Download as docx, pdf, or txt
You might also like
- Ae 311 Midterm Exam PartDocument13 pagesAe 311 Midterm Exam PartSamsung AccountNo ratings yet
- SPSS Instructions (BEO6000) 6Document15 pagesSPSS Instructions (BEO6000) 6Apple AppleNo ratings yet
- Cost Segregation and Estimation (Final)Document4 pagesCost Segregation and Estimation (Final)Laut Bantuas IINo ratings yet
- Lab 4 AssignmentDocument7 pagesLab 4 AssignmentSeneida BiendarraNo ratings yet
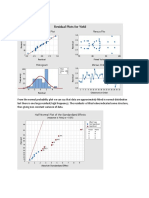
- Residual Plots For Yield: Normal Probability Plot Versus FitsDocument3 pagesResidual Plots For Yield: Normal Probability Plot Versus FitsBablu KumarNo ratings yet
- Principles of Chemistry A Molecular Approach 2nd Edition Tro Solutions Manual 1Document36 pagesPrinciples of Chemistry A Molecular Approach 2nd Edition Tro Solutions Manual 1tammycontrerasgdaxwypisr100% (29)
- Chapter 13 HW 13-5Document18 pagesChapter 13 HW 13-5Tushar GoyalNo ratings yet
- Analisis ResidualDocument6 pagesAnalisis ResidualLuis Enrique Tuñoque GutiérrezNo ratings yet
- Lecture6 Mar29 2024Document23 pagesLecture6 Mar29 2024sd.ashifNo ratings yet
- AssignmentDocument10 pagesAssignmentTharindu DhananjayaNo ratings yet
- Residual Plots For Response: Normal Probability Plot Versus FitsDocument2 pagesResidual Plots For Response: Normal Probability Plot Versus FitsBablu KumarNo ratings yet
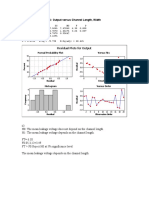
- Two-Way ANOVA: Output Versus Channel Length, Width: Normal Probability Plot Versus FitsDocument1 pageTwo-Way ANOVA: Output Versus Channel Length, Width: Normal Probability Plot Versus FitsFfmohamad NAdNo ratings yet
- Analysis of ANOVADocument6 pagesAnalysis of ANOVASadi MohaiminulNo ratings yet
- Analysis of ANOVA: Regression StatisticsDocument6 pagesAnalysis of ANOVA: Regression StatisticsSadi MohaiminulNo ratings yet
- Analysis of ANOVA: Regression StatisticsDocument6 pagesAnalysis of ANOVA: Regression StatisticsSadi MohaiminulNo ratings yet
- Stats - Assignment 3Document18 pagesStats - Assignment 3haonanzhangNo ratings yet
- Chapter 5 - SupportDocument15 pagesChapter 5 - SupportwafarasoolNo ratings yet
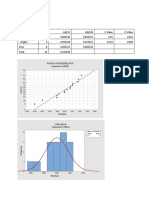
- Octane Numbe R Afte R Inje CtionDocument2 pagesOctane Numbe R Afte R Inje CtionFaizal NurNo ratings yet
- Fixed Income - Part II SolutionsDocument50 pagesFixed Income - Part II SolutionsJohnNo ratings yet
- Determining Returns ExercisesDocument6 pagesDetermining Returns ExercisesRicarr ChiongNo ratings yet
- Determining Returns - ExercisesDocument6 pagesDetermining Returns - ExercisesRicarr ChiongNo ratings yet
- Histogram: (Response Is Interaction)Document5 pagesHistogram: (Response Is Interaction)Bablu KumarNo ratings yet
- 01 - 0 Harian PRINTDocument31 pages01 - 0 Harian PRINTwhiteshadow15514No ratings yet
- Chapter 11: Multiple Regression and Correlation: Ey Ey Ey X X Ey X X X For Which by Contrast, When X Ey XDocument14 pagesChapter 11: Multiple Regression and Correlation: Ey Ey Ey X X Ey X X X For Which by Contrast, When X Ey XŞterbeţ RuxandraNo ratings yet
- Financial Management Predictive ModelingDocument15 pagesFinancial Management Predictive ModelingShankaran RamanNo ratings yet
- Ch25 Tool KitADocument27 pagesCh25 Tool KitARoy HemenwayNo ratings yet
- Design and Analysis of Experiments 2Document8 pagesDesign and Analysis of Experiments 2api-3723257100% (1)
- Figure 1. Data Brands of Batteries Are Under StudyDocument13 pagesFigure 1. Data Brands of Batteries Are Under StudyAbner SuarezNo ratings yet
- This Work Is Licensed Under The Creative Commons Attribution-Noncommercial 3.0 Singapore LicenseDocument24 pagesThis Work Is Licensed Under The Creative Commons Attribution-Noncommercial 3.0 Singapore LicenseFrancesco ZucchettoNo ratings yet
- Residual Plots For Kekuatan BahanDocument1 pageResidual Plots For Kekuatan BahanFebrian IsharyadiNo ratings yet
