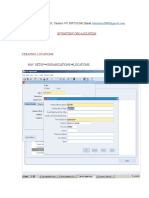
Download as pdf or txt
You might also like
- Affidavit by A Co-Worker For H-1B - Sample 1Document2 pagesAffidavit by A Co-Worker For H-1B - Sample 1Arpan Kumar100% (1)
- Mellel GuideDocument402 pagesMellel GuideabrahamzNo ratings yet
- Spark DetailsDocument11 pagesSpark Detailssarvesh_mishraNo ratings yet
- Big Data Hadoop Certification Training: About IntellipaatDocument13 pagesBig Data Hadoop Certification Training: About IntellipaatVinay Nagnath JokareNo ratings yet
- Kelly Hadoop Hyd May 2018Document14 pagesKelly Hadoop Hyd May 2018dilip kumarNo ratings yet
- PySpark+Slides v1Document458 pagesPySpark+Slides v1ravikumar lankaNo ratings yet
- RaviKumar Gurrappagari PDFDocument8 pagesRaviKumar Gurrappagari PDFBenedict ZanderNo ratings yet
- Mohit BigData 5yrDocument3 pagesMohit BigData 5yrshreya arunNo ratings yet
- ResumeDocument4 pagesResumeshekharNo ratings yet
- Inndata Analytics PVT LTD December 2016 - Present: E-Mail: PhoneDocument3 pagesInndata Analytics PVT LTD December 2016 - Present: E-Mail: Phonepreeti dNo ratings yet
- HOL Hive PDFDocument23 pagesHOL Hive PDFKishore KumarNo ratings yet
- Hands OnDocument26 pagesHands OnAshok Kumar K RNo ratings yet
- Hadoop Architecture ExerciseDocument24 pagesHadoop Architecture Exercisepav20021No ratings yet
- Spark Sample Resume 2Document7 pagesSpark Sample Resume 2pupscribd100% (1)
- Top Answers To Sqoop Interview QuestionsDocument4 pagesTop Answers To Sqoop Interview QuestionsEjaz AlamNo ratings yet
- Hadoop Training VM: 1 Download Virtual BoxDocument3 pagesHadoop Training VM: 1 Download Virtual BoxMiguel Angel Hernández RuizNo ratings yet
- Hadoop-Oozie User MaterialDocument183 pagesHadoop-Oozie User MaterialrahulneelNo ratings yet
- Hadoop Interview QuestionsDocument28 pagesHadoop Interview QuestionsAnand SNo ratings yet
- Dzone Apache Hadoop DeploymentDocument7 pagesDzone Apache Hadoop DeploymentVernFWKNo ratings yet
- Hadoop Interview QuestionsDocument28 pagesHadoop Interview Questionsjey011851No ratings yet
- Create An Spark Streaming App: 1. Architecture and AbstractionDocument8 pagesCreate An Spark Streaming App: 1. Architecture and AbstractionNgô HoàngNo ratings yet
- Midhun BIGDATA CuricullumDocument17 pagesMidhun BIGDATA CuricullumFukkkNo ratings yet
- HadoopDocument114 pagesHadoopasdaNo ratings yet
- Hadoop Interview Questions - Part 1Document8 pagesHadoop Interview Questions - Part 1Arunkumar PalathumpattuNo ratings yet
- Hadoop Interview Questions FaqDocument14 pagesHadoop Interview Questions FaqmihirhotaNo ratings yet
- Sqoop Interview QuestionsDocument6 pagesSqoop Interview QuestionsGuruprasad VijayakumarNo ratings yet
- Final Print Py SparkDocument133 pagesFinal Print Py SparkShivaraj KNo ratings yet
- 24 Hadoop Interview Questions & Answers For MapReduce Developers - FromDevDocument7 pages24 Hadoop Interview Questions & Answers For MapReduce Developers - FromDevnalinbhattNo ratings yet
- Hadoop 2Document111 pagesHadoop 2asdaNo ratings yet
