
Lecture Notes Chapter 5
Lecture Notes Chapter 5
You might also like
- Assignment #4 Magic Timber & SteelDocument12 pagesAssignment #4 Magic Timber & SteelASAD ULLAH36% (14)
- Linear - Regression - Assignment: Problem StatementDocument24 pagesLinear - Regression - Assignment: Problem Statementrakesh sandhyapogu100% (3)
- Econ 201 Exam 2 Study GuideDocument6 pagesEcon 201 Exam 2 Study GuideprojectilelolNo ratings yet
- Example 2Document7 pagesExample 2Thái TranNo ratings yet
- Homework 5 - Part - I - AKDocument14 pagesHomework 5 - Part - I - AKBagus SaputroNo ratings yet
- Regression, Correlation Analysis and Chi-Square AnalysisDocument39 pagesRegression, Correlation Analysis and Chi-Square AnalysisSaif Ali0% (1)
- Class 5Document7 pagesClass 5wingyanlam233No ratings yet
- Tutorial 5 - Bivariate AnalysisDocument7 pagesTutorial 5 - Bivariate AnalysisNoorNabilaNo ratings yet
- Statictics and Measures of Central TendencyDocument46 pagesStatictics and Measures of Central TendencyId Mohammad75% (4)
- Case Study 1 Ledgers and Emp - DSDocument20 pagesCase Study 1 Ledgers and Emp - DSAnand RajNo ratings yet
- Newsletter 17Document15 pagesNewsletter 17HungNo ratings yet
- MATH108X - Trend Lines Case Study: Project Goal: To Learn How Trend Lines Can Be Used As A Powerful Tool in TheDocument18 pagesMATH108X - Trend Lines Case Study: Project Goal: To Learn How Trend Lines Can Be Used As A Powerful Tool in TheJoel Haro100% (1)
- Tesla (TSLA) - WedbushDocument9 pagesTesla (TSLA) - WedbushpachzevelNo ratings yet
- Decision Science-Answers Dec 2023Document14 pagesDecision Science-Answers Dec 2023suhasini authuNo ratings yet
- Lecture 12 Part A-1Document11 pagesLecture 12 Part A-1Mai AnhNo ratings yet
- How To Perform Monte Carlo SimulationDocument13 pagesHow To Perform Monte Carlo SimulationsarabjeethanspalNo ratings yet
- Hero Motocorp LTDDocument26 pagesHero Motocorp LTDRahul KeshavanNo ratings yet
- Take-Home Assignment July 14Document9 pagesTake-Home Assignment July 14Fazal AbbasNo ratings yet
- Correlation and RegressionDocument6 pagesCorrelation and RegressionAline BritoNo ratings yet
- Imperfect Competition: Pure MonopolyDocument15 pagesImperfect Competition: Pure MonopolyMarcus WellsNo ratings yet
- Dynamic Dashboard in Excel - DemoDocument52 pagesDynamic Dashboard in Excel - DemoBhuvana RajendranNo ratings yet
- 18e Key Question Answers CH 8Document4 pages18e Key Question Answers CH 8David DavidNo ratings yet
- FinalDocument7 pagesFinalRak ADURNo ratings yet
- Ch12 ExercisesDocument10 pagesCh12 Exercisesamisha256258533% (3)
- Section 7 - BMIK 2023 - FinalDocument60 pagesSection 7 - BMIK 2023 - Final10622006No ratings yet
- Practice ProblemsDocument14 pagesPractice ProblemsAgANo ratings yet
- The 2D Tyre Modelling Conundrum and How To Fix It Using Setup ReferencingDocument10 pagesThe 2D Tyre Modelling Conundrum and How To Fix It Using Setup ReferencingbanabanaNo ratings yet
- Dynamic Dashboard in Excel - DemoDocument52 pagesDynamic Dashboard in Excel - Demoa3h1 5h3kNo ratings yet
- Topic 4 Notes On - Cost Curves DerivationDocument24 pagesTopic 4 Notes On - Cost Curves DerivationsilasmafungaNo ratings yet
