
REGRESSION AND CORRELATION Assignment Recovered
REGRESSION AND CORRELATION Assignment Recovered
You might also like
- Appendix ComputationDocument20 pagesAppendix Computationgirlwithglasses50% (4)
- Galvanized Spiral Duct Weight Chart - (Pounds Per Foot)Document1 pageGalvanized Spiral Duct Weight Chart - (Pounds Per Foot)Mehmet CinarNo ratings yet
- Data Analysis ProblemsDocument12 pagesData Analysis Problems陈凯华No ratings yet
- 6 - Measures of Non Central TendencyDocument8 pages6 - Measures of Non Central TendencyAbdul RehmanNo ratings yet
- Exposure: Understanding Living in Extreme Environments ProcessDocument34 pagesExposure: Understanding Living in Extreme Environments Processm.young@gold.ac.uk100% (3)
- Pounds To Kilograms Conversion ChartDocument1 pagePounds To Kilograms Conversion ChartNick MomrikNo ratings yet
- A.5 Critical Values of the χ Distribution: 2 k,q 2 2 k 2 k,q 2 k 2 k,q 2Document2 pagesA.5 Critical Values of the χ Distribution: 2 k,q 2 2 k 2 k,q 2 k 2 k,q 2Jose Ruben Sorto BadaNo ratings yet
- GSM Best Server Report: Chosen Area: Statistics For Threshold: Demographics For Traffic CaseDocument60 pagesGSM Best Server Report: Chosen Area: Statistics For Threshold: Demographics For Traffic CaseSathya SathyarajNo ratings yet
- T (Parameter Rotaion Angle, Radians) X, Normalised To 100% Y, Normalised To 100% Y, RoundedDocument2 pagesT (Parameter Rotaion Angle, Radians) X, Normalised To 100% Y, Normalised To 100% Y, Roundedсвященник Евгений КукушкинNo ratings yet
- Converison TorquesDocument2 pagesConverison TorquesSalvador Manuel Rocha CastilloNo ratings yet
- Proyecto Nuevo AlausiDocument16 pagesProyecto Nuevo AlausiSantiago CujiNo ratings yet
- Status - of - L - Zone - Sector - ParticipationDocument1 pageStatus - of - L - Zone - Sector - ParticipationagrilandncrNo ratings yet
- Setiembre - 2018: Yu Li YenDocument54 pagesSetiembre - 2018: Yu Li YenelizabethNo ratings yet
- Appendix Table 7 - Upper Critical Values of Chi-Square DistributionDocument2 pagesAppendix Table 7 - Upper Critical Values of Chi-Square DistributionNhi Nguyễn Trần LiênNo ratings yet
- Table C. Critical Values of Chi-Square Distribu: Si Ificance - 10 - . 1 - . - 1Document1 pageTable C. Critical Values of Chi-Square Distribu: Si Ificance - 10 - . 1 - . - 1Kyle Daeniel TanNo ratings yet
- 1 Station Name 2 Mukhtb SB 4 5Document7 pages1 Station Name 2 Mukhtb SB 4 5Muhammad AsifNo ratings yet
- Unclassified: So A o ADocument3 pagesUnclassified: So A o AErick Santiago CubillosNo ratings yet
- Unclassified: So A o ADocument3 pagesUnclassified: So A o AErick Santiago CubillosNo ratings yet
- Basic Fret CalculatorDocument2 pagesBasic Fret CalculatorBenjamin RivasNo ratings yet
- Chisq and F TableDocument10 pagesChisq and F Tablesujay giriNo ratings yet
- CV Vs Travel A115003-2B69 30Cv Equal % Characteristic: % OpenDocument1 pageCV Vs Travel A115003-2B69 30Cv Equal % Characteristic: % OpenDerrick MuirNo ratings yet
- Approximate Generator Fuel Consumption ChartDocument1 pageApproximate Generator Fuel Consumption Chartankur yadavNo ratings yet
- OMAS Marks PDFDocument388 pagesOMAS Marks PDFSushanta SaNo ratings yet
- Ceng431 Final ProjectDocument26 pagesCeng431 Final ProjectDuaa SalehNo ratings yet
- JbbkabkDocument5 pagesJbbkabkshadiqNo ratings yet