- Bhanu Busi: E-Mail: Contact No: +91 8897834104Document6 pagesBhanu Busi: E-Mail: Contact No: +91 8897834104ChandanaNo ratings yet
- Mix Hadoop Developer Interview QuestionsDocument3 pagesMix Hadoop Developer Interview QuestionsAmit KumarNo ratings yet
- 13 SparkBuildingAndDeployingDocument53 pages13 SparkBuildingAndDeployingPetter PNo ratings yet
- 1 Apache ZookeeperDocument7 pages1 Apache ZookeeperatufNo ratings yet
- Hadoop Administration Interview Questions and Answers: 40% Career Booster Discount On All Course - Call Us Now 9019191856Document26 pagesHadoop Administration Interview Questions and Answers: 40% Career Booster Discount On All Course - Call Us Now 9019191856krishnaNo ratings yet
- SAmple HadoopDocument7 pagesSAmple HadoopMottu2003No ratings yet
- Golden GateDocument69 pagesGolden GateArunKumar ANo ratings yet
- SoumyadipKhan ResumeDocument1 pageSoumyadipKhan ResumeSoumyadip KhanNo ratings yet
- Homework Labs Lecture01Document9 pagesHomework Labs Lecture01Episode UnlockerNo ratings yet
- Apache HiveDocument3 pagesApache Hivekual21No ratings yet
- Hadoop Admin Download Syllabus PDFDocument4 pagesHadoop Admin Download Syllabus PDFshubham phulariNo ratings yet
- Hadoop Interview QuestionDocument25 pagesHadoop Interview Questionsatish.sathya.a2012No ratings yet
- NoSQL and MongoDBDocument47 pagesNoSQL and MongoDBarya1017No ratings yet
- Real Time Hadoop Interview Questions From Various InterviewsDocument6 pagesReal Time Hadoop Interview Questions From Various InterviewsSaurabh GuptaNo ratings yet
- 6 Frequently Asked Hadoop Interview Questions and Answers: Q1.What Is Hadoop?Document8 pages6 Frequently Asked Hadoop Interview Questions and Answers: Q1.What Is Hadoop?Krish DhoomNo ratings yet
- Apps DBA Interview QuestionDocument12 pagesApps DBA Interview QuestionRamesh KumarNo ratings yet
- HDFS ArchitectureDocument47 pagesHDFS Architecturekrishan GoyalNo ratings yet
- SparkDocument17 pagesSparkRavi KumarNo ratings yet
- AaxHadoop Interview Questions and AnswersDocument37 pagesAaxHadoop Interview Questions and Answersshubham rathodNo ratings yet
- Big Data Hadoop ArchitectDocument19 pagesBig Data Hadoop ArchitectAnonymous nQ9mMyNo ratings yet
- Spark Training - JavaDocument8 pagesSpark Training - JavaPavan KumarNo ratings yet
- Linux Command ListDocument8 pagesLinux Command ListhkneptuneNo ratings yet
- 1 Hdfs NotesDocument38 pages1 Hdfs NotesSandeep BoyinaNo ratings yet
- Mining Data StreamsDocument67 pagesMining Data StreamsushaNo ratings yet
- 7 Hive NotesDocument36 pages7 Hive NotesSandeep BoyinaNo ratings yet
- Bigdata NotesDocument26 pagesBigdata NotesAnil YarlagaddaNo ratings yet
- Sreeja.T: SR Hadoop DeveloperDocument7 pagesSreeja.T: SR Hadoop DeveloperAnonymous Kf8Nw5TmzGNo ratings yet
- DVS SPARK Course Content PDFDocument2 pagesDVS SPARK Course Content PDFJayaramReddyNo ratings yet
- Edureka Interview Questions - HDFSDocument4 pagesEdureka Interview Questions - HDFSvarunpratapNo ratings yet
- Teradata & AbinitioDocument2 pagesTeradata & AbinitioAtlury JeyyadevNo ratings yet
