
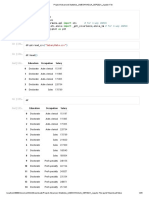
Machine Learning - Nabeel Khan - Final Project Report - Problem 2
Machine Learning - Nabeel Khan - Final Project Report - Problem 2
You might also like
- Time Series Forecasting - Project ReportDocument68 pagesTime Series Forecasting - Project ReportKhursheedKhan33% (3)
- Time Series Forecasting - Final Project ReportDocument67 pagesTime Series Forecasting - Final Project ReportKhursheedKhan89% (9)
- Decision Making: Submitted By-Ankita MishraDocument20 pagesDecision Making: Submitted By-Ankita MishraAnkita MishraNo ratings yet
- Extended Project FastKart SQLite MYSQL 1 1 PDFDocument5 pagesExtended Project FastKart SQLite MYSQL 1 1 PDFAmey UdapureNo ratings yet
- Logistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1Document1 pageLogistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1AbhijitSinha50% (2)
- MRA Project Milestone2 PDFDocument1 pageMRA Project Milestone2 PDFRekha Rajaram100% (1)
- Asphalt Shingles Data Analysis PDFDocument4 pagesAsphalt Shingles Data Analysis PDFsonali PradhanNo ratings yet
- Data Mining Project - 27.06.2021Document6 pagesData Mining Project - 27.06.2021vansh guptaNo ratings yet
- Predictive Modelling - Final Project Report-Logistic Regression and LDADocument25 pagesPredictive Modelling - Final Project Report-Logistic Regression and LDAKhursheedKhan100% (1)
- Predictive Modelling - Final Project Report-Logistic Regression and LDADocument25 pagesPredictive Modelling - Final Project Report-Logistic Regression and LDAKhursheedKhan100% (1)
- Clustering Analysis: Prepared by Muralidharan NDocument16 pagesClustering Analysis: Prepared by Muralidharan Nrakesh sandhyapoguNo ratings yet
- Simple Regression QuizDocument6 pagesSimple Regression QuizKiranmai GogireddyNo ratings yet
- Factor-Hair RV PDFDocument23 pagesFactor-Hair RV PDFRamachandran VenkataramanNo ratings yet
- CAC Authentication in Linux With The Dell SK-3205 KeyboardDocument12 pagesCAC Authentication in Linux With The Dell SK-3205 KeyboardIanNo ratings yet
- Smart Metering SAP ISUDocument59 pagesSmart Metering SAP ISUDipesh0% (1)
- Predictive Modelling Report - ReshmaDocument20 pagesPredictive Modelling Report - Reshmareshma ajithNo ratings yet
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- SQL Quiz ResultsDocument17 pagesSQL Quiz ResultsJram MarjNo ratings yet
- Data Mining Assignment: Sudhanva SaralayaDocument16 pagesData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- TimeSeries ReportDocument41 pagesTimeSeries ReportSukanya ManickavelNo ratings yet
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Document18 pagesBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya HajareNo ratings yet
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Pranjal - Singh - 25.12.2022 - Data Mining ProjectDocument8 pagesPranjal - Singh - 25.12.2022 - Data Mining ProjectPranjal SinghNo ratings yet
- Quiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series DataDocument2 pagesQuiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series Dataraja ahmedNo ratings yet
- Project Time Series Forecasting ROSE Dataset by Somya Dhar 1 PDFDocument52 pagesProject Time Series Forecasting ROSE Dataset by Somya Dhar 1 PDFARCHANA RNo ratings yet
- Predictive Modelling Project 2Document32 pagesPredictive Modelling Project 2Purva Soni100% (3)