- Lampiran V: Nilai Kritis Distribusi X2 Level of SignificanceDocument2 pagesLampiran V: Nilai Kritis Distribusi X2 Level of SignificanceMuhammad Iqbal SalehNo ratings yet
- Graphs Sindh Barrage NewDocument161 pagesGraphs Sindh Barrage NewsaibaNo ratings yet
- Pile SetlementDocument18 pagesPile SetlementAli_nauman429458No ratings yet
- Centimeter Per InchDocument1 pageCentimeter Per Inchschoko1987No ratings yet
- R2 Coeficiente de Determinación: Analisis de Varianza CorregidoDocument5 pagesR2 Coeficiente de Determinación: Analisis de Varianza CorregidoEdson Arturo Quispe SánchezNo ratings yet
- Table Chi SquaredDocument2 pagesTable Chi Squaredmariapappalardo02No ratings yet
- AWG Specifications TableDocument6 pagesAWG Specifications TableMaralo SinagaNo ratings yet
- Chi Square TableDocument1 pageChi Square TableAlvin XuNo ratings yet
- Engineering Tables Part1Document12 pagesEngineering Tables Part1RRSNo ratings yet
- TablasDocument8 pagesTablasDavid PiscoyaNo ratings yet
- PrykRea INdicadores Avon 1.Document41 pagesPrykRea INdicadores Avon 1.Diana PalaciosNo ratings yet
- Air Pressure, Psi XY X 2 Height of Nail Out of Board, MMDocument13 pagesAir Pressure, Psi XY X 2 Height of Nail Out of Board, MMravindra erabattiNo ratings yet
- Vane Shear LogDocument3 pagesVane Shear LogAndrianto Handoko NugrohoNo ratings yet
- Protective Angle MethodDocument1 pageProtective Angle MethodAhamed AshithNo ratings yet
- Y (BMI) Xy X y : Respondents X (Age in Years)Document6 pagesY (BMI) Xy X y : Respondents X (Age in Years)Portia IgnacioNo ratings yet
- Practica 2 Simul RepDocument44 pagesPractica 2 Simul RepKatya MoyaNo ratings yet
- No of Obs Accelerating Potential (V) Plate Current (A.u.)Document2 pagesNo of Obs Accelerating Potential (V) Plate Current (A.u.)MD. DIDARUL ISLAMNo ratings yet
- Torque Chart For 12.9Document7 pagesTorque Chart For 12.9Amit SinghNo ratings yet
- Water 2 Assignment 01Document8 pagesWater 2 Assignment 01Talha BhuttoNo ratings yet
- Particulars Note No.: I.Source of Funds: 1.shareholder's FundsDocument12 pagesParticulars Note No.: I.Source of Funds: 1.shareholder's FundsAkash MannaNo ratings yet
- CALIBTKDocument1 pageCALIBTKPaul CarlyNo ratings yet
- Quadro ResumoDocument2 pagesQuadro ResumoIgor FerreiraNo ratings yet
- r717 PT Chart PDFDocument2 pagesr717 PT Chart PDFAlexander Cordero GomezNo ratings yet
- R717 (Ammonia) Pressure Temperature ChartDocument2 pagesR717 (Ammonia) Pressure Temperature ChartNeoZeruelNo ratings yet
- r717 PT ChartDocument2 pagesr717 PT ChartYogesh Narkar100% (1)
- r717 PT Chart PDFDocument2 pagesr717 PT Chart PDFTechnos GuruNo ratings yet
- Radiation Safety DistanceDocument1 pageRadiation Safety Distancesyanas90No ratings yet
- Pardon Supervision 2017Document1 pagePardon Supervision 2017Kakal D'GreatNo ratings yet
- Examen 1 - PS1-Uribe Garcia Jairo LeviDocument31 pagesExamen 1 - PS1-Uribe Garcia Jairo LeviJairo GarciaNo ratings yet
- Linear Trend Analysis Exercise 19 SolutionDocument5 pagesLinear Trend Analysis Exercise 19 SolutionSven A. SchnydrigNo ratings yet
- Propylene PT ChartDocument2 pagesPropylene PT ChartbillNo ratings yet
- Advance Book ADocument6 pagesAdvance Book Aabdelkadera257No ratings yet
- Tables For Wood Post Design Based On NDS 2005: Post Axial Capacity For Douglas Fir-Larch # 1, (Kips)Document22 pagesTables For Wood Post Design Based On NDS 2005: Post Axial Capacity For Douglas Fir-Larch # 1, (Kips)leroytuscanoNo ratings yet