- SCM End Sem QPDocument3 pagesSCM End Sem QPTharun GNo ratings yet
- Braking Effectiveness at Higher SpeedsDocument6 pagesBraking Effectiveness at Higher SpeedsdannoxyzNo ratings yet
- Quantitative AnalysisDocument6 pagesQuantitative AnalysisAnkur SinhaNo ratings yet
- Business School ADA University ECON 6100 Economics For Managers Student: Exam Duration: 18:45-20:15 Summer 2021Document5 pagesBusiness School ADA University ECON 6100 Economics For Managers Student: Exam Duration: 18:45-20:15 Summer 2021Ramil AliyevNo ratings yet
- Economics of Health and Health Care 7th Edition Folland Solutions ManualDocument16 pagesEconomics of Health and Health Care 7th Edition Folland Solutions Manuallisafloydropyebigcf100% (9)
- Word Note Aurora Textile Case Zinser 351Document6 pagesWord Note Aurora Textile Case Zinser 351alka murarka100% (1)
- Mcd2080-Etc1000-Etf1100 S1 2016Document11 pagesMcd2080-Etc1000-Etf1100 S1 2016michella vegaNo ratings yet
- Question.5 Allegheny Steel Corporation Has Been Looking Into The Factors That Influence How ManyDocument5 pagesQuestion.5 Allegheny Steel Corporation Has Been Looking Into The Factors That Influence How ManyRajkumarNo ratings yet
- Predictive Modelling ProjectDocument28 pagesPredictive Modelling ProjectPARIJAT DEVNo ratings yet
- KAREN JOY MAGSAYO - Final ExamDocument17 pagesKAREN JOY MAGSAYO - Final ExamKaren MagsayoNo ratings yet
- Econometrics Project: Supply and DemandDocument4 pagesEconometrics Project: Supply and DemandVasikeNo ratings yet
- Ftest and Applications Instructor: Dr. Kartikeya BolarDocument5 pagesFtest and Applications Instructor: Dr. Kartikeya Bolarharsha_295725251No ratings yet
- Chapter 12 - Applied ProblemsDocument9 pagesChapter 12 - Applied ProblemsZoha KamalNo ratings yet
- Value-at-Risk (VAR)Document19 pagesValue-at-Risk (VAR)Mayur SolankiNo ratings yet
- Optimal Operating Analysis: The XYZ CompanyDocument1 pageOptimal Operating Analysis: The XYZ Companyunderwood@eject.co.zaNo ratings yet
- Problems-Chapter 2Document5 pagesProblems-Chapter 2An VyNo ratings yet
- Done Unit2 Written AssignmentDocument7 pagesDone Unit2 Written AssignmentDjahan RanaNo ratings yet
- Application of Quantitative Methods in Managerial - Data Processing - Classification - SummarizationDocument22 pagesApplication of Quantitative Methods in Managerial - Data Processing - Classification - SummarizationRajat KukretiNo ratings yet
- Seminar 2Document5 pagesSeminar 2KNo ratings yet
- Practice Problem 2Document7 pagesPractice Problem 2Austin AzengaNo ratings yet
- Asm Chap 4 Bus 3382Document9 pagesAsm Chap 4 Bus 3382Đào ĐăngNo ratings yet
- Activity 26Document23 pagesActivity 26Jonathan ZhouNo ratings yet
- Trend Report 2 Book 4 - The Triple DutchDocument27 pagesTrend Report 2 Book 4 - The Triple DutchjohndoeertyNo ratings yet
- THURGA Tutorial 5Document5 pagesTHURGA Tutorial 5thurgakannanNo ratings yet
- Finance Assessment 2003Document19 pagesFinance Assessment 2003Avinash NarayanaNo ratings yet
- Engineering EconomicDocument10 pagesEngineering EconomicNguyễn Ý100% (1)
- Use of Weighted Average in GraphDocument4 pagesUse of Weighted Average in GraphneelimaNo ratings yet