- Answer Report: Data MiningDocument32 pagesAnswer Report: Data MiningChetan SharmaNo ratings yet
- ML Quiz-2Document5 pagesML Quiz-2Saikat BhattacharyyaNo ratings yet
- Predictive Model: Submitted byDocument27 pagesPredictive Model: Submitted byAnkita Mishra100% (2)
- Predictive ModelingDocument38 pagesPredictive ModelingHafsah Wita KusumaNo ratings yet
- SMDM STATISTICS PROJECT-MARCH27th - DEEPA CHURIDocument16 pagesSMDM STATISTICS PROJECT-MARCH27th - DEEPA CHURIDeepa ChuriNo ratings yet
- LDA KNN LogisticDocument29 pagesLDA KNN Logisticshruti gujar100% (1)
- Data Mining Clustering PDFDocument15 pagesData Mining Clustering PDFSwing TradeNo ratings yet
- VaibhavKumar Extendedproject PDFDocument10 pagesVaibhavKumar Extendedproject PDFAnshul Dyundi100% (2)
- Travel Agency PackageDocument26 pagesTravel Agency PackageKATHIRVEL SNo ratings yet
- Girish Chadha - 29th December 2022Document35 pagesGirish Chadha - 29th December 2022Girish Chadha100% (3)
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- Random Forest - US - Heart - Patients - ClassDocument24 pagesRandom Forest - US - Heart - Patients - ClassShripad H100% (1)
- Cart-Rf-ANN: Prepared by Muralidharan NDocument16 pagesCart-Rf-ANN: Prepared by Muralidharan NKrishnaveni Raj0% (1)
- Assignment MLDocument21 pagesAssignment MLManish Verma100% (2)
- Us PresidentDocument24 pagesUs PresidentAnonymous nfHBPXz178No ratings yet
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Document15 pagesProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo coco100% (1)
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- Project QuestionsDocument3 pagesProject QuestionsravikgovinduNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- ML - Project - Business ReportDocument43 pagesML - Project - Business ReportROHINI ROKDENo ratings yet
- Namta Bansal - Machine Learning - 17 Jan 2022Document33 pagesNamta Bansal - Machine Learning - 17 Jan 2022namtaNo ratings yet
- Project Advanced Statistics UMESHHASIJA SEP2021 Jupyter FileDocument25 pagesProject Advanced Statistics UMESHHASIJA SEP2021 Jupyter Fileumesh hasijaNo ratings yet
- Problem 2 Businessreport MLDocument9 pagesProblem 2 Businessreport MLRajeshNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- Project Time Series ForecastingDocument53 pagesProject Time Series Forecastingharish kumar100% (1)
- SMDM Project ReportDocument19 pagesSMDM Project ReportSANJAY ANANDAN100% (1)
- Capstone-2 Market Basket Analysis Vinothkumar RDocument18 pagesCapstone-2 Market Basket Analysis Vinothkumar RVinothkumar RadhakrishnanNo ratings yet
- Suresh-Rose Time Series Forecasting Project ReportDocument75 pagesSuresh-Rose Time Series Forecasting Project ReportARCHANA R100% (1)
- Code It QuestionsDocument3 pagesCode It QuestionsNimisha SharmaNo ratings yet
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Project 3 - Build A Logistic Regression Model To Predict Custo Mer Churn in Telecom IndustryV1.0 PDFDocument38 pagesProject 3 - Build A Logistic Regression Model To Predict Custo Mer Churn in Telecom IndustryV1.0 PDFPrakash Jha100% (1)
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Document12 pagesBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya Hajare100% (1)
- Capstone Project SubmissionDocument31 pagesCapstone Project Submissionguruss604684100% (1)
- ML Assignemnt PDFDocument21 pagesML Assignemnt PDFEric NormanNo ratings yet