- S MapReduce Types Formats Features 03Document16 pagesS MapReduce Types Formats Features 03Ashwin AjmeraNo ratings yet
- 100 Days of DatascienceDocument41 pages100 Days of Datascienceahmed_sftNo ratings yet
- Punjab Examination Commission Examination 2018, Grade 5 Mathematics PartDocument4 pagesPunjab Examination Commission Examination 2018, Grade 5 Mathematics Partahmed_sftNo ratings yet
- PythonDocument77 pagesPythonahmed_sftNo ratings yet
- Hive AzureDocument646 pagesHive Azureahmed_sftNo ratings yet
- ClassDocument3 pagesClassahmed_sftNo ratings yet
- Scala Cheat SheetDocument60 pagesScala Cheat Sheetahmed_sftNo ratings yet
- PyspakDocument2 pagesPyspakahmed_sftNo ratings yet
- Process Flow Social Media Data - HadoopDocument25 pagesProcess Flow Social Media Data - Hadoopahmed_sft100% (1)
- ICEIS 110 BPMN2DModelDocument12 pagesICEIS 110 BPMN2DModelahmed_sftNo ratings yet
- Spark Lab Guide For Scala - GS - Ver 1.0Document18 pagesSpark Lab Guide For Scala - GS - Ver 1.0ahmed_sftNo ratings yet
- CA ERwin Data Modeler. Methods GuideDocument98 pagesCA ERwin Data Modeler. Methods Guideahmed_sftNo ratings yet
- Spark Lab Guide Ver 3.0Document25 pagesSpark Lab Guide Ver 3.0ahmed_sftNo ratings yet
- Lab Setup Guide 2.0Document7 pagesLab Setup Guide 2.0ahmed_sftNo ratings yet
- Spark Kafka TutorialDocument6 pagesSpark Kafka Tutorialahmed_sftNo ratings yet
- Spark Using Scala - Developer Training 1.0Document106 pagesSpark Using Scala - Developer Training 1.0ahmed_sftNo ratings yet
- BI Server Securty MigrationDocument1 pageBI Server Securty Migrationahmed_sftNo ratings yet
- Hrms PayrollDocument153 pagesHrms Payrollahmed_sftNo ratings yet
- SDE ORA GLBalanceFact Full LogDocument42 pagesSDE ORA GLBalanceFact Full Logahmed_sftNo ratings yet
- SDE ORA ExchangeRateGeneral Compress Full LogDocument7 pagesSDE ORA ExchangeRateGeneral Compress Full Logahmed_sftNo ratings yet
- Multi OrgDocument41 pagesMulti Orgahmed_sftNo ratings yet
- Essbase Studi Deep DriveDocument31 pagesEssbase Studi Deep Driveahmed_sftNo ratings yet
- 12.1.3 To 12.2Document56 pages12.1.3 To 12.2ahmed_sftNo ratings yet
- 12.2.5 UpgradeDocument14 pages12.2.5 Upgradeahmed_sftNo ratings yet
- EBS-Strategy-12 2 5Document100 pagesEBS-Strategy-12 2 5ahmed_sftNo ratings yet
- Nikdvbadt-3.0.8 em Nike Asia Eng 201023.0Document238 pagesNikdvbadt-3.0.8 em Nike Asia Eng 201023.0Anonymous 74EiX2MzgcNo ratings yet
- M/M/1: The Classical Queueing System: of Range The in Is It and WhereDocument3 pagesM/M/1: The Classical Queueing System: of Range The in Is It and WhereriasinghalNo ratings yet
- Blues Crusher SchematicDocument28 pagesBlues Crusher Schematiczeus maxNo ratings yet
- Instruction Manual Sensor Laser Keyence PDFDocument4 pagesInstruction Manual Sensor Laser Keyence PDFAri Putra RamadhanNo ratings yet
- Case For Pokayoke & SensorDocument56 pagesCase For Pokayoke & SensorSukhdev BhatiaNo ratings yet
- Logiq Scan Assistant Guide Global 1Document8 pagesLogiq Scan Assistant Guide Global 1danielNo ratings yet