- 2018 Sprint Deductible and Repair Schedule GAP GROUPDocument7 pages2018 Sprint Deductible and Repair Schedule GAP GROUPjakobguiNo ratings yet
- Worksheet 1Document2 pagesWorksheet 1yitagesu eshetuNo ratings yet
- Electroplating, Plating, Polishing, Anodizing & Coloring World Summary: Market Values & Financials by CountryFrom EverandElectroplating, Plating, Polishing, Anodizing & Coloring World Summary: Market Values & Financials by CountryNo ratings yet
- Speed Changers, Drives & Gears World Summary: Market Values & Financials by CountryFrom EverandSpeed Changers, Drives & Gears World Summary: Market Values & Financials by CountryNo ratings yet
- Allison Transmissions: How to Rebuild & Modify: How to Rebuild & ModifyFrom EverandAllison Transmissions: How to Rebuild & Modify: How to Rebuild & ModifyRating: 5 out of 5 stars5/5 (1)
- Normative Values and The Effects of Age, Gender, and Handedness On The Moberg Pick-Up Test.Document5 pagesNormative Values and The Effects of Age, Gender, and Handedness On The Moberg Pick-Up Test.Mary OvbieboNo ratings yet
- Respondents Age Sex Smoker? A.Categorical Frequency Distribution SexDocument13 pagesRespondents Age Sex Smoker? A.Categorical Frequency Distribution SexLalaluluNo ratings yet
- Business Statistics: Graphs, Charts, and Tables - Describing Your Data Graphs, Charts, and Tables - Describing Your DataDocument74 pagesBusiness Statistics: Graphs, Charts, and Tables - Describing Your Data Graphs, Charts, and Tables - Describing Your DataMuneer Quraishi100% (1)
- CA51018 Departmentals Quiz 1, 2, 3, - 4Document38 pagesCA51018 Departmentals Quiz 1, 2, 3, - 4artemisNo ratings yet
- Year 10 Maths - Chance - Data - Data Represnetation - Analysis - Questions (Ch2 Ex2)Document4 pagesYear 10 Maths - Chance - Data - Data Represnetation - Analysis - Questions (Ch2 Ex2)coffee080403No ratings yet
- GEA 1000 Tutorial 1 SolutionDocument12 pagesGEA 1000 Tutorial 1 SolutionAudryn LeeNo ratings yet
- JMP Help 1Document4 pagesJMP Help 1handsomepeeyushNo ratings yet
- Activity 1 - Descriptive StatisticsDocument7 pagesActivity 1 - Descriptive StatisticsCarl AfosNo ratings yet
- 1 Descriptive StatisticsDocument20 pages1 Descriptive StatisticsNittin BaruNo ratings yet
- Cazoom Maths. Box Plots GCSE Revision. AnswersDocument5 pagesCazoom Maths. Box Plots GCSE Revision. Answershollowayjustin643No ratings yet
- Handbook For Statistical Analysis of Environmental Background DataDocument137 pagesHandbook For Statistical Analysis of Environmental Background Dataapi-3833008No ratings yet
- 03.DataPreparation Outlier TreatmentDocument9 pages03.DataPreparation Outlier TreatmentSukhwinder KaurNo ratings yet
- Name: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Document8 pagesName: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Shivam BatraNo ratings yet
- Introductory Statistics With RDocument84 pagesIntroductory Statistics With RTamim IqbalNo ratings yet
- Basic Concepts of Statistics and Probability (2 of 3)Document24 pagesBasic Concepts of Statistics and Probability (2 of 3)adnan_aisNo ratings yet
- STATS Introduction Statistical AnalysisDocument105 pagesSTATS Introduction Statistical AnalysisKimberly parciaNo ratings yet