- OPIM-274 HW2-SolutionsDocument4 pagesOPIM-274 HW2-SolutionsJSNo ratings yet
- Lecture 9 Activity Furqan Farooq - 18292Document10 pagesLecture 9 Activity Furqan Farooq - 18292Furqan Farooq VadhariaNo ratings yet
- Sympatec - Typical Sample Report PDFDocument1 pageSympatec - Typical Sample Report PDFhamedNo ratings yet
- BiostatDocument7 pagesBiostatyoan yulista hartivaNo ratings yet
- Investment CriteriaDocument15 pagesInvestment CriteriaGOWTHAM K KNo ratings yet
- 3.sieve Analysis in Fine AggregateDocument1 page3.sieve Analysis in Fine AggregateLakshithaGonapinuwalaWithanageNo ratings yet
- Savings Analysis Short Run and Long Run 1Document7 pagesSavings Analysis Short Run and Long Run 1davidNo ratings yet
- B3-201-2018 - Developing and Using Justifiable Asset Health Indices For Tactical and Strategic Risk ManagementDocument10 pagesB3-201-2018 - Developing and Using Justifiable Asset Health Indices For Tactical and Strategic Risk ManagementNamLeNo ratings yet
- Bern Klein Bulk Sorting Abstract2Document3 pagesBern Klein Bulk Sorting Abstract2Luis Katsumoto Huere AnayaNo ratings yet
- The Effects of B, C and AC Are Large and Significant.: Problem 6.6 A) Calculation of EffectDocument4 pagesThe Effects of B, C and AC Are Large and Significant.: Problem 6.6 A) Calculation of EffectBablu KumarNo ratings yet
- Assignment 4 10Document4 pagesAssignment 4 10Bablu KumarNo ratings yet
- Analysis of VarianceDocument4 pagesAnalysis of VarianceBablu KumarNo ratings yet
- CH 5Document13 pagesCH 5Rupesh kumarNo ratings yet
- QM Assignment 1Document3 pagesQM Assignment 1GogNo ratings yet
- Given The Table Below, Fill Up The Columns Labeled Proportion and Percentage. ADocument9 pagesGiven The Table Below, Fill Up The Columns Labeled Proportion and Percentage. ADennis Esik MaligayaNo ratings yet
- Output AnalysisDocument4 pagesOutput AnalysisTinuk SetyoriniNo ratings yet
- Update k3 Ulat Kantong 2020 NovemberDocument75 pagesUpdate k3 Ulat Kantong 2020 NovemberGhufran Shauma BayumurtiNo ratings yet
- FM16 Ch25 Tool KitDocument35 pagesFM16 Ch25 Tool KitAdamNo ratings yet
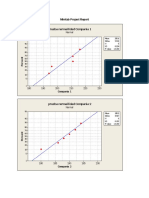
- Minitab Project ReportDocument3 pagesMinitab Project Reportramonfer79No ratings yet
- 환공 솔루션Document119 pages환공 솔루션김채원No ratings yet
- Definitive Measurement For Gradient Performance WatersDocument2 pagesDefinitive Measurement For Gradient Performance WatersWellerson OliveiraNo ratings yet
- Lack of Fit 17.46 7 2.49 0.62 0.7267 Not Significant Pure Error 32.02 8 4.00Document3 pagesLack of Fit 17.46 7 2.49 0.62 0.7267 Not Significant Pure Error 32.02 8 4.00Anonymous bnwcKLNo ratings yet
- Tools Used For Analysis: Test of IndependenceDocument7 pagesTools Used For Analysis: Test of IndependenceManojkumar R DglNo ratings yet
- A6 Regression Challenge ANSWERSDocument6 pagesA6 Regression Challenge ANSWERSeoip.swdept.mgmtNo ratings yet
- Financial ModellingDocument8 pagesFinancial ModellingHasan UL KarimNo ratings yet
- Free Sample of Portfolio OptimizationDocument45 pagesFree Sample of Portfolio OptimizationPrarthana MohapatraNo ratings yet
- Simple Linear Regression: Interpreting Minitab OutputDocument4 pagesSimple Linear Regression: Interpreting Minitab Outputrkrajesh86No ratings yet
- 6.2. MethodologyDocument12 pages6.2. MethodologyAtiaTahiraNo ratings yet
- Particle Separator Guidelines 1996 PDFDocument5 pagesParticle Separator Guidelines 1996 PDFRicardo MachadoNo ratings yet
- Group I RepairDocument5 pagesGroup I RepairMTS EHSNo ratings yet
- Chapter 8 Dividend and ValuationDocument22 pagesChapter 8 Dividend and ValuationRoy YadavNo ratings yet
- Increment: Lognormal 7.08% Lognormal 11.08%Document54 pagesIncrement: Lognormal 7.08% Lognormal 11.08%l3aliday4440No ratings yet
- Health and Safety Management Plan Faculty of Management Studies Align With ISO 45001: 2018Document21 pagesHealth and Safety Management Plan Faculty of Management Studies Align With ISO 45001: 2018Nadeeka SanjeewaniNo ratings yet