- Tushar Tukaram Bhakare: Education SkillsDocument1 pageTushar Tukaram Bhakare: Education SkillsSUMEET SARODENo ratings yet
- DSBAProject Oct 2020Document24 pagesDSBAProject Oct 2020Abhay PoddarNo ratings yet
- Cubic Zirconia Price Prediction Case Study ReportDocument34 pagesCubic Zirconia Price Prediction Case Study ReportSomnath Kumbhar100% (1)
- Applied Computational Fluid Dynamics Techniques: An Introduction Based on Finite Element MethodsFrom EverandApplied Computational Fluid Dynamics Techniques: An Introduction Based on Finite Element MethodsNo ratings yet
- Machine Learning - Final Project Report - Problem 1Document26 pagesMachine Learning - Final Project Report - Problem 1KhursheedKhan100% (1)
- IT 7000 - Week 7 Final Presentation - SubramanyamDocument25 pagesIT 7000 - Week 7 Final Presentation - SubramanyamKhursheedKhanNo ratings yet
- Triveni Guntipally - IT 7000 - Week 7 PresentationDocument16 pagesTriveni Guntipally - IT 7000 - Week 7 PresentationKhursheedKhanNo ratings yet
- Ananda Vidya Sagar KATAKAM - MIS - Week 7 Assignment - PresentationDocument26 pagesAnanda Vidya Sagar KATAKAM - MIS - Week 7 Assignment - PresentationKhursheedKhanNo ratings yet
- Ehealth Smart Health Prediction System: Pujitha GangarapuDocument20 pagesEhealth Smart Health Prediction System: Pujitha GangarapuKhursheedKhanNo ratings yet
- Macr PresentationDocument1 pageMacr PresentationKhursheedKhanNo ratings yet
- Success Story Template V0 1Document2 pagesSuccess Story Template V0 1KhursheedKhanNo ratings yet
- Gigabyte GA-H61M-S1Document29 pagesGigabyte GA-H61M-S1arturo rivasNo ratings yet
- Class-Xi Syllabus 2015-16Document34 pagesClass-Xi Syllabus 2015-16Nandini SinghNo ratings yet
- 4G - NCR SSA - 3 - NW - Ischak - SPRO - JBRO - WJRO - CJRO - MODCELLDLSCHALGO - MODEUTRANINTRAFREQNCELL - SE Improvement - 4 - NE - 20210120Document19 pages4G - NCR SSA - 3 - NW - Ischak - SPRO - JBRO - WJRO - CJRO - MODCELLDLSCHALGO - MODEUTRANINTRAFREQNCELL - SE Improvement - 4 - NE - 20210120Ischak ChaerudinNo ratings yet
- Performance Evaluation of Fixed-Point Array Multipliers On Xilinx FpgasDocument5 pagesPerformance Evaluation of Fixed-Point Array Multipliers On Xilinx FpgasMeghanand KumarNo ratings yet
- 4QDocument2 pages4QRakesh ShivshankarNo ratings yet
- NFS2-640/E: Fire Alarm Control Panel Programming ManualDocument124 pagesNFS2-640/E: Fire Alarm Control Panel Programming ManualMinhthien NguyenNo ratings yet
- 5g Wireless Technology Documentation-1Document25 pages5g Wireless Technology Documentation-118WJ1A03L4 RAVI MechNo ratings yet
- IThome Taiwan Cyberscape Sep2021Document1 pageIThome Taiwan Cyberscape Sep2021Roland TamNo ratings yet
- Autonomous VehiclesDocument61 pagesAutonomous VehiclesRohan RahalkarNo ratings yet
- News Sharing in Social Media PDFDocument14 pagesNews Sharing in Social Media PDFCamille PajarilloNo ratings yet
- Logistic Support Analysis (LSA) : TitleDocument26 pagesLogistic Support Analysis (LSA) : Titlenebodepa lyftNo ratings yet
- Implementation of The Internet of Things On Smart Posters Using Near Field Communication Technology in The Tourism SectorDocument9 pagesImplementation of The Internet of Things On Smart Posters Using Near Field Communication Technology in The Tourism SectorCSIT iaesprimeNo ratings yet
- Project Jig & Fixture UTMDocument90 pagesProject Jig & Fixture UTMadibah ismail100% (1)
