdaNo ratings yet
- JavascriptDocument15 pagesJavascriptRajashekar PrasadNo ratings yet
- MCQ ON - Chapter 1 - Artificial Intelligence (AI)Document18 pagesMCQ ON - Chapter 1 - Artificial Intelligence (AI)Adinath Baliram ShelkeNo ratings yet
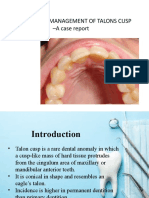
- Conservative Management of Talon's Cusp-A Case ReportDocument22 pagesConservative Management of Talon's Cusp-A Case ReportHarees Shabir100% (1)
- Jamb CRK Past QuestionsDocument79 pagesJamb CRK Past Questionsabedidejoshua100% (1)
- Hoa Election ProtestDocument2 pagesHoa Election Protestmaycil ambagNo ratings yet
- Mangroves of India - ReportDocument146 pagesMangroves of India - ReportAnjali Mohan100% (1)
- 61 0500eDocument30 pages61 0500eMuhammad DoniNo ratings yet
- Passports Rules, 1980Document62 pagesPassports Rules, 1980Latest Laws TeamNo ratings yet
- Cover Letter Sample For Software Engineer FresherDocument6 pagesCover Letter Sample For Software Engineer Fresherafiwhwlwx100% (1)
- Ost-Kerala Solar Energy Policy 2013Document7 pagesOst-Kerala Solar Energy Policy 2013Mahi On D RockzzNo ratings yet
- Keiko DilbeckDocument4 pagesKeiko DilbeckizaikellyNo ratings yet
- FranceDocument8 pagesFrancehorror339No ratings yet
- 3 Transcripts From The Fasting Transformation SummitDocument42 pages3 Transcripts From The Fasting Transformation SummitgambouchNo ratings yet
- Farewell RaymondlochengcoDocument42 pagesFarewell RaymondlochengcoOdie SeneresNo ratings yet
- 001 Nokia 810 Contacts Sync Instruction GuideDocument6 pages001 Nokia 810 Contacts Sync Instruction GuideJuan Ramón MartínezNo ratings yet
- MIP 2021 (Budget Proposal)Document215 pagesMIP 2021 (Budget Proposal)Yanny ManggugubatNo ratings yet
- Common Chemical Reactions in Everyday Life: ImagewillbeuploadedsoonDocument3 pagesCommon Chemical Reactions in Everyday Life: ImagewillbeuploadedsoonMei NalunneNo ratings yet
- Research Paper Topics About DogsDocument7 pagesResearch Paper Topics About Dogscafjhhaj100% (1)
- Life Without Trapped EmotionsDocument12 pagesLife Without Trapped EmotionsALTERINDONESIANo ratings yet
- AOCS Recommended Practice Ca 12-55 Phosphorus PDFDocument2 pagesAOCS Recommended Practice Ca 12-55 Phosphorus PDFWynona Basilio100% (1)

























































































Download as pdf or txt
You might also like
- 155 เครน32ตันDocument95 pages155 เครน32ตันOos Tk100% (2)
- Sarajevo S Landscape First Look 20140417Document46 pagesSarajevo S Landscape First Look 20140417ado080992aodNo ratings yet
- SQL CREATE TABLE StatementDocument11 pagesSQL CREATE TABLE Statementkerya ibrahimNo ratings yet
- SQL Server Interview QuestionsDocument28 pagesSQL Server Interview QuestionshardhikasreeNo ratings yet
- Data Processing (hsd1)Document25 pagesData Processing (hsd1)jonahorjiNo ratings yet
- SS2 Data Processing Lesson Note Second TermDocument20 pagesSS2 Data Processing Lesson Note Second TermOLUWATAYO OLUWASEUNNo ratings yet
- Taking Advantage of Indexes: How It WorksDocument7 pagesTaking Advantage of Indexes: How It WorksMonika GuptaNo ratings yet
- ImplementingDocument8 pagesImplementingJaweriya AlamNo ratings yet
- Mysql: Eecs 448 Software Engineering Lab Lab #10: Mysql Due TimeDocument9 pagesMysql: Eecs 448 Software Engineering Lab Lab #10: Mysql Due TimeJeren ChenNo ratings yet
- Chapter 5 (SQL)Document19 pagesChapter 5 (SQL)rtyiookNo ratings yet
- Ignition DatabasesDocument38 pagesIgnition DatabasesMiguel100% (1)
- Structured Query Language (SQL)Document9 pagesStructured Query Language (SQL)James AndersonNo ratings yet
- 2A AssigmentDocument8 pages2A AssigmentrajNo ratings yet
- Define Candidate Key, Alternate Key, Composite Key.: AtomicityDocument4 pagesDefine Candidate Key, Alternate Key, Composite Key.: AtomicityrajeshlivetechNo ratings yet
- Automation Testing Using QTP, Visual Studio, Coded Ui Test, Manual Testing, Excel Database TestingDocument4 pagesAutomation Testing Using QTP, Visual Studio, Coded Ui Test, Manual Testing, Excel Database Testingshailesh_shekharNo ratings yet