- Dokumen - Pub - Statistics-For-Bus94160-1337516716-9781337516716 1012Document1 pageDokumen - Pub - Statistics-For-Bus94160-1337516716-9781337516716 1012Bình Giang Nguyễn ĐinhNo ratings yet
- Shree 20000 To 1 CRDocument5 pagesShree 20000 To 1 CRsuman.s9072No ratings yet
- Pto. DH Azimut Proyecciones G M S N S EDocument6 pagesPto. DH Azimut Proyecciones G M S N S EBryan RaNo ratings yet
- Policy AnalysisDocument5 pagesPolicy AnalysisCourei-FxAlcazarNo ratings yet
- Action PlanDocument3 pagesAction PlanCourei-FxAlcazarNo ratings yet
- Information Sheet 6 Tag Transmission ComponentsDocument12 pagesInformation Sheet 6 Tag Transmission ComponentsCourei-FxAlcazarNo ratings yet
- Personal Reflection Notes CaasiDocument2 pagesPersonal Reflection Notes CaasiCourei-FxAlcazarNo ratings yet
- Personal Reflection Notes AlcazarDocument2 pagesPersonal Reflection Notes AlcazarCourei-FxAlcazarNo ratings yet
- Auto-TRAINING-DESIGN FinalDocument4 pagesAuto-TRAINING-DESIGN FinalCourei-FxAlcazarNo ratings yet
- Faithful Word Baptist Church Starter PackDocument1 pageFaithful Word Baptist Church Starter PackCourei-FxAlcazarNo ratings yet
- MTE 516 Ajeboy ReportDocument19 pagesMTE 516 Ajeboy ReportCourei-FxAlcazarNo ratings yet
- Move and Position VehicleDocument3 pagesMove and Position VehicleCourei-FxAlcazarNo ratings yet
- After The TribulationDocument24 pagesAfter The TribulationCourei-FxAlcazarNo ratings yet
- COT LESSON LOG BendingDocument5 pagesCOT LESSON LOG BendingCourei-FxAlcazarNo ratings yet
- Information Sheet 1 SealantDocument7 pagesInformation Sheet 1 SealantCourei-FxAlcazarNo ratings yet
- Advantages and Disadvantages of Dewey Decimal Classification System and Library of Congress Classification SystemDocument4 pagesAdvantages and Disadvantages of Dewey Decimal Classification System and Library of Congress Classification SystemCourei-FxAlcazarNo ratings yet
- Monthly SchedDocument1 pageMonthly SchedCourei-FxAlcazarNo ratings yet
- Technology and Livelihood Education: Cookery Quarter 2 - Module 6: Accompaniments of Salads and DressingsDocument24 pagesTechnology and Livelihood Education: Cookery Quarter 2 - Module 6: Accompaniments of Salads and DressingsCourei-FxAlcazarNo ratings yet
- Technology and Livelihood Education: Cookery Quarter 2 - Module 4: Prepare Salad DressingDocument24 pagesTechnology and Livelihood Education: Cookery Quarter 2 - Module 4: Prepare Salad DressingCourei-FxAlcazarNo ratings yet
- Week 3 Wiring DiagramDocument12 pagesWeek 3 Wiring DiagramCourei-FxAlcazarNo ratings yet
- Mte 513 Evaluation of Technology ProgramDocument11 pagesMte 513 Evaluation of Technology ProgramCourei-FxAlcazarNo ratings yet
- Technology and Livelihood Education: Cookery NC Ii Quarter 2 - Module 5: Present A Variety of Salads and DressingsDocument32 pagesTechnology and Livelihood Education: Cookery NC Ii Quarter 2 - Module 5: Present A Variety of Salads and DressingsCourei-FxAlcazarNo ratings yet
- Learners' Names Economic Status Age Math English ScienceDocument12 pagesLearners' Names Economic Status Age Math English ScienceCourei-FxAlcazarNo ratings yet
- CHI SQUARE AssignmentDocument4 pagesCHI SQUARE AssignmentCourei-FxAlcazarNo ratings yet