- Minitab GraphsDocument7 pagesMinitab GraphsAero AcadNo ratings yet
- Measures of Spread 2Document8 pagesMeasures of Spread 2Jattawee MarkNo ratings yet
- Chapter 3 Numerical Descriptive MeasuresDocument73 pagesChapter 3 Numerical Descriptive MeasuresTasya Asdiga0% (1)
- Mathews Paul G. Design of Experiments With MINITABDocument521 pagesMathews Paul G. Design of Experiments With MINITABDiego Vargas D100% (1)
- Box and Whisker Plot PDFDocument6 pagesBox and Whisker Plot PDFAtapolLeetrakulNo ratings yet
- Box & Whisker PlotsDocument15 pagesBox & Whisker Plotsapi-245317729No ratings yet
- TRIAL STPM Mathematics M 2 (KEDAH) SMK KhirJohariDocument9 pagesTRIAL STPM Mathematics M 2 (KEDAH) SMK KhirJohariSKNo ratings yet
- Stats Chapter 2Document40 pagesStats Chapter 2rrs_1988No ratings yet
- Third Space Learning Paper 3 Mark Scheme (Higher) AQADocument8 pagesThird Space Learning Paper 3 Mark Scheme (Higher) AQAHannah YeungNo ratings yet
- Co358U R' Programming Lab: Government College of Engineering Jalgaon M.S. Department of Computer EngineeringDocument97 pagesCo358U R' Programming Lab: Government College of Engineering Jalgaon M.S. Department of Computer EngineeringRiya MehtaNo ratings yet
- Pre-Practicum Lesson 10 28Document9 pagesPre-Practicum Lesson 10 28api-576039499No ratings yet
- Statistics Fundamentals SuccinctlyDocument104 pagesStatistics Fundamentals SuccinctlyJedaias RodriguesNo ratings yet
- Dads301 (U)Document11 pagesDads301 (U)Thrift ArmarioNo ratings yet



























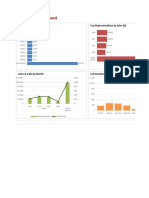






























































Download as doc, pdf, or txt
You might also like
- Assignment #4 Magic Timber & SteelDocument12 pagesAssignment #4 Magic Timber & SteelASAD ULLAH36% (14)
- Linear - Regression - Assignment: Problem StatementDocument24 pagesLinear - Regression - Assignment: Problem Statementrakesh sandhyapogu100% (3)
- Econ 201 Exam 2 Study GuideDocument6 pagesEcon 201 Exam 2 Study GuideprojectilelolNo ratings yet
- Example 2Document7 pagesExample 2Thái TranNo ratings yet
- Homework 5 - Part - I - AKDocument14 pagesHomework 5 - Part - I - AKBagus SaputroNo ratings yet
- Regression, Correlation Analysis and Chi-Square AnalysisDocument39 pagesRegression, Correlation Analysis and Chi-Square AnalysisSaif Ali0% (1)
- Class 5Document7 pagesClass 5wingyanlam233No ratings yet
- Tutorial 5 - Bivariate AnalysisDocument7 pagesTutorial 5 - Bivariate AnalysisNoorNabilaNo ratings yet
- Statictics and Measures of Central TendencyDocument46 pagesStatictics and Measures of Central TendencyId Mohammad75% (4)
- Case Study 1 Ledgers and Emp - DSDocument20 pagesCase Study 1 Ledgers and Emp - DSAnand RajNo ratings yet
- Newsletter 17Document15 pagesNewsletter 17HungNo ratings yet
- MATH108X - Trend Lines Case Study: Project Goal: To Learn How Trend Lines Can Be Used As A Powerful Tool in TheDocument18 pagesMATH108X - Trend Lines Case Study: Project Goal: To Learn How Trend Lines Can Be Used As A Powerful Tool in TheJoel Haro100% (1)
- Tesla (TSLA) - WedbushDocument9 pagesTesla (TSLA) - WedbushpachzevelNo ratings yet