- En Ac80remapcelem CDocument351 pagesEn Ac80remapcelem CAlejandra De Anda JimenezNo ratings yet
- Demonstrative Adjectives Online PDF Worksheet - Live WorksheetsDocument1 pageDemonstrative Adjectives Online PDF Worksheet - Live WorksheetsCristofer FárezNo ratings yet
- Ict 7 Week 4, 1Document29 pagesIct 7 Week 4, 1Jhan G CalateNo ratings yet
- Crate Archives - RFLDocument4 pagesCrate Archives - RFLFaisal Mohd ShahneoazNo ratings yet
- Product Data Sheet: Asfora - Single Socket Outlet With Side Earth - 16A CreamDocument2 pagesProduct Data Sheet: Asfora - Single Socket Outlet With Side Earth - 16A CreamДимитър МирчевNo ratings yet
- GSM Map ErrorcodeDocument3 pagesGSM Map Errorcodeariful_islam_20067643No ratings yet
- GSI Corti Quick GuideDocument1 pageGSI Corti Quick GuideLourdes Hernández GonzálezNo ratings yet
- WEEK 7 Module - CircuitsDocument6 pagesWEEK 7 Module - CircuitsSatsuki MomoiNo ratings yet
- INF3707 ExaminationDocument4 pagesINF3707 ExaminationhilaryNo ratings yet
- 106Document495 pages106Shankar SahniNo ratings yet
- N E Z E P: Practice Worksheet: Properties of ExponentsDocument2 pagesN E Z E P: Practice Worksheet: Properties of ExponentsAlex ZzNo ratings yet
- Secure OpenShift Applications W IBM Cloud App IDDocument117 pagesSecure OpenShift Applications W IBM Cloud App IDContus FirmasNo ratings yet
- Od 327583247761431100Document1 pageOd 327583247761431100jto HVGNo ratings yet
- Adama Science and Technology University: School of Electrical Engineering and ComputingDocument10 pagesAdama Science and Technology University: School of Electrical Engineering and ComputingDechasa ShimelsNo ratings yet
- Wood Express ManualDocument36 pagesWood Express ManualgertjaniNo ratings yet


































































































Download as docx, pdf, or txt
You might also like
- Time Series Forecasting - Project ReportDocument68 pagesTime Series Forecasting - Project ReportKhursheedKhan33% (3)
- Time Series Forecasting - Final Project ReportDocument67 pagesTime Series Forecasting - Final Project ReportKhursheedKhan89% (9)
- Decision Making: Submitted By-Ankita MishraDocument20 pagesDecision Making: Submitted By-Ankita MishraAnkita MishraNo ratings yet
- Extended Project FastKart SQLite MYSQL 1 1 PDFDocument5 pagesExtended Project FastKart SQLite MYSQL 1 1 PDFAmey UdapureNo ratings yet
- Logistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1Document1 pageLogistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1AbhijitSinha50% (2)
- MRA Project Milestone2 PDFDocument1 pageMRA Project Milestone2 PDFRekha Rajaram100% (1)
- Asphalt Shingles Data Analysis PDFDocument4 pagesAsphalt Shingles Data Analysis PDFsonali PradhanNo ratings yet
- Data Mining Project - 27.06.2021Document6 pagesData Mining Project - 27.06.2021vansh guptaNo ratings yet
- Predictive Modelling - Final Project Report-Logistic Regression and LDADocument25 pagesPredictive Modelling - Final Project Report-Logistic Regression and LDAKhursheedKhan100% (1)
- Predictive Modelling - Final Project Report-Logistic Regression and LDADocument25 pagesPredictive Modelling - Final Project Report-Logistic Regression and LDAKhursheedKhan100% (1)
- Clustering Analysis: Prepared by Muralidharan NDocument16 pagesClustering Analysis: Prepared by Muralidharan Nrakesh sandhyapoguNo ratings yet
