Download as pdf or txt
You might also like
- Reinforcement Learning OptimizationDocument6 pagesReinforcement Learning OptimizationrhvzjprvNo ratings yet
- Wang, 2023, Deep Self-Consistent Learning of Local VolatilityDocument21 pagesWang, 2023, Deep Self-Consistent Learning of Local VolatilitynguyenhoangnguyenntNo ratings yet
- Stock Price Prediction Using Reinforcement LearningDocument6 pagesStock Price Prediction Using Reinforcement Learningankurdey2002.adNo ratings yet
- Random Sampling of States in Dynamic Programming: Christopher G. Atkeson and Benjamin J. StephensDocument6 pagesRandom Sampling of States in Dynamic Programming: Christopher G. Atkeson and Benjamin J. Stephenscnhzcy14No ratings yet
- Operator Tuning in Fuzzy Production Rules Using Neural NetworksDocument6 pagesOperator Tuning in Fuzzy Production Rules Using Neural Networksfree5050No ratings yet
- RL Course ReportDocument10 pagesRL Course ReportshaneNo ratings yet
- Nips00 BsDocument7 pagesNips00 BsmikeNo ratings yet
- Reinforcement Learning, Crawling Robot: Faculty of Sciences and Techniques Béni-MellalDocument5 pagesReinforcement Learning, Crawling Robot: Faculty of Sciences and Techniques Béni-MellalMohamedLahouaouiNo ratings yet
- Nodal Reliability and Nodal PricesDocument7 pagesNodal Reliability and Nodal Priceshodeegits9526No ratings yet
- DoomAIDocument7 pagesDoomAINghĩa TrọngNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- Research PaperDocument10 pagesResearch Paper李默然No ratings yet
- ProofDocument2 pagesProofanand vihariNo ratings yet
- Simulation of The Navigation of A Mobile Robot by The Q-Learning Using Artificial Neuron NetworksDocument12 pagesSimulation of The Navigation of A Mobile Robot by The Q-Learning Using Artificial Neuron NetworkstechlabNo ratings yet
- 16895-Article Text-20389-1-2-20210518Document8 pages16895-Article Text-20389-1-2-20210518Francis SimpsonNo ratings yet
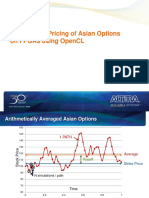
- Exm Opencl Asian Option Opencl FpgaDocument19 pagesExm Opencl Asian Option Opencl FpgaPaul RogerNo ratings yet
- Ann Lab Manual 2Document7 pagesAnn Lab Manual 2Manak JainNo ratings yet
- Hard Drive Failure Prediction Using Non-Parametric Statistical MethodsDocument4 pagesHard Drive Failure Prediction Using Non-Parametric Statistical MethodsEarl LaynoNo ratings yet
- 01ijcai MikeDocument6 pages01ijcai MikeHosseinNo ratings yet
- Calculating Sample Size To Estimate, With A Specified Tolerable Error, The Average For A Characteristic of A Lot or ProcessDocument5 pagesCalculating Sample Size To Estimate, With A Specified Tolerable Error, The Average For A Characteristic of A Lot or ProcessILSEN N. DAETNo ratings yet
- Trivedi 23 ADocument33 pagesTrivedi 23 AamleshkumarchandelNo ratings yet
- Panel DataDocument9 pagesPanel DataSharma ShikhaNo ratings yet
- 18AI71 - AAI INTERNAL 1 QB AnswersDocument14 pages18AI71 - AAI INTERNAL 1 QB AnswersSahithi BhashyamNo ratings yet
- The Optimization of A Pulverizing System Based On Genetic Algorithm and Neural NetworkDocument5 pagesThe Optimization of A Pulverizing System Based On Genetic Algorithm and Neural NetworkAnonymous PkeI8e84RsNo ratings yet
- Multi-Agent Deep Reinforcement Learning: Maxim Egorov Stanford UniversityDocument8 pagesMulti-Agent Deep Reinforcement Learning: Maxim Egorov Stanford UniversityCreativ PinoyNo ratings yet
- C-2008-Optimal Reconfiguration of Power System With Fuzzy ARTMAP Neural NetworksDocument6 pagesC-2008-Optimal Reconfiguration of Power System With Fuzzy ARTMAP Neural NetworksshahramjNo ratings yet