- Week 1 Wires and CablesDocument22 pagesWeek 1 Wires and CablesCourei-FxAlcazarNo ratings yet
- 3rd Quarter Exam (Statistics)Document4 pages3rd Quarter Exam (Statistics)JERALD MONJUANNo ratings yet
- MOOC Econometrics 6Document4 pagesMOOC Econometrics 6edison medardo100% (1)
- 4 DC 2 F 16583 e 31196Document20 pages4 DC 2 F 16583 e 31196f/z BENRABOUHNo ratings yet
- Research CH 4Document27 pagesResearch CH 4Ebsa AbdiNo ratings yet
- Mariblanca Statistics and ProbabilityDocument14 pagesMariblanca Statistics and ProbabilityArmin Diolosa100% (1)
- PDF Lesson 7 Confidence Level and Sample SizeDocument14 pagesPDF Lesson 7 Confidence Level and Sample SizeJohn Lloyd CasioNo ratings yet
- Lecture 6 - PCA - LecturefinDocument71 pagesLecture 6 - PCA - LecturefinBrown ZeblackNo ratings yet
- Panel Data AssignmentDocument24 pagesPanel Data Assignmentvaishnavidevi dharmarajNo ratings yet
- Confidence Intervals For The Difference Between Two Means With Tolerance ProbabilityDocument10 pagesConfidence Intervals For The Difference Between Two Means With Tolerance ProbabilityscjofyWFawlroa2r06YFVabfbajNo ratings yet
- MBA-BS-Recap Session Model Questions-13-07-2023-SV1Document74 pagesMBA-BS-Recap Session Model Questions-13-07-2023-SV1seyon sithamparanathanNo ratings yet
- Business Statistics V2Document20 pagesBusiness Statistics V2solvedcareNo ratings yet
- Probability and Statistics: Code: CAT-208 Bca-Iii SemDocument19 pagesProbability and Statistics: Code: CAT-208 Bca-Iii SemSandeep MoghaNo ratings yet
- Mca4020 SLM Unit 11Document23 pagesMca4020 SLM Unit 11AppTest PINo ratings yet
- Muhammad Farizky Oktaviannizar AliDocument7 pagesMuhammad Farizky Oktaviannizar AliMuhammad Ramadhannizar AliNo ratings yet
- Biostatistics PPT - 5Document44 pagesBiostatistics PPT - 5asaduzzaman asadNo ratings yet
- Normal Curve and Standard Score-1 2Document31 pagesNormal Curve and Standard Score-1 2Angela Grace CatralNo ratings yet
- Jurnal Fauzan 03-05-2021Document17 pagesJurnal Fauzan 03-05-2021irma rohimahNo ratings yet
- Httpsnalanda Aws - Bits Pilani - Ac.inpluginfile - Php138730mod Resourcecontent1Tutorial20Sheet207 PDFDocument2 pagesHttpsnalanda Aws - Bits Pilani - Ac.inpluginfile - Php138730mod Resourcecontent1Tutorial20Sheet207 PDFf20221673No ratings yet
- Preparing DataDocument37 pagesPreparing DataAlfu AlfinnikmahNo ratings yet
- SCRIBBR - Choosing The Right Statistical TestDocument14 pagesSCRIBBR - Choosing The Right Statistical TestmllabateNo ratings yet
- Chapter 7Document15 pagesChapter 7Khay OngNo ratings yet
- Statistics in Economics and BusinessDocument34 pagesStatistics in Economics and BusinessVương QuáchNo ratings yet
- Lec 21Document14 pagesLec 21deepanshuNo ratings yet
- Individual Assignment AnswerDocument4 pagesIndividual Assignment AnswerChee HongNo ratings yet
- STATISTICDocument6 pagesSTATISTICJung Rae SunNo ratings yet
- VAR Models and Cointegration - Sebastian FossatiDocument64 pagesVAR Models and Cointegration - Sebastian Fossatialexa_sherpyNo ratings yet
- Relative Bias Assessment of D4815 As An Alternative To D5599 For Determination of Ethanol in GasolineDocument38 pagesRelative Bias Assessment of D4815 As An Alternative To D5599 For Determination of Ethanol in GasolineDaniel SanchezNo ratings yet


































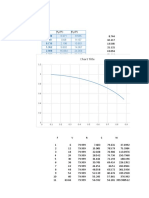