- 3 - Describe Concepts of Relational DataDocument6 pages3 - Describe Concepts of Relational DataGustavoLadinoNo ratings yet
- SQL Interview QuestionsDocument14 pagesSQL Interview QuestionsRamu Yadav M100% (1)
- SQL ConstraintsDocument18 pagesSQL ConstraintsKristine CapaoNo ratings yet
- Chapter 2 & 3Document9 pagesChapter 2 & 3Marinette MedranoNo ratings yet
- ConstrangeriDocument17 pagesConstrangerigefinnaNo ratings yet
- Handout 5 - Working With Tables in SQLDocument10 pagesHandout 5 - Working With Tables in SQLabdiNo ratings yet
- SQL For Beginners Tutorial (Learn SQL in 2020) - DatagyDocument27 pagesSQL For Beginners Tutorial (Learn SQL in 2020) - DatagyVincent John RigorNo ratings yet
- SQL QueryDocument9 pagesSQL QuerynnandhaNo ratings yet
- ConstraintDocument30 pagesConstraintArbabNo ratings yet
- Data Processing SS2Document29 pagesData Processing SS2Ideji EkemenaNo ratings yet
- Data Types in SQLDocument12 pagesData Types in SQLharbolanle16No ratings yet
- Handout 5 - Working With Tables in SQLDocument11 pagesHandout 5 - Working With Tables in SQLRoha CbcNo ratings yet
- 105 SQL Interview Questions (2023 Prep Guide)Document24 pages105 SQL Interview Questions (2023 Prep Guide)Christine CaoNo ratings yet
- Rpl2020 SQL DDL DML 29thsep2020Document11 pagesRpl2020 SQL DDL DML 29thsep2020Vedasree TadukaNo ratings yet
- SQL QuestionsDocument28 pagesSQL Questionssanket@iiit100% (1)
- Database Management System MySQLDocument71 pagesDatabase Management System MySQLhazelyildiz18No ratings yet
- Unit 3 Relational ModelDocument32 pagesUnit 3 Relational ModelAshish bhandariNo ratings yet
- Coding RulesDocument8 pagesCoding Rulesapi-3747051No ratings yet
- Sample Paper For PreparationDocument11 pagesSample Paper For Preparationashish.s.sagamNo ratings yet
- Baker Construction....................... SQL ScreeningDocument8 pagesBaker Construction....................... SQL Screeningjiahui.jianggNo ratings yet
- Index CreationDocument30 pagesIndex CreationSubir Kumar DeyNo ratings yet
- SQL - CH 12 - Creating A DatabaseDocument9 pagesSQL - CH 12 - Creating A DatabaseNavinYattiNo ratings yet
- SQL AllDocument122 pagesSQL AllApurvaNo ratings yet
- IndexesDocument7 pagesIndexesSaurabh GuptaNo ratings yet
- Structured Query Language (SQL)Document29 pagesStructured Query Language (SQL)Sameer KhanNo ratings yet
- MSBI (Microsoft Business Intelligence) DataDocument10 pagesMSBI (Microsoft Business Intelligence) DataammapalliNo ratings yet
- Beginners SQL PlusDocument14 pagesBeginners SQL Plussalamanda1969No ratings yet
- A Quick-Start Tutorial On Relational Database Design: Step 1: Define The Purpose of The Database (Requirement Analysis)Document5 pagesA Quick-Start Tutorial On Relational Database Design: Step 1: Define The Purpose of The Database (Requirement Analysis)Prisca Michele MichaelNo ratings yet
- Advanced Android Development: Lesson 6.01 - Working With SQL and SqliteDocument33 pagesAdvanced Android Development: Lesson 6.01 - Working With SQL and SqliteRob LimaNo ratings yet
- Perofrmance and Indexes Discussion Questions Solutions PDFDocument5 pagesPerofrmance and Indexes Discussion Questions Solutions PDFbmaksNo ratings yet
- SQL Server Index BasicsDocument5 pagesSQL Server Index BasicsshashankniecNo ratings yet
- Oracle ImpDocument35 pagesOracle ImpPankaj AsudaniNo ratings yet
- Business Object UniverseDocument6 pagesBusiness Object Universeashish10mca9394No ratings yet
- Context: Stored ProceduresDocument18 pagesContext: Stored ProceduresZilemuhammad123No ratings yet
- SQL Qtns/Ans What Are Two Methods of Retrieving SQL?Document5 pagesSQL Qtns/Ans What Are Two Methods of Retrieving SQL?saumitra ghogale100% (1)
- Chetan SQL LearnsDocument21 pagesChetan SQL LearnsChetan BelagaliNo ratings yet