- Simple Regression QuizDocument6 pagesSimple Regression QuizKiranmai GogireddyNo ratings yet
- Factor-Hair RV PDFDocument23 pagesFactor-Hair RV PDFRamachandran VenkataramanNo ratings yet
- CAC Authentication in Linux With The Dell SK-3205 KeyboardDocument12 pagesCAC Authentication in Linux With The Dell SK-3205 KeyboardIanNo ratings yet
- Smart Metering SAP ISUDocument59 pagesSmart Metering SAP ISUDipesh0% (1)
- Predictive Modelling Report - ReshmaDocument20 pagesPredictive Modelling Report - Reshmareshma ajithNo ratings yet
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- SQL Quiz ResultsDocument17 pagesSQL Quiz ResultsJram MarjNo ratings yet
- Data Mining Assignment: Sudhanva SaralayaDocument16 pagesData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- TimeSeries ReportDocument41 pagesTimeSeries ReportSukanya ManickavelNo ratings yet
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Document18 pagesBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya HajareNo ratings yet
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Pranjal - Singh - 25.12.2022 - Data Mining ProjectDocument8 pagesPranjal - Singh - 25.12.2022 - Data Mining ProjectPranjal SinghNo ratings yet
- Quiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series DataDocument2 pagesQuiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series Dataraja ahmedNo ratings yet
- Project Time Series Forecasting ROSE Dataset by Somya Dhar 1 PDFDocument52 pagesProject Time Series Forecasting ROSE Dataset by Somya Dhar 1 PDFARCHANA RNo ratings yet
- Predictive Modelling Project 2Document32 pagesPredictive Modelling Project 2Purva Soni100% (3)
- Answer Report: Data MiningDocument32 pagesAnswer Report: Data MiningChetan SharmaNo ratings yet
- ML Quiz-2Document5 pagesML Quiz-2Saikat BhattacharyyaNo ratings yet
- Predictive Model: Submitted byDocument27 pagesPredictive Model: Submitted byAnkita Mishra100% (2)
- Predictive ModelingDocument38 pagesPredictive ModelingHafsah Wita KusumaNo ratings yet
- SMDM STATISTICS PROJECT-MARCH27th - DEEPA CHURIDocument16 pagesSMDM STATISTICS PROJECT-MARCH27th - DEEPA CHURIDeepa ChuriNo ratings yet
- LDA KNN LogisticDocument29 pagesLDA KNN Logisticshruti gujar100% (1)
- Data Mining Clustering PDFDocument15 pagesData Mining Clustering PDFSwing TradeNo ratings yet
- VaibhavKumar Extendedproject PDFDocument10 pagesVaibhavKumar Extendedproject PDFAnshul Dyundi100% (2)
- Travel Agency PackageDocument26 pagesTravel Agency PackageKATHIRVEL SNo ratings yet
- Girish Chadha - 29th December 2022Document35 pagesGirish Chadha - 29th December 2022Girish Chadha100% (3)
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- Random Forest - US - Heart - Patients - ClassDocument24 pagesRandom Forest - US - Heart - Patients - ClassShripad H100% (1)
- Cart-Rf-ANN: Prepared by Muralidharan NDocument16 pagesCart-Rf-ANN: Prepared by Muralidharan NKrishnaveni Raj0% (1)
- Assignment MLDocument21 pagesAssignment MLManish Verma100% (2)
- Us PresidentDocument24 pagesUs PresidentAnonymous nfHBPXz178No ratings yet
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Document15 pagesProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo coco100% (1)
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- Project QuestionsDocument3 pagesProject QuestionsravikgovinduNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- ML - Project - Business ReportDocument43 pagesML - Project - Business ReportROHINI ROKDENo ratings yet