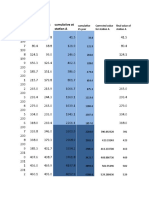






































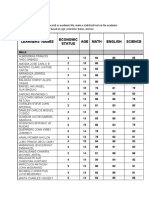





























Download as docx, pdf, or txt
You might also like
- Appendix ComputationDocument20 pagesAppendix Computationgirlwithglasses50% (4)
- Galvanized Spiral Duct Weight Chart - (Pounds Per Foot)Document1 pageGalvanized Spiral Duct Weight Chart - (Pounds Per Foot)Mehmet CinarNo ratings yet
- Data Analysis ProblemsDocument12 pagesData Analysis Problems陈凯华No ratings yet
- 6 - Measures of Non Central TendencyDocument8 pages6 - Measures of Non Central TendencyAbdul RehmanNo ratings yet
- Exposure: Understanding Living in Extreme Environments ProcessDocument34 pagesExposure: Understanding Living in Extreme Environments Processm.young@gold.ac.uk100% (3)
- Pounds To Kilograms Conversion ChartDocument1 pagePounds To Kilograms Conversion ChartNick MomrikNo ratings yet
- A.5 Critical Values of the χ Distribution: 2 k,q 2 2 k 2 k,q 2 k 2 k,q 2Document2 pagesA.5 Critical Values of the χ Distribution: 2 k,q 2 2 k 2 k,q 2 k 2 k,q 2Jose Ruben Sorto BadaNo ratings yet
- GSM Best Server Report: Chosen Area: Statistics For Threshold: Demographics For Traffic CaseDocument60 pagesGSM Best Server Report: Chosen Area: Statistics For Threshold: Demographics For Traffic CaseSathya SathyarajNo ratings yet
- T (Parameter Rotaion Angle, Radians) X, Normalised To 100% Y, Normalised To 100% Y, RoundedDocument2 pagesT (Parameter Rotaion Angle, Radians) X, Normalised To 100% Y, Normalised To 100% Y, Roundedсвященник Евгений КукушкинNo ratings yet
- Converison TorquesDocument2 pagesConverison TorquesSalvador Manuel Rocha CastilloNo ratings yet
- Proyecto Nuevo AlausiDocument16 pagesProyecto Nuevo AlausiSantiago CujiNo ratings yet
- Status - of - L - Zone - Sector - ParticipationDocument1 pageStatus - of - L - Zone - Sector - ParticipationagrilandncrNo ratings yet
- Setiembre - 2018: Yu Li YenDocument54 pagesSetiembre - 2018: Yu Li YenelizabethNo ratings yet
- Appendix Table 7 - Upper Critical Values of Chi-Square DistributionDocument2 pagesAppendix Table 7 - Upper Critical Values of Chi-Square DistributionNhi Nguyễn Trần LiênNo ratings yet
- Table C. Critical Values of Chi-Square Distribu: Si Ificance - 10 - . 1 - . - 1Document1 pageTable C. Critical Values of Chi-Square Distribu: Si Ificance - 10 - . 1 - . - 1Kyle Daeniel TanNo ratings yet
- 1 Station Name 2 Mukhtb SB 4 5Document7 pages1 Station Name 2 Mukhtb SB 4 5Muhammad AsifNo ratings yet
- Unclassified: So A o ADocument3 pagesUnclassified: So A o AErick Santiago CubillosNo ratings yet
- Unclassified: So A o ADocument3 pagesUnclassified: So A o AErick Santiago CubillosNo ratings yet
- Basic Fret CalculatorDocument2 pagesBasic Fret CalculatorBenjamin RivasNo ratings yet
- Chisq and F TableDocument10 pagesChisq and F Tablesujay giriNo ratings yet
- CV Vs Travel A115003-2B69 30Cv Equal % Characteristic: % OpenDocument1 pageCV Vs Travel A115003-2B69 30Cv Equal % Characteristic: % OpenDerrick MuirNo ratings yet
- Approximate Generator Fuel Consumption ChartDocument1 pageApproximate Generator Fuel Consumption Chartankur yadavNo ratings yet
- OMAS Marks PDFDocument388 pagesOMAS Marks PDFSushanta SaNo ratings yet
- Ceng431 Final ProjectDocument26 pagesCeng431 Final ProjectDuaa SalehNo ratings yet