- Reinforcement Learning Based Quadcopter ControllerDocument7 pagesReinforcement Learning Based Quadcopter ControllerJoma JemmyNo ratings yet
- 111 ReportDocument6 pages111 ReportNguyễn Tự SangNo ratings yet
- Particle Swarm Optimization For Fuzzy Membership Functions OptimizationDocument6 pagesParticle Swarm Optimization For Fuzzy Membership Functions Optimizationwawan aries sandiNo ratings yet
- RL Course ReportDocument11 pagesRL Course Reportsyed zain abbasNo ratings yet
- Playing Geometry Dash With Convolutional Neural NetworksDocument7 pagesPlaying Geometry Dash With Convolutional Neural NetworksfriedmanNo ratings yet
- A Reinforcement Learning Approach To Obstacle Avoidance of MobilDocument5 pagesA Reinforcement Learning Approach To Obstacle Avoidance of MobilGhanshyam s.nairNo ratings yet
- ml96 PsDocument9 pagesml96 Pstye mooreNo ratings yet
- H Arsham 1989 Inverse Problems 5 927Document9 pagesH Arsham 1989 Inverse Problems 5 927Steve OkumuNo ratings yet
- Qpol 2104.07715Document31 pagesQpol 2104.07715roi.ho2706No ratings yet
- Learning Simple Games With Neural Networks: Kumar Ashutosh Mohd Safwan Manas VashisthaDocument6 pagesLearning Simple Games With Neural Networks: Kumar Ashutosh Mohd Safwan Manas VashisthaMohd SafwanNo ratings yet
- Synchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasDocument5 pagesSynchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasSatya NagendraNo ratings yet
- Class IubLinkDocument12 pagesClass IubLinkYoucef BERKANINo ratings yet
- Generating Intelligent Agent Behaviors in Multi-Agent Game AI Using Deep Reinforcement Learning AlgorithmDocument9 pagesGenerating Intelligent Agent Behaviors in Multi-Agent Game AI Using Deep Reinforcement Learning AlgorithmInternational Journal of Advances in Applied Sciences (IJAAS)No ratings yet
- 1 SMDocument8 pages1 SMshruthiNo ratings yet
- Agent-Based Evaluation of Driver Heterogeneous Behavior During Safety-Critical EventsDocument6 pagesAgent-Based Evaluation of Driver Heterogeneous Behavior During Safety-Critical EventscielyaoNo ratings yet
- Integration of Principal Components Analysis and Cellular Automata For Spatial Decisionmaking and UrbanDocument9 pagesIntegration of Principal Components Analysis and Cellular Automata For Spatial Decisionmaking and UrbancamilazahiraputritasrifNo ratings yet
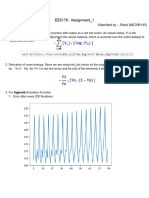
- Assignment EE5179 ME20B145 ReportDocument6 pagesAssignment EE5179 ME20B145 ReportRahul me20b145No ratings yet
- Optimization, Learning, and Games With Predictable SequencesDocument22 pagesOptimization, Learning, and Games With Predictable SequencesIrwan Adhi PrasetyaNo ratings yet
- Consensus For Multiple Euler-Lagrange Dynamics With Arbitrary Sampling Periods and Event-Triggered StrategyDocument5 pagesConsensus For Multiple Euler-Lagrange Dynamics With Arbitrary Sampling Periods and Event-Triggered StrategyUmarShahrozNo ratings yet
- The Controlled Random Search Algorithm in Optimizing Regression ModelsDocument6 pagesThe Controlled Random Search Algorithm in Optimizing Regression ModelsAlmir RodriguesNo ratings yet
- Corrections To Off-Axis Data Recorders: Measurements From EventDocument48 pagesCorrections To Off-Axis Data Recorders: Measurements From Eventdj39alxNo ratings yet
- Cellular Automata Based Synthesis of Easily and Fully Testable FSMsDocument4 pagesCellular Automata Based Synthesis of Easily and Fully Testable FSMsDipanwita Roy ChowdhuryNo ratings yet
- Learning To Learn by Gradient Descent by Gradient DescentDocument10 pagesLearning To Learn by Gradient Descent by Gradient DescentAnkit BiswasNo ratings yet
- CS181 Final ProjectDocument5 pagesCS181 Final ProjectRahul RNo ratings yet