- Strategic ManagementDocument9 pagesStrategic ManagementNadeeka SanjeewaniNo ratings yet
- Application of Spearmen CorrelationDocument21 pagesApplication of Spearmen CorrelationNadeeka SanjeewaniNo ratings yet
- Application of Pearson Correlation and Partial CorrelationDocument20 pagesApplication of Pearson Correlation and Partial CorrelationNadeeka SanjeewaniNo ratings yet
- Application of Spearmen Correlation: Data Analysis and Presentation (BM - 4152)Document17 pagesApplication of Spearmen Correlation: Data Analysis and Presentation (BM - 4152)Nadeeka SanjeewaniNo ratings yet
- Cmjs Full Date 2022 11 23 56266079Document15 pagesCmjs Full Date 2022 11 23 56266079Ai lynNo ratings yet
- Baptista, I. (2019) - Positional Differences in Peak - and Accumulated - Training Load Relative To Match Load in Elite FootballDocument10 pagesBaptista, I. (2019) - Positional Differences in Peak - and Accumulated - Training Load Relative To Match Load in Elite FootballjefeNo ratings yet
- Using R For Linear RegressionDocument9 pagesUsing R For Linear RegressionMohar SenNo ratings yet
- QT-Assignment 1 - Nov22Document4 pagesQT-Assignment 1 - Nov22Rafiq BawanyNo ratings yet
- Histogram PorositasDocument2 pagesHistogram PorositasajnmboNo ratings yet
- Using The T-Test: IB Biology Topic 1Document22 pagesUsing The T-Test: IB Biology Topic 1Elena KaraivanovaNo ratings yet
- Chapter 3 DoneDocument5 pagesChapter 3 DoneJERRICO TENEBRO100% (1)
- Schwalbe (2008) - A Meta Analysys of Juvenile Justice Risk Assessment InstrumentsDocument15 pagesSchwalbe (2008) - A Meta Analysys of Juvenile Justice Risk Assessment InstrumentsGilberto Zúñiga MonjeNo ratings yet
- Discriminant AnalysisDocument16 pagesDiscriminant Analysishsrinivas_7No ratings yet
- Covid-19 Case Study Using MS-Excel (Report) : Submitted By: Rasika Deshpande (020) PGDM-RBA, Welingkar, BangaloreDocument19 pagesCovid-19 Case Study Using MS-Excel (Report) : Submitted By: Rasika Deshpande (020) PGDM-RBA, Welingkar, BangaloreRasika DeshpandeNo ratings yet
- BA Module 5 SummaryDocument3 pagesBA Module 5 Summaryshubham waghNo ratings yet
- SHARIFI-EnGR 371 Summer 2016 Outline ModifiedDocument5 pagesSHARIFI-EnGR 371 Summer 2016 Outline ModifiedBrunoNo ratings yet
- Trading StrategyDocument2 pagesTrading StrategyJamison CarsonNo ratings yet
- Chapter 18 Nonparametric Methods AnalysiDocument17 pagesChapter 18 Nonparametric Methods Analysiyoussef888 tharwatNo ratings yet
- 15 Practice Exercise Week 3Document5 pages15 Practice Exercise Week 3Shoaib SakhiNo ratings yet
- 7863 17602 1 SMDocument9 pages7863 17602 1 SMATIKA AGUSTINNo ratings yet
- Interpretation of Anova TableDocument3 pagesInterpretation of Anova Tablesunusimaryamabdullahi2006No ratings yet
- MCQ Chapter 11Document3 pagesMCQ Chapter 11Linh Chi100% (1)
- Polynomial Regression and Step FunctionDocument6 pagesPolynomial Regression and Step Functionapi-285777244100% (1)
- TN Board Samacheer Kalvi Class12 Statistics Book EMDocument280 pagesTN Board Samacheer Kalvi Class12 Statistics Book EMVikas JhaNo ratings yet
- Interview Questions Data AnalyticsDocument25 pagesInterview Questions Data AnalyticsArpit SoniNo ratings yet
- 5 6107033548873532058Document29 pages5 6107033548873532058Vishal SNo ratings yet
- QM Statistic NotesDocument24 pagesQM Statistic NotesSalim Abdulrahim BafadhilNo ratings yet
- 4-Accuracy in Forecasting PDFDocument43 pages4-Accuracy in Forecasting PDFAmber KiranNo ratings yet
- Chapter 15: Two-Factor Analysis of VarianceDocument21 pagesChapter 15: Two-Factor Analysis of VarianceMohd Ellif SarianNo ratings yet
- Statistical Control of Measures and Processes: 2009 Elsevier B.V. All Rights ReservedDocument30 pagesStatistical Control of Measures and Processes: 2009 Elsevier B.V. All Rights ReservedCalidad LassNo ratings yet
- Assignment PMRPDocument2 pagesAssignment PMRPA2 MotivationNo ratings yet