- Namta Bansal - Machine Learning - 17 Jan 2022Document33 pagesNamta Bansal - Machine Learning - 17 Jan 2022namtaNo ratings yet
- Project Advanced Statistics UMESHHASIJA SEP2021 Jupyter FileDocument25 pagesProject Advanced Statistics UMESHHASIJA SEP2021 Jupyter Fileumesh hasijaNo ratings yet
- Problem 2 Businessreport MLDocument9 pagesProblem 2 Businessreport MLRajeshNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- Project Time Series ForecastingDocument53 pagesProject Time Series Forecastingharish kumar100% (1)
- SMDM Project ReportDocument19 pagesSMDM Project ReportSANJAY ANANDAN100% (1)
- Capstone-2 Market Basket Analysis Vinothkumar RDocument18 pagesCapstone-2 Market Basket Analysis Vinothkumar RVinothkumar RadhakrishnanNo ratings yet
- Suresh-Rose Time Series Forecasting Project ReportDocument75 pagesSuresh-Rose Time Series Forecasting Project ReportARCHANA R100% (1)
- Code It QuestionsDocument3 pagesCode It QuestionsNimisha SharmaNo ratings yet
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Project 3 - Build A Logistic Regression Model To Predict Custo Mer Churn in Telecom IndustryV1.0 PDFDocument38 pagesProject 3 - Build A Logistic Regression Model To Predict Custo Mer Churn in Telecom IndustryV1.0 PDFPrakash Jha100% (1)
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Document12 pagesBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya Hajare100% (1)
- Capstone Project SubmissionDocument31 pagesCapstone Project Submissionguruss604684100% (1)
- ML Assignemnt PDFDocument21 pagesML Assignemnt PDFEric NormanNo ratings yet
- Tushar Tukaram Bhakare: Education SkillsDocument1 pageTushar Tukaram Bhakare: Education SkillsSUMEET SARODENo ratings yet
- DSBAProject Oct 2020Document24 pagesDSBAProject Oct 2020Abhay PoddarNo ratings yet
- Cubic Zirconia Price Prediction Case Study ReportDocument34 pagesCubic Zirconia Price Prediction Case Study ReportSomnath Kumbhar100% (1)
- Applied Computational Fluid Dynamics Techniques: An Introduction Based on Finite Element MethodsFrom EverandApplied Computational Fluid Dynamics Techniques: An Introduction Based on Finite Element MethodsNo ratings yet
- Machine Learning - Final Project Report - Problem 1Document26 pagesMachine Learning - Final Project Report - Problem 1KhursheedKhan100% (1)
- IT 7000 - Week 7 Final Presentation - SubramanyamDocument25 pagesIT 7000 - Week 7 Final Presentation - SubramanyamKhursheedKhanNo ratings yet
- Triveni Guntipally - IT 7000 - Week 7 PresentationDocument16 pagesTriveni Guntipally - IT 7000 - Week 7 PresentationKhursheedKhanNo ratings yet
- Ananda Vidya Sagar KATAKAM - MIS - Week 7 Assignment - PresentationDocument26 pagesAnanda Vidya Sagar KATAKAM - MIS - Week 7 Assignment - PresentationKhursheedKhanNo ratings yet
- Ehealth Smart Health Prediction System: Pujitha GangarapuDocument20 pagesEhealth Smart Health Prediction System: Pujitha GangarapuKhursheedKhanNo ratings yet
- Macr PresentationDocument1 pageMacr PresentationKhursheedKhanNo ratings yet
- Success Story Template V0 1Document2 pagesSuccess Story Template V0 1KhursheedKhanNo ratings yet
- Gigabyte GA-H61M-S1Document29 pagesGigabyte GA-H61M-S1arturo rivasNo ratings yet
- Class-Xi Syllabus 2015-16Document34 pagesClass-Xi Syllabus 2015-16Nandini SinghNo ratings yet