- Decision Science-Answers Dec 2023Document14 pagesDecision Science-Answers Dec 2023suhasini authuNo ratings yet
- Lecture 12 Part A-1Document11 pagesLecture 12 Part A-1Mai AnhNo ratings yet
- How To Perform Monte Carlo SimulationDocument13 pagesHow To Perform Monte Carlo SimulationsarabjeethanspalNo ratings yet
- Hero Motocorp LTDDocument26 pagesHero Motocorp LTDRahul KeshavanNo ratings yet
- Take-Home Assignment July 14Document9 pagesTake-Home Assignment July 14Fazal AbbasNo ratings yet
- Correlation and RegressionDocument6 pagesCorrelation and RegressionAline BritoNo ratings yet
- Imperfect Competition: Pure MonopolyDocument15 pagesImperfect Competition: Pure MonopolyMarcus WellsNo ratings yet
- Dynamic Dashboard in Excel - DemoDocument52 pagesDynamic Dashboard in Excel - DemoBhuvana RajendranNo ratings yet
- 18e Key Question Answers CH 8Document4 pages18e Key Question Answers CH 8David DavidNo ratings yet
- FinalDocument7 pagesFinalRak ADURNo ratings yet
- Ch12 ExercisesDocument10 pagesCh12 Exercisesamisha256258533% (3)
- Section 7 - BMIK 2023 - FinalDocument60 pagesSection 7 - BMIK 2023 - Final10622006No ratings yet
- Practice ProblemsDocument14 pagesPractice ProblemsAgANo ratings yet
- The 2D Tyre Modelling Conundrum and How To Fix It Using Setup ReferencingDocument10 pagesThe 2D Tyre Modelling Conundrum and How To Fix It Using Setup ReferencingbanabanaNo ratings yet
- Dynamic Dashboard in Excel - DemoDocument52 pagesDynamic Dashboard in Excel - Demoa3h1 5h3kNo ratings yet
- Topic 4 Notes On - Cost Curves DerivationDocument24 pagesTopic 4 Notes On - Cost Curves DerivationsilasmafungaNo ratings yet
- SCM End Sem QPDocument3 pagesSCM End Sem QPTharun GNo ratings yet
- Braking Effectiveness at Higher SpeedsDocument6 pagesBraking Effectiveness at Higher SpeedsdannoxyzNo ratings yet
- Quantitative AnalysisDocument6 pagesQuantitative AnalysisAnkur SinhaNo ratings yet
- Business School ADA University ECON 6100 Economics For Managers Student: Exam Duration: 18:45-20:15 Summer 2021Document5 pagesBusiness School ADA University ECON 6100 Economics For Managers Student: Exam Duration: 18:45-20:15 Summer 2021Ramil AliyevNo ratings yet
- Economics of Health and Health Care 7th Edition Folland Solutions ManualDocument16 pagesEconomics of Health and Health Care 7th Edition Folland Solutions Manuallisafloydropyebigcf100% (9)
- Word Note Aurora Textile Case Zinser 351Document6 pagesWord Note Aurora Textile Case Zinser 351alka murarka100% (1)
- Mcd2080-Etc1000-Etf1100 S1 2016Document11 pagesMcd2080-Etc1000-Etf1100 S1 2016michella vegaNo ratings yet
- Question.5 Allegheny Steel Corporation Has Been Looking Into The Factors That Influence How ManyDocument5 pagesQuestion.5 Allegheny Steel Corporation Has Been Looking Into The Factors That Influence How ManyRajkumarNo ratings yet
- Predictive Modelling ProjectDocument28 pagesPredictive Modelling ProjectPARIJAT DEVNo ratings yet
- KAREN JOY MAGSAYO - Final ExamDocument17 pagesKAREN JOY MAGSAYO - Final ExamKaren MagsayoNo ratings yet
- Econometrics Project: Supply and DemandDocument4 pagesEconometrics Project: Supply and DemandVasikeNo ratings yet