- JbbkabkDocument5 pagesJbbkabkshadiqNo ratings yet
- Lampiran V: Nilai Kritis Distribusi X2 Level of SignificanceDocument2 pagesLampiran V: Nilai Kritis Distribusi X2 Level of SignificanceMuhammad Iqbal SalehNo ratings yet
- Graphs Sindh Barrage NewDocument161 pagesGraphs Sindh Barrage NewsaibaNo ratings yet
- Pile SetlementDocument18 pagesPile SetlementAli_nauman429458No ratings yet
- Centimeter Per InchDocument1 pageCentimeter Per Inchschoko1987No ratings yet
- R2 Coeficiente de Determinación: Analisis de Varianza CorregidoDocument5 pagesR2 Coeficiente de Determinación: Analisis de Varianza CorregidoEdson Arturo Quispe SánchezNo ratings yet
- Table Chi SquaredDocument2 pagesTable Chi Squaredmariapappalardo02No ratings yet
- AWG Specifications TableDocument6 pagesAWG Specifications TableMaralo SinagaNo ratings yet
- Chi Square TableDocument1 pageChi Square TableAlvin XuNo ratings yet
- Engineering Tables Part1Document12 pagesEngineering Tables Part1RRSNo ratings yet
- TablasDocument8 pagesTablasDavid PiscoyaNo ratings yet
- PrykRea INdicadores Avon 1.Document41 pagesPrykRea INdicadores Avon 1.Diana PalaciosNo ratings yet
- Air Pressure, Psi XY X 2 Height of Nail Out of Board, MMDocument13 pagesAir Pressure, Psi XY X 2 Height of Nail Out of Board, MMravindra erabattiNo ratings yet
- Vane Shear LogDocument3 pagesVane Shear LogAndrianto Handoko NugrohoNo ratings yet
- Protective Angle MethodDocument1 pageProtective Angle MethodAhamed AshithNo ratings yet
- Y (BMI) Xy X y : Respondents X (Age in Years)Document6 pagesY (BMI) Xy X y : Respondents X (Age in Years)Portia IgnacioNo ratings yet
- Practica 2 Simul RepDocument44 pagesPractica 2 Simul RepKatya MoyaNo ratings yet
- No of Obs Accelerating Potential (V) Plate Current (A.u.)Document2 pagesNo of Obs Accelerating Potential (V) Plate Current (A.u.)MD. DIDARUL ISLAMNo ratings yet
- Torque Chart For 12.9Document7 pagesTorque Chart For 12.9Amit SinghNo ratings yet
- Water 2 Assignment 01Document8 pagesWater 2 Assignment 01Talha BhuttoNo ratings yet
- Particulars Note No.: I.Source of Funds: 1.shareholder's FundsDocument12 pagesParticulars Note No.: I.Source of Funds: 1.shareholder's FundsAkash MannaNo ratings yet
- CALIBTKDocument1 pageCALIBTKPaul CarlyNo ratings yet
- Quadro ResumoDocument2 pagesQuadro ResumoIgor FerreiraNo ratings yet
- r717 PT Chart PDFDocument2 pagesr717 PT Chart PDFAlexander Cordero GomezNo ratings yet
- R717 (Ammonia) Pressure Temperature ChartDocument2 pagesR717 (Ammonia) Pressure Temperature ChartNeoZeruelNo ratings yet
- r717 PT ChartDocument2 pagesr717 PT ChartYogesh Narkar100% (1)
- r717 PT Chart PDFDocument2 pagesr717 PT Chart PDFTechnos GuruNo ratings yet
- Radiation Safety DistanceDocument1 pageRadiation Safety Distancesyanas90No ratings yet
- Pardon Supervision 2017Document1 pagePardon Supervision 2017Kakal D'GreatNo ratings yet
- Examen 1 - PS1-Uribe Garcia Jairo LeviDocument31 pagesExamen 1 - PS1-Uribe Garcia Jairo LeviJairo GarciaNo ratings yet
- Linear Trend Analysis Exercise 19 SolutionDocument5 pagesLinear Trend Analysis Exercise 19 SolutionSven A. SchnydrigNo ratings yet
- Propylene PT ChartDocument2 pagesPropylene PT ChartbillNo ratings yet
- Advance Book ADocument6 pagesAdvance Book Aabdelkadera257No ratings yet