- SELECT DISTINCT Empname FROM EmptableDocument10 pagesSELECT DISTINCT Empname FROM Emptableapi-3818400No ratings yet
- SQL Server Interview QuestionsDocument9 pagesSQL Server Interview Questionsamanblr12No ratings yet
- Let Us Take An Example of We Have A Customer Table, in Customer Table We Have Customer Name, Customer Id, Customer Address ColumnsDocument1 pageLet Us Take An Example of We Have A Customer Table, in Customer Table We Have Customer Name, Customer Id, Customer Address ColumnsMoiz MohammedNo ratings yet
- SQL Interview Questions PDFDocument57 pagesSQL Interview Questions PDFNehal patilNo ratings yet
- 5.3 SQLDocument29 pages5.3 SQLBLADE LEMONNo ratings yet
- SQL CheatshetDocument15 pagesSQL Cheatshetdavita100% (1)
- Querying with SQL T-SQL for Microsoft SQL ServerFrom EverandQuerying with SQL T-SQL for Microsoft SQL ServerRating: 2.5 out of 5 stars2.5/5 (4)
- Cant Hurt Me Master Your Mind and Defy The OddsDocument32 pagesCant Hurt Me Master Your Mind and Defy The Oddspatrick.knapp196100% (46)
- Makati City Ordinance 2002 090H32vmTZOSSbwHa2RYGq0OWjZL9U-2zXIPH3EigH7XcBdXhmx30NqUeYAf8XMmYADocument2 pagesMakati City Ordinance 2002 090H32vmTZOSSbwHa2RYGq0OWjZL9U-2zXIPH3EigH7XcBdXhmx30NqUeYAf8XMmYAMyrna Francisco CasabonNo ratings yet
- Ryanair Magazine August - September 2010Document168 pagesRyanair Magazine August - September 2010jman5000No ratings yet
- Birla AlokyaDocument18 pagesBirla AlokyaanjaligargisbNo ratings yet
- How To Install XAMPP For WindowsDocument35 pagesHow To Install XAMPP For Windowsmarlon marcaidaNo ratings yet
- Allison Weir - A Study of FulviaDocument168 pagesAllison Weir - A Study of Fulviadumezil3729No ratings yet
- Inpho GT Lom KMDocument11 pagesInpho GT Lom KMlash73752No ratings yet
- Sahali Vs COMELECDocument11 pagesSahali Vs COMELECDaley CatugdaNo ratings yet
- JavascriptDocument15 pagesJavascriptRajashekar PrasadNo ratings yet
- MCQ ON - Chapter 1 - Artificial Intelligence (AI)Document18 pagesMCQ ON - Chapter 1 - Artificial Intelligence (AI)Adinath Baliram ShelkeNo ratings yet
- Conservative Management of Talon's Cusp-A Case ReportDocument22 pagesConservative Management of Talon's Cusp-A Case ReportHarees Shabir100% (1)
- Jamb CRK Past QuestionsDocument79 pagesJamb CRK Past Questionsabedidejoshua100% (1)
- Hoa Election ProtestDocument2 pagesHoa Election Protestmaycil ambagNo ratings yet
- Mangroves of India - ReportDocument146 pagesMangroves of India - ReportAnjali Mohan100% (1)
- 61 0500eDocument30 pages61 0500eMuhammad DoniNo ratings yet
- Passports Rules, 1980Document62 pagesPassports Rules, 1980Latest Laws TeamNo ratings yet
- Cover Letter Sample For Software Engineer FresherDocument6 pagesCover Letter Sample For Software Engineer Fresherafiwhwlwx100% (1)
- Ost-Kerala Solar Energy Policy 2013Document7 pagesOst-Kerala Solar Energy Policy 2013Mahi On D RockzzNo ratings yet
- Keiko DilbeckDocument4 pagesKeiko DilbeckizaikellyNo ratings yet
- FranceDocument8 pagesFrancehorror339No ratings yet
- 3 Transcripts From The Fasting Transformation SummitDocument42 pages3 Transcripts From The Fasting Transformation SummitgambouchNo ratings yet
- Farewell RaymondlochengcoDocument42 pagesFarewell RaymondlochengcoOdie SeneresNo ratings yet
- 001 Nokia 810 Contacts Sync Instruction GuideDocument6 pages001 Nokia 810 Contacts Sync Instruction GuideJuan Ramón MartínezNo ratings yet
- MIP 2021 (Budget Proposal)Document215 pagesMIP 2021 (Budget Proposal)Yanny ManggugubatNo ratings yet
- Common Chemical Reactions in Everyday Life: ImagewillbeuploadedsoonDocument3 pagesCommon Chemical Reactions in Everyday Life: ImagewillbeuploadedsoonMei NalunneNo ratings yet
- Research Paper Topics About DogsDocument7 pagesResearch Paper Topics About Dogscafjhhaj100% (1)
- Life Without Trapped EmotionsDocument12 pagesLife Without Trapped EmotionsALTERINDONESIANo ratings yet
- AOCS Recommended Practice Ca 12-55 Phosphorus PDFDocument2 pagesAOCS Recommended Practice Ca 12-55 Phosphorus PDFWynona Basilio100% (1)