- Ftest and Applications Instructor: Dr. Kartikeya BolarDocument5 pagesFtest and Applications Instructor: Dr. Kartikeya Bolarharsha_295725251No ratings yet
- Chapter 12 - Applied ProblemsDocument9 pagesChapter 12 - Applied ProblemsZoha KamalNo ratings yet
- Value-at-Risk (VAR)Document19 pagesValue-at-Risk (VAR)Mayur SolankiNo ratings yet
- Optimal Operating Analysis: The XYZ CompanyDocument1 pageOptimal Operating Analysis: The XYZ Companyunderwood@eject.co.zaNo ratings yet
- Problems-Chapter 2Document5 pagesProblems-Chapter 2An VyNo ratings yet
- Done Unit2 Written AssignmentDocument7 pagesDone Unit2 Written AssignmentDjahan RanaNo ratings yet
- Application of Quantitative Methods in Managerial - Data Processing - Classification - SummarizationDocument22 pagesApplication of Quantitative Methods in Managerial - Data Processing - Classification - SummarizationRajat KukretiNo ratings yet
- Seminar 2Document5 pagesSeminar 2KNo ratings yet
- Practice Problem 2Document7 pagesPractice Problem 2Austin AzengaNo ratings yet
- Asm Chap 4 Bus 3382Document9 pagesAsm Chap 4 Bus 3382Đào ĐăngNo ratings yet
- Activity 26Document23 pagesActivity 26Jonathan ZhouNo ratings yet
- Trend Report 2 Book 4 - The Triple DutchDocument27 pagesTrend Report 2 Book 4 - The Triple DutchjohndoeertyNo ratings yet
- THURGA Tutorial 5Document5 pagesTHURGA Tutorial 5thurgakannanNo ratings yet
- Finance Assessment 2003Document19 pagesFinance Assessment 2003Avinash NarayanaNo ratings yet
- Engineering EconomicDocument10 pagesEngineering EconomicNguyễn Ý100% (1)
- Use of Weighted Average in GraphDocument4 pagesUse of Weighted Average in GraphneelimaNo ratings yet
- 2018 Sprint Deductible and Repair Schedule GAP GROUPDocument7 pages2018 Sprint Deductible and Repair Schedule GAP GROUPjakobguiNo ratings yet
- Worksheet 1Document2 pagesWorksheet 1yitagesu eshetuNo ratings yet
- Electroplating, Plating, Polishing, Anodizing & Coloring World Summary: Market Values & Financials by CountryFrom EverandElectroplating, Plating, Polishing, Anodizing & Coloring World Summary: Market Values & Financials by CountryNo ratings yet
- Speed Changers, Drives & Gears World Summary: Market Values & Financials by CountryFrom EverandSpeed Changers, Drives & Gears World Summary: Market Values & Financials by CountryNo ratings yet
- Allison Transmissions: How to Rebuild & Modify: How to Rebuild & ModifyFrom EverandAllison Transmissions: How to Rebuild & Modify: How to Rebuild & ModifyRating: 5 out of 5 stars5/5 (1)
- Normative Values and The Effects of Age, Gender, and Handedness On The Moberg Pick-Up Test.Document5 pagesNormative Values and The Effects of Age, Gender, and Handedness On The Moberg Pick-Up Test.Mary OvbieboNo ratings yet
- Respondents Age Sex Smoker? A.Categorical Frequency Distribution SexDocument13 pagesRespondents Age Sex Smoker? A.Categorical Frequency Distribution SexLalaluluNo ratings yet
- Business Statistics: Graphs, Charts, and Tables - Describing Your Data Graphs, Charts, and Tables - Describing Your DataDocument74 pagesBusiness Statistics: Graphs, Charts, and Tables - Describing Your Data Graphs, Charts, and Tables - Describing Your DataMuneer Quraishi100% (1)