- An Introduction To Neural Networks: Instituto Tecgraf PUC-Rio Nome: Fernanda Duarte Orientador: Marcelo GattassDocument45 pagesAn Introduction To Neural Networks: Instituto Tecgraf PUC-Rio Nome: Fernanda Duarte Orientador: Marcelo GattassGiGa GFNo ratings yet
- Tips For FEA AnalysisDocument6 pagesTips For FEA Analysissagar1503No ratings yet
- Performing Aggressive Maneuvers Using Iterative Learning ControlDocument6 pagesPerforming Aggressive Maneuvers Using Iterative Learning ControlVan Tien LeNo ratings yet
- Making The Car Faster On Highway in DeeptrafficDocument3 pagesMaking The Car Faster On Highway in Deeptrafficapi-339792990No ratings yet
- A Comparison Between Monte Carlo and Forms in Calculating The Reliability of A Composite StructureDocument8 pagesA Comparison Between Monte Carlo and Forms in Calculating The Reliability of A Composite Structuremin yoonjiNo ratings yet
- Brands 1988-1Document4 pagesBrands 1988-1Usman AliNo ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- Schematic of Experimental Span of JSC "STC FGC UES" For Testing of Vibration Dampers On Wire EfficiencyDocument5 pagesSchematic of Experimental Span of JSC "STC FGC UES" For Testing of Vibration Dampers On Wire EfficiencyStevepallmerNo ratings yet
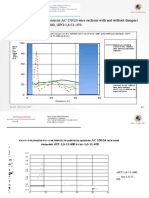
- Maximum Bending Stresses in AC 150/24 Wire Sections With and Without Dampers HVT-1,6-11-800, GPG-1,6-11-450Document5 pagesMaximum Bending Stresses in AC 150/24 Wire Sections With and Without Dampers HVT-1,6-11-800, GPG-1,6-11-450StevepallmerNo ratings yet
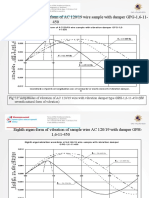
- Seventh Natural Waveform of AC 120/19 Wire Sample With Damper GPG-1,6-11-450Document5 pagesSeventh Natural Waveform of AC 120/19 Wire Sample With Damper GPG-1,6-11-450StevepallmerNo ratings yet
- Clase6 2014-7 PDFDocument1 pageClase6 2014-7 PDFStevepallmerNo ratings yet
- Thirteenth Proper Form of Vibration of The Sample Wire AC 120/19 With Dampener GPH-1,6-11-450Document5 pagesThirteenth Proper Form of Vibration of The Sample Wire AC 120/19 With Dampener GPH-1,6-11-450StevepallmerNo ratings yet
- Clase6 2014-5 PDFDocument1 pageClase6 2014-5 PDFStevepallmerNo ratings yet
- 10 PDFDocument1 page10 PDFStevepallmerNo ratings yet
- View PDFDocument135 pagesView PDFStevepallmerNo ratings yet
- BF 02129047Document14 pagesBF 02129047StevepallmerNo ratings yet
- Mediators: The Scientific World JournalDocument1 pageMediators: The Scientific World JournalStevepallmerNo ratings yet
- 3.4. Analysis and Discussions. The Curve and Fitted Curve ofDocument1 page3.4. Analysis and Discussions. The Curve and Fitted Curve ofStevepallmerNo ratings yet
- 10 PDFDocument1 page10 PDFStevepallmerNo ratings yet
- Influence On Air Pressure Dynamic Characteristics: Figure 5: Respiratory Resistance of The SystemDocument1 pageInfluence On Air Pressure Dynamic Characteristics: Figure 5: Respiratory Resistance of The SystemStevepallmerNo ratings yet
- 6 PDFDocument1 page6 PDFStevepallmerNo ratings yet
- Research Article: Pressure Dynamic Characteristics of Pressure Controlled Ventilation System of A Lung SimulatorDocument1 pageResearch Article: Pressure Dynamic Characteristics of Pressure Controlled Ventilation System of A Lung SimulatorStevepallmerNo ratings yet
- Section 2.2.4: 5. ConclusionsDocument1 pageSection 2.2.4: 5. ConclusionsStevepallmerNo ratings yet
- Tube Lung: 3. Experimental and Simulation StudyDocument1 pageTube Lung: 3. Experimental and Simulation StudyStevepallmerNo ratings yet
- Computational and Mathematical Methods in Medicine 9Document1 pageComputational and Mathematical Methods in Medicine 9StevepallmerNo ratings yet