- Tables For Wood Post Design Based On NDS 2005: Post Axial Capacity For Douglas Fir-Larch # 1, (Kips)Document22 pagesTables For Wood Post Design Based On NDS 2005: Post Axial Capacity For Douglas Fir-Larch # 1, (Kips)leroytuscanoNo ratings yet
- Dokumen - Pub - Statistics-For-Bus94160-1337516716-9781337516716 1012Document1 pageDokumen - Pub - Statistics-For-Bus94160-1337516716-9781337516716 1012Bình Giang Nguyễn ĐinhNo ratings yet
- Shree 20000 To 1 CRDocument5 pagesShree 20000 To 1 CRsuman.s9072No ratings yet
- Pto. DH Azimut Proyecciones G M S N S EDocument6 pagesPto. DH Azimut Proyecciones G M S N S EBryan RaNo ratings yet
- Policy AnalysisDocument5 pagesPolicy AnalysisCourei-FxAlcazarNo ratings yet
- Action PlanDocument3 pagesAction PlanCourei-FxAlcazarNo ratings yet
- Information Sheet 6 Tag Transmission ComponentsDocument12 pagesInformation Sheet 6 Tag Transmission ComponentsCourei-FxAlcazarNo ratings yet
- Personal Reflection Notes CaasiDocument2 pagesPersonal Reflection Notes CaasiCourei-FxAlcazarNo ratings yet
- Personal Reflection Notes AlcazarDocument2 pagesPersonal Reflection Notes AlcazarCourei-FxAlcazarNo ratings yet
- Auto-TRAINING-DESIGN FinalDocument4 pagesAuto-TRAINING-DESIGN FinalCourei-FxAlcazarNo ratings yet
- Faithful Word Baptist Church Starter PackDocument1 pageFaithful Word Baptist Church Starter PackCourei-FxAlcazarNo ratings yet
- MTE 516 Ajeboy ReportDocument19 pagesMTE 516 Ajeboy ReportCourei-FxAlcazarNo ratings yet
- Move and Position VehicleDocument3 pagesMove and Position VehicleCourei-FxAlcazarNo ratings yet
- After The TribulationDocument24 pagesAfter The TribulationCourei-FxAlcazarNo ratings yet
- COT LESSON LOG BendingDocument5 pagesCOT LESSON LOG BendingCourei-FxAlcazarNo ratings yet
- Information Sheet 1 SealantDocument7 pagesInformation Sheet 1 SealantCourei-FxAlcazarNo ratings yet
- Advantages and Disadvantages of Dewey Decimal Classification System and Library of Congress Classification SystemDocument4 pagesAdvantages and Disadvantages of Dewey Decimal Classification System and Library of Congress Classification SystemCourei-FxAlcazarNo ratings yet
- Monthly SchedDocument1 pageMonthly SchedCourei-FxAlcazarNo ratings yet
- Technology and Livelihood Education: Cookery Quarter 2 - Module 6: Accompaniments of Salads and DressingsDocument24 pagesTechnology and Livelihood Education: Cookery Quarter 2 - Module 6: Accompaniments of Salads and DressingsCourei-FxAlcazarNo ratings yet
- Technology and Livelihood Education: Cookery Quarter 2 - Module 4: Prepare Salad DressingDocument24 pagesTechnology and Livelihood Education: Cookery Quarter 2 - Module 4: Prepare Salad DressingCourei-FxAlcazarNo ratings yet
- Week 3 Wiring DiagramDocument12 pagesWeek 3 Wiring DiagramCourei-FxAlcazarNo ratings yet
- Mte 513 Evaluation of Technology ProgramDocument11 pagesMte 513 Evaluation of Technology ProgramCourei-FxAlcazarNo ratings yet
- Technology and Livelihood Education: Cookery NC Ii Quarter 2 - Module 5: Present A Variety of Salads and DressingsDocument32 pagesTechnology and Livelihood Education: Cookery NC Ii Quarter 2 - Module 5: Present A Variety of Salads and DressingsCourei-FxAlcazarNo ratings yet
- Learners' Names Economic Status Age Math English ScienceDocument12 pagesLearners' Names Economic Status Age Math English ScienceCourei-FxAlcazarNo ratings yet