- CA51018 Departmentals Quiz 1, 2, 3, - 4Document38 pagesCA51018 Departmentals Quiz 1, 2, 3, - 4artemisNo ratings yet
- Year 10 Maths - Chance - Data - Data Represnetation - Analysis - Questions (Ch2 Ex2)Document4 pagesYear 10 Maths - Chance - Data - Data Represnetation - Analysis - Questions (Ch2 Ex2)coffee080403No ratings yet
- GEA 1000 Tutorial 1 SolutionDocument12 pagesGEA 1000 Tutorial 1 SolutionAudryn LeeNo ratings yet
- JMP Help 1Document4 pagesJMP Help 1handsomepeeyushNo ratings yet
- Activity 1 - Descriptive StatisticsDocument7 pagesActivity 1 - Descriptive StatisticsCarl AfosNo ratings yet
- 1 Descriptive StatisticsDocument20 pages1 Descriptive StatisticsNittin BaruNo ratings yet
- Cazoom Maths. Box Plots GCSE Revision. AnswersDocument5 pagesCazoom Maths. Box Plots GCSE Revision. Answershollowayjustin643No ratings yet
- Handbook For Statistical Analysis of Environmental Background DataDocument137 pagesHandbook For Statistical Analysis of Environmental Background Dataapi-3833008No ratings yet
- 03.DataPreparation Outlier TreatmentDocument9 pages03.DataPreparation Outlier TreatmentSukhwinder KaurNo ratings yet
- Name: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Document8 pagesName: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Shivam BatraNo ratings yet
- Introductory Statistics With RDocument84 pagesIntroductory Statistics With RTamim IqbalNo ratings yet
- Basic Concepts of Statistics and Probability (2 of 3)Document24 pagesBasic Concepts of Statistics and Probability (2 of 3)adnan_aisNo ratings yet
- STATS Introduction Statistical AnalysisDocument105 pagesSTATS Introduction Statistical AnalysisKimberly parciaNo ratings yet
- Minitab GraphsDocument7 pagesMinitab GraphsAero AcadNo ratings yet
- Measures of Spread 2Document8 pagesMeasures of Spread 2Jattawee MarkNo ratings yet
- Chapter 3 Numerical Descriptive MeasuresDocument73 pagesChapter 3 Numerical Descriptive MeasuresTasya Asdiga0% (1)
- Mathews Paul G. Design of Experiments With MINITABDocument521 pagesMathews Paul G. Design of Experiments With MINITABDiego Vargas D100% (1)
- Box and Whisker Plot PDFDocument6 pagesBox and Whisker Plot PDFAtapolLeetrakulNo ratings yet
- Box & Whisker PlotsDocument15 pagesBox & Whisker Plotsapi-245317729No ratings yet
- TRIAL STPM Mathematics M 2 (KEDAH) SMK KhirJohariDocument9 pagesTRIAL STPM Mathematics M 2 (KEDAH) SMK KhirJohariSKNo ratings yet
- Stats Chapter 2Document40 pagesStats Chapter 2rrs_1988No ratings yet
- Third Space Learning Paper 3 Mark Scheme (Higher) AQADocument8 pagesThird Space Learning Paper 3 Mark Scheme (Higher) AQAHannah YeungNo ratings yet
- Co358U R' Programming Lab: Government College of Engineering Jalgaon M.S. Department of Computer EngineeringDocument97 pagesCo358U R' Programming Lab: Government College of Engineering Jalgaon M.S. Department of Computer EngineeringRiya MehtaNo ratings yet
- Pre-Practicum Lesson 10 28Document9 pagesPre-Practicum Lesson 10 28api-576039499No ratings yet
- Statistics Fundamentals SuccinctlyDocument104 pagesStatistics Fundamentals SuccinctlyJedaias RodriguesNo ratings yet
- Dads301 (U)Document11 pagesDads301 (U)Thrift ArmarioNo ratings yet