- Java Programming - Mid - 2 - Question Bank: UNIT-4 Part-ADocument2 pagesJava Programming - Mid - 2 - Question Bank: UNIT-4 Part-ASivaramakrishna Markandeya GuptaNo ratings yet
- DBSCAN PresentationDocument10 pagesDBSCAN PresentationRosemelyne WartdeNo ratings yet
- Kaizen Digital - Pdfkaizen Digital PDFDocument22 pagesKaizen Digital - Pdfkaizen Digital PDFarunNo ratings yet
- Enter AV1: Alliance For Open Media CodecDocument14 pagesEnter AV1: Alliance For Open Media CodecVikram BhaskaranNo ratings yet
- AMD FidelityFX Super Resolution 3-Overview and IntegrationDocument64 pagesAMD FidelityFX Super Resolution 3-Overview and IntegrationIvor LiNo ratings yet
- Operation Manual: Biological Safety CabinetDocument16 pagesOperation Manual: Biological Safety Cabinetsourabh naikyaNo ratings yet
- Pre-Assessment Module: Dashboard PA Set-ADocument8 pagesPre-Assessment Module: Dashboard PA Set-Aneed qNo ratings yet
- Gigabyte GA-H61M-S1Document29 pagesGigabyte GA-H61M-S1arturo rivasNo ratings yet
- SAP Innovation Awards 2020 Entry Pitch Deck: Design and Implementation - EY IFRS 17 CockpitDocument10 pagesSAP Innovation Awards 2020 Entry Pitch Deck: Design and Implementation - EY IFRS 17 CockpitJose Rengifo LeonettNo ratings yet
- Evaluationof Web Vulnerability Scanners Basedon OWASPBenchmarkDocument7 pagesEvaluationof Web Vulnerability Scanners Basedon OWASPBenchmarktaslim bangkinangNo ratings yet
- CCNA - EIGRP Authentication ConfigurationDocument3 pagesCCNA - EIGRP Authentication ConfigurationJay Mehta100% (1)
- Design Automation With IOTDocument1 pageDesign Automation With IOTravikaran tripathiNo ratings yet
- FF68 - Check Deposit Process - SAP CommunityDocument6 pagesFF68 - Check Deposit Process - SAP Communitybqueli22No ratings yet
- AshiDocument12 pagesAshikirnifirniNo ratings yet
- User Guide Book - G2scanDCUDocument18 pagesUser Guide Book - G2scanDCUelcafedemarieNo ratings yet
- A2 14.2 Circuit Switching Packet SwitchingDocument5 pagesA2 14.2 Circuit Switching Packet SwitchingMaryam NuurNo ratings yet
- Name and Address Algorithms White Paper 009Document21 pagesName and Address Algorithms White Paper 009Christina LockwoodNo ratings yet
- Create Product Master of Type "Configurable Material" (2T7) : Master Data Script SAP S/4HANA - 03-09-19Document31 pagesCreate Product Master of Type "Configurable Material" (2T7) : Master Data Script SAP S/4HANA - 03-09-19Vengaiah Chowdary Pachava Chinna100% (1)
- Labmate Lims Erp Product IntroductionDocument45 pagesLabmate Lims Erp Product IntroductionN. K. MandilNo ratings yet
- Hard Reference Sensor Section 8 Electrical Torque 5665001 01Document13 pagesHard Reference Sensor Section 8 Electrical Torque 5665001 01Daniel Rolando Gutierrez FuentesNo ratings yet
- LG Q6 LM-M700TVDocument115 pagesLG Q6 LM-M700TVLaura PicklerNo ratings yet
- IRubric - Event Planning & Execution Rubric - LAW6CW - RCampusDocument1 pageIRubric - Event Planning & Execution Rubric - LAW6CW - RCampusRecks Mateo100% (1)