- Introduction and Modeling of Mechanical Ventilation SystemDocument1 pageIntroduction and Modeling of Mechanical Ventilation SystemStevepallmerNo ratings yet
- ME (PSE) Unit - 5 (Non Linear Programming)Document8 pagesME (PSE) Unit - 5 (Non Linear Programming)Dharshini A SNo ratings yet
- Graphical Linear ProgrammingDocument18 pagesGraphical Linear ProgrammingYuuNo ratings yet
- Classnotes - Coursework of OptimizationDocument14 pagesClassnotes - Coursework of OptimizationHudzaifa AhnafNo ratings yet
- Seminar 8 - Network Models I (Exercise)Document2 pagesSeminar 8 - Network Models I (Exercise)ms2447No ratings yet
- 9th Polynomial Test Paper-5Document1 page9th Polynomial Test Paper-5weblogicdocsNo ratings yet
- Lecture-3 Problems Solving by SearchingDocument79 pagesLecture-3 Problems Solving by SearchingmusaNo ratings yet
- Operations ResearchDocument2 pagesOperations ResearchIshant Bansal100% (4)
- 06 - Binomial Theorem For Positve Integral IndexDocument8 pages06 - Binomial Theorem For Positve Integral Indexpoojitha ponagantiNo ratings yet
- Unit 2Document38 pagesUnit 2HOW to BASIC INDIANNo ratings yet
- Curve Fitting: Professor Henry ArguelloDocument36 pagesCurve Fitting: Professor Henry ArguelloCristian MartinezNo ratings yet
- 2 LPM + SimplexDocument66 pages2 LPM + SimplexEndashaw DebruNo ratings yet
- HW2Document3 pagesHW2당근으로만든무말랭이No ratings yet
- Chapter One Polynomials: 1-1 Introduction Definition 1.1: A Monomial in Variable X Is An Expression of The Form C XDocument28 pagesChapter One Polynomials: 1-1 Introduction Definition 1.1: A Monomial in Variable X Is An Expression of The Form C Xعبداللە عمر ابراهیمNo ratings yet
- 01 Interpolation 1Document14 pages01 Interpolation 1kevincarloscanalesNo ratings yet
- SolutionDocument247 pagesSolutiontalha khanNo ratings yet
- Mathematics For Class 10 Real NumbersDocument5 pagesMathematics For Class 10 Real Numberssharik9431313158No ratings yet
- DWBI Assignment 17BDocument3 pagesDWBI Assignment 17BSiri Penmetsa0% (1)
- Data Structure: Depth/Breadth-First SearchDocument19 pagesData Structure: Depth/Breadth-First SearchJahangir AliNo ratings yet
- Neural Network BSCDocument32 pagesNeural Network BSCSHIVAS RAINANo ratings yet
- Summative Test # 1.1Document2 pagesSummative Test # 1.1April Rose Alforque MagbanuaNo ratings yet
- Algorithm Suggestion 2021Document3 pagesAlgorithm Suggestion 2021Sajid Hossain KhanNo ratings yet
- A. Finding Roots of The Equations:: (AlgorithmDocument2 pagesA. Finding Roots of The Equations:: (AlgorithmBinoNo ratings yet
- Model For The Layout Problem (Part 1)Document43 pagesModel For The Layout Problem (Part 1)Noormalita IrvianaNo ratings yet
- Problem Set 3: Solutions: Damien Klossner Damien - Klossner@epfl - CH Extranef 128 October 19, 2018Document6 pagesProblem Set 3: Solutions: Damien Klossner Damien - Klossner@epfl - CH Extranef 128 October 19, 2018ddd huangNo ratings yet
- Idoc - Pub - Ccodechamp Com C Program of Newton Raphson Method C Code Cha PDFDocument7 pagesIdoc - Pub - Ccodechamp Com C Program of Newton Raphson Method C Code Cha PDFPrincess NobleNo ratings yet
- Quadratic EquationDocument5 pagesQuadratic EquationteachersarasNo ratings yet
- Chapter 3 OTSMDocument74 pagesChapter 3 OTSMayush5699.ajNo ratings yet
- Approximation Algorithms PDFDocument59 pagesApproximation Algorithms PDFMr PhiNo ratings yet
- Steps in Stepping Stone MethodDocument1 pageSteps in Stepping Stone MethodHazell DNo ratings yet
- Engineering Mathematics 3Document319 pagesEngineering Mathematics 3Pranjyoti NathNo ratings yet