- CHI SQUARE AssignmentDocument4 pagesCHI SQUARE AssignmentCourei-FxAlcazarNo ratings yet
- Week 1 Wires and CablesDocument22 pagesWeek 1 Wires and CablesCourei-FxAlcazarNo ratings yet
- 3rd Quarter Exam (Statistics)Document4 pages3rd Quarter Exam (Statistics)JERALD MONJUANNo ratings yet
- MOOC Econometrics 6Document4 pagesMOOC Econometrics 6edison medardo100% (1)
- 4 DC 2 F 16583 e 31196Document20 pages4 DC 2 F 16583 e 31196f/z BENRABOUHNo ratings yet
- Research CH 4Document27 pagesResearch CH 4Ebsa AbdiNo ratings yet
- Mariblanca Statistics and ProbabilityDocument14 pagesMariblanca Statistics and ProbabilityArmin Diolosa100% (1)
- PDF Lesson 7 Confidence Level and Sample SizeDocument14 pagesPDF Lesson 7 Confidence Level and Sample SizeJohn Lloyd CasioNo ratings yet
- Lecture 6 - PCA - LecturefinDocument71 pagesLecture 6 - PCA - LecturefinBrown ZeblackNo ratings yet
- Panel Data AssignmentDocument24 pagesPanel Data Assignmentvaishnavidevi dharmarajNo ratings yet
- Confidence Intervals For The Difference Between Two Means With Tolerance ProbabilityDocument10 pagesConfidence Intervals For The Difference Between Two Means With Tolerance ProbabilityscjofyWFawlroa2r06YFVabfbajNo ratings yet
- MBA-BS-Recap Session Model Questions-13-07-2023-SV1Document74 pagesMBA-BS-Recap Session Model Questions-13-07-2023-SV1seyon sithamparanathanNo ratings yet
- Business Statistics V2Document20 pagesBusiness Statistics V2solvedcareNo ratings yet
- Probability and Statistics: Code: CAT-208 Bca-Iii SemDocument19 pagesProbability and Statistics: Code: CAT-208 Bca-Iii SemSandeep MoghaNo ratings yet
- Mca4020 SLM Unit 11Document23 pagesMca4020 SLM Unit 11AppTest PINo ratings yet
- Muhammad Farizky Oktaviannizar AliDocument7 pagesMuhammad Farizky Oktaviannizar AliMuhammad Ramadhannizar AliNo ratings yet
- Biostatistics PPT - 5Document44 pagesBiostatistics PPT - 5asaduzzaman asadNo ratings yet
- Normal Curve and Standard Score-1 2Document31 pagesNormal Curve and Standard Score-1 2Angela Grace CatralNo ratings yet
- Jurnal Fauzan 03-05-2021Document17 pagesJurnal Fauzan 03-05-2021irma rohimahNo ratings yet
- Httpsnalanda Aws - Bits Pilani - Ac.inpluginfile - Php138730mod Resourcecontent1Tutorial20Sheet207 PDFDocument2 pagesHttpsnalanda Aws - Bits Pilani - Ac.inpluginfile - Php138730mod Resourcecontent1Tutorial20Sheet207 PDFf20221673No ratings yet
- Preparing DataDocument37 pagesPreparing DataAlfu AlfinnikmahNo ratings yet
- SCRIBBR - Choosing The Right Statistical TestDocument14 pagesSCRIBBR - Choosing The Right Statistical TestmllabateNo ratings yet
- Chapter 7Document15 pagesChapter 7Khay OngNo ratings yet
- Statistics in Economics and BusinessDocument34 pagesStatistics in Economics and BusinessVương QuáchNo ratings yet
- Lec 21Document14 pagesLec 21deepanshuNo ratings yet
- Individual Assignment AnswerDocument4 pagesIndividual Assignment AnswerChee HongNo ratings yet
- STATISTICDocument6 pagesSTATISTICJung Rae SunNo ratings yet
- VAR Models and Cointegration - Sebastian FossatiDocument64 pagesVAR Models and Cointegration - Sebastian Fossatialexa_sherpyNo ratings yet
- Relative Bias Assessment of D4815 As An Alternative To D5599 For Determination of Ethanol in GasolineDocument38 pagesRelative Bias Assessment of D4815 As An Alternative To D5599 For Determination of Ethanol in GasolineDaniel SanchezNo ratings yet