- 4G - NCR SSA - 3 - NW - Ischak - SPRO - JBRO - WJRO - CJRO - MODCELLDLSCHALGO - MODEUTRANINTRAFREQNCELL - SE Improvement - 4 - NE - 20210120Document19 pages4G - NCR SSA - 3 - NW - Ischak - SPRO - JBRO - WJRO - CJRO - MODCELLDLSCHALGO - MODEUTRANINTRAFREQNCELL - SE Improvement - 4 - NE - 20210120Ischak ChaerudinNo ratings yet
- Performance Evaluation of Fixed-Point Array Multipliers On Xilinx FpgasDocument5 pagesPerformance Evaluation of Fixed-Point Array Multipliers On Xilinx FpgasMeghanand KumarNo ratings yet
- 4QDocument2 pages4QRakesh ShivshankarNo ratings yet
- NFS2-640/E: Fire Alarm Control Panel Programming ManualDocument124 pagesNFS2-640/E: Fire Alarm Control Panel Programming ManualMinhthien NguyenNo ratings yet
- 5g Wireless Technology Documentation-1Document25 pages5g Wireless Technology Documentation-118WJ1A03L4 RAVI MechNo ratings yet
- IThome Taiwan Cyberscape Sep2021Document1 pageIThome Taiwan Cyberscape Sep2021Roland TamNo ratings yet
- Autonomous VehiclesDocument61 pagesAutonomous VehiclesRohan RahalkarNo ratings yet
- News Sharing in Social Media PDFDocument14 pagesNews Sharing in Social Media PDFCamille PajarilloNo ratings yet
- Logistic Support Analysis (LSA) : TitleDocument26 pagesLogistic Support Analysis (LSA) : Titlenebodepa lyftNo ratings yet
- Implementation of The Internet of Things On Smart Posters Using Near Field Communication Technology in The Tourism SectorDocument9 pagesImplementation of The Internet of Things On Smart Posters Using Near Field Communication Technology in The Tourism SectorCSIT iaesprimeNo ratings yet
- Project Jig & Fixture UTMDocument90 pagesProject Jig & Fixture UTMadibah ismail100% (1)
- En Ac80remapcelem CDocument351 pagesEn Ac80remapcelem CAlejandra De Anda JimenezNo ratings yet
- Demonstrative Adjectives Online PDF Worksheet - Live WorksheetsDocument1 pageDemonstrative Adjectives Online PDF Worksheet - Live WorksheetsCristofer FárezNo ratings yet
- Ict 7 Week 4, 1Document29 pagesIct 7 Week 4, 1Jhan G CalateNo ratings yet
- Crate Archives - RFLDocument4 pagesCrate Archives - RFLFaisal Mohd ShahneoazNo ratings yet
- Product Data Sheet: Asfora - Single Socket Outlet With Side Earth - 16A CreamDocument2 pagesProduct Data Sheet: Asfora - Single Socket Outlet With Side Earth - 16A CreamДимитър МирчевNo ratings yet
- GSM Map ErrorcodeDocument3 pagesGSM Map Errorcodeariful_islam_20067643No ratings yet
- GSI Corti Quick GuideDocument1 pageGSI Corti Quick GuideLourdes Hernández GonzálezNo ratings yet
- WEEK 7 Module - CircuitsDocument6 pagesWEEK 7 Module - CircuitsSatsuki MomoiNo ratings yet
- INF3707 ExaminationDocument4 pagesINF3707 ExaminationhilaryNo ratings yet
- 106Document495 pages106Shankar SahniNo ratings yet
- N E Z E P: Practice Worksheet: Properties of ExponentsDocument2 pagesN E Z E P: Practice Worksheet: Properties of ExponentsAlex ZzNo ratings yet
- Secure OpenShift Applications W IBM Cloud App IDDocument117 pagesSecure OpenShift Applications W IBM Cloud App IDContus FirmasNo ratings yet
- Od 327583247761431100Document1 pageOd 327583247761431100jto HVGNo ratings yet
- Adama Science and Technology University: School of Electrical Engineering and ComputingDocument10 pagesAdama Science and Technology University: School of Electrical Engineering and ComputingDechasa ShimelsNo ratings yet
- Wood Express ManualDocument36 pagesWood Express ManualgertjaniNo ratings yet